数据分析师面试必备,数据分析面试题集锦(六)
经常会被问到,“数据分析需要学习什么技能?”,“针对实际的业务场景,如何使用数据分析工具去分析?”基于此作者总结数据分析面试常用的问题,面试内容包括技能应用篇:EXCEL、SQL、Python、BI工具等,业务思维篇:常用的数据分析方法与业务思维等。
其中大部分问题点,没有绝对标准答案,所有问题点都是为了解决问题,大家如果有更好的问题答案,也可以提出,对于其中的问题也可以提出,共同解答,欢迎点赞、转发、评论,下面一起来学习。
本文讲解内容:Excel、SQL、Python面试必备
适用范围:多种数据分析实用技巧
Excel篇
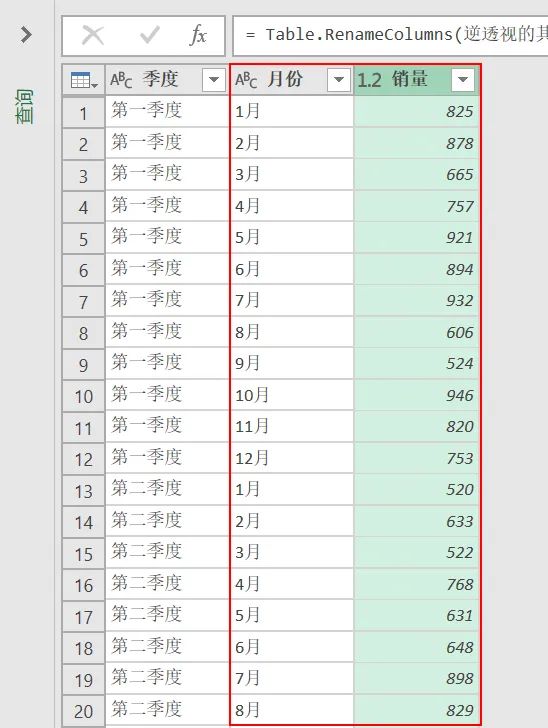
1、Excel将多行数据变为一列
Excel将多行数据放到一列中,如下包含1月到12月共计12列数据,有5行数据,将以下多列数据聚合到一列中。

框选数据,点击数据选项卡下的从表格。

在创建表选项下点击确定。

进入Powerquery界面,选择第一列数据,在转换选项卡下选择逆透视列中的逆透视其他列选项卡。

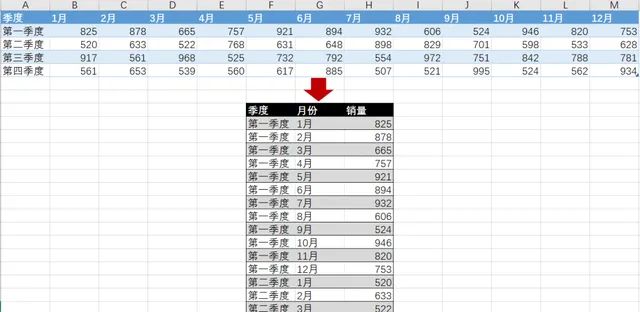
即可将多列数据聚合到一列,从而形成多行数据。
在开始选项卡下点击关闭并上载功能。

如下即为数据转化的前后对比,将多列数据聚合为一列数据。
2、Excel将一行数据拆分为多行
Excel将一行数据拆分为多行,如下有一行包含多个城市的数据。

选择数据,点击数据选项卡下的从表格。
在创建表选项下点击确定。

选择数据,在开始选项卡下点击拆分列按分隔符。

因为示例数据使用点分隔,所以选择自定义分隔符,拆分位置为每次出现分隔符时,拆分为行,点击确定。

点击关闭并上载即可将数据结果加载至Excel表格中。

如下即为数据转化的前后对比,将一行数据拆分为多行。

3、VLOOKUP高级用法
1)跨表查找
如下是原始数据,使用VLOOKUP跨表查询功能。

使用VLOOKUP+COLUMN函数实现多列同时跨表查询。
=VLOOKUP($A3,'Q1'!$A$1:$D$9,COLUMN(B:B),0)
2)跨多表查找
INDIRECT函数用于返回由文本字符串指定的引用。
=VLOOKUP($A2,INDIRECT(B$1&"!A:B"),2,0)
3)跨多表查找(格式不一致)
这里不仅使用INDIRECT函数,而且使用MATCH函数来返回"销量"在单元格区域中的位置。
=VLOOKUP($A2,INDIRECT(B$1&"!A:G"),MATCH("销量",INDIRECT(B$1&"!1:1"),0),0)
SQL篇
1、每天的日活数及新用户占比
如下是用户行为日志表,求每天的日活数及新用户占比。

