[论文精读]Brain Network Transformer
论文网址:[2210.06681] Brain Network Transformer (arxiv.org)
论文代码:GitHub - Wayfear/BrainNetworkTransformer: The open-source implementation of the NeurIPS 2022 paper Brain Network Transformer.
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用!
目录
1. 省流版
1.1. 心得
1.2. 论文框架图
2. 论文逐段精读
2.1. Abstract
2.2. Introduction
2.3. Background and Related Work
2.3.1. GNNs for Brain Network Analysis
2.3.2. Graph Transformer
2.4. Brain Network Transformer
2.4.1. Problem Definition
2.4.2. Multi-Head Self-Attention Module (MHSA)
2.4.3. ORTHONORMAL CLUSTERING READOUT (OCREAD)
2.4.4. Generalizing OCREAD to Other Graph Tasks and Domains
2.5. Experiments
2.5.1. Experimental Settings
2.5.2. Performance Analysis (RQ1)
2.5.3. Ablation Studies on the OCREAD Module (RQ2)
2.5.4. In-depth Analysis of Attention Scores and Cluster Assignments (RQ3)
2.6. Discussion and Conclusion
2.7. Appendix
2.7.1. Training Curves of Different Models with or without StratifiedSampling
2.7.2. Transformer Performance with Different Node Features
2.7.3. Statistical Proof of the Goodness with Orthonormal Cluster Centers
2.7.4. Running Time
2.7.5. Number of Parameters
2.7.6. Parameter Tuning
2.7.7. Software Version
2.7.8. The Difference between Various Initialization Methods
3. 知识补充
3.1. Positional embedding
3.2. Centrality
3.3. Weisfeiler-Lehman Test
3.4. Xavier uniform initialization
3.5. Gram-Schmidt process
3.6. Variance inflation factor
3.7. Eigendecomposition
4. Reference List
1. 省流版
1.1. 心得
(1)在介绍中说根据一些区域的共同激活和共同停用可以分为不同的功能模块。这样的话感觉针对不同的疾病就需要不同的图谱了。但是我又没去研究这个图谱,,,=。=而且还是大可能看玄学
(2)⭐作者认为功能连接矩阵阻碍①中心性(其实可以算啊...我忘了叫啥了反正我最开始写的那篇a gentle introduction of graph neural network([论文精读]A Gentle Introduction to Graph Neural Networks_a gentle introduction to graph neural networks pdf-CSDN博客)吗啥玩意儿的里面有计算的方式。不过感觉算的是连接强度的中心性而不是位置中心性。emm...位置中心性应该也本不重要吧?),②空间性(我更认为功能>结构性,在脑子里面...),③边缘编码(我不是太熟悉这玩意儿不过能大概或许get到。这...的确是个问题,但是我还没有想过它是否真的影响很大)
(3)整笑了这文章把我的疑惑也写进去了这FC本体连接性确实太强了,十六万哈哈哈哈哈哈
(4)对ROI聚类持有保留态度(读完略有改观,参见框架图自我想法)
1.2. 论文框架图
![[论文精读]Brain Network Transformer_第1张图片](http://img.e-com-net.com/image/info8/65737d464ea44dad894dca64e4084fad.jpg)
2. 论文逐段精读
2.1. Abstract
①They intend to obtain positional information and strength of connections
②⭐They propose an ORTHONORMAL CLUSTERING READOUT operation, which is based on self-supervised soft clustering and orthonormal projection
2.2. Introduction
①⭐Research in the medical field findings some regions might work together when activate or deactivate. Then the brain can be divided into different ROIs to better analyse diseases. Unfortunately, they may not be absolutely reliable.
