LLM之长度外推(二)| Self-Extend:无需微调的自扩展大模型上下文窗口

论文链接:https://simg.baai.ac.cn/paperfile/a34ae7f4-f0ce-4f8f-b8f2-e8e4d84bbee5.pdf
目前大模型基本都采用transformer结构,而transformer中attention机制的计算复杂度与序列长度呈平方关系,因此大模型在训练时候通常会设置固定的上下文窗口,而且也不会太大,比如GPT-4支持32K上下文,但这会限制大模型在推理时处理长序列的能力。
作者认为LLM本身具有处理长上下文的能力,基于这一论点,提出了Self-Extend,其基本思想是构建两个维度的注意力机制:组维度和邻居维度。这两个维度是通过原始模型的self-attention来计算的,这意味着模型不需要任何训练。仅需修改四行代码,所提出的方法就可以毫不费力地扩展现有LLM的上下文窗口,而无需任何微调。
一、介绍
大多数现有LLM的上下文窗口长度是有限的,因为它们是用固定长度的训练序列训练的。在预训练阶段就确定了上下文窗口长度,在推断阶段,输入序列的长度一旦超过预训练上下文窗口大小,LLM的行为就变的不可预测,性能就会急速下滑,这可以从困惑度(PPL)指标看出,随着输入序列长度的增加,模型的PPL将出现陡然增强的趋势(可以参考论文:《EFFICIENT STREAMING LANGUAGE MODELS WITH ATTENTION SINKS》)。
最近,针对扩展预训练LLM的上下文窗口大小已经提出了很多方法。一种常见而直接的方法是在足够广泛的文本上微调这些模型。除此之外,还有一些方法在寻求不需要微调或仅进行最小微调。在这些当代方法中,一些著名的技术包括“PI”、“CLEX”和“Yarn”。然而,这些通常都需要一些微调步骤来实现扩展,这可能是资源密集型且耗时的。这些方法旨在基于预先训练的LLM缺乏处理长内容的能力的假设来扩展内容窗口。因此,有限的微调可能会使LLM过拟合到特定的长序列,这对分布外的长序列缺乏可推广性,并在预训练过程中获得的短序列上失去性能。另一方面,一些方法(《EFFICIENT STREAMING LANGUAGE MODELS WITH ATTENTION SINKS》)旨在避免微调。这些免微调方法主要依赖于序列中的局部信息。然而,这些方法可能无法有效扩展上下文窗口,因为它是有限的而不是扩展LLM的整体上下文处理能力。因此,它们可能无法完全实现在LLM中扩展上下文窗口的潜力,并且性能较差。
在本论文中,作者认为LLM应该具有处理长上下文的固有能力,而不是扩展内容窗口。信念源于这样一个事实,即当我们还是孩子的时候,我们被教导如何使用相对较短的文本来阅读和写作,比如几页的文章。我们很少像完整的那样使用超长的文本书籍或完整的文件作为学习材料。然而,我们仍然能够有效地理解长文本。有了这种强大的动机,LLM在面对超出预训练上下文窗口大小的长文本时表现不佳并不是因为缺乏长上下文理解能力。作者认为应该有一种方法来引出LLM固有的长上下文能力。
在作者的分析中,观察到,阻止LLM有效管理广泛上下文的关键挑战是与位置编码相关的分布外(O.O.D)问题,称之为位置O.O.D问题。当LLM在推理过程中遇到超过其预训练上下文窗口长度的文本序列时,就会出现这个问题,其中LLM暴露于新的相对距离在他们的预训练阶段没有出现。人们普遍认为,神经网络在处理O.O.D输入时容易受到不可预测行为的影响。为了解决这个问题,一个直观而实用的解决方案是将看不见的相对位置重新映射到预训练过程中遇到的相对位置,从而扩展LLM自然处理较长上下文的能力。
