2023 12.9~12.15
一、上周工作
继续OpenFWI中InversionNet相关代码,主要学习损失函数、优化器、tensorboard等内容。
二、本周计划
结束OpenFWI中InversionNet部分,如test、vis等,看论文。
三、完成情况
3.1 回顾前面
dataset、train部分
了解了warmup
3.2 test.py
3.2.1 lambda函数
1)lambda 函数的语法:
lambda [arg1 [,arg2,.....argn]]:expression[arg…] 是参数列表, expression 是一个参数表达式,表达式中出现的参数需要在[arg..]中有定义,并且表达式只能是单行的,只能有一个表达式。
2)lambda 特性
- lambda 函数是匿名函数
- lambda 函数有输入和输出:输入是传入到参数列表的值,输出是根据表达式expression计算得到的值。
- lambda 函数拥有自己的命名空间:不能访问自己参数列表之外或全局命名空间里的参数,只能完成非常简单的功能。
3.2.2 model.eval()
在模型中,我们通常会加上Dropout层和batch normalization层,在模型预测阶段,我们需要将这些层设置到预测模式,model.eval()则能一键解决,如果在预测的时候忘记使用model.eval(),会导致不一致的预测结果。
Dropout就是我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性(泛化可以理解为一种迁移学习的能力,大致可以理解为把从过去的经验中学习到的表示、知识和策略应用到新的领域,是大模型最被需要的能力。)更强,因为它不会太依赖某些局部的特征。
在测试时,应该用整个训练好的模型,因此不需要dropout。我们不会对神经元进行随机置0,这就导致预测值和训练值的大小是不一样的。因此,有两个解决办法:
- 在训练中,dropout后,对输出值进行rescale,就是每个神经元的输出值乘以1/(1-p)
- 在测试中,对每个神经元的输出乘以p
这样,使得在训练时和测试时每一层输入有大致相同的期望。
BN(batch normalization)是对数据的规范化,使每层的数据输入都保持在相近的范围内。
在训练时,由于是一个batch一个batch给模型投喂数据,模型只能计算当前batch的均值和方差,当所有的batch都投喂完成,模型对每个batch上的均值和方差做指数平均,来得到整个样本上的均值和方差的近似值。
在预测时,一般不必要去计算的均值和方差。因此会直接拿训练过程中对整个样本空间估算的均值和方差直接来用。
3.2.3 missing和std的添加
如果没有噪音等,速度模型的预测值就是模型的输出,直接调用 plot_velocity绘制速度模型的结果对比。
# 对test产生的速度模型进行绘图
def plot_velocity(output, target, path, vmin=None, vmax=None):
# 创建了一个大小为11(宽)*5(高)英寸画布,把这个画布赋值给变量fig,
# 同时在这个画布上创建了一个axes,把这个axes赋值给ax。两幅子图,排列方式为一行两列
fig, ax = plt.subplots(1, 2, figsize=(11, 5))
if vmin is None or vmax is None:
vmax, vmin = np.max(target), np.min(target)
# 如果你有两个图,那么ax是一个有两个元素ax[0],ax[1] 的list。ax[0]就对应第一个subplot的ax。
# matshow()可绘制矩阵的函数
im = ax[0].matshow(output, cmap=rainbow_cmap, vmin=vmin, vmax=vmax)
ax[0].set_title('Prediction', y=1.08)
ax[1].matshow(target, cmap=rainbow_cmap, vmin=vmin, vmax=vmax)
ax[1].set_title('Ground Truth', y=1.08)
for axis in ax:
# 设置x轴的刻度
axis.set_xticks(range(0, 70, 10))
# 设置x轴刻度上的标签
axis.set_xticklabels(range(0, 700, 100))
axis.set_yticks(range(0, 70, 10))
axis.set_yticklabels(range(0, 700, 100))
# 设置y/x轴的标签,即文本内容
axis.set_ylabel('Depth (m)', fontsize=12)
