挑战Transformer的新架构Mamba解析以及Pytorch复现
今天我们来详细研究这篇论文“Mamba:具有选择性状态空间的线性时间序列建模”

Mamba一直在人工智能界掀起波澜,被吹捧为Transformer的潜在竞争对手。到底是什么让Mamba在拥挤的序列建中脱颖而出?
在介绍之前先简要回顾一下现有的模型
Transformer:以其注意力机制而闻名,其中序列的任何部分都可以动态地与任何其他部分相互作用,特别是具有因果注意力机制的的Transformer,擅长处理序列中的单个元素。但是它们带来了显著的计算和内存成本,与序列长度的平方(L²)成比例。
循环神经网络(rnn): rnn只考虑当前输入和最后一个隐藏状态,按顺序更新隐藏状态。这种方法允许它们潜在地处理无限序列长度和恒定的内存需求。但是rnn的简单性是一个缺点,限制了它们记住长期依赖关系的能力。此外,rnn中的时间反向传播(BPTT)是内存密集型的,并且可能遭受梯度消失或爆炸的影响,尽管有LSTM等创新部分结解决了这个问题。
State Space Models(S4):这些模型已经显示出很好的特性。它们提供了一种平衡,比rnn更有效地捕获远程依赖关系,同时比transformer更高效地使用内存。
Mamba
选择性状态空间:Mamba建立在状态空间模型的概念之上,但引入了一个新的变化。它利用选择性状态空间,支持跨长序列更高效和有效地捕获相关信息。
线性时间复杂度:与Transformer不同,Mamba在序列长度方面以线性时间运行。这个属性使得它特别适合涉及非常长的序列的任务,而传统模型在这方面会遇到困难。
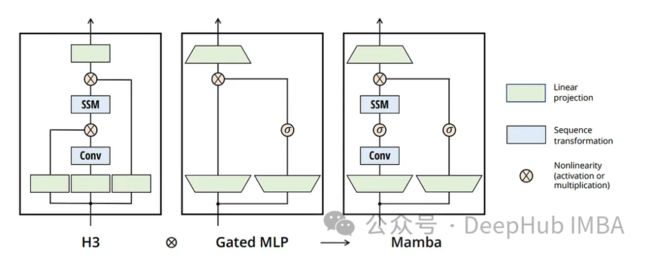
Mamba以其选择性状态空间的概念引入了传统状态空间模型的一个有趣的改进。这种方法稍微放松了标准状态空间模型的严格状态转换,使其更具适应性和灵活性(有点类似于lstm)。并且Mamba保留了状态空间模型的高效计算特性,使其能够在一次扫描中执行整个序列的前向传递-这一特性更让人想起Transformer。
在训练期间,Mamba的行为类似于Transformer,同时处理整个序列。而lstm必须一步一步地计算前向传递,即使所有输入都是已知的。在推理中,Mamba的行为更符合传统的循环模型,提供有效的序列处理。
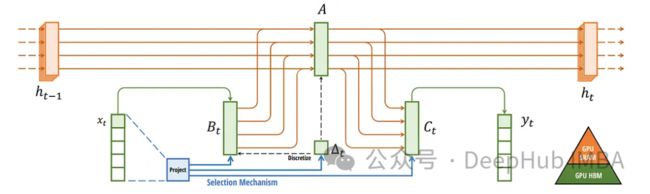
先验状态空间模型(ssm)的一个关键限制是其刚性的、输入不变的结构。这些模型为整个序列使用一组固定参数(我们称它们为a和B)。这种结构甚至比lstm等模型更具限制性,在lstm中,信号的转换可能依赖于先前的隐藏状态和输入。
Mamba则一种范式转换,即如何计算向下一个隐藏状态的过渡?在Mamba的体系结构中,转换依赖于当前输入,这种方法在传统ssm的固定计算和循环神经网络的输入依赖动态性之间取得了平衡。
主要组成如下:
固定主干:从一个隐藏状态到下一个隐藏状态的转换仍然是一个固定的计算(由a矩阵定义),允许跨序列的预计算。
输入相关转换:输入影响下一个隐藏状态(由B矩阵定义)的方式取决于当前输入,而不是之前的隐藏状态。与传统ssm相比,这种输入依赖性提供了更大的灵活性。

为了满足这种方法的计算需求,Mamba使用了一种硬件感知算法。该算法使用扫描操作而不是卷积来循环执行计算,这样在gpu上非常高效的。尽管输入依赖转换带来了算法复杂性,但这种效率对于保持高性能至关重要。
Mamba和选择性状态空间模型不是同义词。Mamba是一个使用选择性状态空间概念的实现。这种区别是至关重要的,因为它突出了Mamba的独特贡献:在保持计算效率的同时,使SSM框架更加灵活和响应输入。
SRAM和HBM
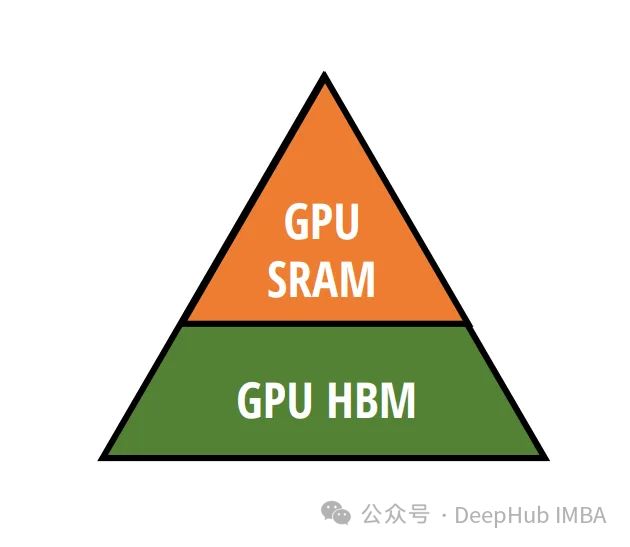
gpu包含两种主要类型的内存:HBM (High Bandwidth memory)和SRAM (Static Random-Access memory)。HBM虽然带宽很高,但与更快但更小的SRAM相比,它的访问时间相对较慢。Mamba则使用SRAM在矩阵乘法期间进行快速访问,这是其计算的关键。
计算中的主要瓶颈通常不是计算本身,而是数据在内存类型之间的移动。Mamba通过显著减少传输大量数据的需求来解决这个问题。它通过直接在SRAM中执行算法的关键部分(如离散化和递归计算)来实现,从而减少延迟。
还引入了一个融合选择扫描层,使其内存需求与使用flash attention的优化Transformer实现相当。这一层对于保持效率至关重要,尤其是在处理模型中依赖于输入的元素时。
结果
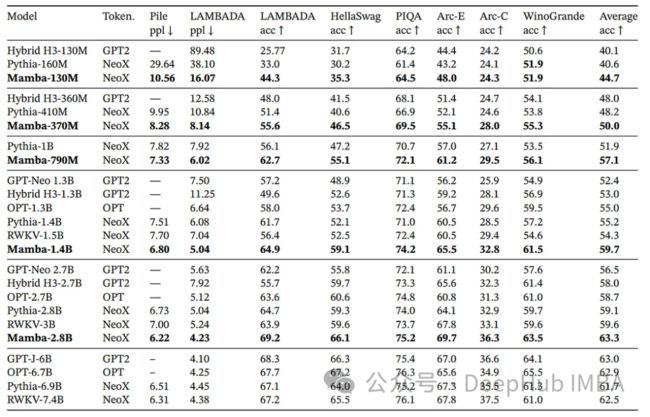
Mamba代表了序列建模的重大进步,特别是在其高效使用GPU内存和计算策略方面。它具有高效率处理长序列的能力,使其成为各种应用的有前途的模型,我们下面来使用Pytorch代码来对其进复现。
Pytorch复现
导入基本库
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torch.nn import functional as F
from einops import rearrange
from tqdm import tqdm
import math
import os
import urllib.request
from zipfile import ZipFile
from transformers import AutoTokenizer
torch.autograd.set_detect_anomaly(True)
设置标志和超参数
# Configuration flags and hyperparameters
USE_MAMBA = 1
DIFFERENT_H_STATES_RECURRENT_UPDATE_MECHANISM = 0
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
定义超参数和初始化
d_model = 8
state_size = 128 # Example state size
seq_len = 100 # Example sequence length
