神经网络——卷积层和池化层
目录
卷积层
池化层
代码实践
学习之前我们先要了解卷积和池化间的联系——首先卷积用来提取图像特征,但是提取后图片的数据量依旧很大,所以需要通过池化来降低特征,池化没有可学习的参数,它仅仅是对输入的聚合操作。通过减小特征图的尺寸,池化层可以减少后续层的参数数量,从而降低模型的复杂度和计算量。
卷积层
卷积层(Convolutional Layer)是神经网络中的一种基本层,主要用于图像处理和计算机视觉任务中。它通过对输入图像进行多个卷积核的卷积运算,提取出图像中的特征,生成输出特征图。
一个卷积层通常由多个卷积核、偏置、激活函数和池化层等组成。其中,卷积核是该层的核心部分,它将输入图像中的每个像素与自身权重进行点乘,再加上偏置项,生成单个输出值。多个卷积核可以提取不同的特征,例如边缘、纹理、颜色等,从而捕获图像中更高级的结构和特征。
我们先通过官方文档看下比较正规的卷积层说明,卷积层的使用
| nn.Conv2d |
Applies a 2D convolution over an input signal composed of several input planes. |
这里我们重点介绍 nn.Conv2d ,即二维卷积,需要注意这里的 nn.Conv2d 和 nn.conv2d 的区别,nn.Conv2d 是一个类,可以创建可学习的卷积层,而 nn.conv2d 是一个函数,用于执行卷积操作。通常情况下,建议使用 nn.Conv2d 类来创建卷积层,因为它更加灵活,并且可以与其他模块一起使用。而 nn.conv2d 可以在需要时用作函数调用。
nn.Conv2d 相关参数如下:

- in_channels:输入图像的通道数
- out_channels:输出图像的通道数
- kernel_size:卷积核大小
- stride:卷积核每次匹配后移动的步长
- padding:选择是否进行图像边缘填充,提取出更多边缘特征
- padding_mode:填充的模式,一般默认以0填充
- dilation:空洞卷积,卷积核内部元素之间的间隔大小
- group:将输入特征图和卷积核进行分组处理
- bias:偏置,选择是否在输出加上一个常数
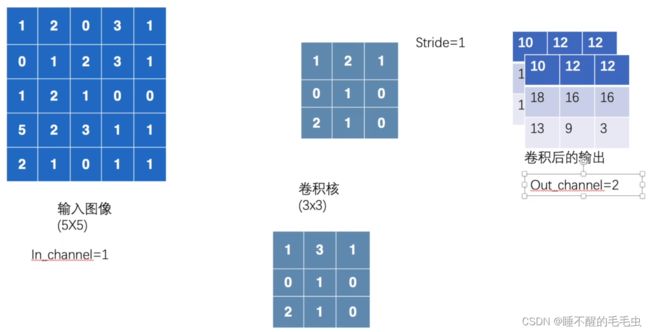
其中 kernel_size 初始时并不需要我们去设置具体的参数,只需指明它是一个 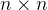 的数组即可,具体参数会在不断训练中去进行优化,从而更适应模型。通过 Gif 动图可以更直观的理解 padding 和 stride 的作用,这里显示的是默认参数时的情形,若要查看更多类型,“请点击查看”
的数组即可,具体参数会在不断训练中去进行优化,从而更适应模型。通过 Gif 动图可以更直观的理解 padding 和 stride 的作用,这里显示的是默认参数时的情形,若要查看更多类型,“请点击查看”
|
|
| No padding, no strides |

蓝色部分是输入图像的数组形状,深蓝色是卷积核大小,而绿色表示经过卷积之后得到的输出。若要具体了解卷积的实现流程,可参考:神经网络骨架搭建及卷积
参数 dilation 我们这里也通过一个Gif 动图进行简单说明:其中 dilation 为默认值,从下层扫描方式可以看出,卷积核是一个  的大小,但两个相邻元素之间间隔1个单位。
的大小,但两个相邻元素之间间隔1个单位。
|
|
| No padding, no stride, dilation |

