ES高级查询
ES中提供了一种强大的检索数据方式,这种检索方式称为Query DSL,这种方式的丰富查询语法让ES检索变得更强大,更简洁。
1.常见查询
1.1查询所有[match_all]
match_all关键字:返回索引中的全部文档。
GET /products/_search
{
"query": {
"match_all": {}
}
}

1.2term基于关键词查询
注意:文档信息存储是按照字段的类型去分词,以分词后的结果来存储的。
1.在ES中除了text类型会分词,其余类型均不分词(如keyword、Integer、double、date、boolean),其完整的整个数据就是一个关键字/词。
2.在ES中默认使用的是标准分词器,中文是单字分词,英文是单词分词。
GET /products/_search
{
"query": {
"term": {
"description": { #字段
"value": "很"
}
}
}
}

1.3range范围查询
GET /products/_search
{
"query": {
"range": {
"price": { #字段
"gte": 10, #gt表示>,gte表示>=
"lte": 20 #lt表示<,lte表示<=
}
}
}
}
1.4prefix前缀查询

1.5wildcard查询
?可以匹配一个字符,而*可以匹配多个字符
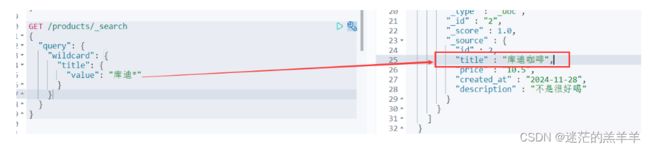
1.6多id查询[ids]
用一组id获取多个对应的文档
GET /products/_search
{
"query": {
"ids": {
"values": [1,2]
}
}
}
1.7模糊查询[fuzzy]
fuzzy关键字:用来模糊查询含有指定关键字的文档
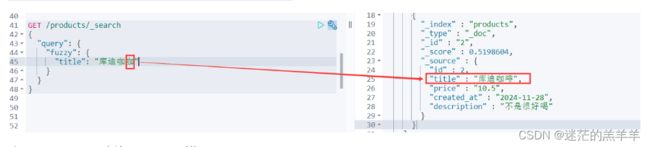
注意:fuzzy模糊查询 最大模糊错误必须在0-2之间
-
搜索关键词长度为2不允许存在模糊
-
搜索关键词长度为3-5允许一次模糊
-
搜索关键词长度大于5允许最大两次模糊
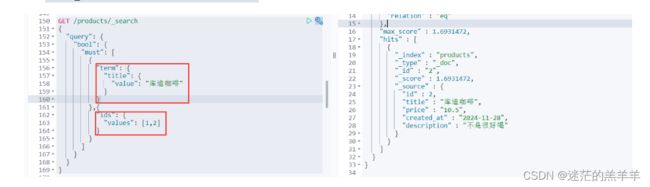
1.8布尔查询[bool]
bool关键字:用来组合多个条件实现复杂查询
-
must:相当于&&同时成立
-
should:相当于||成立一个就行
-
must_not:相当于!不能满足任何一个
2.多字段查询[multi_match]

注意:多字段查询时,query中的查询语句会根据fields中字段的类型先去分词之后再去查询,如果该字段不分词就会将整体作为条件进行查询。
比如先按照title来说,因为keyword类型是不分词的,所以会将"不是"整体作为title的条件去查,那肯定是查不到记录的。然后再看description,因为是text类型的,所以会分词,先分为"不"和"是",然后将这两个词分别作为description的条件去查,就能查到这一条记录。
3.默认字段分词查询[query_string]
就是先将查询条件按照设定的默认字段类型去分词,分完词后,作为字段的条件去查询。

因为title的类型keyword不分词,所以会直接将"库迪"作为条件去title中查询,那肯定是查询不到的。
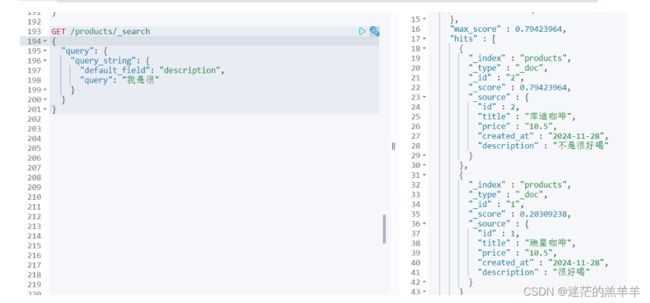
因为description的类型是text所以要分词,先将查询条件"我是很"分为"我"、"是"、"很"。在分别作为条件去description中查询,可以查询出来两条结果。
4.高亮显示highlight
注意:高亮只能用于可以分词的字段,即text。
GET /products/_search
{
"query": {
"query_string": {
"default_field": "description",
"query": "我是很"
}
},
"highlight": {
"pre_tags": [""], #开始标签
"post_tags": [""], #结束标签
"require_field_match": "false", #开启多字段高亮
"fields": {
"*":{}
}
}
}

5.返回条数等待[size]
size:指定查询结果中返回指定条数。默认返回值10条。
GET /products/_search
{
"query":{
"match_all":{}
},
"size":5
}
6.分页查询[from]
from:用来指定起始返回位置,和size关键字连用可实现分页效果。
GET /products/_search
{
"query":{
"match_all":{}
},
"from":0
"size":5,
}
7.指定字段排序[sort]
GET /products/_search
{
"query":{
"match_all":{}
},
"sort":[
{
"price":{
"order":"desc"
}
}
]
}
8.返回指定字段
_socre:是一个数组,在数组中用来指定展示哪些字段。
GET /products/_search
{
"query":{
"match_all":{}
},
"_source":["title","description"]
}