BM25相关文档
原文链接:
https://my.oschina.net/stanleysun/blog/1617727
https://www.jianshu.com/p/b51a1b35d853
https://blog.csdn.net/u011734144/article/details/79559295#commentBox
https://www.elastic.co/guide/cn/elasticsearch/guide/current/pluggable-similarites.html
https://blog.csdn.net/Oscar6280868/article/details/81288772
搜索中的权重度量利器: TF-IDF和BM25
我们在网上搜东西时,搜索引擎总是会把相关性高的内容显示在前面,相关性低的内容显示在后面。那么,搜索引擎是如何计算关键字和内容的相关性呢?这里介绍2种重要的权重度量方法:TF-IDF和BM25。
在进入理论探讨之前,我们先举个例子。假如,我们想找和“Lucence”相关的文章。可以想一下,那些内容里只出现过一次“Lucence”的文章,有可能是在讲某种技术,顺便提到了Lucence这个工具。而那些出现了两三次“Lucence”的文章,很可能是专门讨论Lucence的。通过直觉,我们可以得出判断:关键字出现的次数越多,文档与关键字的匹配度越高。
TF的定义
有一个专门的术语来表示关键字出现的次数,叫“词频”(Term Frequency), 简写为TF。TF越大,通常相关性越高。
但是,你可能会发现一个问题。 如果一篇小短文里出现了一次“Lucence”,而一部好几百页的书里提到两次“Lucence”,我们不会认为那部书与Lucence相关性更高。为了消除文档本身大小的影响,一般使用TF时会把文本长度考虑上:
TF Score = 某个词在文档中出现的次数 / 文档的长度举例:某文档D,长度为200,其中“Lucence”出现了2次,“的”出现了20次,“原理”出现了3次,那么:
TF(Lucence|D) = 2/200 = 0.01
TF(的|D) = 20/200 = 0.1
TF(原理|D) = 3/200 = 0.015“Lucence的原理”这个短语与文档D的相关性就是三个词的相关性之和。
TF(Lucence的原理|D) = 0.01 + 0.1 + 0.015 = 0.125我们发现一个问题,就是“的”这个词占了很大权重,而它对文档主题的几乎没什么贡献。这种词叫停用词,在度量相关性时不考虑它们的词频。去掉这个词后,上面的相关性变为0.025。其中“Lucence”贡献了0.01, “原理”贡献了0.015。
细心的人还会发现,“原理”是个很通用的词,而“Lucence”是个专业词。直觉告诉我们,“Lucence”这个词对我们的搜索比“原理”更重要。抽象一下,可以理解为 一个词预测主题的能力越强,就越重要,权重也应该越大。反之,权重越小。
假设我们把世界上所有的文档的总和看成一个文档库。如果一个词,很少在文档库里出现过,那通过它就容易找到目标,它的权重也应该大。反之,如果一个词在文档库中大量出现,看到它仍然不清楚在讲什么内容,它的权重就应该小。“的、地、得”这些虚词出现的频率太高,以至于权重设为零也不影响搜素,这也是它们成为停用词的原因之一。
IDF的定义
假设关键词w在n个文档中出现过,那么n越大,则w的权重越小。常用的方法叫“逆文本频率指数”(Inverse Dcument Frequency, 缩写为IDF)。一般的:
IDF = log(N/n)
注意: 这里的log是指以2为底的对数,不是以10为底的对数。
N表示全部文档数。假如世界上文档总数位100亿,"Lucence"在1万个文档中出现过,“原理”在2亿个文档中出现过,那么它们的IDF值分别为:
IDF(Lucence) = log(100亿/1万) = 19.93
IDF(原理) = log(100亿/2亿) = 5.64“Lucence”重要性相当于“原理”的3.5倍。停用词“的”在所有的文档里出现过,它的IDF=log(1)=0。短语与文档的最终相关性就是TF和IDF的加权求和:
simlarity = TF1*IDF1 + TF2*IDF2 + ... + TFn*IDFn现在可以计算出上文中提到的“Lucence的原理”与文档D的相关性:
simlarity(Lucence的原理|D) = 0.01*19.93 + 0 + 5.64*0.015 = 0.2839
其中,“Lucence”占了70%的权重,“原理”仅占30%的权重。
Lucence中的TF-IDF
早期的Lucence是直接把TF-IDF作为默认相似度来用的,只不过做了适当调整,它的相似度公式为:
simlarity = log(numDocs / (docFreq + 1)) * sqrt(tf) * (1/sqrt(length))numDocs:索引中文档数量,对应前文中的N。lucence不是(也不可能)把整个互联网的文档作为基数,而是把索引中的文档总数作为基数。
-
docFreq: 包含关键字的文档数量,对应前文中的n。
-
tf: 关键字在文档中出现的次数。
-
length: 文档的长度。
上面的公式在Lucence系统里做计算时会被拆分成三个部分:
IDF Score = log(numDocs / (docFreq + 1))
TF Score = sqrt(tf)
fieldNorms = 1/sqrt(length)fieldNorms 是对文本长度的归一化(Normalization)。所以,上面公式也可以表示成:
simlarity = IDF score * TF score * fieldNorms
BM25, 下一代的TF-IDF
新版的lucence不再把TF-IDF作为默认的相关性算法,而是采用了BM25(BM是Best Matching的意思)。BM25是基于TF-IDF并做了改进的算法。
BM25中的TF
传统的TF值理论上是可以无限大的。而BM25与之不同,它在TF计算方法中增加了一个常量k,用来限制TF值的增长极限。下面是两者的公式:
传统 TF Score = sqrt(tf)
BM25的 TF Score = ((k + 1) * tf) / (k + tf) 下面是两种计算方法中,词频对TF Score影响的走势图。从图中可以看到,当tf增加时,TF Score跟着增加,但是BM25的TF Score会被限制在0~k+1之间。它可以无限逼近k+1,但永远无法触达它。这在业务上可以理解为某一个因素的影响强度不能是无限的,而是有个最大值,这也符合我们对文本相关性逻辑的理解。 在Lucence的默认设置里,k=1.2,使用者可以修改它。![]()

BM25如何对待文档长度
BM25还引入了平均文档长度的概念,单个文档长度对相关性的影响力与它和平均长度的比值有关系。BM25的TF公式里,除了k外,引入另外两个参数:L和b。L是文档长度与平均长度的比值。如果文档长度是平均长度的2倍,则L=2。b是一个常数,它的作用是规定L对评分的影响有多大。加了L和b的公式变为:
TF Score = ((k + 1) * tf) / (k * (1.0 - b + b * L) + tf)下面是不同L的条件下,词频对TFScore影响的走势图:

从图上可以看到,文档越短,它逼近上限的速度越快,反之则越慢。这是可以理解的,对于只有几个词的内容,比如文章“标题”,只需要匹配很少的几个词,就可以确定相关性。而对于大篇幅的内容,比如一本书的内容,需要匹配很多词才能知道它的重点是讲什么。
上文说到,参数b的作用是设定L对评分的影响有多大。如果把b设置为0,则L完全失去对评分的影响力。b的值越大,L对总评分的影响力越大。此时,相似度最终的完整公式为:
simlarity = IDF * ((k + 1) * tf) / (k * (1.0 - b + b * (|d|/avgDl)) + tf)
传统TF-IDF vs. BM25
传统的TF-IDF是自然语言搜索的一个基础理论,它符合信息论中的熵的计算原理,虽然作者在刚提出它时并不知道与信息熵有什么关系,但你观察IDF公式会发现,它与熵的公式是类似的。实际上IDF就是一个特定条件下关键词概率分布的交叉熵。
BM25在传统TF-IDF的基础上增加了几个可调节的参数,使得它在应用上更佳灵活和强大,具有较高的实用性。
读者思考
为什么BM25的TF Score计算要用 d/avgDl, 而不是用平方根、log或者其它计算方法?它背后是否有理论支持?
