【ACL 2023】 The Art of Prompting Event Detection based on Type Specific Prompts
【ACL 2023】 The Art of Prompting: Event Detection based on Type Specific Prompts

论文:https://aclanthology.org/2023.acl-short.111/
代码:https://github.com/VT-NLP/Event_APEX
Abstract
我们比较了各种形式的提示来表示事件类型,并开发了一个统一的框架,将特定于事件类型的提示用于监督、少样本和零样本触发词事件检测。实验结果表明,定义明确且全面的事件类型提示可以显著提高事件检测性能,尤其是当标注数据稀缺(少样本事件检测)或不可用(零样本事件检测)时。通过利用事件类型的语义,我们的统一框架显示出比以前的最先进基线高达22.2%的F1分数增益。
Introduction
以往的研究进一步鼓励我们向前迈进一步,思考以下三个问题:(1)当训练数据丰富或稀缺时,选择提示是否重要?(2) ED(事件检测)提示的最佳形式是什么?(3) 如何最好地利用提示来检测事件提及?
为了回答上述研究问题,我们对每种事件类型的各种形式的提示进行了广泛的实验,包括(a)事件类型名称,(b)原型种子触发词,(c)定义,(d)基于事件类型名称及其预定义论元角色的事件类型结构,(e)基于自由论元的连续软提示,以及(f)更全面的事件类型描述(命名为APEX提示),其涵盖了提示(a)-(d)的所有信息。我们观察到:(1)通过考虑大多数形式的提示的事件类型的语义,特别是种子触发词和全面的事件类型描述,ED在所有设置下的性能都可以显著提高;(2) 在所有形式的事件表示中,基于全面描述的提示显示是最有效的,尤其是对于少样本和零样本ED;(3) 不同形式的事件类型表示提供了互补的改进,表明它们捕获了事件类型的不同方面和知识。
这项工作的贡献如下:
- 我们研究了各种提示来表示有监督和弱监督ED的事件类型,并证明了定义明确和全面的事件类型提示可以显著提高ED的性能和从旧类型到新类型的可转移性。
- 开发了一个统一的框架,以利用事件类型的语义,提示监督ED、少样本ED和零样本ED,并展示了最先进的性能,与强大的基线方法相比,F1-score提高了22.2%。
Problem Formulation
Setting of ED
supervised EE(SED):我们遵循传统的监督事件检测设置,其中训练、验证和评估数据集覆盖相同的事件类型集。目标是学习用于识别和分类目标事件类型的事件提及的模型 f f f。
few-shot ED(FSED):有两个单独的训练数据集用于少样本事件检测:(1)覆盖旧事件类型(叫做base类型)的大规模数据集 D b a s e = { ( x i , y i ) } i = 1 M \mathcal{D}_{base}=\{(x_i,y_i)\}^M_{i=1} Dbase={(xi,yi)}i=1M,其中 M M M表示基本事件类型的数量;(2) 一个较小的数据集 D n o v e l = { ( x j , y j ) } j = 1 N × K \mathcal{D}_{novel}=\{(x_j,y_j)\}^{N\times K}_{j=1} Dnovel={(xj,yj)}j=1N×K,它覆盖了 N N N种新的事件类型,每个事件类型有 K K K个例子。请注意,除了Other类之外,base事件类型和novel事件类型是不相交的。模型 f f f将首先在 D b a s e \mathcal{D}_{base} Dbase上进行优化,然后在 D n o v e l \mathcal{D}_{novel} Dnovel上进行进一步微调。目标是评估模型从基本事件类型到几乎没有标注的新事件类型的可推广性和可转移性。
zero-shot ED(ZSED):训练数据集是零样本和少样本事件检测之间的唯一区别。在零样本事件检测中,对于基础事件类型,只有大规模的基础训练数据集 D b a s e = { ( x i , y i ) } i = 1 M D_{base}=\{(x_i,y_i)\}^M_{i=1} Dbase={(xi,yi)}i=1M。模型 f f f将仅在基本事件类型上进行优化,并在新类型上进行评估。
Event Type Prompts
我们比较以下五种形式的提示来表示事件类型:(a)事件类型名称是事件类名,通常由一到三个token组成。(b) 定义可以是正式描述事件类型含义的短句。(c) 原型种子触发词经常被识别为事件触发词的token或短语的列表。(d) 事件类型结构由事件关键论元角色组成,指示目标事件类型的核心参与者。(e) 提示也可以是连续软提示,即表示每个事件类型的参数的自由向量。(f) 我们进一步定义了一个更全面的描述APEX Prompt,它是手动编写的,涵盖了除软提示之外的所有以前的提示。所有事件类型提示的示例如图1所示。
A Unified Framework for ED

