深度学习框架笔记
一、深度学习框架是什么?
1.1 说明
深度学习框架像Caffe、tensorflow,这些是深度学习的工具,简单来说就是库,编程时需要import caffe、import tensorflow。
作一个简单的比喻,一套深度学习框架就是这个品牌的一套积木,各个组件就是某个模型或算法的一部分,你可以自己设计如何使用积木去堆砌符合你数据集的积木。
1.2 应用优势
深度学习框架的出现降低了入门的门槛,你不需要从复杂的神经网络开始编代码,你可以依据需要,使用已有的模型,模型的参数你自己训练得到,你也可以在已有模型的基础上增加自己的layer,或者是在顶端选择自己需要的分类器和优化算法(比如常用的梯度下降法)。当然也正因如此,没有什么框架是完美的,就像一套积木里可能没有你需要的那一种积木,所以不同的框架适用的领域不完全一致。 总的来说深度学习框架提供了一些列的深度学习的组件(对于通用的算法,里面会有实现),当需要使用新的算法的时候就需要用户自己去定义,然后调用深度学习框架的函数接口使用用户自定义的。
1.3 关于组件
大部分深度学习框架都包含以下五个核心组件:
1. 张量(Tensor)
2. 基于张量的各种操作
3. 计算图(Computation Graph)
4. 自动微分(Automatic Differentiation)工具
5. BLAS、cuBLAS、cuDNN等拓展包
二、深度学习框架有哪些?

- 熟知有:
caffe,tensorflow,pytorch/caffe2,keras,mxnet,paddldpaddle,theano,cntk,tiny-dnn,deeplearning4j,matconvnet等
- 一个合格的深度学习算法工程师:得熟悉其中的3个以上吧
其中:
谷歌:TensorFlow
Facebook:pytorch
百度:Paddle Paddle
微软:CNTK
亚马逊的AWS:MXNet
华为:mindspore
一流科技:oneflow
旷世:MegEngine
清华:Jittor
- 学习
不应该停留在官方的demo上
- 而是要学会以下等全方位进行掌握:
- 从自定义数据的读取
- 自定义网络的搭建
- 模型的训练
- 模型的可视化
- 模型的测试与部署


深度学习系统通常有两种编程方式:
1.一种是声明式编程(declarative programming):
用户只需要声明要做什么,而具体执行则由系统完成。
以Caffe,TensorFlow的计算图为代表。
- 优点:
1.由于在真正开始计算的时候已经拿到了整个计算图,所以可以做一系列优化来提升性能。
2.实现辅助函数也容易。
例如对任何计算图都提供forward和backward函数
3.另外也方便对计算图进行可视化
将图保存到硬盘和从硬盘读取。
- 缺点:
1.debug很麻烦,
监视一个复杂的计算图中的某个节点的中间结果并不简单
2.逻辑控制也不方便。
2.一种是命令式编程(imperative programming):
以numpy,torch/pytorch为代表
每个语句按照原来的意思顺序执行。
- 优点:
1.语义上容易理解,灵活,可以精确控制行为。
2.通常可以无缝地和主语言交互,方便地利用主语言的各类算法,工具包,debug和性能调试器
- 缺点:实现统一的辅助函数和提供整体优化都很困难。
三、框架简介
3.1 caffe
- 伯克利的贾扬清主导开发,以C++/CUDA 代码为主
- 最早的深度学习框架之一,比 TensorFlow、Mxnet、Pytorch等都更早
- 需要进行编译安装。
- 支持命令行、Python和Matlab接口
- 单机多卡、多机多卡等都可以很方便的使用
- caffe的使用通常是下面的流程:

流程相互之间是解耦合的,所以caffe的使用非常优雅简单。
- 优点 & 缺点
- 优点:
1.以C++/CUDA/python代码为主,速度快,性能高。
2.工厂设计模式,代码结构清晰,可读性和拓展性强。
3.支持命令行、Python和Matlab接口,使用方便。
4.CPU和GPU之间切换方便,多GPU训练方便。
5.工具丰富,社区活跃。
- 缺点:
1.源代码修改门槛较高,需要实现前向反向传播,以及CUDA代码。
2.不支持自动求导。
3.不支持模型级并行,只支持数据级并行
4.不适合于非图像任务。
3.2 tensorflow
- Google brain推出的开源机器学习库
- 与Caffe一样,主要用作深度学习相关的任务
- 与Caffe相比TensorFlow的安装简单很多
- TensorFlow = Tensor + Flow
Tensor就是张量,代表N维数组,这与Caffe中的blob是类似的;Flow即流,代表基于数据流图的计算。
- 最大的特点是:计算图
即:先定义好图,然后进行运算 - 所以所有的TensorFlow代码,都包含两部分:
(1) 创建计算图
1.表示计算的数据流。