本文聚焦于bm25算法,重点讲解:
①bm25算法的推导过程
②bm25和tfidf的区别
③lucene中的bm25
④如何在solr中使用bm25算法
BM25简介
solr BM25(best match)是一种信息检索模型,属于二值独立概率模型。
IR模型分类
基于集合论的IR模型:布尔模型
基于代数论的IR模型:向量空间模型/潜性语义索引模型
基于概率统计的IR模型:回归模型/二值独立概率模型/基于统计语言建模的IR模型
公式推导
BM25分值与term的两个特征有关:一是term的权重,二是term与文档(查询文档、搜索结果文档)的相关性。




![]()
这里的IDF来源于二值独立模型
二值独立模型假设
如果一:一篇文章在由特征(term)表示的时候。以特征“出现”和“不出现”两种情况来表示,也能够理解为相关不相关。
如果二:词汇独立性
所谓独立性,是指文档里出现的单词之间没有不论什么关联。任一个单词在文章中的分布率不依赖于还有一个单词是否出现,这个如果明显与事实不符,可是为了简化计算。非常多地方须要做出独立性如果。这样的如果是普遍的。
W=文档在相关文档中出现的概率/文档在非相关文档中出现的概率
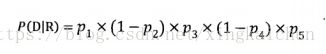
![]()




为了方便计算,对上述公式两边取log,得到:

那么怎样估算概率Si和Pi呢,假设给定用户查询。我们能确定哪些文档集合构成了相关文档集合,哪些文档构成了不相关文档集合,那么就能够用例如以下的数据对概率进行估算:

依据上表能够计算出Pi和Si的概率估值。为了避免log(0),对估值公式进行平滑操作,分子+0.5。分母+1.0
![]()
代入估值公式得到:
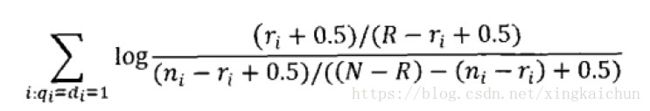
在我们不知道哪些文档相关。哪些文档不相关的情况下。将相关文档数R及包括查询词相关文档数r设为0。那么BIM公式退化成:
这个公式代表的含义就是。对于同一时候出如今查询Q和文档D中的单词,累加每一个单词的估值结果就是文档D和查询Q的相关性度量,在预先不知道哪些文档相关哪些文档不相关的情况下。能够使用固定值取代,这样的情况下该公式等价于向量空间模型(VSM)中的IDF因子。

solr验证
7.7496266 = sum of:
7.7496266 = weight(default_search:apple in 58214) [BM25Similarity], result of:
7.7496266 = score(doc=58214,freq=4.0 = termFreq=4.0
), product of:
4.3986993 = idf(docFreq=63357, maxDocs=5153814)
1.7617996 = tfNorm, computed from:
4.0 = termFreq=4.0
2.0 = parameter k1
0.5 = parameter b
90.458496 = avgFieldLength
163.84 = fieldLength
BM25 k b 参数调优
k取值越大,tf影响越大,分值越大;
b取值于0,1之间,b越大,对文档长度惩罚越大;
经验k=1.2,b=0.75效果最好。
---------------------
作者:邢星星
来源:CSDN
原文:https://blog.csdn.net/xingkaichun/article/details/82660614
版权声明:本文为博主原创文章,转载请附上博文链接!
BM25算法在Lucene中的应用
jiezheng
2018.03.18 22:59* 字数 645 阅读 410评论 0喜欢 0
Lucene是apache软件基金会jakarta项目组的一个子项目,是一个用Java写的全文检索引擎工具包,可以方便的集成到系统中提以提供高效的检索能力,Lucene核心功能分为建索和检索两部分。而对于检索部分来说,检索词和结果的相关度则为整个系统的核心部分,Lucene在相关度得分上提供了多种算法,现在大多数文章都会提到其中的TF/IDF算法,本文主要说一下其中的BM25算法在Lucene中的应用
BM25是二元独立模型(BIM)的扩展,是一种用来评价搜索词和文档之间相关性的算法,在Lucene中被应用在对查询结果的评分计算中。也就是对于一个Query查询到的文档与Query的相关度的评分计算。
BM25模型:
BM25算法模型
其中Q为Query,d标识搜索结果的文档,qi表示Query中的一个语素(分词),Wi表示qi的权重,R(qi,d)表示语素qi与文档d的相关性得分。
这里的Wi的处理方式在Lucene中使用的是IDF算法,计算如下
IDF
N为文档的总数,n(qi)为包含qi的文档数,显而易见,当n(qi)越高时得分越低,语素的常见度越大则权重越低,因此在建索和查询时去除停止词也很有必要。
R(qi,d):
R
K
这里fi为qi在d中的出现频率,K表示对文档长度的考虑,dl表示文档d的长度,avdl表示所有文档长度的平均值,k1和b则为调节因子,qfi表示qi在Query出现的频率,实际使用中通常为1,公式进一步简化:
完整公式
公式中的k1和b为经验参数Lucene中默认设置为k1=1.2;b=0.75
k1和b
综上公式可以看出,BM25对于相关性的计算中主要包含以下方面IDF 因子、文档长度因子、文档词频和查询词频
BM25
并且能够通过调节因子k1,k2,b对以上因子权重进行调整,b能够对文档长度因子进行调整,k2对查询词频因子进行调整,k1对文档词频因子进行调整。
综上我们对BM25的算法有了大致的了解,那么我们深入到Lucene中去,看一看具体的应用中是如何实现的:
在Lucene的package org.apache.lucene.search.similarities;包下面包含了评分有关的算法实现,其中BM25Similarity即是我们所使用的BM25算法的实现:
此处涉及到一个用户自定义的语素的权限
以上便是在Lucene中BM25具体的实现,我们在根据业务需要进行评分规则自定义时,也需从此处入手。
了解了规则和实现后,最后再通过一个实际使用的Query进行深入分析:
案例如下
e.g:
查询语句由 A - B - C基础条件组成,根据业务逻辑对A B C组合成与关系查询语句:
( A B C ) + ( * B * ) + C
通过explain()方法可以看到每一项的得分:
18.029978 = sum of:
13.986211 = sum of:
3.4537745 = weight(Field:A in 57939) [BM25Similarity], result of:
3.4537745 = score(doc=57939,freq=2.0 = termFreq=2.0
), product of:
2.916005 = idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:
38503.0 = docFreq
711057.0 = docCount
1.18442 = tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:
2.0 = termFreq=2.0
1.2 = parameter k1
0.75 = parameter b
40.709637 = avgFieldLength
64.0 = fieldLength
3.281716 = weight(Field:B in 57939) [BM25Similarity], result of:
3.281716 = score(doc=57939,freq=2.0 = termFreq=2.0
), product of:
2.770737 = idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:
44523.0 = docFreq
711057.0 = docCount
1.18442 = tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:
2.0 = termFreq=2.0
1.2 = parameter k1
0.75 = parameter b
40.709637 = avgFieldLength
64.0 = fieldLength
7.25072 = weight(Field:B in 57939) [BM25Similarity], result of:
7.25072 = score(doc=57939,freq=2.0 = termFreq=2.0
), product of:
6.1217475 = idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:
1560.0 = docFreq
711057.0 = docCount
1.18442 = tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:
2.0 = termFreq=2.0
1.2 = parameter k1
0.75 = parameter b
40.709637 = avgFieldLength
64.0 = fieldLength
1.0 = MedicineName_filter:*B*, product of:
1.0 = boost
1.0 = queryNorm
3.0437667 = weight(ContentLabel_filter:C in 57939) [BM25Similarity], result of:
3.0437667 = score(doc=57939,freq=1.0 = termFreq=1.0
), product of:
3.0437667 = idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:
33885.0 = docFreq
711057.0 = docCount
1.0 = tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:
1.0 = termFreq=1.0
1.2 = parameter k1
0.75 = parameter b
1.0 = avgFieldLength
1.0 = fieldLength
至此便是BM25在Lucene中的使用情况,相信看完对Lucene的打分有了一个基本的认识,作为检索引擎的核心,评分算法还有很多需要了解的,包括自定义,通过机器学习对业务更精准的排序等,后续有深入了解再做补充。
原理
BM25算法,通常用来作搜索相关性平分。一句话概况其主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法的一般性公式如下:
其中,Q表示Query,qi表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi。);d表示一个搜索结果文档;Wi表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。
下面我们来看如何定义Wi。判断一个词与一个文档的相关性的权重,方法有多种,较常用的是IDF。这里以IDF为例,公式如下:
其中,N为索引中的全部文档数,n(qi)为包含了qi的文档数。
根据IDF的定义可以看出,对于给定的文档集合,包含了qi的文档数越多,qi的权重则越低。也就是说,当很多文档都包含了qi时,qi的区分度就不高,因此使用qi来判断相关性时的重要度就较低。
我们再来看语素qi与文档d的相关性得分R(qi,d)。首先来看BM25中相关性得分的一般形式:
其中,k1,k2,b为调节因子,通常根据经验设置,一般k1=2,b=0.75;fi为qi在d中的出现频率,qfi为qi在Query中的出现频率。dl为文档d的长度,avgdl为所有文档的平均长度。由于绝大部分情况下,qi在Query中只会出现一次,即qfi=1,因此公式可以简化为:
从K的定义中可以看到,参数b的作用是调整文档长度对相关性影响的大小。b越大,文档长度的对相关性得分的影响越大,反之越小。而文档的相对长度越长,K值将越大,则相关性得分会越小。这可以理解为,当文档较长时,包含qi的机会越大,因此,同等fi的情况下,长文档与qi的相关性应该比短文档与qi的相关性弱。
综上,BM25算法的相关性得分公式可总结为:
从BM25的公式可以看到,通过使用不同的语素分析方法、语素权重判定方法,以及语素与文档的相关性判定方法,我们可以衍生出不同的搜索相关性得分计算方法,这就为我们设计算法提供了较大的灵活性。
代码实现
-
import math -
import jieba -
from utils import utils -
# 测试文本 -
text = ''' -
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。 -
它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。 -
自然语言处理是一门融语言学、计算机科学、数学于一体的科学。 -
因此,这一领域的研究将涉及自然语言,即人们日常使用的语言, -
所以它与语言学的研究有着密切的联系,但又有重要的区别。 -
自然语言处理并不是一般地研究自然语言, -
而在于研制能有效地实现自然语言通信的计算机系统, -
特别是其中的软件系统。因而它是计算机科学的一部分。 -
''' -
class BM25(object): -
def __init__(self, docs): -
self.D = len(docs) -
self.avgdl = sum([len(doc)+0.0 for doc in docs]) / self.D -
self.docs = docs -
self.f = [] # 列表的每一个元素是一个dict,dict存储着一个文档中每个词的出现次数 -
self.df = {} # 存储每个词及出现了该词的文档数量 -
self.idf = {} # 存储每个词的idf值 -
self.k1 = 1.5 -
self.b = 0.75 -
self.init() -
def init(self): -
for doc in self.docs: -
tmp = {} -
for word in doc: -
tmp[word] = tmp.get(word, 0) + 1 # 存储每个文档中每个词的出现次数 -
self.f.append(tmp) -
for k in tmp.keys(): -
self.df[k] = self.df.get(k, 0) + 1 -
for k, v in self.df.items(): -
self.idf[k] = math.log(self.D-v+0.5)-math.log(v+0.5) -
def sim(self, doc, index): -
score = 0 -
for word in doc: -
if word not in self.f[index]: -
continue -
d = len(self.docs[index]) -
score += (self.idf[word]*self.f[index][word]*(self.k1+1) -
/ (self.f[index][word]+self.k1*(1-self.b+self.b*d -
/ self.avgdl))) -
return score -
def simall(self, doc): -
scores = [] -
for index in range(self.D): -
score = self.sim(doc, index) -
scores.append(score) -
return scores -
if __name__ == '__main__': -
sents = utils.get_sentences(text) -
doc = [] -
for sent in sents: -
words = list(jieba.cut(sent)) -
words = utils.filter_stop(words) -
doc.append(words) -
print(doc) -
s = BM25(doc) -
print(s.f) -
print(s.idf) -
print(s.simall(['自然语言', '计算机科学', '领域', '人工智能', '领域']))
分段再分词结果
-
[['自然语言', '计算机科学', '领域', '人工智能', '领域', '中', '一个', '方向'], -
['研究', '人', '计算机', '之间', '自然语言', '通信', '理论', '方法'], -
['自然语言', '一门', '融', '语言学', '计算机科学', '数学', '一体', '科学'], -
[], -
['这一', '领域', '研究', '涉及', '自然语言'], -
['日常', '语言'], -
['语言学', '研究'], -
['区别'], -
['自然语言', '研究', '自然语言'], -
['在于', '研制', '自然语言', '通信', '计算机系统'], -
['特别', '软件系统'], -
['计算机科学', '一部分']]
s.f
列表的每一个元素是一个dict,dict存储着一个文档中每个词的出现次数
-
[{'中': 1, '计算机科学': 1, '领域': 2, '一个': 1, '人工智能': 1, '方向': 1, '自然语言': 1}, -
{'之间': 1, '方法': 1, '理论': 1, '通信': 1, '计算机': 1, '人': 1, '研究': 1, '自然语言': 1}, -
{'融': 1, '一门': 1, '一体': 1, '数学': 1, '科学': 1, '计算机科学': 1, '语言学': 1, '自然语言': 1}, -
{}, -
{'领域': 1, '这一': 1, '涉及': 1, '研究': 1, '自然语言': 1}, -
{'日常': 1, '语言': 1}, -
{'语言学': 1, '研究': 1}, -
{'区别': 1}, -
{'研究': 1, '自然语言': 2}, -
{'通信': 1, '计算机系统': 1, '研制': 1, '在于': 1, '自然语言': 1}, -
{'软件系统': 1, '特别': 1}, -
{'一部分': 1, '计算机科学': 1}]
s.df
存储每个词及出现了该词的文档数量
{'在于': 1, '人工智能': 1, '语言': 1, '领域': 2, '融': 1, '日常': 1, '人': 1, '这一': 1, '软件系统': 1, '特别': 1, '数学': 1, '通信': 2, '区别': 1, '之间': 1, '计算机科学': 3, '科学': 1, '一体': 1, '方向': 1, '中': 1, '理论': 1, '计算机': 1, '涉及': 1, '研制': 1, '一门': 1, '研究': 4, '语言学': 2, '计算机系统': 1, '自然语言': 6, '一部分': 1, '一个': 1, '方法': 1}
s.idf
存储每个词的idf值
{'在于': 2.0368819272610397, '一部分': 2.0368819272610397, '一个': 2.0368819272610397, '语言': 2.0368819272610397, '领域': 1.4350845252893225, '融': 2.0368819272610397, '日常': 2.0368819272610397, '人': 2.0368819272610397, '这一': 2.0368819272610397, '软件系统': 2.0368819272610397, '特别': 2.0368819272610397, '数学': 2.0368819272610397, '通信': 1.4350845252893225, '区别': 2.0368819272610397, '之间': 2.0368819272610397, '一门': 2.0368819272610397, '科学': 2.0368819272610397, '一体': 2.0368819272610397, '方向': 2.0368819272610397, '中': 2.0368819272610397, '理论': 2.0368819272610397, '计算机': 2.0368819272610397, '涉及': 2.0368819272610397, '研制': 2.0368819272610397, '计算机科学': 0.9985288301111273, '研究': 0.6359887667199966, '语言学': 1.4350845252893225, '计算机系统': 2.0368819272610397, '自然语言': 0.0, '人工智能': 2.0368819272610397, '方法': 2.0368819272610397}
s.simall(['自然语言', '计算机科学', '领域', '人工智能', '领域'])
['自然语言', '计算机科学', '领域', '人工智能', '领域']与每一句的相似度
[5.0769919814311475, 0.0, 0.6705449078118518, 0, 2.5244316697250033, 0, 0, 0, 0.0, 0.0, 0, 1.2723636062357853]
详细代码
https://github.com/jllan/jannlp/blob/master/similarity/bm25.py
参考
http://www.cnblogs.com/hdflzh/p/4034602.html
http://www.aiuxian.com/article/p-2690039.html