batch_size = 256 # Example batch size
last_batch_size = 81 # only for the very last batch of the dataset
current_batch_size = batch_size
different_batch_size = False
h_new = None
temp_buffer = None
这里的超参数,如模型维度(d_model)、状态大小、序列长度和批大小。
S6模块是Mamba架构中的一个复杂组件,负责通过一系列线性变换和离散化过程处理输入序列。它在捕获序列的时间动态方面起着关键作用,这是序列建模任务(如语言建模)的一个关键方面。这里包括张量运算和自定义离散化方法来处理序列数据的复杂需求。
classS6(nn.Module):
def__init__(self, seq_len, d_model, state_size, device):
super(S6, self).__init__()
self.fc1=nn.Linear(d_model, d_model, device=device)
self.fc2=nn.Linear(d_model, state_size, device=device)
self.fc3=nn.Linear(d_model, state_size, device=device)
self.seq_len=seq_len
self.d_model=d_model
self.state_size=state_size
self.A=nn.Parameter(F.normalize(torch.ones(d_model, state_size, device=device), p=2, dim=-1))
nn.init.xavier_uniform_(self.A)
self.B=torch.zeros(batch_size, self.seq_len, self.state_size, device=device)
self.C=torch.zeros(batch_size, self.seq_len, self.state_size, device=device)
self.delta=torch.zeros(batch_size, self.seq_len, self.d_model, device=device)
self.dA=torch.zeros(batch_size, self.seq_len, self.d_model, self.state_size, device=device)
self.dB=torch.zeros(batch_size, self.seq_len, self.d_model, self.state_size, device=device)
# h [batch_size, seq_len, d_model, state_size]
self.h=torch.zeros(batch_size, self.seq_len, self.d_model, self.state_size, device=device)
self.y=torch.zeros(batch_size, self.seq_len, self.d_model, device=device)
defdiscretization(self):
self.dB=torch.einsum("bld,bln->bldn", self.delta, self.B)
self.dA=torch.exp(torch.einsum("bld,dn->bldn", self.delta, self.A))
returnself.dA, self.dB
defforward(self, x):
# Algorithm 2 MAMBA paper
self.B=self.fc2(x)
self.C=self.fc3(x)
self.delta=F.softplus(self.fc1(x))
self.discretization()
ifDIFFERENT_H_STATES_RECURRENT_UPDATE_MECHANISM:
globalcurrent_batch_size
current_batch_size=x.shape[0]
ifself.h.shape[0] !=current_batch_size:
different_batch_size=True
h_new= torch.einsum('bldn,bldn->bldn', self.dA, self.h[:current_batch_size, ...]) +rearrange(x, "b l d -> b l d 1") *self.dB
else:
different_batch_size=False
h_new= torch.einsum('bldn,bldn->bldn', self.dA, self.h) +rearrange(x, "b l d -> b l d 1") *self.dB
# y [batch_size, seq_len, d_model]
self.y=torch.einsum('bln,bldn->bld', self.C, h_new)
globaltemp_buffer
temp_buffer=h_new.detach().clone() ifnotself.h.requires_gradelseh_new.clone()
returnself.y
else:
# h [batch_size, seq_len, d_model, state_size]
h=torch.zeros(x.size(0), self.seq_len, self.d_model, self.state_size, device=x.device)
y=torch.zeros_like(x)
h= torch.einsum('bldn,bldn->bldn', self.dA, h) +rearrange(x, "b l d -> b l d 1") *self.dB