2.它做了什么呢?实际上就是定义好了一些操作,你可以将它看做是Caffe中的prototxt 的 定义过程。
(2)运行会话
1.执行图中的运算,可以看作是Caffe中的训练过程。
2.只是TensorFlow的会话比Caffe灵活很多,由于是Python接口,取中间结果分析,Debug 等方便很多
3.3 mxnet
- amazon的官方框架
- 它尝试将上面说的两种模式无缝的结合起来。
- 非常灵活,扩展性很强的框架
- 在命令式编程上
MXNet提供张量运算,进行模型的迭代训练和更新中的控制逻辑; - 在声明式编程中
MXNet支持符号表达式,用来描述神经网络,并利用系统提供的自动求导来训练模型
3.4 pytorch
- Pytorch = Python + Torch
Torch是纽约大学的一个机器学习开源框架- 几年前在学术界非常流行,包括Lecun等大佬都在使用
- 但是由于使用的是一种绝大部分人绝对没有听过的Lua语言,导致很多人都被吓退。
- 后来随着Python的生态越来越完善,Facebook人工智能研究院推出了
Pytorch并开源。
- Pytorch不是简单的封装 Torch 并提供Python 接口
- 而是对Tensor以上的所有代码进行了重构
- 同TensorFlow一样,增加了自动求导。
- 后来Caffe2全部并入Pytorch,如今已经成为了非常流行的框架。
- 很多最新的研究,如风格化、GAN等大多数采用Pytorch源码
-
特点:
- 动态图计算。
1.TensorFlow从静态图发展到了动态图机制Eager Execution
2.pytorch则一开始就是动态图机制。
3.动态图机制的好处就是随时随地修改,随处debug,没有类似编译的过程。
- 简单。
1.相比TensorFlow1.0中Tensor、Variable、Session等概念充斥,数据读取接口频繁更新,tf.nn、 tf.layers、tf.contrib各自重复
2.Pytorch则是从Tensor到Variable再到nn.Module
最新的Pytorch已经将Tensor和Variable合并
这分别就是从数据张量到网络的抽象层次的递进。
TensorFlow的设计是“make it complicated”,那么 Pytorch的设计就是“keep it simple”。
3.5 keras
-
Keras是一个非常流行、简单的深度学习框架 -
它的设计参考了
torch,用Python语言编写,是一个高度模块化的神经网络库 -
能够在
TensorFlow,CNTK或Theano之上运行 -
Keras的特点是能够快速实现模型的搭建,是高效地进行科学研究的关键
对小白用户非常友好而简单的深度学习框架
严格来说并不是一个开源框架,而是一个高度模块化的神经网络库。
- 特点:
- 高度模块化,搭建网络非常简洁。
- API很简单,具有统一的风格。
- 容易扩展,只需使用python添加新类和函数。
3.6 paddlepaddle
- google有tensorflow,facebook有pytorch,amazon有mxnet
- 作为国内机器学习的先驱,百度也有PaddlePaddle
- 其中Paddle即Parallel Distributed Deep Learning(并行分布式深度学习)
- 整体使用起来与tensorflow非常类似
- 特点:
- 性能也很不错,整体使用起来与tensorflow非常类似
- 拥有中文帮助文档,在百度内部也被用于推荐等任务。
- 另外,配套了一个可视化框架visualdl,与tensorboard也有异曲同工之妙。
- 国产框架为数不多的之一
3.7 其他
- 除了以上最常用的框架
- 还有
theano,cntk,tiny-dnn,deeplearning 4j,matconvnet等
3.7.1 CNTK
- 概述
1.微软开源的深度学习工具包
2.它通过有向图将神经网络描述为一系列计算步骤。
在有向图中,叶节点表示输入值或网络参数,而其他节点表示其输入上的矩阵运算。
3.CNTK允许用户非常轻松地实现和组合流行的模型
包括前馈DNN,卷积网络(CNN)和循环网络(RNN / LSTM)。
4.与目前大部分框架一样,实现了自动求导,利用随机梯度下降方法进行优化。
- 特点
- NTK性能较高,按照其官方的说法,比其他的开源框架性能都更高。
- 适合做语音,CNTK本就是微软语音团队开源的,自然是更合适做语音任务
- 使用RNN等模型,以及在时空尺度分别进行卷积非常容易。
3.7.2 Matconvnet
- 概述
- 不同于各类深度学习框架广泛使用的语言Python
- MatConvnet是用**
matlab作为接口语言的开源深度学习库**,底层语言是cuda。
- 特点
- 因为是在matlab下面,所以debug的过程非常的方便
- 因为本身就有很多的研究者一直都使用matlab语言,所以其实该语言的群体非常大。