为了克服位置O.O.D问题,作者提出Self-Extend方法,该方法使用简单的FLOOR(//)操作作为映射函数,将看不见的较大相对位置映射到预训练期间遇到的位置。这个想法源于两种直觉:1)对于文本中距离较长的词之间并不需要精确的位置。只要保持不同部分的相对顺序,就足以理解文本的整体含义。在回答关于长文中信息的问题时,我们永远不会记住每个单词的确切位置,只记得相关信息的大致位置和顺序。由于自然语言文本往往在小范围内(如段落)具有相似的语义,因此接近甚至相等位置的编码应该足以保持有用信息的相对顺序,这与floor操作一致。2)在自然语言文本中,当一小词袋(比如n-grams)一起出现时,由于语言语法的惯例,大多数时候,该袋中的所有tokens只有一个可能的顺序。尽管从理论上讲,一袋tokens可以以任何顺序出现,但在实践中,一小组单词很少有多个合理的顺序,例如“unnecessary encodings”可以标记为“unn”、“necessary”、“enc”和“odings”,但这些标记只能按该顺序有意义地出现。这表明,在小区域内不需要保持精确的位置信息,这也与floor操作一致。
Self-Extend是一种即插即用的方法,在推理阶段使用,适用于现有的大型语言模型。作者使用三种流行的LLM(Llama-2、Mistral和SOLAR)对三种类型的任务(包括语言建模、合成长上下文任务和真实世界长上下文任务)进行Self-Extend评估。所提出的Self-Extend大大提高了长上下文理解能力,甚至在某些任务上优于基于微调的方法,这些结果说明了Self-Extend是上下文窗口扩展的有效解决方案。Self-Extend的卓越性能也展示了大型语言模型有效处理长上下文的潜力。
论文的主要贡献总结如下:
1.作者认为RoPE的LLM具有处理长文本的天生能力,即使他们在训练中没有遇到超长文本。之前的限制源于分布外的位置,这意味着在训练中没有看到“较大”的位置,称之为位置O.O.D.问题。
2.为了解决位置O.O.D.问题,我们建议Self-Extend在没有任何微调的情况下扩展LLM的上下文窗口,将看不见的大相对位置(在推理时)映射到已知位置(在训练时),因此它允许LLM在没有额外微调的情况下保持较长文本的连贯性。
3.在合成和现实世界的长上下文任务上,Self-Extend可以实现与许多现有的基于微调的模型相当或令人惊讶的更好的性能。
二、背景
2.1 位置编码
Transformers通过不同的位置嵌入设计结合了位置信息。常见的位置嵌入设计通常可以分为两类:绝对位置编码和相对位置编码。绝对位置编码提供了绝对位置,它将每个绝对位置i嵌入到位置向量pi中并添加单词embedding中,然后将它们发送到模型。使用绝对位置编码的例子包括sinusoidal位置嵌入,以及GPT3和OPT中的可学习位置嵌入,或者在注意力logit上添加两个标记的位置嵌入之间的点积。
最近,已经提出了相对位置编码来代替使用tokens之间的距离信息,并且已经成为位置嵌入的主流。相对位置编码通常应用在注意力层。这样的例子包括T5、Transformer XL;一种称为Alibi的固定线性注意力衰减;基于距离旋转query和key序列的RoPE和XPos。本文提出的方法是基于RoPE的。
2.2 RoPE
之前的工作表明RoPE可以有效地扩展上下文窗口,在推理过程中可以适用更长的文本序列。本节将介绍一下RoPE的基本概念。假设我们有一个表示为![]() 的token序列,它们对应的嵌入表示为
的token序列,它们对应的嵌入表示为![]() x1,···,xL∈R|D|,其中|D|是嵌入的维度数。
