用js来实现那些数据结构12(散列表)
上一篇写了如何实现简单的Map结构,因为东西太少了不让上首页。好吧。。。
这一篇文章说一下散列表hashMap的实现。那么为什么要使用hashMap?hashMap又有什么优势呢?hashMap是如何检索数据的?我们一点一点的来解答。
在我们学习一门编程语言的时候,最开始学习的部分就是循环遍历。那么为什么要遍历呢?因为我们需要拿到具体的值,数组中我们要遍历数组获取所有的元素才能定位到我们想要的元素。对象也是一样,我们同样要遍历所有的对象元素来获取我们想要的指定的元素。那么无论是array也好,object也好,栈还是队列还是列表或者集合(我们前面学过的所有数据结构)都需要遍历。不然我们根本拿不到我们想要操作的具体的元素。但是这样就有一个问题,那就是效率。如果我们的数据有成百万上千万的数据。我们每一次循环遍历都会消耗大量的时间,用户体验可以说几乎没有。(当然,前端几乎不会遇到这种情况,因为大数据量的情况都通过分页来转化了)。
那么,有没有一种快速有效的定位我们想要的元素的数据结构呢?答案就是hashMap。当然,应该也有其它更高效的数据处理方式,但是我暂时不知道啊。。。。
那么hashMap是如何存取元素的呢?首先,hashMap在存储元素的时候,会通过lose lose散列函数来设置key,这样我们就无需遍历整个数据结构,就可以快速的定位到该元素的具体位置,从而获取到具体的值。
什么是lose lose散列函数呢?其实lose lose散列函数就是简单的把每个key中的所有字母的ASCII码值相加,生成一个数字,作为散列表的key。当然,这种方法并不是很好,会生成很多相同的散列值。下面会具体的讲解如何解决,以及一种更好的散列函数djb2。
那么我们开始实现我们的hashMap:
// 这里我们没在重复的去写clear,size等其他的方法,因为跟前面实在是没啥区别。
function HashMap() {
// 我们使用数组来存储元素
var list = [];
//转换散列值得loselose散列函数。
var loseloseHashCode = function (key) {
var hash = 0;
// 遍历字符串key的长度,注意,字符串也是可以通过length来获取每一个字节的。
for(var i = 0; i < key.length; i ) {
hash = key.charCodeAt(i)
}
//对hash取余,这是为了得到一个比较小的hash值,
//但是这里取余的对象又不能太大,要注意
return hash % 37;
}
//通过loselose散列函数直接在计算出来的位置放入对应的值。
this.put = function (key,value) {
var position = loseloseHashCode(key);
console.log(position "-" key);
list[position] = value;
}
//同样的,我们想要得到一个值,只要通过散列函数计算出位置就可以直接拿到,无需循环
this.get = function (key) {
return list[loseloseHashCode(key)];
}
//这里要注意一下,我们的散列表是松散结构,也就是说散列表内的元素并不是每一个下标index都一定是有值,
//比如我存储两个元素,一个计算出散列值是14,一个是20,那么其余的位置仍旧是存在的,我们不能删除它,因为一旦删除,我们存储元素的位置也会改变。
//所以这里要移除一个元素,只要为其赋值为undefined就可以了。
this.remove = function (key) {
list[loseloseHashCode(key)] = undefined;
}
this.print = function () {
for(var i = 0; i < list.length; i ) {
// 大家可以把这里的判断去掉,看看到底是不是松散的数组结构。
if(list[i] !== undefined) {
console.log(i ":" list[i]);
}
}
}
}
//那么我们来测试一下我们的hashMap
var hash = new HashMap();
hash.put("Gandalf",'www.gandalf.com');
hash.put("John",'www.john.com');
hash.put("Tyrion",'www.tyrion.com');
//因为我们在put代码中加了一个console以便我们更好的理解代码,我们看一下输出
// 19-Gandalf
// 29-John
// 16-Tyrion
console.log(hash.get('John'));//www.john.com
console.log(hash.get("Zaking"));//undefined
//那么我们来移除一个元素John
hash.remove("John");
console.log(hash.get("John"));//undefined那么我们就实现并且简单测试了一下我们自定义的hashMap,发现还不错哦。但是元素太少,没有代表性。我们再多测试几个数据看看会如何?
