聊聊微服务环境中的可观察性和弹性
Kubernetes 简化了微服务的管理和扩展工作。但对于开发人员和运维团队而言,跟踪如此多的活动部件往往是一大挑战。弄清楚对系统进行了哪些变更,以及变更由谁所做这样的简单过程逐渐成了不可能完成的任务。获得清晰的可观察性以实现更好的监视和故障排除,是改进开发流程的关键所在。
聊聊分布式系统中的变更跟踪和挑战
我是 Itiel,Komodor 的首席技术官。今天,我将和你们讨论分布式系统中的变更跟踪,以及变更的阴暗面。Komodor 是一家初创公司,它建立了业内第一个 Kubernetes 原生的故障排除平台。
我是 DEV Empowerment 理念的信徒,这个理念的内容基本上就是快速前进和“测试左移”。在之前工作中,我曾在 eBay、Forter 和 Rookout 工作。我有很多后端和基础设施相关的经验。另外,我还是 Kubernetes 的忠实粉丝。
我首先要谈谈为什么要关心变更,以及哪些事物改变了你的环境。然后,我将尝试缩小范围,谈谈我所说的变更指的是什么,以及在当今的现代化环境中哪些变更具有极大风险。稍后,我将讨论为什么我们很难找出系统中发生了什么变化。我们将讨论变更跟踪的未来。最后,我将提供一些有用的提示,帮你减轻在今天的现代化系统中跟踪变更时遇到的种种痛苦。