x1,···,xL∈R|D|,其中|D|是嵌入的维度数。
RoPE的基本思想是将位置信息分别合并到查询q和关键向量k中。这种集成确保了它们的内积![]() 包含相对位置嵌入信息。为了实现这一点,RoPE采用了以下矢量变换:
包含相对位置嵌入信息。为了实现这一点,RoPE采用了以下矢量变换:
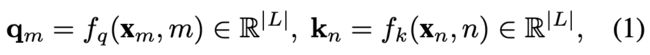
其中|L|是每个头部的隐藏维度大小。函数![]() 负责添加位置信息的,定义如下:
负责添加位置信息的,定义如下:
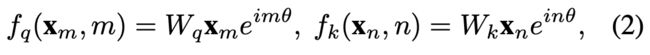
其中![]() ,b=10000和
,b=10000和![]() 。RoPE保持内积
。RoPE保持内积![]() 的实部,即Re(q*k)。此操作确保query和key向量的点积完全取决于tokens之间的相对距离,由令牌m−n表示,如下所示
的实部,即Re(q*k)。此操作确保query和key向量的点积完全取决于tokens之间的相对距离,由令牌m−n表示,如下所示
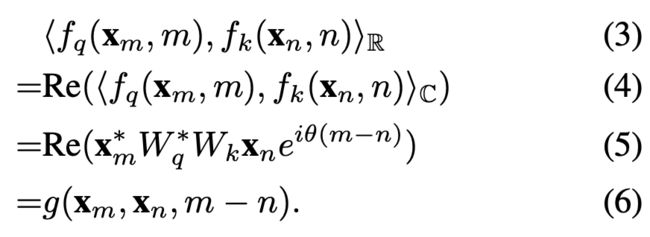
后续研究(https://arxiv.org/abs/2308.12950)表明,当对较短的序列长度进行微调预训练时,RoPE可以适应较长的序列长度。作者认为,使用RoPE的LLM具有直接处理长上下文的内在能力,这项工作的重点是利用这种潜在能力,而无需进行微调。
三、Self-Extend上下文窗口
在本节中,首先进行初步调查LLM处理长内容的固有能力。
3.1 初步分析
① 为什么LLM在预训练上下文窗口之外的输入时失败?作者认为,这种失败源于相对距离的分布外问题。神经网络对分布外(O.O.D.)输入不具有鲁棒性。对于具有相对位置编码(如RoPE)的预训练LLM,在推断时,如果序列长于其预训练上下文窗口长度,则LLM的行为将是不可预测的。《LM-Infinite: Simple On-the-Fly Length Generalization for Large Language Models》已经阐述了这一点,即对于看不见的相对位置,与预训练上下文窗口长度内的注意力分布相比,注意力分布非常不同。
② 如何在保持长距离信息的同时,绕过长度限制?——使用FLOOR操作进行group attention。Self-Extend的主要目标是在不进行任何微调的情况下引出LLM的固有能力。避免由看不见的相对位置引起的O.O.D.问题的一种可行方法是将新的相对位置映射到预训练期间看到的相对位置。FLOOR操作非常适合这些要求,因为有以下两个方面:
•使用floor操作可以映射tokens之间的顺序信息。尽管tokens之间的顺序并不是那么精确。
•FLOOR操作简单易用。

在图1中,我们展示了如何应用FLOOR操作将位置映射到预训练上下文窗口中的位置。除了在内积之前,FLOOR操作应用于每个token的原始位置之外,其他一切都与原始的自注意机制相同。在Python风格中,此操作可以表示为

而![]() 是整数中的原始位置。B是批量大小,N是输入文本序列长度。
是整数中的原始位置。B是批量大小,N是输入文本序列长度。![]() 是组大小的超参数。它是FLOOR操作的基础。我们将使用FLOOR运算的自我注意力表示为“分组注意力”。
是组大小的超参数。它是FLOOR操作的基础。我们将使用FLOOR运算的自我注意力表示为“分组注意力”。
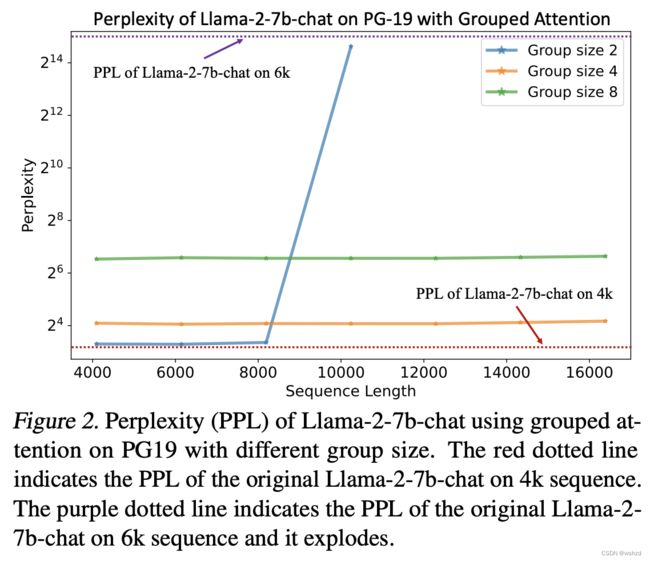