3.7.3 Deeplearning4j
- 概述
- 不同于深度学习广泛应用的语言Python,
- DL4J是为
java和jvm编写的开源深度学习库,支持各种深度学习模型。
- 特点
- 最重要的特点是支持分布式,可以在Spark和Hadoop上运行
- 支持分布式CPU和GPU运行。
- DL4J是为商业环境,而非研究所设计的,因此更加贴近某些生产环境。
3.7.4 Chainer
- 概述
- chainer也是一个基于python的深度学习框架
- 能够轻松直观地编写复杂的神经网络架构,在日本企业中应用广泛。
- 特点
- 采用“
Define-by-Run”方案,即通过实际的前向计算动态定义网络。 - 更确切地说,chainer存储计算历史而不是编程逻辑
- pytorch的动态图机制思想主要就来源于chainer。
3.7.5 Lasagne/Theano
- 概述
- 其实就是封装了theano,后者是一个很老牌的框架
- 在2008年的时候就由Yoshua Bengio领导的蒙特利尔LISA组开源了。
- 特点
- 使用成本高,需要从底层开始写代码构建模型
- Lasagen对其进行了封装,使得theano使用起来更简单。
3.7.6 Darknet
- 概述
1. Darknet本身是Joseph Redmon为了Yolo系列开发的框架。
2. Joseph Redmon提出了Yolo v1,Yolo v2,Yolo v3。
- 特点
1. Darknet几乎没有依赖库
2. 从C和CUDA开始撰写的深度学习开源框架
3. 支持CPU和GPU
4. Darknet跟caffe颇有几分相似之处,却更加轻量级,非常值得学习使用。
四、学习Tips
4.1 选择
1.不管怎么说,tensorflow/pytorch你都必须会,这是目前开发者最喜欢,开源项目最丰富的两个框架。
2.如果你要进行移动端算法的开发,那么Caffe是不能不会的。
3.如果你非常熟悉Matlab,matconvnet你不应该错过。
4.如果你追求高效轻量,那么darknet和mxnet你不能不熟悉。
5.如果你很懒,想写最少的代码完成任务,那么用keras吧。
6.如果你是java程序员,那么掌握deeplearning4j没错的。
7.其他的框架,也自有它的特点,大家可以自己多去用用。
4.2 如何学习开源框架
- 要掌握好一个开源框架,通常需要做到以下几点:
- 熟练掌握 不同任务数据的准备和使用。
- 熟练掌握 模型的定义。
- 熟练掌握 训练过程和结果的可视化。
- 熟练掌握 训练方法和测试方法。
- 学习不应该停留在跑通官方的demo上,而是要解决实际的问题。
- 一个框架,官方都会开放有若干的案例
- 最常见的案例就是 以MNISI数据接口+预训练模型的形式,供大家快速获得结果
- 我们要学会从自定义数据读取接口,自定义网络的搭建,模型的训练,模型的可视化,模型的测试与部署等全方位进行掌握。
4.3 训练任务
- 所有框架的学习过程中,我们都要完成下面这个流程,只有这样,才能叫做真正的完成了一个训练任务。

- 所有的框架都可以使用同样的一个模型
- 网络结构:优化的时候根据不同的框架,采用了略有不同的方案。
五、百度百科
5.1 Pytorch

- PyTorch是一个开源的
Python机器学习库,基于Torch,用于自然语言处理等应用程序。 - 由Facebook人工智能研究院(FAIR)基于Torch推出了PyTorch。
- 两个高级功能:
- 具有强大的GPU加速的张量计算(如NumPy)。
- 包含自动求导系统的深度神经网络。
1. PyTorch的前身是Torch,其底层和Torch框架一样
2. 但是使用Python重新写了很多内容,不仅更加灵活,支持动态图,而且提供了Python接口。
3. 由Torch7团队开发,是一个以Python优先的深度学习框架,不仅能够实现强大的GPU加速,同时还支持动态神经网络。
4. PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。
- 优点:
- PyTorch是相当简洁且高效快速的框架
- 设计追求最少的封装
- 设计符合人类思维,它让用户尽可能地专注于实现自己的想法
- 与google的Tensorflow类似,FAIR的支持足以确保PyTorch获得持续的开发更新
- PyTorch作者亲自维护的论坛 : 供用户交流和求教问题
- 入门简单
- 环境搭建
- 根据PyTorch官网,对系统选择和安装方式等灵活选择即可。
- 这里以
anaconda为例。 - 需要说明的是:在1.2版本以后,Pytorch只支持**
cuda9.2**以上了,所以需要对cuda进行升级。
#默认 使用 cuda10.1
pip3 install torch===1.3.0 torchvision===0.4.1 -f https://download.pytorch.org/whl/torch_stable.