var conflictHash = new HashMap();
conflictHash.put("Gandalf",'www.Gandalf.com');//19-Gandalf
conflictHash.put("John",'www.John.com');//29-John
conflictHash.put("Tyrion",'www.Tyrion.com');//16-Tyrion
conflictHash.put("Aaron",'www.Aaron.com');//16-Aaron
conflictHash.put("Donnie",'www.Donnie.com');//13-Donnie
conflictHash.put("Ana",'www.Ana.com');//13-Ana
conflictHash.put("Jonathan",'www.Jonathan.com');//5-Jonathan
conflictHash.put("Jamie",'www.Jamie.com');//5-Jamie
conflictHash.put("Sue",'www.Sue.com');//5-Sue
conflictHash.put("Mindy",'www.Mindy.com');//32-Mindy
conflictHash.put("Paul",'www.Paul.com');//32-Paul
conflictHash.put("Nathan",'www.Nathan.com');//10-Nathan
conflictHash.print();
/*
5:www.Sue.com
10:www.Nathan.com
13:www.Ana.com
16:www.Aaron.com
19:www.Gandalf.com
29:www.John.com
32:www.Paul.com
*/我们发现后来的把前面相同散列值得元素给替换了。那么之前的元素也就随之丢失了,这绝不是我们想要看到的样子。这才十几个元素就有这么多相同的,如果数据量极大那还了得。。。这啥用没有啊。。。所以,我们需要解决这样的问题,我们这里介绍两种解决这种冲突的方法。分离链接和线性探查。
1、分离链接
分离链接,其实核心就是为散列表的每一个位置创建一个链表,并将元素存储在里面。它可以说是解决冲突的最简单的方法,但是,它占用了额外的存储空间。之前的例子,如果用分离链接来解决冲突的话,那么看起来就是这个样子。
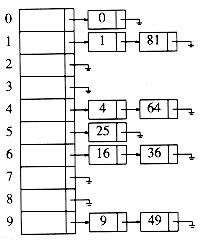
那么我们就需要重写hashMap,我们来看看分离链接下的hashMap是如何实现的。由于我们要重写hashMap类中的方法,所以我们重新构建一个新的类:SeparateHashMap。
function LinkedList() {//...链表方法}
// 创建分离链接法下的hashMap。
function SeparateHashMap () {
var list = [];
//loselose散列函数。
var loseloseHashCode = function (key) {
var hash = 0;
for(var i = 0; i < key.length; i ) {
hash = key.charCodeAt(i)
}
return hash % 37;
}
//这里为什么要创建一个新的用来存储键值对的构造函数?
//首先我们要知道的一点是,在分离链接下,我们元素所存储的位置实际上是在链表里面。
//而一旦在该散列位置下的链表中有多个值,我们仍旧需要通过key去找链表中所对应的元素。
//换句话说,分离链接下的存储方式是,首先通过key来计算散列值,然后把对应的key和value也就是ValuePair存入linkedList。
//这就是valuePair的作用了。
var ValuePair = function (key,value) {
this.key = key;
this.value = value;
this.toString = function () {
return "[" this.key "-" this.value "]";
}
}
//同样的,我们通过loselose散列函数计算出对应key的散列值。
this.put = function (key,value) {
var position = loseloseHashCode(key);
//这里如果该位置为undefined,说明这个位置没有链表,那么我们就新建一个链表。
if(list[position] == undefined) {
list[position] = new LinkedList();
}
//新建之后呢,我们就通过linkedList类的append方法把valuePair加入进去。
//那么如果上面的判断是false,也就是有了链表,直接跳过上面的判断执行加入操作就好了。
list[position].append(new ValuePair(key,value));
}
this.get = function (key) {
var position = loseloseHashCode(key);
//链表的操作前面相应的链表文章已经写的很清楚了。这里就尽量简单说清
//如果这个位置不是undefined,那么说明存在链表
if(list[position] !== undefined) {
//我们要拿到current,也就是链表中的第一个元素进行链表中的遍历。
var current = list[position].getHead();
//如果current.next不为null说明还有下一个
while(current.next) {
//如果要查找的key是当前链表元素的key,就返回该链表节点的value。
//这里要注意一下。current.element = ValuePair噢!
if(current.element.key === key) {
return current.element.value;
}
current = current.next;
}
//那么这里刚开始让我有些疑惑。为啥还要单独判断一下?