③ LLM在没有准确位置信息的情况下能正常工作吗?——是的,但不是那么完美。在图2中,作者展示了在PG-19数据集上FLOOR运算应用于不同序列长度的几个LLM的困惑(PPL)。作为比较,作者还将没有经过FLOOR操作的原始模型的PPL显示为虚线。从这个图中可以看出,通过FLOOR操作,LLM仍然可以保持相对良好的PPL。同时,在小组规模较小的情况下,PPL略高于原始LLM。这种语言建模性能下降是意料之中的事。然而,它可以暗示组注意力的有效性,并支持关于粗略位置编码的假设。PPL不太大,LLM的行为w.r.t.PPL与原始模型相似,即PPL在“上下文窗口”内几乎没有变化(对于Llama-2:2-8192、4-16384和8-32768)。
④ 如何重建群体注意力导致的语言建模能力下降?——在相邻区域重新引入正常注意力。在生成某个token时,相邻token对该token来说是最重要。这得到了稀疏注意力和上下文窗口扩展的许多现有工作的支持。所有这些工作都保持了相邻token的注意力机制不变。这也符合直觉:相邻token直接负责生成的下一个令牌。一旦LLM精确地建模了相邻token,至少生成的句子是流畅的,并且PPL不应该很大。更具体地说,如果我们使用前面提到的分组注意力,尽管它只会在生成下一个表征来构建可读句子时影响对文本的理解,但仍然需要提供确切的位置。最后,我们仍然需要保持注意机制在相邻区域保持不变,这将是预训练阶段使用的正常注意。
3.2.无需调整的自扩展LLM上下文窗口
基于上述见解,作者提出了Self-Extend方法,它包含两种注意力:分组注意力是为长距离的token设计的,并在位置上应用了FLOOR运算;在一个范围的相邻token采用标准的注意力机制,不需要任何修改,Self-Extend的示意图如图3所示。Self-Extend仅在推理过程中修改注意力机制,不需要任何微调或训练。

将预训练上下文窗口大小表示为L,将分组注意力的组大小表示为G,将相邻标记的窗口大小表示为![]() 。在将两个注意力合并在一起之前,我们将分组注意力的相对位置移动
。在将两个注意力合并在一起之前,我们将分组注意力的相对位置移动![]() ,这是因为从正常注意力区域到分组注意力区域的过渡是平滑的。我们通过用分组注意力的注意力值替换邻居标记窗口外的注意力值来合并注意力的两个部分。
,这是因为从正常注意力区域到分组注意力区域的过渡是平滑的。我们通过用分组注意力的注意力值替换邻居标记窗口外的注意力值来合并注意力的两个部分。
在softmax操作之前应用所有修改,其他部分保持不变。扩展上下文窗口的最大长度为:
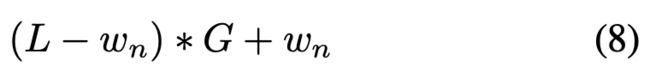
例如,在图3中,上下文窗口从其预训练长度7扩展到(7−4)*2+4=10。算法1中给出了SelfExtend的python风格的伪代码。

四、实验
作者使用目前比较流行的Llama-2家族以及基于RoPE编码的Mistral和SOLAE三个大模型来评估Self-Extend,并且在语言建模、合成长上下文任务和真实长上下文任务三种任务上评估Self-Extend的有效性。考虑到大多数任务都是短上下文,作者还构建了对标准短上下文任务的评估。
4.1 语言建模性能
语言建模是LLM最基本的、最起码的功能。PPL低不能保证在实际任务中具有良好的性能,而PPL过高则表明LLM的性能严重下降。
作者在长文本书籍PG19数据集上评估Self-Extend的语言建模性能。对PG19测试集(100本书)中每本书的第一句话来测试语言建模能力,使用困惑(PPL)来评估。所有PPL结果均使用滑动窗口法计算,S=256。作者还评估了PPL如何随着输入长度的增加而变化,结果如下表1所示:

在表1中,Self-Extend将原始Llama-2的上下文窗口长度从4096(4k)扩展到大于16384(16k),组大小G设置为8,相邻窗口wn设置为1024(1k)。对于不带SWA的Mistral,上下文窗口为8192(8k),也通过相同设置的“Self-Extend”扩展为大于16k。使用SWA,Mistral可以处理无限长的序列。
Self-Extend可以成功地在Llama-2-chat和Mistral的预训练上下文窗口之外保持较低的PPL。如果没有“Self-Extend”,PPL将从上下文窗口中展开。使用SWA的Mistral也可以在其上下文窗口之外保持较低的PPL。但在下一节的后面,我们将展示低PPL并不意味着处理长上下文的真正能力。
4.2 合成长上下文任务的表现
《Landmark Attention: Random-Access Infinite Context Length for Transformers》中所定义密钥检索任务需要一个语言模型来检索一个长而无意义的文本序列中的简单密钥(一个五位数的随机数)。这个任务非常简单,它测试LLM是否可以知道输入序列所有位置的信息。
受“Needle in a Haystack”测试设计的启发,密钥被放置在不同文档深度(密钥放置在输入文本中的位置)和上下文长度(从4k到24k不等)中。对于每个上下文长度的每个深度,从一个深度区间均匀分布中的一个随机位置执行多次迭代来检索密钥的位置。更具体地说,对于400的每个span迭代执行十次密钥检索。例如,如果针对上下文测试文档深度0.1长度为8k,密钥将在每次迭代中随机放置在[8001600)之间的位置,总共执行10×(8000×0.1/400)=20次迭代。
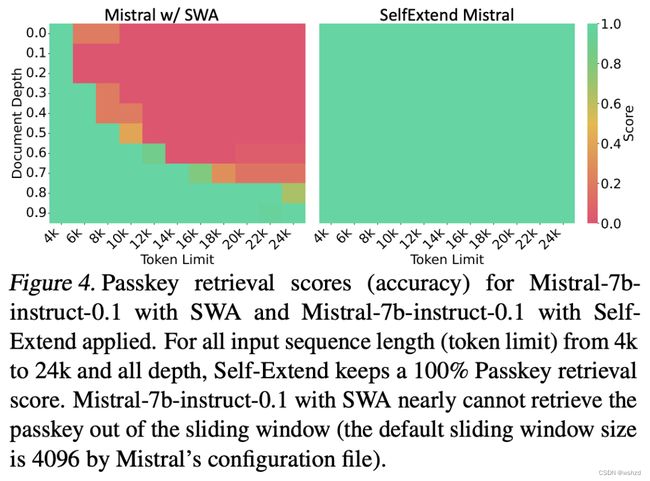
结果如图4所示。我们可以看到,在所有测试的深度和上下文长度中,无需任何微调,Self-Extend可以获得100%的密钥检索准确率。结果还表明:尽管Mistral w/SWA在其预训练上下文窗口之外具有较低的PPL,但它只能访问其滑动窗口内的信息(即密钥)。考虑到这项任务的简单性,这一结果强烈表明它仍然不具备处理长上下文的真正能力。
这主要是因为PPL是通过对许多tokens进行平均来计算的,并且只要大多数tokens都建模良好,PPL就不会很高。正如我们之前所讨论的,这与相邻token密切相关。来自相邻token(例如,滑动窗口中的令牌)的信息足以预测大多数令牌以及低PPL。
尽管如此,一些与理解长上下文和回答问题有关的重要表征可能无法很好地预测。
4.3 实际长上下文任务的表现
大多数现有的上下文长度扩展工作都依赖于语言建模(由PPL测量)和合成任务(如密钥检索)来测量LLM的真实长上下文能力。然而,这样的任务不能全面反映LLM的长上下文能力。密钥检索太容易了,LLM可能无法在低PPL的情况下很好地处理长上下文。
为了衡量长上下文性能,作者使用两个真实世界的长上下文评估基准进行评估:Longbench和L-Eval。结果如表2和表3所示:


在Longbench上,对于所有三个不同的基础模型和大多数数据集,应用Self-Extend后,与计数器部分相比,该模型可以获得显著的性能提升(SExt-Llama-2-7B-chat与Llama-2-7B-chat;SExt-Mistral-7B-in-0.1与Mistral7B-ins-0.1(w/SWA);SExt-SOLAR-10.5B-instruct-v1.0与SOLAR-10.5B-instruct-v1.0)。在一些数据集上,Self-Extend没有获得性能改进,例如MultiNews。作者认为这主要是因为这些数据集的长度没有那么长,例如,MultiNews的平均长度只有2k,或者像PassageCount这样的一些任务不适合测试这种大小的模型(即太具有挑战性)。此外,与许多经过微调的模型相比,Self-Extend具有相当甚至更好的性能。更具体地说:
Llama-2-7B:使用Self-Extend将Llama-2-7bchat的上下文窗口从4k扩展到16k和25k4,并使用两种不同的设置。他们两个都比Llama2-7b-chat要好得多。在HotpotQA等多个数据集上,它们的性能也比所有经过微调的同类产品更好。在其他方面,性能仍然具有可比性。考虑到vicuna良好的指令跟随能力,还将vicuna1.5-7B从4k扩展到16k和25k。它的微调对应物是vicuna1.5-7B 16k。同样,通过Self-Extend,vicuna1.5-7B比vicuna1.5-7B-16k好得多,它甚至是所有基于Llama-2-7B的型号中的顶级模型之一。在一些数据集上,观察到25k变体的性能不如16k变体。这是由于较大的上下文窗口和位置精度之间的权衡。通过更大的上下文窗口,模型可以访问更多信息。但同时,为了拥有更大的上下文窗口,Self-Extend需要更大的组大小,这意味着更粗略的位置信息,并且对模型有害。
Mistral-7B:将Mistral-7B的指令微调变体的上下文窗口扩展到16k。使用Mistral基线的默认设置,该基线已应用SWA。Self-Extend再次显著提高了Mistral的长上下文能力。从Mistral-7b进行了微调的MistralLite模型也获得更长的上下文窗口,并在大多数数据集上具有更好的性能。但其中许多数据集已包含在MistralLite的微调数据中,如NarrativeQA、Qasper等。
SOLAR-10.7B:SOLAR-10.75B是《SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling》最新发布的,它还没有针对上下文窗口扩展进行微调的变体,使用Self-Extend将其从4k扩展到16k,并获得了实质性的性能改进。
在LEval上,观察到了类似的结果。除了使用Mistral作为基本模型外,与一些微调的自由基线(如NTK)或进一步训练的基线(如Longchat1.5-7b-32k和Vicuna1.5-7b-32k)相比,Self-Extend几乎在所有数据集上都实现了卓越的性能。对于Mistral,作者怀疑较差的性能主要来自Prompt工程。与vanilla Mistral相比,MistralLite的性能要差得多。作者没有为Mistral做Prompt工程。
简单地说,对于这两个基准测试,即使与需要进一步微调的方法相比,Self-Extend也能实现相当或最佳的性能。尽管最初,作者只是期望Self-Extend可以比没有任何扩展方法的基本模型更好。考虑到Self-Extend仅在推理过程中生效,不进行任何微调或训练。这太令人惊讶了。通常,基于学习的方法比没有学习的方法具有更好的性能,不仅在上下文窗口扩展和LLM方面,而且在许多其他任务和NN方面。
4.4 短期任务的表现
理想的上下文长度扩展方法应该确保标准短上下文任务的性能不会降低。作者使用Hugging Face Open LLM Leaderboard来评估Self-Extend在五个公共基准任务上的表现。具体而言,使用25-shot ARC-Challenge、10-shot HellaSwag、5-shot MMLU、0-shot TruthfulQA和5-shot GSM8K。结果如表4所示。Self-Extend对这些短上下文任务几乎没有影响。
