用通俗易懂的方式讲解:十分钟读懂 Stable Diffusion 运行原理
AIGC 热潮正猛烈地席卷开来,可以说 Stable Diffusion 开源发布把 AI 图像生成提高了全新高度,特别是 ControlNet 和 T2I-Adapter 控制模块的提出进一步提高生成可控性,也在逐渐改变一部分行业的生产模式。惊艳其出色表现,也不禁好奇其背后技术。
之前写过一篇实战类的文章一文教会你学会 AI 绘画利器 Stable Diffusion
本文整理了一些学习过程中记录的技术内容,主要包括 Stable Diffusion 技术运行机制,希望帮助大家知其所以然。
喜欢记得收藏、关注、点赞,想进行技术交流,也可以加入我们
文章目录
-
-
- 用通俗易懂的方式讲解系列
- 技术交流
- 一 背景介绍
- 二 原理简介
- 三 模块分析
-
- 1 Unet 网络
- 2 采样器迭代
- 3 CLIP 模型
- 四 本文小结
- 参考链接
-
用通俗易懂的方式讲解系列
- 用通俗易懂的方式讲解:不用再找了,这是大模型最全的面试题库
- 用通俗易懂的方式讲解:这是我见过的最适合大模型小白的 PyTorch 中文课程
- 用通俗易懂的方式讲解:一文讲透最热的大模型开发框架 LangChain
- 用通俗易懂的方式讲解:基于 LangChain + ChatGLM搭建知识本地库
- 用通俗易懂的方式讲解:基于大模型的知识问答系统全面总结
- 用通俗易懂的方式讲解:ChatGLM3 基础模型多轮对话微调)
- 用通俗易懂的方式讲解:最火的大模型训练框架 DeepSpeed 详解来了
- 用通俗易懂的方式讲解:这应该是最全的大模型训练与微调关键技术梳理
- 用通俗易懂的方式讲解:Stable Diffusion 微调及推理优化实践指南
- 用通俗易懂的方式讲解:大模型训练过程概述
- 用通俗易懂的方式讲解:专补大模型短板的RAG
- 用通俗易懂的方式讲解:大模型LLM Agent在 Text2SQL 应用上的实践
- 用通俗易懂的方式讲解:大模型 LLM RAG在 Text2SQL 上的应用实践
技术交流
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
建立了大模型技术交流群,大模型学习资料、数据代码、技术交流提升, 均可加知识星球交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:技术交流
方式②、添加微信号:mlc2060,备注:技术交流

一 背景介绍
AI 绘画作为 AIGC(人工智能创作内容)的一个应用方向,它绝对是 2022 年以来 AI 领域最热门的话题之一。AI 绘画凭借着其独特创意和便捷创作工具迅速走红,广受关注。举两个简单例子,左边是利用 controlnet 新魔法把一张四个闺蜜在沙滩边上的普通合影照改成唯美动漫风,右边是 midjourney v5 最新版本解锁的逆天神技, 只需输入文字“旧厂街风格,带着浓浓 90 年代氛围感”即可由 AI 一键生成超逼真图片!