![[论文精读]Brain Network Transformer_第2张图片](http://img.e-com-net.com/image/info8/f1181b5900c243e5b83193021e7187ab.jpg)
②Transformer based models on fMRI analysis have been prevalent these years. Such as GAT with local aggregation, Graph Transformer with edge information injection, SAN with eigenvalues and eigenvectors embedding and Graphomer with unique centrality and spatial/edge encodin
③⭐It may lose centrality, spatial, and edge encoding when adopting functional connectivity (FC)
④In FC, every node has the same degree(不是...你不能砍一点吗...)and only considers the one-hop information
⑤The edge in formation in brain is the strength of connevtivity but in biology is probably whether they connect
⑥In molecule, the number of nodes < 50, the number of edges < 2500. In FC, the number of node < 400, the number of edges < 160000
⑦Thereupon, the authors put forward BRAIN NETWORK TRANSFORMER (BRAINNETTF), which uses the "effective initial node features of connection profiles"(我不知道这是啥,文中说它可以“自然地为基于变压器的模型提供了位置特征,避免了特征值或特征向量的昂贵计算”)
⑧In order to reduce the impact of inaccurate regional division, they design the ORTHONORMAL CLUSTERING READOUT, which is a global pooling operator.
![[论文精读]Brain Network Transformer_第3张图片](http://img.e-com-net.com/image/info8/fc984def96fb48b2b7778002183bc1ea.jpg)
⑨It is a big challenge that open access datasets are limited in brain analysis
unleash vt.使爆发;发泄;突然释放[VN] ~ sth (on/upon sb/sth)
2.3. Background and Related Work
2.3.1. GNNs for Brain Network Analysis
①GroupINN: reduces model size and is based on grouping
②BrainGNN: utilizes GNN and special pooling operator
③IBGNN: analyzes disorder-specific ROIs and prominent connections
④FBNetGen: brings learnable generation of brain networks
⑤STAGIN: extracts dynamic brain network
2.3.2. Graph Transformer
①Graph Transformer: injects edge information and embeds eigenvectors as position
②SAN: enhances positional embedding
③Graphomer: designs a fine-grained attention mechanism
④HGT: adopts special sampling algorithm
⑤EGT: edge augmentation
⑥LSPE: utilizes learnable structural and positional encoding
⑦GRPE: improves relative position information encoding
2.4. Brain Network Transformer
2.4.1. Problem Definition
①Setting a brain as ![]() , where
, where  denotes the number of ROIs
denotes the number of ROIs
②The overall framework, which mainly contains  -layer MHSA and OCREAD parts:
-layer MHSA and OCREAD parts:
![[论文精读]Brain Network Transformer_第4张图片](http://img.e-com-net.com/image/info8/72959b0348b9447d854f39f417ec6b7a.jpg)
where ![]() ,
, ![]() ,
, 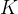 is the number of clusters;
is the number of clusters;
cross-entropy loss applied throughout.
2.4.2. Multi-Head Self-Attention Module (MHSA)
①⭐这里用中文说。作者认为在特征矩阵 中,将某个节点
中,将某个节点 所在的行定义为其连接轮廓
所在的行定义为其连接轮廓 。这样的方法是优于节点度(FC满度没啥好谈的)、特征向量嵌入(这个我没有特别了解)、节点特征(可能是啥性别年龄站点之类的)。
。这样的方法是优于节点度(FC满度没啥好谈的)、特征向量嵌入(这个我没有特别了解)、节点特征(可能是啥性别年龄站点之类的)。
②⭐Through previous works, it is known that edge weights generated in attention score will significantly reduce the effectiveness. We all know that there are a lot of edges, redundant edges...
③⭐So they use as the node feature(啊!!?emm)
④They apply vanilla pair-wise attention mechanism and remove edge weights or relative position information in attention score learning
⑤Thus, in Multi-Head Self-Attention (MHSA) part:
![]()
For each layer  , the specific function is:
, the specific function is:
where ![]() ,
, ![]() denotes concatenation,
denotes concatenation,  represents the number of heads, all the
represents the number of heads, all the  are learnable parameters and
are learnable parameters and ![]() is the first dimension of
is the first dimension of ![]() ,
, ![]() is the head.
is the head.