# y [batch_size, seq_len, d_model]
y=torch.einsum('bln,bldn->bld', self.C, h)
returny
这个S6的模块,可以处理离散化过程和正向传播。
MambaBlock类是一个定制的神经网络模块,被设计为Mamba模型的关键构建块。它封装了几个层和操作来处理输入数据。
包括线性投影、卷积、激活函数、自定义S6模块和残差连接。该块是Mamba模型的基本组件,负责通过一系列转换处理输入序列,以捕获数据中的相关模式和特征。这些不同层和操作的组合允许MambaBlock有效地处理复杂的序列建模任务。
classMambaBlock(nn.Module):
def__init__(self, seq_len, d_model, state_size, device):
super(MambaBlock, self).__init__()
self.inp_proj=nn.Linear(d_model, 2*d_model, device=device)
self.out_proj=nn.Linear(2*d_model, d_model, device=device)
# For residual skip connection
self.D=nn.Linear(d_model, 2*d_model, device=device)
# Set _no_weight_decay attribute on bias
self.out_proj.bias._no_weight_decay=True
# Initialize bias to a small constant value
nn.init.constant_(self.out_proj.bias, 1.0)
self.S6=S6(seq_len, 2*d_model, state_size, device)
# Add 1D convolution with kernel size 3
self.conv=nn.Conv1d(seq_len, seq_len, kernel_size=3, padding=1, device=device)
# Add linear layer for conv output
self.conv_linear=nn.Linear(2*d_model, 2*d_model, device=device)
# rmsnorm
self.norm=RMSNorm(d_model, device=device)
defforward(self, x):
"""
x_proj.shape = torch.Size([batch_size, seq_len, 2*d_model])
x_conv.shape = torch.Size([batch_size, seq_len, 2*d_model])
x_conv_act.shape = torch.Size([batch_size, seq_len, 2*d_model])
"""
# Refer to Figure 3 in the MAMBA paper
x=self.norm(x)
x_proj=self.inp_proj(x)
# Add 1D convolution with kernel size 3
x_conv=self.conv(x_proj)
x_conv_act=F.silu(x_conv)
# Add linear layer for conv output
x_conv_out=self.conv_linear(x_conv_act)
x_ssm=self.S6(x_conv_out)
x_act=F.silu(x_ssm) # Swish activation can be implemented as x * sigmoid(x)
# residual skip connection with nonlinearity introduced by multiplication
x_residual=F.silu(self.D(x))
x_combined=x_act*x_residual
x_out=self.out_proj(x_combined)
returnx_out
MambaBlock是Mamba核心功能
Mamba模型
包括一系列MambaBlock模块。每个块都顺序处理输入数据,一个块的输出作为下一个块的输入。这种顺序处理允许模型捕获输入数据中的复杂模式和关系,使其对涉及顺序建模的任务有效。多个块的堆叠是深度学习架构中的常见设计,因为它使模型能够学习数据的分层表示。
classMamba(nn.Module):
def__init__(self, seq_len, d_model, state_size, device):
super(Mamba, self).__init__()
self.mamba_block1=MambaBlock(seq_len, d_model, state_size, device)
self.mamba_block2=MambaBlock(seq_len, d_model, state_size, device)
self.mamba_block3=MambaBlock(seq_len, d_model, state_size, device)
defforward(self, x):
x=self.mamba_block1(x)
x=self.mamba_block2(x)
x=self.mamba_block3(x)
returnx
RMSNorm是一个自定义规范化层,这一层用于规范神经网络的激活,这可以帮助稳定和加快训练。
classRMSNorm(nn.Module):
def__init__(self,
d_model: int,
eps: float=1e-5,
device: str='cuda'):
super().__init__()
self.eps=eps
self.weight=nn.Parameter(torch.ones(d_model, device=device))
defforward(self, x):