图1 两个stable diffusion例子
Stable Diffusion,是一个 2022 年发布的文本到图像潜在扩散模型,由 CompVis、Stability AI 和 LAION 的研究人员创建的。要提到的是,Stable Diffusion 技术提出者 StabilityAI 公司在 2022 年 10 月完成了 1.01 亿美元的融资,估值目前已经超过 10 亿美元。本文会在第二部分着重介绍 Stable Diffusion 的技术思路,第三部分深入分析各个重要模块的运行机制,最后总结下 AI 绘画。
二 原理简介
Stable Diffusion 技术,作为 Diffusion 改进版本,通过引入隐向量空间来解决 Diffusion 速度瓶颈,除了可专门用于文生图任务,还可以用于图生图、特定角色刻画,甚至是超分或者上色任务。作为一篇基础原理介绍,这里着重解析最常用的“文生图(text to image)”为主线,介绍 stable diffusion 计算思路以及分析各个重要的组成模块。
下图是一个基本的文生图流程,把中间的 Stable Diffusion 结构看成一个黑盒,那黑盒输入是一个文本串“paradise(天堂)、cosmic(广阔的)、beach(海滩)”,利用这项技术,输出了最右边符合输入要求的生成图片,图中产生了蓝天白云和一望无际的广阔海滩。
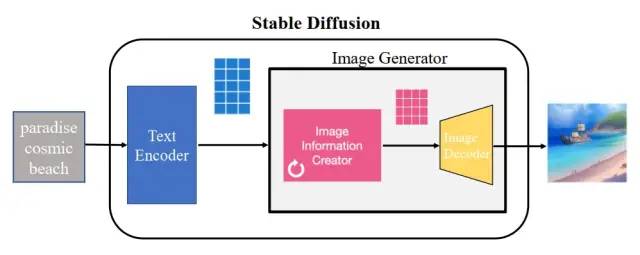
图2 Stable Diffusion组成
Stable Diffusion 的核心思想是,由于每张图片满足一定规律分布,利用文本中包含的这些分布信息作为指导,把一张纯噪声的图片逐步去噪,生成一张跟文本信息匹配的图片。它其实是一个比较组合的系统,里面包含了多个模型子模块,接下来把黑盒进行一步步拆解。stable diffusion 最直接的问题是,如何把人类输入的文字串转换成机器能理解的数字信息。这里就用到了文本编码器 text encoder(蓝色模块),可以把文字转换成计算机能理解的某种数学表示,它的输入是文字串,输出是一系列具有输入文字信息的语义向量。有了这个语义向量,就可以作为后续图片生成器 image generator(粉黄组合框)的一个控制输入,这也是 stable diffusion 技术的核心模块。图片生成器,可以分成两个子模块(粉色模块+黄色模块)来介绍。下面介绍下 stable diffusion 运行时用的主要模块:
(1) 文本编码器(蓝色模块),功能是把文字转换成计算机能理解的某种数学表示,在第三部分会介绍文本编码器是怎么训练和如何理解文字,暂时只需要了解文本编码器用的是 CLIP 模型,它的输入是文字串,输出是一系列包含文字信息的语义向量。
(2) 图片信息生成器(粉色模块),是 stable diffusion 和 diffusion 模型的区别所在,也是性能提升的关键,有两点区别:
① 图片信息生成器的输入输出均为低维图片向量(不是原始图片),对应上图里的粉色 4_4 方格。同时文本编码器的语义向量作为图片信息生成器的控制条件,把图片信息生成器输出的低维图片向量进一步输入到后续的图片解码器(黄色)生成图片。(注:原始图片的分辨率为 512_512,有RGB 三通道,可以理解有 RGB 三个元素组成,分别对应红绿蓝;低维图片向量会降低到 64*64 维度)
② Diffusion 模型一般都是直接生成图片,不会有中间生成低维向量的过程,需要更大计算量,在计算速度和资源利用上都比不过 stable diffusion;
那低维空间向量是如何生成的?是在图片信息生成器里由一个 Unet 网络和一个采样器算法共同完成,在 Unet 网络中一步步执行生成过程,采样器算法控制图片生成速度,下面会在第三部分详细介绍这两个模块。Stable Diffusion 采样推理时,生成迭代大约要重复 30~50 次,低维空间变量在迭代过程中从纯噪声不断变成包含丰富语义信息的向量,图片信息生成器里的循环标志也代表着多次迭代过程。
(3) 图片解码器(黄色模块),输入为图片信息生成器的低维空间向量(粉色 4*4 方格),通过升维放大可得到一张完整图片。由于输入到图片信息生成器时做了降维,因此需要增加升维模块。这个模块只在最后阶段进行一次推理,也是获得一张生成图片的最终步骤。
那扩散过程发生了什么?
-
扩散过程发生在图片信息生成器中,把初始纯噪声隐变量输入到 Unet 网络后结合语义控制向量,重复 30~50 次来不断去除纯噪声隐变量中的噪声,并持续向隐向量中注入语义信息,就可以得到一个具有丰富语义信息的隐空间向量(右下图深粉方格)。采样器负责统筹整个去噪过程,按照设计模式在去噪不同阶段中动态调整 Unet 去噪强度。
-
更直观看一下,如图 3 所示,通过把初始纯噪声向量和最终去噪后的隐向量都输到后面的图片解码器,观察输出图片区别。从下图可以看出,纯噪声向量由于本身没有任何有效信息,解码出来的图片也是纯噪声;而迭代 50 次去噪后的隐向量已经耦合了语义信息,解码出来也是一张包含语义信息的有效图片。