//我们回头看一下,我们while循环的条件是current.next。没current什么事啊...对了。
//所以,这里我们还要单独判断一下是不是current。
//总结一下,这段get方法的代码运行方式是从第一个元素的下一个开始遍历,如果到最后还没找到,就看看是不是第一个,如果第一个也不是,那就返回undefined。没找到想要得到元素。
if(current.element.key === key) {
return current.element.value;
}
}
return undefined;
}
//这个remove方法就不说了。跟get方法一模一样,get方法是在找到对应的值的时候返回该值的value,而remove方法是在找到该值的时候,重新赋值为undefined,从而移除它。
this.remove = function (key) {
var position = loseloseHashCode(key);
if(list[position] !== undefined) {
var current = list[position].getHead();
while(current.next) {
if(current.element.key === key) {
list[position].remove(current.element);
if(list[position].isEmpty()) {
list[position] = undefined;
}
return true;
}
current = current.next;
}
if(current.element.key === key) {
list[position].remove(current.element);
if(list[position].isEmpty()) {
list[position] = undefined;
}
return true;
}
}
return false;
};
this.print = function () {
for(var i = 0; i < list.length; i ) {
// 大家可以把这里的判断去掉,看看到底是不是松散的数组结构。
if(list[i] !== undefined) {
console.log(i ":" list[i]);
}
}
}
}
var separateHash = new SeparateHashMap();
separateHash.put("Gandalf",'www.Gandalf.com');//19-Gandalf
separateHash.put("John",'www.John.com');//29-John
separateHash.put("Tyrion",'www.Tyrion.com');//16-Tyrion
separateHash.put("Aaron",'www.Aaron.com');//16-Aaron
separateHash.put("Donnie",'www.Donnie.com');//13-Donnie
separateHash.put("Ana",'www.Ana.com');//13-Ana
separateHash.put("Jonathan",'www.Jonathan.com');//5-Jonathan
separateHash.put("Jamie",'www.Jamie.com');//5-Jamie
separateHash.put("Sue",'www.Sue.com');//5-Sue
separateHash.put("Mindy",'www.Mindy.com');//32-Mindy
separateHash.put("Paul",'www.Paul.com');//32-Paul
separateHash.put("Nathan",'www.Nathan.com');//10-Nathan
separateHash.print();
/*
5:[Jonathan-www.Jonathan.com]n[Jamie-www.Jamie.com]n[Sue-www.Sue.com]
10:[Nathan-www.Nathan.com]
13:[Donnie-www.Donnie.com]n[Ana-www.Ana.com]
16:[Tyrion-www.Tyrion.com]n[Aaron-www.Aaron.com]
19:[Gandalf-www.Gandalf.com]
29:[John-www.John.com]
32:[Mindy-www.Mindy.com]n[Paul-www.Paul.com]
*/
console.log(separateHash.get("Paul"));
/*
www.Paul.com
*/
console.log(separateHash.remove("Jonathan"));//true
separateHash.print();
/*
5:[Jamie-www.Jamie.com]n[Sue-www.Sue.com]
10:[Nathan-www.Nathan.com]
13:[Donnie-www.Donnie.com]n[Ana-www.Ana.com]
16:[Tyrion-www.Tyrion.com]n[Aaron-www.Aaron.com]
19:[Gandalf-www.Gandalf.com]
29:[John-www.John.com]
32:[Mindy-www.Mindy.com]n[Paul-www.Paul.com]
*/
其实,分离链接法,是在每一个散列值对应的位置上新建了一个链表以供重复的值可以存储,我们需要通过key分别在hashMap和linkedList中查找值,而linkedList中的查找仍旧是遍历。如果数据量很大,其实仍旧会耗费一些时间。但是当然,肯定要比数组等这样需要遍历整个数据结构的方式要效率的多。
下面我们来看看线性探查法。
2、线性探查
什么是线性探查呢?其实就是在hashMap中发生冲突的时候,将散列函数计算出的散列值 1,如果 1还是有冲突那么就 2。直到没有冲突为止。
其实分离链接和线性探查两种方法,多少有点时间换空间的味道。
我们还是来看代码。
function LinearHashMap () {
var list = [];
var loseloseHashCode = function (key) {
var hash = 0;