axis.set_xlabel('Offset (m)', fontsize=12)
# shrink参数用来缩小色条的宽度
fig.colorbar(im, ax=ax, shrink=0.75, label='Velocity(m/s)')
plt.savefig(path)
plt.close('all')
添加这两者,会调用plot_seismic,可视化地震数据之间的差异图
# 对test产生的地震数据及其之间差异进行绘图
def plot_seismic(output, target, path, vmin=-1e-5, vmax=1e-5):
# 三个子图 一行三列
fig, ax = plt.subplots(1, 3, figsize=(20, 5))
aspect = output.shape[1] / output.shape[0]
im = ax[0].matshow(target, aspect=aspect, cmap='gray', vmin=vmin, vmax=vmax)
ax[0].set_title('Ground Truth')
ax[1].matshow(output, aspect=aspect, cmap='gray', vmin=vmin, vmax=vmax)
ax[1].set_title('Prediction')
ax[2].matshow(output - target, aspect='auto', cmap='gray', vmin=vmin, vmax=vmax)
ax[2].set_title('Difference')
# for axis in ax:
# axis.set_xticks(range(0, 70, 10))
# axis.set_xticklabels(range(0, 1050, 150))
# axis.set_title('Offset (m)', y=1.1)
# axis.set_ylabel('Time (ms)', fontsize=12)
# fig.colorbar(im, ax=ax, shrink=1.0, pad=0.01, label='Amplitude')
fig.colorbar(im, ax=ax, shrink=0.75, label='Amplitude')
plt.savefig(path)
plt.close('all')
3.3 vis.py
3.3.1 Colormap
Colormap分ListedColormap和LinearSegmentedColormap两种,前一种存储特定的颜色(比如说红白黑三种),使用colors可以取出所有的RGBA色号值;后一种可能是渐变色无colors属性。matplotlib.colors.ListedColormap类用于从颜色列表创建colarmap对象,这对于直接索引到颜色表中很有用。
加载颜色的npy文件:np.load('rainbow256.npy')
用法:
class matplotlib.colors.ListedColormap(colors, name=’from_list’, N=None)参数:
- 颜色:它是Matplotlib颜色规格的数组或列表,或等于N x 3或N x 4浮点数组(N rgb或rgba值)
- 名称:它是一个可选参数,它接受一个字符串来标识颜色图。
- N:它是一个可选参数,它接受表示映射中条目数的整数值。它的默认值为“无”,其中颜色列表中的每个元素都有一个颜色表条目。如果N小于len(colors),则列表将在N处截断,而如果N大于len,则列表将重复进行扩展。
3.2.2 plt.subplots——基本绘图
fig, ax = plt.subplots(参数1,参数2,figsize = (a, b))

如果你的figure有subplot,那么每一个subplot就是一个axes。第一个参数是子图的行数,第二个参数是子图的列数,第三个参数是代表第一个子图,如果想要设置子图的宽度和高度可以在函数内加入figsize值。figsize用来设置图形的大小,a为图形的宽, b为图形的高,单位为英寸。Axis:xy坐标轴,每个坐标轴由竖线和数字组成的。
# 创建了一个大小为11(宽)*5(高)英寸画布,把这个画布赋值给变量fig,
# 同时在这个画布上创建了一个axes,把这个axes赋值给ax。两幅子图,排列方式为一行
fig, ax = plt.subplots(1, 2, figsize=(11, 5))
if vmin is None or vmax is None:
vmax, vmin = np.max(target), np.min(target)