图3 可视化输出图片变化
到这里,我们大致介绍了 Stable Diffusion 是什么以及各个模块思路,并且简单介绍了 stable diffusion 的扩散过程。第三部分我们继续分析各个重要组成模块的运行机制,更深入理解 Stable Diffusion 工作原理。
三 模块分析
第二部分以零基础角度介绍了 Stable Diffusion 技术思路,这部分会更细致地介绍下 Stable Diffusion 文生图技术,训练阶段和采样阶段的总体框架如图 4 所示,可以划分成 3 个大模块:PART1-CLIP 模型,PART2-Unet 训练,PART3-采样器迭代。

图4 Stable Diffusion文生图框架
训练阶段, 包含了图里 PART1 CLIP 模型和 PART2 Unet 训练,分成三步:
1、用 AutoEncoderKL 自编码器把输入图片从像素空间映射到隐向量空间,把 RGB 图片转换到隐式向量表达。其中,在训练 Unet 时自编码器参数已经训练好和固定的,自编码器把输入图片张量进行降维得到隐向量。
2、用 FrozenCLIPEmbedder 文本编码器来编码输入提示词 Prompt,生成向量表示 context,这里需要规定文本最大编码长度和向量嵌入大小。
3、对输入图像的隐式向量施加不同强度噪声,再把加噪后隐向量输入到 UNetModel 来输出预估噪声,和真实噪声信息标签作比较来计算 KL 散度 loss,并通过反向传播算法更新 UNetModel 模型参数;引入文本向量 context 后,UNetModel 在训练时把其作为 condition,利用注意力机制来更好地引导图像往文本向量方向生成;
采样阶段,包含了图里 PART1 CLIP 模型和 PART3 采样器迭代,分成三步:
1、用 FrozenCLIPEmbedder 文本编码器把输入提示词 Prompt 进行编码,生成维度为[B, K, E]的向量表示 context,与训练阶段的第 2 步一致;
2、利用随机种子随机产出固定维度的噪声隐空间向量,利用训练好的 UNetModel 模型,结合不同采样器(如 DDPM/DDIM/PLMS)迭代 T 次不断去除噪声,得到具有文本信息的隐向量表征;
3、用 AutoEncoderKL 自编码器把上面得到的图像隐向量进行解码,得到被映射到像素空间的生成图像。
上面对 stable diffusion 总体架构进行了介绍,那接下来进一步分析介绍下每个重要组成模块,分别是 Unet 网络、采样器和 CLIP 模型三个主要模块。
1 Unet 网络
Stable Diffusion 里采用的 UNetModel 模型,采用 Encoder-Decoder 结构来预估噪声,网络结构如图 5:

图5 Unet网络结构示意图
模型输入包括 3 个部分,(1) 图像表示,用隐空间向量输入的维度为[B, Z, H/8, W/8];(2) timesteps 值,维度为[B, ];(3) 文本向量表示 context,维度为[B, K, E]。其中[B, Z, H, W]分别表示[batch_size 图片数,C 隐空间通道数,height 长度,weight 宽度],K 和 E 分别表示文本最大编码长度 max length 和向量嵌入大小。
模型使用 DownSample 和 UpSample 进行样本的下上采样,在采样模块之间还有黑色虚线框的 ResBlock 和 SpatialTransformer,分别接收 timesteps 信息和提示词信息(这里只画出一次作为参考)。ResBlock 模块的输入有 ① 来自上一个模块的输入和 ②timesteps 对应的嵌入向量 timestep_emb(维度为[B, 4*M],M 为可配置参数);SpatialTransformer 模块的输入有 ① 来自上一个模块的输入和 ② 提示词 Prompt 文本的嵌入表示 context,以 context 为注意力机制里的 condition,学习提示词 Prompt 和图像的匹配程度。最后,UNetModel 不改变输入和输出大小,隐空间向量的输入输出维度均为[B, Z, H/8, W/8]。
ResBlock 网络
ResBlock 网络,有两个输入分别是 ① 来自上一个模块的输入和 ②timesteps 对应的嵌入向量 timestep_emb(维度为[B, 4*M],M 为可配置参数),网络结构图如下所示。
timestep_embedding 的生成方式,用的是“Attention is All you Need”论文的 Transformer 方法,通过 sin 和 cos 函数再经过两个 Linear 进行变换。