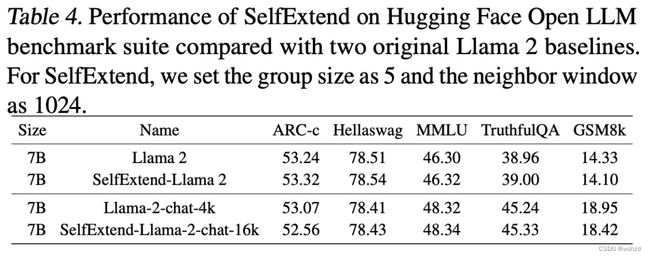
此外,由于所提出的Self-Extend不做任何微调,只在推理过程中生效,因此Self-Extend是插件式的,可以是动态的。这意味着当遇到短文本序列时,Self-Extend可以自动禁用。在参数不变的情况下,LLM可以在这些短上下文场景中保持其原始性能。尽管我们并不是有意获得这样的优势,但与其他基于微调的方法相比,这是Self-Extend的额外优势,因为这种方法通常在短上下文任务中会出现性能下降。
4.5 消融研究
作者还构建了一个实验来研究组大小G和相邻窗口![]() 的不同选择的影响。消融研究是在LEval的两个真实世界数据集上构建的:GSM100和Quality。GSM100没有那么长,它的平均长度为5.5k,最大长度为6k。Quality稍微长一些且平均长度7k,它的最大长度是8.5k。之所以不选择超长数据集,因为作者想覆盖较小的组大小(G)。当G=4,
的不同选择的影响。消融研究是在LEval的两个真实世界数据集上构建的:GSM100和Quality。GSM100没有那么长,它的平均长度为5.5k,最大长度为6k。Quality稍微长一些且平均长度7k,它的最大长度是8.5k。之所以不选择超长数据集,因为作者想覆盖较小的组大小(G)。当G=4, ![]() =2048时,使用Self-Extend的Llama-2-chat可以处理长度小于10k的序列。结果如下图5所示:
=2048时,使用Self-Extend的Llama-2-chat可以处理长度小于10k的序列。结果如下图5所示:

五、结论与讨论
在本文中,作者认为LLM本身具有处理长序列的固有能力,并且它应该能够在没有任何微调的情况下扩展上下文窗口大小。基于这一信念,以一种无需微调的方式,提出了Self-Extend,通过简单地将看不见的相对位置映射到通过FLOOR操作在预训练期间看到的相对位置,来引出LLM固有的长上下文能力。作者进行了深入的实验来研究SelfExtend的有效性,包括语言建模任务、合成密钥检索任务和两个真实世界的基准测试。尽管没有任何调整或进一步的训练,但所提出的自扩展可以有效地改善LLM的长期环境表演更令人惊讶的是,Self-Extend甚至在许多数据集上击败了现有的基于微调的方法。这些结果突出了LLM处理长时间上下文的潜力,并可能启发对LLM固有能力进行更深入的研究。
局限性:Self-Extend的局限性包括缺乏Flash Attention的实现,以及组大小过大导致的性能下降,这意味着当前的Self-Extend仍然无法将上下文窗口扩展到无穷大。同时,与许多常规任务一样,目前如何对长上下文任务进行评估还没有达成共识,这可能会导致评估结果出现问题。
展望:对于未来的工作,作者将实施Flash Attention来提高Self-Extend的效率。也会在使用其他位置编码的模型上测试Self-Extend。如果将来能够获得更多的计算资源,那么可以在更大的模型、更长的上下文和更具挑战性的任务上进行测试。同时,将考虑使用更复杂的映射方法来代替简单的FLOOR操作,以实现更好的长上下文理解能力和更长的扩展上下文窗口长度。
参考文献:
[1] https://simg.baai.ac.cn/paperfile/a34ae7f4-f0ce-4f8f-b8f2-e8e4d84bbee5.pdf