# 如果你有两个图,那么ax是一个有两个元素ax[0],ax[1] 的list。ax[0]就对应第一个subplot的ax。
# matshow()可绘制矩阵的函数
im = ax[0].matshow(output, cmap=rainbow_cmap, vmin=vmin, vmax=vmax)
ax[0].set_title('Prediction', y=1.08)
ax[1].matshow(target, cmap=rainbow_cmap, vmin=vmin, vmax=vmax)
ax[1].set_title('Ground Truth', y=1.08)
for axis in ax:
# 设置x轴的刻度
axis.set_xticks(range(0, 70, 10))
# 设置x轴刻度上的标签
axis.set_xticklabels(range(0, 700, 100))
axis.set_yticks(range(0, 70, 10))
axis.set_yticklabels(range(0, 700, 100))
# 设置y/x轴的标签,即文本内容
axis.set_ylabel('Depth (m)', fontsize=12)
axis.set_xlabel('Offset (m)', fontsize=12)
3.3.3 Matplotlib颜色条
colorbar:即主图旁一个长条状的小图,能够辅助表示主图中 colormap 的颜色组成以及颜色与数值的对应关系。
常用参数介绍:
mappable:“可映射的”,要求是matplotlib.cm.ScalarMappable对象,能够向 colorbar 提供数据与颜色间的映射关系(即 colormap 和 normalization 信息)。主图中使用contourf、pcolormesh和imshow等二维绘图函数时返回的对象都是ScalarMappable的子类。cax:colorbar 本质上也是一种特殊的Axes,我们为了在画布上决定其位置、形状和大小,可以事先画出一个空Axes,然后将这个Axes提供给cax参数,那么这个空Axes就会变成 colorbar。ax:如果不直接为 colorbar 确定好位置,那么可以用ax参数指定 colorbar 依附于哪个Axes,接着 colorbar 会自动从这个Axes里“偷”一部分空间来作为自己的空间。orientation:指定 colorbar 的朝向,默认为垂直方向。类似的参数还有location。extend:设置是否在 colorbar 两端额外标出归一化范围外的颜色。如果 colormap 有设置过set_under和set_over,那么使用这两个颜色。ticks:指定 colorbar 的刻度位置,可以接受数值序列或Locator对象。format:指定 colorbar 的刻度标签的格式,可以接受格式字符串,例如'%.3f',或Formatter对象。label:整个 colorbar 的标签,类似于Axes的xlabel和ylabel。
shrink参数对比:shrink=0.75(左),shrink=0.75(右)
# shrink参数用来缩小色条的长度
fig.colorbar(im, ax=ax, shrink=0.75, label='Velocity(m/s)')

Matplotlib 系列:colorbar 的设置-CSDN博客
3.4 论文完成情况
还有一部分未完成
四、存在的主要问题(已解决)
问题1:dataset.py中 data = np.load(data_path)[:, :, ::self.sample_ratio, :] 为什么要写成这样,调试后发现[:, :, ::self.sample_ratio, :]等价于[:, :, ::1, :]等价于[:, :, :, :]还等价于去掉该部分内容,改写成其他形式不影响。
self.sample_ratio空间采样,如改为2,每隔两个点取一个值,相当于大小变为原来1/2。
问题2:train.py中加载数据集处,使用RandomSampler数据随机采样和直接使用shuffle=true性质一样吗?
自己想法如下:性质一样
当dataset类型是map style时, shuffle其实就是改变sampler的取值
- shuffle为默认值 False时,sampler是SequentialSampler,按顺序取样
- shuffle为True时,sampler是RandomSampler, 按随机取样
问题3:没有理解为什么要反归一化,做对比试验?or其他
——为了还原速度的值,在之前的处理中进行了归一化。
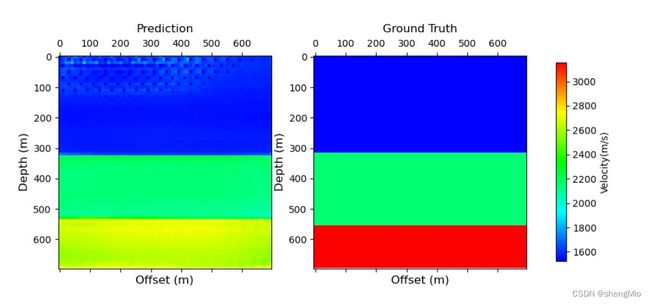
问题4:test的结果并不是特别理想,效果最好的一次是:只有分界限不是特别明显。下图结果为采用找到的官方给出的预训练模型进行训练测试出现的结果。
五、下一步计划
找到一篇与FWI相关 带有代码的论文进行研读