图6 ResBlock模块和Timestep生成流程
SpatialTransformer 结构
SpatialTransformer 这里,包含模块比较多,有两个输入分别是 ① 来自上一个模块的输入和 ② 提示词 Prompt 文本的嵌入表示 context 作为 condition,两者使用 cross attention 进行建模。其中,SpatialTransformer 里面的注意力模块 CrossAttention 结构,把图像向量作为 Query,文本表示 context 作为 Key&Value,利用 Cross Attention 模块来学习图像和文本对应内容的相关性。
注意力模块的作用是,当输入提示词来生成图片时,比如输入 “一匹马在吃草”,由于模型已经能捕捉图文相关性以及文本中的重点信息,当看到 “马”时,注意力机制会重点突出图像“马”的生成;当看到“草”时,注意力机制会重点突出图像 “草” 的生成,进而实现和文本匹配的图片生成。

图7 SpatialTransformer结构示意图
Unet 如何训练?
Stable Diffusion 里面 Unet 的学习目标是什么?简单来说就是去噪。那在为去噪任务设计训练集时,就可以通过向普通照片添加噪声来得到训练样本。具体来说,对于下面这张照片,用 random 函数生成从强到弱的多个强度噪声,比如图 8 里 0~3 有 4 个强度的噪声。训练时把噪声强度和加噪后图片输入到 Unet,计算预测噪声图和真正噪声图之间的误差损失,通过反向传播更新 unet 参数。

图8 去噪训练样本说明
训练好 Unet 后,如图 9 所示,从加噪图片中推断出噪声后,就可以用加噪图减掉噪声来恢复原图;重复这个过程,第一步预测噪声图后再减去噪声图,用更新后的加噪图进行第二步去噪,最终就能得到一张很清晰的生成图片。由于使用了高斯分布的 KL 散度损失,Unet 生成图片实际上是接近训练集分布的,和训练集有着相同像素规律。也就是说,使用真实场景的写实训练集去训练模型,它的结果就会具有写实风格,尽量符合真实世界规律。

图9 Unet网络采样阶段迭代
2 采样器迭代
这部分介绍下采样阶段中扩散模型如何多次迭代去除噪声,进而得到生成图片的潜在空间表示。提到采样器,要从最基础的采样器 DDPM(Denoising Diffusion Probabilistic Models)进行介绍[4]。DDPM 推导有点复杂,这里就用朴素一点的大白话结合几个关键公式来理清推导思路。
1 扩散模型的思路是,训练时先在图片上不断加噪来破坏图片,推理时对加噪后的图片去噪来恢复出原始图片。训练过程的 T 次迭代中,可推导出一个重要特性:任意时刻的 Xt 可以由 X0 和 β 表示,任意时刻的 X0 也可以由 Xt 和噪声 z 求得。

![]()
其中,第一行里 a 和 β 可以描述噪声强度;第二行,X0 为初始的干净图片,增加噪声 z 后生成加噪图片 Xt,后个公式由前个公式变换而来,表示加噪图片减去一定强度噪声,得到图片 X0。
2 问题变成,如何求逆向阶段的分布,即给定了一张加噪后图片,如何才能求得前一时刻没有被破坏得那么严重的略清晰图片。经过论文里的一顿推导,又得出两个重要结论:
① 逆向过程也服从高斯分布;② 在知道原始清晰图片时,能通过贝叶斯公式把逆向过程转换成前向过程,进而算出逆向过程分布。在公式上体现如下:
![]()
![]()
其中,第一行指的是给定 X0 情况下,逆向过程也服从高斯分布,并且利用贝叶斯公式把逆向过程转换成前向过程,前向过程是不断加噪的过程,可以被计算;第二行指的是,Xt 和 X0 由于可以相互转换,从公式上看,均值也可以从 Xt 减去不同噪声得到。
3 算出逆向过程分布后,就可以训练一个模型尽量拟合这个分布,而且模型预估结果也应该服从高斯分布:

其中,求均值公式里只包含 Xt 和噪声,由于 Xt 在训练时已知,那只需要得到模型输出的预估噪声,该值可由模型用 Xt 和 t 预估得到。
4 把逆向过程分布(也就是 Label 值)和模型的预估分布做比较,由于 ①KL 散度可以用来描述两个分布之间的差异和 ② 多元高斯分布的 KL 散度有闭式解,经过一番推导发现损失函数变成计算两个高斯分布的 KL 散度。
![]()
其中,q 分布是逆向过程分布,p 是模型预估分布,训练损失是求两个高斯分布的 KL 散度,即两个分布之间的差距。
5 DDPM 训练过程和采样过程的伪代码如下图所示。由于 DDPM 的高质量生成依赖于较大的 T(一般为 1000 以上),导致 Diffusion 前向过程特别缓慢,因此后续进一步有了 DDIM、PLMS 和 Euler A 等一些优化版采样器。

其中,训练阶段实际上是求真实噪声和模型预估噪声的 MSE 误差,再对 Loss 求导反向传播来训练模型;采样阶段,求得均值和方差后,采用重参数技巧来生成样本。
总结下,扩散模型采样阶段是对加噪后图片去噪来恢复出原始图片,基于 ① 任意时刻的图片均可以由原始图片和噪声表示;② 逆向过程的图片参数符合高斯分布,优化目标转化为计算逆向分布和预估分布的 KL 散度差异,并在采样阶段使用重参数技巧来生成图片。
3 CLIP 模型
在前面有提到,提示词 Prompt 文本利用文本模型转换成嵌入表示 context,作为 Unet 网络的 condition 条件。那问题来了,语义信息和图片信息属于两种模态,怎么用 attention 耦合到一起呢?这里介绍下用于提取语义信息的 CLIP 模型。
语义信息的好坏直接影响到了最终生成图片的多样性和可控性,那像 CLIP 这样的语言模型是如何训练出来的?是如何结合文本串和计算机视觉的呢?首先,要有一个具有文本串和计算机视觉配对的数据集。CLIP 模型所使用的训练集达到了 4 亿张,通过从网络上爬取图片及相应的标签或者注释。

图9 CLIP模型训练用到的图片和标签示例
CLIP 模型结构包含一个图片 encoder 和一个文字 encoder,类似于推荐场景常用到的经典双塔模型。
-
训练时,从训练集随机取出一些样本(图片和标签配对的话就是正样本,不匹配的话就是负样本),CLIP 模型的训练目标是预测图文是否匹配;
-
取出文字和图片后,用图片 encoder 和文字 encoder 分别转换成两个 embedding 向量,称作图片 embedding 和文字 embedding;
-
用余弦相似度来比较两个 embedding 向量相似性,并根据标签和预测结果的匹配程度计算损失函数,用来反向更新两个 encoder 参数。
-
在 CLIP 模型完成训练后,输入配对的图片和文字,这两个 encoder 就可以输出相似的 embedding 向量,输入不匹配的图片和文字,两个 encoder 输出向量的余弦相似度就会接近于 0。
推理时,输入文字可以通过一个 text encoder 转换成 text embedding,也可以把图片用 image encoder 转换成 image embedding,两者就可以相互作用。在生成图片的采样阶段,把文字输入利用 text encoder 转换成嵌入表示 text embedding,作为 Unet 网络的 condition 条件。

图10 CLIP模型结构示意图
四 本文小结
AI 绘画各种应用不断涌现,目前有关 Stable Diffusion 的文章主要偏向应用介绍,对于 Stable Diffusion 技术逻辑的介绍还是比较少。这篇文章主要介绍了 Stable Diffusion 技术结构和各个重要组成模块的基本原理,希望能够让大家了解 Stable Diffusion 是如何运行的,才能更好地控制 AI 绘画生成。AI 绘画虽然还面临一些技术挑战,但随着技术不断迭代和发展,相信 AI 能够在更多领域发挥出惊喜生产力。
(本文参考了 stable diffusion 官方仓库以及一些解读 Blog,结合个人在其他 ML 领域经验的一些解读。如有不合理的地方,欢迎在评论区指出。)
参考链接
1 GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model
2 The Illustrated Stable Diffusion:The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
3 由浅入深了解 Diffusion Model
4 Denoising Diffusion Probabilistic Models