为什么关心变更?
那么首先,你为什么要关心变更?我们提到了跟踪以及停机时间和微服务成本之类的东西。这些应该不是什么新鲜的话题,但对于某些公司来说,每个小时,甚至可以是每分钟都会出现问题。
谈到“问题”(issue),它的内涵是很丰富的,从整个系统的停机时间到阶段性的小问题,或者像是某个错误之类的问题都包含在里面。所有事件中有 85%可以追溯到某项系统变更,这意味着组织中某个地方有某人变更了某些内容,于是现在你的应用程序出现了问题。
我要说的是,大多数故障排除时间都在关注这个领域,就是找出根本原因。系统中发生的事情可能可以解释你当前遇到的症状成因。就像我说的那样,这些症状可能是完全停机或你的 UI 中出现的某个错误。
变更到底是什么?
我一直在谈变更这个词,但当我提到这个词时我真正的意思是什么?
我在这次演讲里会专门针对整个系统范围的变更。那么当提到变更和系统变更时,我真正的意思是什么呢?我说的是代码部署之类的东西,首先能想到的就是这个。还有基础设施变更,比如变更 AWS 上的安全组。
还有配置变更,开启关闭一些 flag,暗启动,在 Jenkins、ArgoCD 或其他类似的作业平台中拆分 IO 作业的变更;另外还有 DB、迁移、第三方变更。在这场讲座中,我不会讨论不同的用量或数据变更。
不管怎样,有的时候你的应用程序会停机,因为用户行为发生了变化。也许他们发送了其他类型的数据,或给你的系统发来了巨大的负载。但今天我不会讨论这些问题。就像我说的那样,大多数变更都源于系统变更,而不是这些变更类型。
希望你理解了我的意思,也许你已经知道这种变更都是很重要的。当你尝试解决一个问题时,你的角色就是侦探,并且基本上,你会尝试找出哪些变更可以解释,试着解释清楚你面对的问题。
为什么很难找到变更?
那么,为什么我们很难找到系统中发生了哪些变更呢?
因为今天的现代化技术栈(或者你可以将其称为干草堆)非常复杂。Chinmay 就总结得很好。它包括许多第三方服务,例如 Xero、你的云提供商以及数十种不同的 Rest API,你的应用程序需要这些 API 才能正常运行。
更重要的是,我们把过去那些巨大的单体分解为 Lambda、Kubernetes,分成了十几个、一百甚至数千个到处运行的小型微服务。更重要的是,变更频率已经发生了巨大变化,如今的组织(现代化的优秀组织)每天可以部署数百次甚至数千次。
这里我说的只不过是代码变更之类,但就像我们在上一张幻灯片中看到的那样,有很多变更实际上并没有被视为部署。可是它们实际上可以破坏你的整个系统,比如配置变更、标志等等。在过去,负责部署到生产中的人员通常是一些 IT 或运维人员。
可是在今天的现代化系统中,负责部署到生产环境的可能是开发人员。甚至产品经理现在都可以打开和关闭影响客户的各种功能标志。试图了解当今的现代化系统中发生的变更,基本上就像试图研究一个非常复杂的、不断变化的难题,还要弄清楚这个难题五分钟前是什么样子。
我尝试过,试着仔细研究故障排除面临的三大障碍之类的东西。一切事物都是互相连接的,而 Epsagon 这样的公司在分布式跟踪方面做了很出色的成果来应对这一局面。同时,一个微服务的变更可能会影响很多甚至与它不相关的微服务。
也许这种影响波及的甚至不是第一级的连接,而是第二、第三甚至第四级的连接。一项变更可能会对整个系统产生连锁反应。更重要的是,今天的许多变更都是在根本没有任何音频时钟的工具中完成的,或者这些音频时钟真的很难用得上。
AWS 就是一个很好的例子。每次你在 AWS 控制台中变更某项内容时,基本上这里都会有一些云托盘日志被审核。但几乎没有人使用它们,因为它们用起来太复杂了。而且其他许多变更(例如直接进入生产的变更)完全未经任何形式或方式的审核。
最后说一下,即使所有变更都经过了审核,Epsagon 也是帮助你理解各个连接的绝佳工具。为了真正了解哪些内容发生了变更,你需要打开数十种不同的工具来跟踪每个工具中的变更。
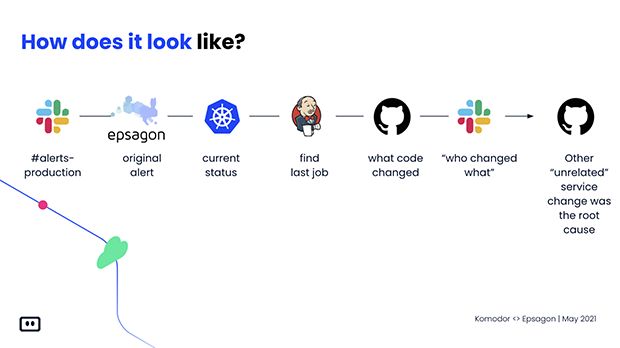
你需要专业知识;你需要具备打开所有这些不同工具并进行有效的故障排除的知识。今天的现代化系统中的故障排除大概是这个样子的。你在 Slack 上看到了警报,然后转至 Epsagon,它会高声提醒你,你的系统存在问题。
你去 Kubernetes 尝试弄清楚到底发生了什么。从 Kubernetes 出来,你进入 CI/CD 管道,想知道是谁部署到了生产环境。为什么?什么时候?然后你转向 Jenkins;从 Jenkins 出来,你试着追溯源码。源码在 GitHub 上,你转到 GitHub,你试图了解其中是否有任何与故障相关的提交,结果什么都没发现,一头雾水。
你问你的团队谁变更了什么内容?为什么?谁能帮助我解决现在面临的问题?到最后,你总算搞明白原来某个不相关的服务是所有这些故障的根本原因,你只是错过了这个连接,没注意到这个无关的 GitHub 部署或变更中的改动。
那么将来呢,情况会变好吗?简单来说,并不会。所有指标都指出,从现在开始情况只会变得更糟。
速度是越来越快了,今天就算是小公司每天也要向生产环境部署几十次。随着测试左移运动的兴起,开发团队也可以部署,产品经理也可以变更事物了。连 QA 现在都可以对你的生产环境做危险的变更,而且这些趋势不会很快结束。
而且,由于现代服务栈中的微服务用起来如此容易,系统变得越来越复杂。然后一切都变得越来越小,从微服务缩到了超微服务,诸如此类。而且各种事情只会变得更加复杂和分散。
因此,我们现在所看到的趋势会让人们更加难以理解系统中到底哪些变更可以解释系统遇到的种种问题。我知道这一切听起来都很糟糕,但是为了缓解这些风险,你可以做很多事情。
我不会一条条解释那十条要点,总之你需要做的第一件事,重要的是审核变更。审核可以自动进行,也可以专门写一个流程。如果没有审核,故障排除只会变得更加复杂。

原文链接:
https://komodor.com/blog/observability-and-resilience-in-microservices-based-environments/?fileGuid=YpxJxqQjG99vVr3r
- END -
推荐阅读:
揭秘 Uber API 网关的架构
NoSQL与关系型数据库全面对比
深入JDK中的Optional
HBase在京东人资数据预处理平台中的实践
互联网技术团队如何搭建自己的管理体系

关注我
学习架构知识
互联网后端架构
