特征工程-特征清洗
特征清洗
在进行玩特征理解后,我们大致理解了面对的数据中包含哪些内容。下一阶段,我么需要对数据中的内容进行进一步分析处理,针对不同数据进行清洗。数据清洗是对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性
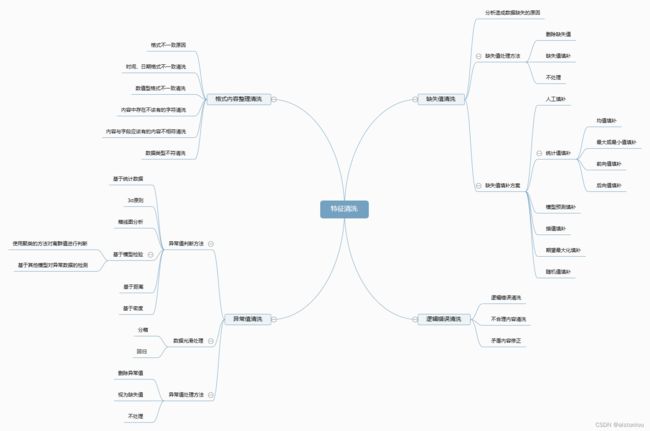
一.格式内容清洗
原因
- 数据通常由人工收集或用户填写而来,很有可能存在格式和内容上的一些问题。
- 不同版本的程序产生的内容或格式不一致;
- 不同数据源采集而来的数据内容和格式定义不一致;
时间、日期格式不一致清洗
将时间和日期格式进行统一化后再进行统一处理
- 建议将年月日时间格式统一为 “2019-07-20 10:99:22”;
- 同时将不同时间颗粒度的时间数据进行对其处理,例如秒、毫秒、微秒的数据进行数据格式的对齐;
数值格式不一致清洗
根据实际需要将,不同保存格式的数据统一化,例如将一个特征下的所有数据全部统一为浮点数(float)类型。
内容中存在不应该有的字符
将不应该有的字符进行筛选与剔除,避免后续处理的问题
内容与字符要求不相符
由于人为填写错误等问题,造成填写错误或者是前端数据读取时没有校验,导致导入数据时部分没有对其或者全部没有对其。需要将其进行识别并处理。
数值类型不相符清洗
由于人为定义错误、转存、加载等原因,数据类型经常会出现数据类型不符的情况。例如:金额特征是字符串类型,实际上应该转换成int/float型。
二.逻辑错误清洗
1.数据重复
对于每个特征值都完全相同的重复数据,应该删除重复值,只保留一条。
pd.drop_duplicates()
对于数据不完全相同,但是作用完全相同的数据,也应该按需进行删除
pd.drop_duplicates(subset=['XX'], keep='last')
2.不合理内容
根据具体常识,可以明显判断出来该特征的部分数据不合理的,应该进行修改删除。例如:age:200, 月份:14
3.矛盾内容
有些字段是可以互相验证的,举例:身份证号是1101031980XXXXXXXX,然后年龄填18岁。在这种时候,需要根据字段的数据来源,来判定哪个字段提供的信息更为可靠,去除或重构不可靠的字段。
三.异常值清洗
在数据分布中,处于特定分布区域或范围之外的数据通常被定义为异常或者噪声。
异常通常分为两种:
- 伪异常:由于业务运营策略改变导致的数据波动,是正常的业务反应,而不是数据本身的异常;
- 真异常:非业务变化带来的巨大的数据变化,即数据本身的异常。
3.1 异常值判断
3.1.1. 基于统计分析
过分析统计数据的散度情况,即数据变异指标,来对数据的总体特征有更进一步的了解,对数据的分布情况有所了解,进而通过数据变异指标来发现数据中的异常点数据。
常用的数据变异指标有极差、四分位数间距、均差、标准差、变异系数等等,变异指标的值大表示变异大、散布广;值小表示离差小,较密集。
3.1.2. 3σ原则
若数据存在正态分布,在3σ原则下,异常值为一组测定值中与平均值的偏差超过3倍标准差的值。如果数据服从正态分布,距离平均值3σ之外的值出现的概率为 P ( ∣ x − μ ∣ > 3 σ ) < = 0.003 P(|x - μ| > 3σ) <= 0.003 P(∣x−μ∣>3σ)<=0.003,属于极个别的小概率事件。如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。
3.1.3. 箱线图
箱线图提供了识别异常值的一个标准:如果一个值小于QL-1.5IQR或大于OU+1.5IQR的值,则被称为异常值。
箱型图判断异常值的方法以四分位数和四分位距为基础,四分位数具有鲁棒性:25%的数据可以变得任意远并且不会干扰四分位数,所以异常值不能对这个标准施加影响。因此箱型图识别异常值比较客观,在识别异常值时有一定的优越性。
3.1.4. 基于模型检测
首先建立一个数据模型,异常是那些同模型不能完美拟合的对象;如果模型是簇的集合,则异常是不显著属于任何簇的对象;在使用回归模型时,异常是相对远离预测值的对象。
3.1.5. 基于距离检测
基于距离的方法是基于下面这个假设:即若一个数据对象和大多数点距离都很远,那这个对象就是异常。通过定义对象之间的临近性度量,根据距离判断异常对象是否远离其他对象,主要使用的距离度量方法有绝对距离(曼哈顿距离)、欧氏距离和马氏距离等方法。
3.1.6. 基于密度
考察当前点周围密度,可以发现局部异常点,离群点的局部密度显著低于大部分近邻点,适用于非均匀的数据集。
3.2 数据光滑处理
检测出异常值后,对异常值进行处理。
3.2.1 分箱
分箱方法通过考察数据的近邻来光滑数据的值,有序值分布到不同的"桶"或者箱中,得到局部光滑的结果。
分箱方法:
- 等高方法
- 等宽方法
- 决策树方法
3.2.2 回归
可以用一个函数(如回归函数)拟合数据来光滑数据。线性回归涉及找出拟合两个属性(或变量)的“最佳”线,是的一个属性可以用来预测另一个。多元线性回归是线性回归的扩展,其中涉及的属性多于两个,并且数据拟合到一个多维曲面。
3.3 异常值处理方法
对异常值处理,需要具体情况具体分析,异常值处理的方法常用有四种:
- 删除含有异常值的记录;
- 将异常值视为缺失值,交给缺失值处理方法来处理;
- 使用均值/中位数/众数来修正;
- 不处理。
四.缺失值清洗
4.1 造成缺失值的原因
- 信息暂时无法获取
- 信息没有获取成功
- 获取的信息不可解析或不可用
- 获取信息的要求性比较高,造成信息缺失
4.2缺失值处理方法
- 数据删除;
- 数据填充;
- 不处理;
4.3 数据填充方法
- 人工填充
- 统计值填补
- 均值填补
- 最大或最小值填补
- 前向值填补
- 后向值填补
- 模型预测填补
- 插值填补
- 期望最大化填补
- 随机值填补
参考文章:
原文链接:https://blog.csdn.net/zhaodedong/article/details/98001930