output=x*torch.rsqrt(x.pow(2).mean(-1, keepdim=True) +self.eps) *self.weight
returnoutput
这一层的用法:
x=torch.rand(batch_size, seq_len, d_model, device=device)
# Create the Mamba model
mamba=Mamba(seq_len, d_model, state_size, device)
# rmsnorm
norm=RMSNorm(d_model)
x=norm(x)
# Forward pass
test_output=mamba(x)
print(f"test_output.shape = {test_output.shape}") # Should be [batch_size, seq_len, d_model]
上面就是模型的全部基本代码,下面就可以进行数据准备和训练
我们自定义一个Enwiki8Dataset
classEnwiki8Dataset(Dataset):
def__init__(self, data):
self.data=data
def__len__(self):
returnlen(self.data['input_ids'])
def__getitem__(self, idx):
item= {key: val[idx].clone().detach() forkey, valinself.data.items()}
returnitem
pad_sequences_3d用于将一批序列填充到统一的长度,确保批中的每个序列具有相同数量的元素(或时间步长)。这在许多机器学习任务中尤其重要,因为输入数据必须具有一致的形状。
# Define a function for padding
defpad_sequences_3d(sequences, max_len=None, pad_value=0):
# Assuming sequences is a tensor of shape (batch_size, seq_len, feature_size)
batch_size, seq_len, feature_size=sequences.shape
ifmax_lenisNone:
max_len=seq_len+1
# Initialize padded_sequences with the pad_value
padded_sequences=torch.full((batch_size, max_len, feature_size), fill_value=pad_value, dtype=sequences.dtype, device=sequences.device)
# Pad each sequence to the max_len
padded_sequences[:, :seq_len, :] =sequences
returnpadded_sequences
训练过程还是传统的pytorch过程:
deftrain(model, tokenizer, data_loader, optimizer, criterion, device, max_grad_norm=1.0, DEBUGGING_IS_ON=False):
model.train()
total_loss=0
forbatchindata_loader:
optimizer.zero_grad()
input_data=batch['input_ids'].clone().to(device)
attention_mask=batch['attention_mask'].clone().to(device)
target=input_data[:, 1:]
input_data=input_data[:, :-1]
# Pad all the sequences in the batch:
input_data=pad_sequences_3d(input_data, pad_value=tokenizer.pad_token_id)
target=pad_sequences_3d(target, max_len=input_data.size(1), pad_value=tokenizer.pad_token_id)
ifUSE_MAMBA:
output=model(input_data)
loss=criterion(output, target)
loss.backward(retain_graph=True)
forname, paraminmodel.named_parameters():
if'out_proj.bias'notinname:
# clip weights but not bias for out_proj
torch.nn.utils.clip_grad_norm_(param, max_norm=max_grad_norm)
ifDEBUGGING_IS_ON:
forname, parameterinmodel.named_parameters():
ifparameter.gradisnotNone:
print(f"{name} gradient: {parameter.grad.data.norm(2)}")
else:
print(f"{name} has no gradient")
ifUSE_MAMBAandDIFFERENT_H_STATES_RECURRENT_UPDATE_MECHANISM:
model.S6.h[:current_batch_size, ...].copy_(temp_buffer)
optimizer.step()
total_loss+=loss.item()
returntotal_loss/len(data_loader)
评估函数也是一样:
defevaluate(model, data_loader, criterion, device):
model.eval()
total_loss=0
withtorch.no_grad():
forbatchindata_loader:
input_data=batch['input_ids'].clone().detach().to(device)