for(var i = 0; i < key.length; i ) {
hash = key.charCodeAt(i)
}
return hash % 37;
}
var ValuePair = function (key,value) {
this.key = key;
this.value = value;
this.toString = function () {
return "[" this.key "-" this.value "]";
}
}
this.put = function (key,value) {
var position = loseloseHashCode(key);
//同样的,若是没有值。就把该值存入
if(list[position] == undefined) {
list[position] = new ValuePair(key,value);
} else {
// 如果有值,那么久循环到没有值为止。
var index = position;
while(list[index] != undefined) {
index
}
list[index] = new ValuePair(key,value);
}
}
this.get = function (key) {
var position = loseloseHashCode(key);
if(list[position] !== undefined) {
if(list[position].key === key) {
return list[position].value;
} else {
var index = position;
while(list[index] === undefined || list[index].key !== key) {
index ;
}
if(list[index] .key === key) {
return list[index].value
}
}
}
return undefined;
}
this.remove = function (key) {
var position = loseloseHashCode(key);
if(list[position] !== undefined) {
if(list[position].key === key) {
list[index] = undefined;
} else {
var index = position;
while(list[index] === undefined || list[index].key !== key) {
index ;
}
if(list[index] .key === key) {
list[index] = undefined;
}
}
}
return undefined;
};
this.print = function () {
for(var i = 0; i < list.length; i ) {
// 大家可以把这里的判断去掉,看看到底是不是松散的数组结构。
if(list[i] !== undefined) {
console.log(i ":" list[i]);
}
}
}
}
var linearHash = new LinearHashMap();
linearHash.put("Gandalf",'www.Gandalf.com');//19-Gandalf
linearHash.put("John",'www.John.com');//29-John
linearHash.put("Tyrion",'www.Tyrion.com');//16-Tyrion
linearHash.put("Aaron",'www.Aaron.com');//16-Aaron
linearHash.put("Donnie",'www.Donnie.com');//13-Donnie
linearHash.put("Ana",'www.Ana.com');//13-Ana
linearHash.put("Jonathan",'www.Jonathan.com');//5-Jonathan
linearHash.put("Jamie",'www.Jamie.com');//5-Jamie
linearHash.put("Sue",'www.Sue.com');//5-Sue
linearHash.put("Mindy",'www.Mindy.com');//32-Mindy
linearHash.put("Paul",'www.Paul.com');//32-Paul
linearHash.put("Nathan",'www.Nathan.com');//10-Nathan
linearHash.print();
console.log(linearHash.get("Paul"));
console.log(linearHash.remove("Mindy"));
linearHash.print();
LinearHashMap与SeparateHashMap在方法上有着相似的实现。这里就不再浪费篇幅的去解释了,但是大家仍旧要注意其中的细节。比如说在位置的判断上的不同之处。
那么HashMap对于冲突的解决方法这里就介绍这两种。其实还有很多方法可以解决冲突,但是我觉得最好的办法就是让冲突的可能性变小。当然,无论是使用什么方法,冲突都是有可能存在的。
那么如何让冲突的可能性变小呢?很简单,就是让计算出的散列值尽可能的不重复。下面介绍一种比loselose散列函数更好一些的散列函数djb2。
var djb2HashCode = function(key) {
var hash = 5831;
for(var i = 0; i < key.length; i ) {
hash = hash * 33 key.charCodeAt(i);
}
return hash % 1013;
}大家可以把最开始实现的HashMap的loselose散列函数换成djb2。再去添加元素测试一下是否冲突的可能性变小了。
djb2散列函数中,首先用一个hash变量存储一个质数(只能被1和自身整除的数)。将hash与33相乘并加上当前迭代道德ASCII码值相加。最后对1013取余。就得到了我们想要的散列值。
到这里,hashMap就介绍完了。希望大家可以认真的去阅读查看。
最后,由于本人水平有限,能力与大神仍相差甚远,若有错误或不明之处,还望大家不吝赐教指正。非常感谢!
更多专业前端知识,请上 【猿2048】www.mk2048.com