我快忘记注意力机制了,所以这里贴一下多头注意力:


可以见得,作者的![]() ,
, ![]() ,
, ![]() ;
;
然后第一层的话就是:
![]()
多头注意力的图大概是这样:
![[论文精读]Brain Network Transformer_第5张图片](http://img.e-com-net.com/image/info8/860830149e5b477e80226563ea5aa03b.jpg)
2.4.3. ORTHONORMAL CLUSTERING READOUT (OCREAD)
①GNN with Sum(·) readout has the same effectiveness as Weisfeiler-Lehman Test. Also, other researchers propose sort pooling and layer-wise readout
②⭐重要的部分还是又来中文了。作者觉得现在的读出没有体现同功能模块的共激活和共抑制性,他们想给ROI聚类。好了,那么我的问题是,你如果要给400个ROI聚类你为什么不直接用STDAGCN(Yang et al., 2023)里面那种22个或者39个ROI?
③They define cluster centers each with dimensions and give their clustering function (a Softmax projection):
![]()
where ![]() , <·,·> is inner product sign,
, <·,·> is inner product sign, ![]() is the final node output of MHSA,
is the final node output of MHSA, ![]() represents the probability of the node being assigned to cluster
represents the probability of the node being assigned to cluster  and
and ![]()
④The graph-level embedding ![]()
⑤⭐However, there is no answer/ground truth in clustering. Thus, they found it is important how initializes  . They design a two-step process to initialize and called this progress Orthonormal Initialization. They firstly take Xavier uniform initialization to initialize random centers
. They design a two-step process to initialize and called this progress Orthonormal Initialization. They firstly take Xavier uniform initialization to initialize random centers ![]() and secondly utilize Gram-Schmidt process to get orthonormal bases :
and secondly utilize Gram-Schmidt process to get orthonormal bases :
(1)Theoretical Justifications
①Theorem 3.1: 作者似乎是在表述希望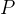 之间有较大差异(即清楚地知道每个点更大概率应该在哪而不是处于一个很边缘的地带)。对于个簇来说,
之间有较大差异(即清楚地知道每个点更大概率应该在哪而不是处于一个很边缘的地带)。对于个簇来说,![]() 是显而易见的事情,然后可以通过和
是显而易见的事情,然后可以通过和![]() 求出方差。作者希望方差是偏大的,越大的方差能给出越多的信息。因此它们设了一个
求出方差。作者希望方差是偏大的,越大的方差能给出越多的信息。因此它们设了一个
![]()
说这是个半径为 的球,
的球,![]() 是什么fracture vectors(我不造这是啥也搜不到),
是什么fracture vectors(我不造这是啥也搜不到), 是这个球
是这个球![]() 的体积。
的体积。
这个公式(没说是啥但是好像可能会在附录详细说明)将在是标准正交基时达到最大。可能是想证明标准正交基会带来更大的可区分度吧。
②Theorem 3.2: 作者觉得“对于没有已知解析形式的一般读出函数,使用正交簇中心初始化具有更大的概率获得更好的性能”(已知的解析形式是啥?max, sum, mean那些有吗?)。他们先建立了一个回归:
![]()
他们想找一个方差扩大/膨胀因子(variance inflation factor, VIF)(然后就没细说了)。他们提出的定理是通过显著性水平![]() ,可以看出在标准正态中心里抽样弃真的概率是小于在非标准正态中心的(附录应该也有证明)
,可以看出在标准正态中心里抽样弃真的概率是小于在非标准正态中心的(附录应该也有证明)
circumvent v. 规避,回避;(为避免某物而)改道,绕过;克服(问题,困难)(尤指暗中智取);欺骗,智胜
2.4.4. Generalizing OCREAD to Other Graph Tasks and Domains
①In other brain network modalities, they might adopt structural connectivities (SC) instead of FC. Compared with FC detecting the BOLD, SC measures the fiber tracts between brain regions.
②因此,作者觉得他提出的聚类也很适合用在结构连接上,因为结构连接也是物理位置上相近的ROI可能存在相似行为。只是要把标准正交改成基于物理距离的而不是功能属性的。
③They think their works can be extended to the biomedical field...