#cuda 9.2
pip3 install torch==1.3.0+cu92 torchvision==0.4.1+cu92 -f https://download.pytorch.org/whl/torch_stable.html
#cpu版本
pip3 install torch==1.3.0+cpu torchvision==0.4.1+cpu -f https://download.pytorch.org/whl/torch_stable.html
验证输入python 进入
import torchtorch.__version__# 得到结果'1.3.0'
5.2 TensorFlow

- TensorFlow是一个基于数据流编程(dataflow programming)的符号数学系统
- 被广泛应用于各类机器学习(machine learning)算法的编程实现
- 其前身是谷歌的神经网络算法库DistBelief
- Tensorflow拥有多层级结构
- 可部署于各类服务器、PC终端和网页并支持GPU和TPU高性能数值计算
- 被广泛应用于谷歌内部的产品开发和各领域的科学研究
- TensorFlow由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护
- 拥有包括TensorFlow Hub、TensorFlow Lite、TensorFlow Research Cloud在内的多个项目以及各类应用程序接口(Application Programming Interface, API)
- 自2015年11月9日起,TensorFlow依据阿帕奇授权协议(Apache 2.0 open source license)开放源代码
- 谷歌大脑自2011年——> 大规模深度学习应用研究 其早期工作即是TensorFlow的前身DistBelief
- DistBelief的功能是构建各尺度下的神经网络分布式学习和交互系统,也被称为“第一代机器学习系统”
- 2015年11月,在DistBelief的基础上,谷歌大脑完成了对“第二代机器学习系统”TensorFlow的开发并对代码开源。
- 相比于前作,TensorFlow在性能上有显著改进、构架灵活性和可移植性也得到增强
- 安装
TensorFlow支持多种客户端语言下的安装和运行。
截至版本1.12.0,绑定完成并支持版本兼容运行的语言为C和Python,
其它(试验性)绑定完成的语言为JavaScript、C++、Java、Go和Swift,依然处于开发阶段 的包括C#、Haskell、Julia、Ruby、Rust和Scala
- Python版本
- TensorFlow提供Python语言下的四个不同版本:CPU版本(tensorflow)、包含GPU加速的版本(tensorflow-gpu),以及它们的每日编译版本(tf-nightly、tf-nightly-gpu)。
- TensorFlow的Python版本支持Ubuntu 16.04、Windows 7、macOS 10.12.6 Sierra、Raspbian 9.0及对应的更高版本,其中macOS版不包含GPU加速
- 安装Python版TensorFlow可以使用模块管理工具pip/pip3 或anaconda并在终端直接运行。
pip install tensorflow
conda install -c conda-forge tensorflow
- 此外Python版TensorFlow也可以使用
Docker安装
docker pull tensorflow/tensorflow:latest
# 可用的tag包括latest、nightly、version等
# docker镜像文件:https://hub.docker.com/r/tensorflow/tensorflow/tags/
docker run -it -p 8888:8888 tensorflow/tensorflow:latest
# dock下运行jupyter notebook
docker run -it tensorflow/tensorflow bash
# 启用编译了tensorflow的bash环境
- 配置GPU
- TensorFlow支持在Linux和Window系统下使用统一计算架构(Compute Unified Device Architecture, CUDA)高于3.5的NVIDIA GPU
- 配置GPU时要求系统有**NVIDIA GPU驱动384.x及以上版本**、CUDA Toolkit和CUPTI(CUDA Profiling Tools Interface)9.0版本、cuDNN SDK7.2以上版本。
- 可选配置包括NCCL 2.2用于多GPU支持、TensorRT 4.0用于TensorFlow模型优化
- Linux系统下使用docker安装的Python版TensorFlow也可配置GPU加速且无需CUDA Toolkit
# 确认GPU状态
lspci | grep -i nvidia
# 导入GPU加速的TensorFlow镜像文件
docker pull tensorflow/tensorflow:latest-gpu
# 验证安装
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
# 启用bash环境
docker run --runtime=nvidia -it tensorflow/tensorflow:latest-gpu bash
- 组件与工作原理
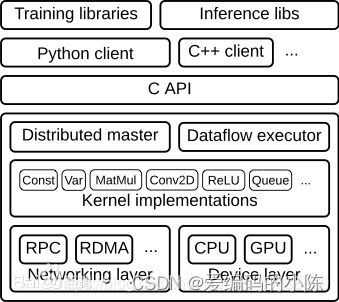
-
低阶API
- 张量(tf.Tensor)
- 张量是TensorFlow的核心数据单位
- 在本质上是一个任意维的数组。
- 可用的张量类型包括常数、变量、张量占位符和稀疏张量
- 一个对各类张量进行定义的例子:
在这里插入代码片import numpy as np
import tensorflow as tf
# tf.constant(value, dtype=None, name='Const', verify_shape=False)
tf.constant([0, 1, 2], dtype=tf.float32) # 定义常数
# tf.placeholder(dtype, shape=None, name=None)
tf.placeholder(shape=(None, 2), dtype=tf.float32) # 定义张量占位符
#tf.Variable(, name=)
tf.Variable(np.random.rand(1, 3), name='random_var', dtype=tf.float32) # 定义变量
# tf.SparseTensor(indices, values, dense_shape)
tf.SparseTensor(indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4]) # 定义稀疏张量
# tf.sparse_placeholder(dtype, shape=None, name=None)
tf.sparse_placeholder(dtype=tf.float32)
- 张量的秩是它的维数,而它的形状是一个整数元组,指定了数组中每个维度的长度
- 张量按NumPy数组的方式进行切片和重构
- 一个进行张量操作的例子:
在这里插入代码片import numpy as np
import tensorflow as tf
# tf.constant(value, dtype=None, name='Const', verify_shape=False)
tf.constant([0, 1, 2], dtype=tf.float32) # 定义常数
# tf.placeholder(dtype, shape=None, name=None)
tf.placeholder(shape=(None, 2), dtype=tf.float32) # 定义张量占位符
#tf.Variable(, name=)
tf.Variable(np.random.rand(1, 3), name='random_var', dtype=tf.float32) # 定义变量
# tf.SparseTensor(indices, values, dense_shape)
tf.SparseTensor(indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4]) # 定义稀疏张量
# tf.sparse_placeholder(dtype, shape=None, name=None)
tf.sparse_placeholder(dtype=tf.float32)
- 张量的秩是它的维数,而它的形状是一个整数元组,指定了数组中每个维度的长度
- 张量按NumPy数组的方式进行切片和重构
- 一个进行张量操作的例子:
# 定义二阶常数张量
a = tf.constant([[0, 1, 2, 3], [4, 5, 6, 7]], dtype=tf.float32)
a_rank = tf.rank(a) # 获取张量的秩
a_shape = tf.shape(a) # 获取张量的形状
b = tf.reshape(a, [4, 2]) # 对张量进行重构
# 运行会话以显示结果
with tf.Session() as sess:
print('constant tensor: {}'.format(sess.run(a)))
print('the rank of tensor: {}'.format(sess.run(a_rank)))
print('the shape of tensor: {}'.format(sess.run(a_shape)))
print('reshaped tensor: {}'.format(sess.run(b)))
# 对张量进行切片
print("tensor's first column: {}".format(sess.run(a[:, 0])))
参考链接:
1.深度学习框架究竟是什么?
2.【机器学习】深度学习框架是什么?有哪些?如何选择?
3.深度学习框架