attention_mask=batch['attention_mask'].clone().detach().to(device)
target=input_data[:, 1:]
input_data=input_data[:, :-1]
# Pad all the sequences in the batch:
input_data=pad_sequences_3d(input_data, pad_value=tokenizer.pad_token_id)
target=pad_sequences_3d(target, max_len=input_data.size(1), pad_value=tokenizer.pad_token_id)
ifUSE_MAMBA:
output=model(input_data)
loss=criterion(output, target)
total_loss+=loss.item()
returntotal_loss/len(data_loader)
最后,calculate_perplexity用于评估语言模型(如Mamba)的性能。
defcalculate_perplexity(loss):
returnmath.exp(loss)
load_enwiki8_dataset函数用于下载和提取enwiki8数据集,该数据集通常用于对语言模型进行基准测试。
defload_enwiki8_dataset():
print(f"Download and extract enwiki8 data")
url="http://mattmahoney.net/dc/enwik8.zip"
urllib.request.urlretrieve(url, "enwik8.zip")
withZipFile("enwik8.zip") asf:
data=f.read("enwik8").decode("utf-8")
returndata
encode_dataset函数设计用于标记和编码数据集,为神经网络模型(如Mamba)处理数据集做准备。
# Tokenize and encode the dataset
defencode_dataset(tokenizer, text_data):
defbatch_encode(tokenizer, text_data, batch_size=1000):
# Tokenize in batches
batched_input_ids= []
foriinrange(0, len(text_data), batch_size):
batch=text_data[i:i+batch_size]
inputs=tokenizer(batch, add_special_tokens=True, truncation=True,
padding='max_length', max_length=seq_len,
return_tensors='pt')
batched_input_ids.append(inputs['input_ids'])
returntorch.cat(batched_input_ids)
# Assuming enwiki8_data is a list of sentences
input_ids=batch_encode(tokenizer, enwiki8_data)
# vocab_size is the number of unique tokens in the tokenizer's vocabulary
globalvocab_size
vocab_size=len(tokenizer.vocab) # Note that for some tokenizers, we might access the vocab directly
print(f"vocab_size = {vocab_size}")
# Create an embedding layer
# embedding_dim is the size of the embedding vectors (MAMBA model's D)
embedding_layer=nn.Embedding(num_embeddings=vocab_size, embedding_dim=d_model)
# Pass `input_ids` through the embedding layer
# This will change `input_ids` from shape [B, L] to [B, L, D]
defbatch_embedding_calls(input_ids, embedding_layer, batch_size=256):
# Check if input_ids is already a tensor, if not convert it
ifnotisinstance(input_ids, torch.Tensor):
input_ids=torch.tensor(input_ids, dtype=torch.long)
# Calculate the number of batches needed
num_batches=math.ceil(input_ids.size(0) /batch_size)
# List to hold the output embeddings
output_embeddings= []
# Process each batch
foriinrange(num_batches):
# Calculate start and end indices for the current batch
start_idx=i*batch_size
end_idx=start_idx+batch_size
# Get the batch
input_id_batch=input_ids[start_idx:end_idx]
# Call the embedding layer
withtorch.no_grad(): # No need gradients for this operation