2.5. Experiments
2.5.1. Experimental Settings
(1)Autism Brain Imaging Data Exchange (ABIDE) dataset
①Samples: 1009, with 516 (51.14%) ASD and 493 HC (48.86%)
②Atlas: Craddock 200
③Proper use of stratified sampling can reduce inter group differences
④Task: diagnose patients (classification)
(2)Adolescent Brain Cognitive Development Study (ABCD) dataset
①Samples: 7901 with 3961 (50.1%) female and 3940 (49.9%) male
②Atlas: HCP 360
③Task: predict sex
(3)Mertics (choose the mean value on 5 random runs)
①AUROC (the highest only)
②Accuracy
③Sensitivity: true positive rate
④Specificity: true negative rate
(4)Implementation details
①Two-layer Multi-Head Self-Attention Module applied
②Number of heads ![]() for each layer
for each layer
③Data split: randomly, 70% for training, 10% for validation, 20% for testing
④Optimizer: Adam
⑤Learning rate: 
⑥Weight decay:
⑦Batch size: 64
⑧Epochs: 200
(5)Computation complexity
①Time complexity of MHSA: ![]() , where is the number of layers, is the number of heads, is the number of nodes
, where is the number of layers, is the number of heads, is the number of nodes
②Time complexity of OCREAD: ![]() , where is the number of clusters
, where is the number of clusters
③Overall computation complexity: ![]() , the same as BrainGNN and BrainGB. (I guess they regard
, the same as BrainGNN and BrainGB. (I guess they regard ![]() and
and ![]() as constants)
as constants)
2.5.2. Performance Analysis (RQ1)
Comparison of different models:
![[论文精读]Brain Network Transformer_第6张图片](http://img.e-com-net.com/image/info8/46b6527097884280be5f28bd91d554ae.jpg)
2.5.3. Ablation Studies on the OCREAD Module (RQ2)
(1)OCREAD with varying readout functions
Comparison when changes readout function:
![[论文精读]Brain Network Transformer_第7张图片](http://img.e-com-net.com/image/info8/9b4e796c087d41a9bb758a8dc063d9be.jpg)
(2)OCREAD with varying cluster initializations
①Different initialization procedures: a) randomly cluser with Xavier uniform, b) learn to cluster by gradient descent, c) their orthonormal
②Hyper-parameter ![]()
③The hyper-parameter influence figures:
![[论文精读]Brain Network Transformer_第8张图片](http://img.e-com-net.com/image/info8/e61aebef114d4d4c972f5ffa22e677c6.jpg)
2.5.4. In-depth Analysis of Attention Scores and Cluster Assignments (RQ3)
①The first layer of MHSA heatmap on ABCD:
![[论文精读]Brain Network Transformer_第9张图片](http://img.e-com-net.com/image/info8/0297123ee2da47b38617e5df165c97ff.jpg)
(作者说不画ABIDE的是因为“没有可用的功能模块标签用于ABIDE数据集的图谱”?咦,那别的可视化ABIDE的是哪里来的啊。怎么会没有呢?)
② value in orthonormal and random initializations when the number of cluster 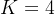 :
:
![[论文精读]Brain Network Transformer_第10张图片](http://img.e-com-net.com/image/info8/7790db7b6b804808a43e5286dcc94c26.jpg)
(我其实没有特别看懂这个图,作者原文是“可视化的数值是每个数据集测试集中所有受试者的平均P值。从可视化中,我们观察到(a)基于附录H,标准正交初始化比随机初始化产生更多的类间判别P;(b)在每个类中,正交初始化鼓励节点组成组。”)
2.6. Discussion and Conclusion
They proposed BRAIN NETWORK TRANSFORMER (BRAINNETTF) which contains ORTHONORMAL CLUSTERING READOUT.
preemption n. 优先购买;强制收购;抢先占有;取代
2.7. Appendix
2.7.1. Training Curves of Different Models with or without StratifiedSampling
Training curves with and without stratified sampling based on different sites:
![[论文精读]Brain Network Transformer_第11张图片](http://img.e-com-net.com/image/info8/97bb44453749441cb0134653d3548889.jpg)
it can be seen that stratified sampling brings more stable performance and lower difference of performances
2.7.2. Transformer Performance with Different Node Features
The AUROC with different node features:
![[论文精读]Brain Network Transformer_第12张图片](http://img.e-com-net.com/image/info8/99c87bac6213449d8332b0cf5167b259.jpg)
where connection profile is the row of one node in FC;
identity feature is the unique one-hot vector for each node;
eigen feature is the eigendecomposition of FC, it generates k dimension eigenvector for each node from k eigenvectors(这句话我paraphrase得和狗屎一样啊,离谱,上翻译“从k个特征向量中为每个节点生成一个k维特征向量”).
⭐这有个很好玩的点就是作者觉得添加这些信息反而没有增强模型性能。其实按理来说是不应该的吧,还是说只是因为注意力机制对于这种比较特别,反而冗余了?我不造
2.7.3. Statistical Proof of the Goodness with Orthonormal Cluster Centers
我现在暂时不想折磨我自己
(1)Proof of Theorem 3.1
(2)Proof of Theorem 3.2
2.7.4. Running Time
Comparison of running time:
![[论文精读]Brain Network Transformer_第13张图片](http://img.e-com-net.com/image/info8/4610fcee046c4362bd790ed9ca9df3e0.jpg)
this is mainly because SAN and Graphormer are more suitable for sparse graph
2.7.5. Number of Parameters
![[论文精读]Brain Network Transformer_第14张图片](http://img.e-com-net.com/image/info8/33ef2972aae04931a3815a1796aeb0d4.jpg)
2.7.6. Parameter Tuning
①They achieve BrainGB, BrainGNN and FBNetGen with open source codes; SAN and graphormer (“我们收集了它们的存储库,并针对大脑网络数据集进行了修改”?啥玩意儿); BrainNetCNN and VanillaTF by themselves
②They list the hyper-parameters they have tried and I won't go into too much detail here.
2.7.7. Software Version
![[论文精读]Brain Network Transformer_第15张图片](http://img.e-com-net.com/image/info8/50b0debb09584e2f9f627b4f0727219b.jpg)
2.7.8. The Difference between Various Initialization Methods
①They defined a formula to prove orthonormal initialization can bring higher difference:
![]()
②Through t-test, the margins between orthonormal and random are significant

3. 知识补充
3.1. Positional embedding
参考学习:Transformer中的位置嵌入究竟应该如何看待? - 知乎 (zhihu.com)
3.2. Centrality
参考学习:度中心性、特征向量中心性、中介中心性、连接中心性 - 知乎 (zhihu.com)
3.3. Weisfeiler-Lehman Test
学了无数百次了学一次忘一次那就再学一次。不过确实,它不就是那个one-hop GCN吗
参考学习:什么是Weisfeiler-Lehman(WL)算法和WL Test? - 知乎 (zhihu.com)
3.4. Xavier uniform initialization
参考学习1:深度学习中,Xavier初始化 是什么?_xavier初始化和randn-CSDN博客
参考学习2:深度学习:零散知识——xavier初始化 - 知乎 (zhihu.com)
3.5. Gram-Schmidt process
参考学习:正交矩阵和 Gram-Schmidt 正交化[MIT线代第十七课] - 知乎 (zhihu.com)
3.6. Variance inflation factor
参考学习1:如何理解方差膨胀因子(Variance Inflation Factor,VIF)? - 知乎 (zhihu.com)
参考学习2:方差扩大因子_百度百科 (baidu.com)
3.7. Eigendecomposition
参考学习1:【矩阵论】特征分解 - 知乎 (zhihu.com)
参考学习2:特征分解_百度百科 (baidu.com)
4. Reference List
Kan X. et al. (2022) 'Brain Network Transformer', NeurIPS. doi: https://doi.org/10.48550/arXiv.2210.06681
Yang R. et al. (2023) 'Spatial-Temporal DAG Convolutional Networks for End-to-End Joint Effective Connectivity Learning and Resting-State fMRI Classification', NeurIPS 2023. doi: https://doi.org/10.48550/arXiv.2312.10317