接下来说一下 out_channels ,out_channels 的数值可以理解为卷积核的数量,每一个卷积核对图像进行卷积都会得到一个输出,把多个输出进行叠加后就会得到最终的结果。比如out_channels=2 ,那么最后将会得到一个2层的图像。
池化层
池化层(Pooling Layer)是卷积神经网络中常用的一种层,用于减小特征图的尺寸并提取主要特征。池化函数是使用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出,本质是降采样,在保留特征的同时,减小数据尺寸,进而加快训练速度。官方文档说明:池化层的使用
| nn.MaxPool2d |
Applies a 2D max pooling over an input signal composed of several input planes. |
| nn.MaxUnpool2d |
Computes a partial inverse of |
上面是两个常用的类, nn.MaxPool2d 被称为二维数组的最大池化,同时也叫 “上采样”,反之, nn.MaxUnpool2d 叫 “下采样”。下图为上采样的相关参数:

- kernel_size:池化核(同卷积核)
- stride:步长,默认值与 kernel_size 相同
- ceil_mode:当 ceil_mode=True 时,表示允许越界,False 时表示不允许
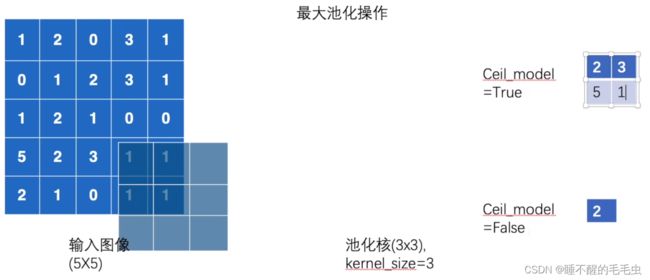
这里对池化的具体操作举例说明:假如输入的图像是 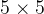 的数组,将kernel_size 设置为 的大小,那么该池化核会对输入图像进行匹配并返回其最大值,同时步长默认为卷积核的大小,当 ceil_mode=True 时,认为池化核会将越界部分也进行匹配并返回最大值,若ceil_mode=False ,则池化核一旦有越界情况则自动进行下一次匹配。
的数组,将kernel_size 设置为 的大小,那么该池化核会对输入图像进行匹配并返回其最大值,同时步长默认为卷积核的大小,当 ceil_mode=True 时,认为池化核会将越界部分也进行匹配并返回最大值,若ceil_mode=False ,则池化核一旦有越界情况则自动进行下一次匹配。
代码实践
卷积:我们这里依旧使用的是 CIFAR10 的数据集,将卷积的 out_channel 设置为6,代表正常的输出应有6个通道,如果直接使用 Tensorboard 进行显示会出现类型错误,这是由于我们输出的图像有6个通道,而彩色图像只有3个通道,因此我们使用 torch.reshape 将其通道减少,通道减少意味着输出图像的叠加层数减少,表示原本6个通道的图像将分裂为3个通道,即显示的图片数量会增加,我们这里在 reshape 将 batch_size 的值设置为-1,表示该函数会依据后面的参数自动计算批量值,也可以手动设置。Tensorboard 的使用方法:PyTorch深度学习快速入门
卷积层相关代码如下:
import torch
import torchvision
from torch.nn import Conv2d
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Mydata(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
output = self.conv1(x)
return output
writer = SummaryWriter("logs")
mydata = Mydata()
step = 0
for data in dataloader:
img, label = data
output = mydata(img)
writer.add_images("input", img, step)
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step = 1 + step
writer.close()
卷积层运行结果如图示:

池化相关代码:我们这里是将池化核定义为 ,允许越界
import torch
from torch import nn
from torch.nn import MaxPool2d
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
input = torch.tensor([[1, 2, 0, 3, 2],
[3, 2, 4, 5, 6],
[3, 4, 5, 6, 2],
[1, 3, 2, 6, 5],
[5, 6, 2, 1, 3]], dtype=torch.float32)
input_reshape = torch.reshape(input, (-1, 1, 5, 5))
print(input_reshape)
print(input_reshape.shape)
class Mydata(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
mydata = Mydata()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data
output = mydata(imgs)
writer.add_images("input", imgs, step)
writer.add_images("maxpool", output, step)
step += 1
writer.close()池化运行结果:

从图中可以看出经过池化的图像相比于原图像模糊了一些,但也能很好的观察出其较好的保留了原图像的形象特征,基本能够辨别出其基本轮廓。