batch_embeddings=embedding_layer(input_id_batch)
# Append the result to the list
output_embeddings.append(batch_embeddings)
# Concatenate the embeddings from each batch into a single tensor
all_embeddings=torch.cat(output_embeddings, dim=0)
returnall_embeddings
# `input_ids` is a list or tensor of the input IDs and `embedding_layer` is model's embedding layer
ifUSE_MAMBA:
# Set `batch_size` to a value that works for memory constraints
encoded_inputs=batch_embedding_calls(input_ids, embedding_layer, batch_size=1).float()
attention_mask= (input_ids!=tokenizer.pad_token_id).type(input_ids.dtype)
returnencoded_inputs, attention_mask
下面就可以进行训练了
# Load a pretrained tokenizer
tokenizer=AutoTokenizer.from_pretrained('bert-base-uncased')
# Assuming encoded_inputs is a preprocessed tensor of shape [num_samples, seq_len, d_model]
encoded_inputs_file='encoded_inputs_mamba.pt'
ifos.path.exists(encoded_inputs_file):
print("Loading pre-tokenized data...")
encoded_inputs=torch.load(encoded_inputs_file)
else:
print("Tokenizing raw data...")
enwiki8_data=load_enwiki8_dataset()
encoded_inputs, attention_mask=encode_dataset(tokenizer, enwiki8_data)
torch.save(encoded_inputs, encoded_inputs_file)
print(f"finished tokenizing data")
# Combine into a single dictionary
data= {
'input_ids': encoded_inputs,
'attention_mask': attention_mask
}
# Split the data into train and validation sets
total_size=len(data['input_ids'])
train_size=int(total_size*0.8)
train_data= {key: val[:train_size] forkey, valindata.items()}
val_data= {key: val[train_size:] forkey, valindata.items()}
train_dataset=Enwiki8Dataset(train_data)
val_dataset=Enwiki8Dataset(val_data)
train_loader=DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader=DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
# Initialize the model
model=Mamba(seq_len, d_model, state_size, device).to(device)
# Define the loss function and optimizer
criterion=nn.CrossEntropyLoss()
optimizer=optim.AdamW(model.parameters(), lr=5e-6)
# Training loop
num_epochs=25 # Number of epochs to train for
forepochintqdm(range(num_epochs)): # loop over the dataset multiple times
train_loss=train(model, tokenizer, train_loader, optimizer, criterion, device, max_grad_norm=10.0, DEBUGGING_IS_ON=False)
val_loss=evaluate(model, val_loader, criterion, device)
val_perplexity=calculate_perplexity(val_loss)
print(f'Epoch: {epoch+1}, Training Loss: {train_loss:.4f}, Validation Loss: {val_loss:.4f}, Validation Perplexity: {val_perplexity:.4f}')
以上就是训练的完整代码
总结
我们介绍了Mamba的概念和架构,并且从头开始构建Mamba复现,这样可以将理论转化为实践。通过这种动手的方法,可以看到Mamba序列建模方法和效率。如果你想直接使用,可以看论文提供的代码
https://avoid.overfit.cn/post/96ca1d7044b4405a9b0a0f6154099078