云原生改造续篇--服务的调用链路和可观测性
一、背景
随着业务的高速发展,CSDN的整体应用架构也在持续不断的进化。在过去的两年时间里,技术团队已对整体架构进行了多次重要重构,如全面微服务化、Serverless化改造、多云部署等等。
在上阶段云原生改造期间,我们同期还实施了微服务注册及流量管控方案,通过云原生网络2.0模型和Consul微服务注册框架实现服务发现和负载均衡。此外,在服务跨云迁移的过度架构中,为快速构建业务全景监控体系,降低运维工作量,我们基于自建的联邦Prometheus系统,再结合华为云APM、阿里云AHAS等云产品,快速实现了对业务系统进行全方位的监控。
历经应用架构重构和跨云迁移后,我们的系统规模和复杂度发生大幅变化,这也给系统稳定性的建设带来了新的问题:
-
服务调用链路复杂:当前业务系统已全面k8s化,但内网调用链路仍走Nginx代理,增加了系统的复杂性和成本,且微服务架构下,系统折分应用越来越多,在突发流量面前可能导致性能瓶颈。
-
缺乏统一的可观测平台:各业务线并未完全纳入统一的可观测性平台,导致难以掌握系统对外接口的完整调用链路和性能质量。如果在故障排除和性能优化时需要在不同云厂商控制台和工具之间切换,可能无法及时定位故障。
随着公司云原生战略的有序推进,运维团队在横向高可用保障和可观测性等方面加大了人力资源投入,也是出于对资源的合理利用以及对系统性能和可靠性的追求。故此,自2023年Q2季度开始,我们在上述方案的基础上开始着手优化服务调用链路并全面构建可观测性平台,具体方案将在下节展开描述。
二、方案
1、服务调用链路
CSDN业务架构通过两套OpenResty集群作为流量接入层,分别承接业务线内外网的流量分发。在全面K8S化的过程中,我们并没有使用K8S本身提供的内建服务发现机制,而是通过整合云原生网络2.0模型和Consul微服务注册框架,使流量接入层直达后端容器,实现跨云平台、跨业务线的服务发现和互通性。其中,conusl架构图如下:

在上述基础上,为进一步降低内网调用链路的复杂性,同时考虑到资源成本、部署环境和团队技术栈等因素,我们决定采用Consul+Openfeign的组合技术栈实现服务间的内部通信。其中,Consul充当了服务注册与发现的角色,同时也支持故障转移和多数据中心部署。而Openfeign作为声明式的客户端调用框架,为服务调用提供了简洁和优雅的编程体验。
相较于OpenResty+Consul的方式,该方案优势有:
-
减少一层额外的代理组件和网络请求,降低内网调用链路的复杂性,减少潜在的故障点
-
服务之间的交互更加清晰,更具灵活性和可扩展性,有助于应对不断变化的云原生环境需求
-
Openfeign可以与Spring Cloud等微服务框架无缝集成,能提供更多方案选择
2、可观测性
近年来,随着微服务、容器、Serverless等部署方式在企业的迅速采用,传统的监控技术和⼯具很难跟踪这些分布式架构中的调用链路和相互依赖关系,已无法满足企业对复杂 IT 系统在可控性、稳定性等方面的要求。2018年,CNCF 率先将“可观测性”一词引入 IT 领域,并称可观测性是云原生时代必须具备的能力。
鉴于现有的跨云迁移架构,我们意识到依赖多个云服务提供商的可观测性商业产品,虽然节省了不少运维人力成本,但也带来了一些问题,以及对商业产品的过度依赖。比如开发人员在故障排除和性能优化时需要在不同云厂商控制台和工具之间切换,这种分散的工作流程不仅耗时耗力,还降低了开发人员的工作效率。此外,未来也无法确保商业产品能够持续满足不断变化的需求。对此,技术团队决定基于OpenTelemetry+Grafana技术栈(Tempo,Loki,Grafana)构建可观测性平台,架构图示意如下:
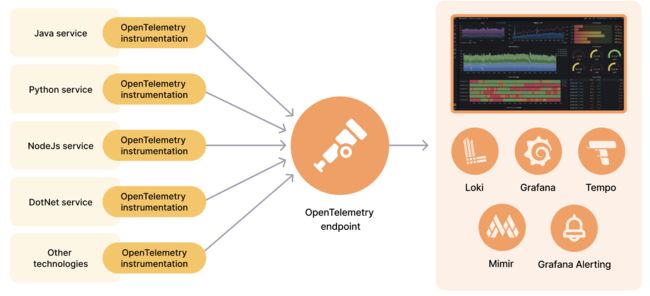
首先使用 Opentracing 协议的采集器(如Otel-Collector),实现对分布式架构的应用进行端到端的链路分析;再通过Grafana可视化工具对应用日志、监控、服务链路数据等统一汇聚,进行各项数据的关联分析。帮助技术人员迅速定位性能瓶颈,缩短故障修复时间。相较于分散的云厂商监控产品,自建可观测性的优势在于:
-
能使更自护地掌握和控制监控系统的方方面面,为每一个完整的应用构建全链路的可观测性,满足云平台、云原生、应用及业务相关的监测需求。
-
对研发人员友好:能提供统一的查询平台界面,研发人员不再需要学习和适应多个云厂商的可观测工具,且能关联多维度的数据,实现同一界面的灵活跳转,极大提升协作效率。
- 开源共建:支持OpenTelemetry SDK进行自定义埋点的增强,横向连接数据库、中间件等三方系统,建立完善的平台观测能力,实现端到端的整体观测解决方案。
-
SLO体系建立:建立多维度的联动监控,比如页面打开速度、页面稳定性和外部服务调用成功率等,更贴近用户真实使用体验,对生产故障分级分级告警,建立一整套生产故障应对机制。
-
有助于建立企业内部的专业知识库,有效地联结“开发、测试、运维团队”;并通过不断打磨逐渐完善平台,为业务的发展提供更强有力的支持。
三、落地实践
1、服务调用
-
调用方式
我们采用Consul和OpenFeign来实现服务间的内部通信,通过Consul进行服务的注册和发现,服务名需保证唯一性,将服务名作为解析的目标,替换原有URL方式。默认情况下,采用轮询策略来进行服务的负载均衡。
@FeignClient(name = "${xxxAPI:xxx-service}", fallbackFactory = EduCoreServiceFallBack.class)
public interface EduCoreClient {
@GetMapping("/test/testConsul")
ResponseDto-
Consul健康检查配置:需确保query-passing的属性为true,以排除掉失效的服务节点
spring:
cloud:
consul:
discovery:
query-passing: true-
服务降级
package xxx.api.service.fallback;
@Slf4j
@Component
public class EduCoreServiceFallBack implements FallbackFactory {
@Override
public XxxClient create(Throwable throwable) {
return new EduCoreClient() {
@Override
public ResponseDto 2、可观测性
业务测
方式一:业务测采用SpringBoot2.7+Sleuth-Otel实现链路数据上报
-
依赖引入
spring-cloud-sleuth-otel-dependencies
opentelemetry-bom
spring-cloud-sleuth-otel-autoconfigure
opentelemetry-exporter-otlp-
上报配置
spring:
sleuth:
sampler:
probability: 1
otel:
config:
trace-id-ratio-based: 1.0
exporter:
otlp:
endpoint: http://xxxxxx:4317-
结构化日志输出,注入traceID、spanID
value="[%d{yyyy-MM-dd HH:mm:ss.SSS}] [${ENV}] [traceId=%X{trace_id} spanId=%X{span_id}] [%X{TRACE_ID}] [%-5level] [%line] %logger{36} - %msg %n"方式二:以java agent的形式引入 opentelemetry-javaagent.jar包,接入opentelemetry。
-
启动方式
java -javaagent:opentelemetry-javaagent.jar \
-Dfile.encoding=UTF-8 \
-Dotel.metrics.exporter=none \
-Dotel.traces.exporter=otlp \
-Dotel.traces.exporter=otlp \
-Dotel.exporter.otlp.endpoint=http://xxx:4317 \
-Dotel.service.name=xxx \
-jar target/xxx.jar3、运维侧
基于OpenTelemetry+Grafana全家桶快速实现对指标(metrics),日志(logs)和链路追踪(Tracing)三大信号的观测,部署示例参考官方docker-compose部署方法,将通过docker-compose部署Prometheus、Promtail、Loki、Tempo以及Grafana,最后部署应用并验证,示例图及配置如下:

-
otel-collector.yaml
receivers:
otlp:
protocols:
grpc:
http:
prometheus:
config:
scrape_configs:
- job_name: 'springboot-app'
metrics_path: '/actuator/prometheus'
scrape_interval: 10s
static_configs:
- targets: ['xxxxxxxx:8081']
processors:
batch:
exporters:
otlp:
endpoint: tempo:4317
tls:
insecure: true
prometheusremotewrite:
endpoint: "http://prometheus:9090/api/v1/write"
loki:
endpoint: "http://loki:3100/loki/api/v1/push"
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlp]
metrics:
receivers: [prometheus]
processors: [batch]
exporters: [prometheusremotewrite]
logs:
receivers: [otlp]
processors: [batch]
exporters: [loki]-
数据源配置如下
prometheus:

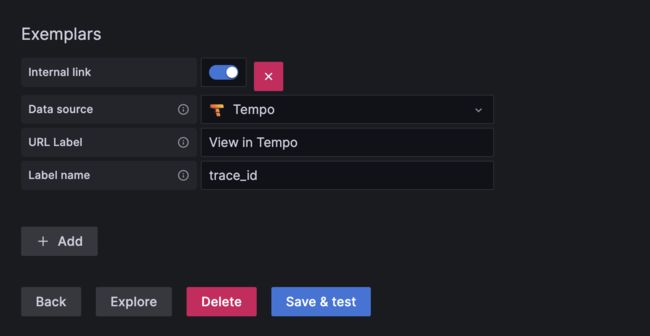
tempo:


Loki:


-
效果展示:多维数据关联跳转
通过请求延迟等指标看到Exemplar与Tempo的关联,方便从Prometheus面板跳转至Tempo:

在Tempo面板可以看到产生的跟踪,并且可以通过该跟踪信息,一键查询所关联的日志:
