7、【C++】单例模式/工厂模式
一、单例模式
单例模式,可以说设计模式中最常应用的一种模式了,据说也是面试官最喜欢的题目。但是如果没有学过设计模式的人,可能不会想到要去应用单例模式,面对单例模式适用的情况,可能会优先考虑使用全局或者静态变量的方式,这样比较简单,也是没学过设计模式的人所能想到的最简单的方式了。
一般情况下,我们建立的一些类是属于工具性质的,基本不用存储太多的跟自身有关的数据,在这种情况下,每次都去new一个对象,即增加了开销,也使得代码更加臃肿。其实,我们只需要一个实例对象就可以。如果采用全局或者静态变量的方式,会影响封装性,难以保证别的代码不会对全局变量造成影响。
考虑到这些需要,我们将默认的构造函数声明为私有的,这样就不会被外部所new了,甚至可以将析构函数也声明为私有的,这样就只有自己能够删除自己了。在Java和C#这样纯的面向对象的语言中,单例模式非常好实现,直接就可以在静态区初始化instance,然后通过getInstance返回,这种就被称为饿汉式单例类。也有些写法是在getInstance中new instance然后返回,这种就被称为懒汉式单例类,但这涉及到第一次getInstance的一个判断问题。
单线程中
Singleton* getInstance()
{
if (instance == NULL)
//饿汉式单例模式(直接在getInstance函数中new一个instance,然后返回)
instance = new Singleton();//懒汉式单例模式
return instance;
}
这样就可以了,保证只取得了一个实例。但是在多线程的环境下却不行了,因为很可能两个线程同时运行到if (instance == NULL)这一句,导致可能会产生两个实例。于是就要在代码中加锁。
Singleton* getInstance()
{
lock();
if (instance == NULL)
{
instance = new Singleton();
}
unlock();
return instance;
}
但这样写的话,会稍稍映像性能,因为每次判断是否为空都需要被锁定,如果有很多线程的话,就爱会造成大量线程的阻塞。于是大神们又想出了双重锁定。
Singleton* getInstance()
{
if (instance == NULL)
{
lock();
if (instance == NULL)
{
instance = new Singleton();
}
unlock();
}
return instance;
}
这样只够极低的几率下,通过越过了if (instance == NULL)的线程才会有进入锁定临界区的可能性,这种几率还是比较低的,不会阻塞太多的线程,但为了防止一个线程进入临界区创建实例,另外的线程也进去临界区创建实例,又加上了一道防御if (instance == NULL),这样就确保不会重复创建了。
常用的场景
单例模式常常与工厂模式结合使用,因为工厂只需要创建产品实例就可以了,在多线程的环境下也不会造成任何的冲突,因此只需要一个工厂实例就可以了。
优点:
1.减少了时间和空间的开销(new实例的开销)。
2.提高了封装性,使得外部不易改动实例。
缺点:
1.懒汉式是以时间换空间的方式。(在getInstance中new instance然后返回)
2.饿汉式是以空间换时间的方式。(在静态区初始化instance,然后通过getInstance返回)
【示例】饿汉单例模式
//Singleton.h
#ifndef _SINGLETON_H_
#define _SINGLETON_H_
class Singleton{
public:
static Singleton* getInstance();//声明静态成员函数
private:
Singleton();
//把复制构造函数和=操作符也设为私有,防止被复制
Singleton(const Singleton&);
Singleton& operator=(const Singleton&);
//在静态区定义并初始化实例
static Singleton* instance;//声明静态成员变量
};
#endif
//Singleton.cpp
#include "Singleton.h"
Singleton::Singleton(){
}
Singleton::Singleton(const Singleton&){
}
Singleton& Singleton::operator=(const Singleton&){
}
//定义并初始化静态成员变量
Singleton* Singleton::instance = new Singleton();
//定义静态成员函数
Singleton* Singleton::getInstance(){
return instance;
}
//main.cpp
#include "Singleton.h"
#include <stdio.h>
int main(){
Singleton* singleton1 = Singleton::getInstance();
Singleton* singleton2 = Singleton::getInstance();
if (singleton1 == singleton2)
fprintf(stderr,"singleton1 = singleton2\n");
return 0;
}
执行结果:
singleton1 = singleton2
二、工厂模式
C++的工厂模式分为三种:简单工厂模式、工厂模式和抽象工厂模式
一、简单工厂模式
简单工厂模式是工厂模式中最简单的一种,他可以用比较简单的方式隐藏创建对象的细节,一般只需要告诉工厂类所需要的类型,工厂类就会返回需要的产品类,但客户端看到的只是产品的抽象对象,无需关心到底是返回了哪个子类。客户端唯一需要知道的具体子类就是工厂子类。除了这点,基本是达到了依赖倒转原则的要求。
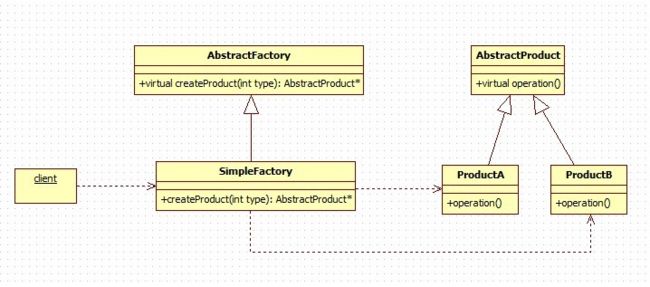
假如,我们不用工厂类,只用AbstractProduct和它的子类,那客户端每次使用不同的子类的时候都需要知道到底是用哪一个子类,当类比较少的时候还没什么问题,但是当类比较多的时候,管理起来就非常的麻烦了,就必须要做大量的替换,一个不小心就会发生错误。
而使用了工厂类之后,就不会有这样的问题,不管里面多少个类,我只需要知道类型号即可。不过,这里还有一个疑问,那就是如果我每次用工厂类创建的类型都不相同,这样修改起来的时候还是会出现问题,还是需要大量的替换。所以简单工厂模式一般应该于程序中大部分地方都只使用其中一种产品,工厂类也不用频繁创建产品类的情况。这样修改的时候只需要修改有限的几个地方即可。
常用的场景
例如部署多种数据库的情况,可能在不同的地方要使用不同的数据库,此时只需要在配置文件中设定数据库的类型,每次再根据类型生成实例,这样,不管下面的数据库类型怎么变化,在客户端看来都是只有一个AbstractProduct,使用的时候根本无需修改代码。提供的类型也可以用比较便于识别的字符串,这样不用记很长的类名,还可以保存为配置文件。
这样,每次只需要修改配置文件和添加新的产品子类即可。
所以简单工厂模式一般应用于多种同类型类的情况,将这些类隐藏起来,再提供统一的接口,便于维护和修改。
优点
1.隐藏了对象创建的细节,将产品的实例化推迟到子类中实现。
2.客户端基本不用关心使用的是哪个产品,只需要知道用哪个工厂就行了,提供的类型也可以用比较便于识别的字符串。
3.方便添加新的产品子类,每次只需要修改工厂类传递的类型值就行了。
4.遵循了依赖倒转原则。
缺点
1.要求产品子类的类型差不多,使用的方法名都相同,如果类比较多,而所有的类又必须要添加一种方法,则会是非常麻烦的事情。或者是一种类另一种类有几种方法不相同,客户端无法知道是哪一个产品子类,也就无法调用这几个不相同的方法。
2.每添加一个产品子类,都必须在工厂类中添加一个判断分支,这违背了开放-封闭原则。
【示例】
//AbstractProduct.h
#ifndef _ABSTRACTPRODUCT_H_
#define _ABSTRACTPRODUCT_H_
#include <stdio.h>
//抽象类
class AbstractProduct{
public:
AbstractProduct();
virtual ~AbstractProduct();
public:
virtual void operation() = 0