由于跨天都记为该用户活跃过,所以使用union建立一个用户活跃日期表。
select uid,date(in_time) as dt
from tb_user_log
union
select uid,date(out_time) as dt
from tb_user_logunion 可以自动去重,此时我们得到了一个包括跨天的用户活跃日期表,然后使用窗口函数,算出每个用户的首登日期。
select uid,dt,min(dt) over (partition by uid) as first_in
from
(
select uid,date(in_time) as dt
from tb_user_log
union
select uid,date(out_time) as dt
from tb_user_log
)
t1由此便得到一个有用户活跃日期dt和用户首登日期first_in的表,将此表命名为temp,接下来使用此表查询,根据日期分组,计算每日的所有有记录的用户作为每日活跃用户,而如果用户活跃日期dt和用户首登日期first_in相等则记为新用户,使用sum累加。
select dt,
count(distinct uid) as dau,
round(sum(if(dt=first_in,1,0))/count(distinct uid),2) as uv_new_ratio
from temp
group by dt
order by dt完整代码如下:
with temp as
(
select uid,dt,min(dt) over (partition by uid) as first_in
from
(
select uid,date(in_time) as dt
from tb_user_log
union
select uid,date(out_time) as dt
from tb_user_log
) t1
)
select dt,
count(distinct uid) as dau,
round(sum(if(dt=first_in,1,0))/count(distinct uid),2) as uv_new_ratio
from temp
group by dt
order by dt2、2021年11月每天新用户的次日留存率
如下是用户行为日志表,求2021年11月每天新用户的次日留存率。

用组合查询将in_time和out_time视为同一时间列,并用union去重,接着使用窗口函数lead()获得每个用户下次登录日期,row_number()获得每个用户本次登录的排序,仅保留新用户首次登录日期的记录,按11月的日期分类,计算留存率。
select dt,
round(sum(if(datediff(next_dt,dt)=1,1,0))/count(distinct uid),2) uv_left_rate
from
(select uid, dt,
lead(dt,1) over(partition by uid order by dt) next_dt,
row_number() over(partition by uid order by dt) dt_rank
from
(select uid, date(in_time) dt
from tb_user_log
union
select uid, date(out_time) dt
from tb_user_log) m ) n
where dt_rank = 1 and date_format(dt,'%Y-%m') = '2021-11'
group by dt
order by dtPython篇
1、列表推导式
具体地Python列表推导式可以分为以下几种:一般形式、带if的列表解析式、带if...else的列表解析式。
1)一般形式
[expression for i in iterable]
依次返回列表numbers中的内容。
#一般形式
numbers = [1,2,3,4,5,6]
[print(i) for i in numbers]
2)带if的列表解析式
[expression for i in iterable if...]
返回列表numbers中大于4的内容。
#带if的列表解析式
numbers = [1,2,3,4,5,6]
[i for i in numbers if i >= 4]
3)带if...else的列表解析式
[expression if...else... for i in iterable]
返回列表numbers中数字的奇偶性。
#带if...else的列表解析式
numbers = [1,2,3,4,5,6]
["偶数" if i % 2 == 0 else "奇数" for i in numbers]
2、map、apply、applymap用法
首先构建一个数据集。
import pandas as pd
import numpy as np
dates = pd.date_range('20230301', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
df
#增加一列数据
df=df.assign(tag=(df['D']>0).map({True:'H',False:'L'}))
df
1)map函数
map将数据逐个当作参数传入字典或者函数中,返回映射之后的值;最后映射结果组成新的Series。
#使用lambda函数,A列乘以10
df['A'].map(lambda x:x*10)
#tag列,把H换成大于0,L换成小于0
df['tag'].map({'H':'▲0','L':'▼0'})
使用自定义函数,这里map只接受一个参数,即传入的x。
#使用函数实现tag列,把H换成大于0,L换成小于0
def HL_map(x):
if x == 'H':
return '▲0'
elif x == 'L':
return '▼0'
df['tag'].map(HL_map)
2)apply函数
相较于map,apply工作原理类似,区别是能够传入更加复杂的参数,接受多个参数。
#函数累计
df.apply(np.cumsum)
df.apply(lambda x: x.max() - x.min())#函数求极差
#A列乘以100除以2
def data_apply(x,multiple,bias):
return x * multiple / bias
df['A'].apply(data_apply,args=(100,2))
对DataFrame而言,apply中的参数axis=1表示对行遍历,axis=0表示对列遍历,对于传入apply的行(或列)数据,以Series格式传入指定函数,返回对应结果。
def DATA_B_apply(x):
if (x['B']>0)&(x['tag']=='H'):
return 'B_H'
elif (x['B']<0)&(x['tag']=='L'):
return 'B_L'
else:
return x['B']
pass
df.apply(DATA_B_apply,axis=1)
3)applymap函数
对DataFrame中的每个单元格执行指定函数的操作。
#同乘100
df.iloc[:,0:4].applymap(lambda x : x*100)
#保留两位小数
df.iloc[:,0:4].applymap(lambda x : '%.2f' % x)
本文首发于公众号:大话数据分析,三年互联网数据分析经验,擅长Excel、SQL、Python、PowerBI数据处理工具,数据可视化、商业数据分析技能,统计学、机器学习知识,持续创作数据分析内容,点赞关注,不迷路。