我们在Wang等人的基础上进行了调整,并设计了一个统一的事件检测框架(如图1所示),该框架利用特定于事件类型的提示来检测监督、少样本和零样本触发词设置下的事件。形式上,给定输入句子 W = { w 1 , w 2 , … , w n } W=\{w_1,w_2,\dots,w_n\} W={w1,w2,…,wn},我们将每个事件类型提示 T t = { τ 1 t , τ 2 t , … , τ m t } T^t=\{\tau ^t_1,\tau ^t_2,\dots,\tau ^t_m\} Tt={τ1t,τ2t,…,τmt}作为 M M M个token的查询,以提取事件类型 t t t的触发词。具体而言,我们首先将它们连接成序列[CLS] τ 1 t , … , τ m t \tau ^t_1,\dots,\tau ^t_m τ1t,…,τmt [SEP] w 1 , … , w n w_1,\dots,w_n w1,…,wn [SEP]。我们使用预训练的BERT编码器来获得输入句子 W = { w 1 , … , w n } W=\{w_1,\dots,w_n\} W={w1,…,wn}以及事件类型提示 T = τ 1 t , … , τ m t T={\tau ^t_1,\dots,\tau ^t_m} T=τ1t,…,τmt的上下文表示。
给定每种事件类型的提示,我们的目标是从输入句子中提取相应的事件触发词。为了实现这一目标,我们需要捕获每个输入token与事件类型的语义相关性。因此,我们学习事件类型提示的上下文表示序列上的权重分布,以获得感知事件类型 t t t的上下文表示 A i t = ∑ j = 1 ∣ T t ∣ α i j ⋅ τ j t A_i^t=\sum_{j=1}^{|T^t|} \alpha_{ij} \cdot \tau_j^t Ait=∑j=1∣Tt∣αij⋅τjt ,其中 α i j = cos ( w i , τ j t ) \alpha_{ij}=\cos (w_i,\tau_j^t) αij=cos(wi,τjt), τ j \tau_j τj是第 j j j个提示token的上下文表示。 cos ( ⋅ ) \cos(\cdot) cos(⋅)是两个向量之间的余弦相似函数。
据此,事件类型感知上下文表示 A i t A^t_i Ait将与来自编码器的原始上下文表示 w i w_i wi连接,并被分类为二进制标签,指示它是否是事件类型 t t t的候选触发词: y ~ i t = U o ( [ w i ; A i t ; P i ] ) \tilde{y}^t_i=U_o([w_i;A^t_i;P_i]) y~it=Uo([wi;Ait;Pi]),其中 [ ; ] [;] [;]表示连接操作, U o U_o Uo是用于事件触发词检测的可学习参数矩阵,并且 P i P_i Pi是单词 w i w_i wi的一个独热码(POS)编码。对于基于连续软提示的事件检测,我们遵循Li和Liang,其中前缀索引 q q q被预加到输入序列 W ′ = [ q ; W ] W′=[q;W] W′=[q;W]。前缀嵌入通过 q = M L P θ ( Q θ [ q ] ) q=MLP_θ(Q_θ[q]) q=MLPθ(Qθ[q])来学习,其中 Q θ ∈ R ∣ Q ∣ × k Q_θ\in \mathbf{R}^{|Q|\times k} Qθ∈R∣Q∣×k表示前缀索引词汇表的嵌入查找表。 M L P θ MLP_θ MLPθ和 Q θ Q_θ Qθ都是可训练的参数。
Experiments and Results


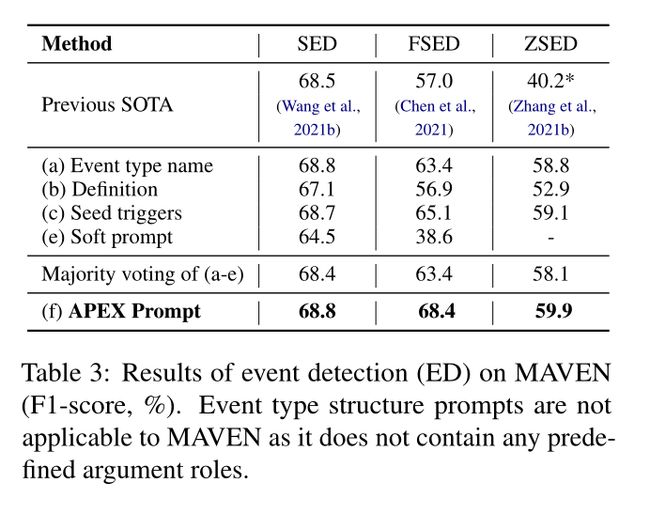
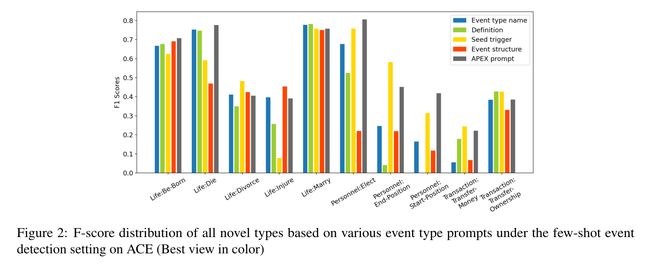
Conclusion
我们研究了各种提示来表示事件类型的语义,并使用统一的框架来进行监督、少样本和零样本事件检测。实验结果表明,对事件类型进行定义明确和全面的描述可以显著提高事件检测的性能,尤其是当标注有限(很少的事件检测)甚至不可用(零样本事件检测)时,与现有技术相比,F1-score增益高达22.2%。