【论文精读CVPR_2023】Face Transformer: Towards High Fidelity and Accurate Face Swapping
【论文精读CVPR_2023】Face Transformer: Towards High Fidelity and Accurate Face Swapping
- 一、前言
- Abstract
- 1. Introduction
- 2. Related Works
-
- 2.1. Face Swapping
-
- 2.1.1 3D-Based methods
- 2.1.2 GAN-Based methods
- 2.2. Transformer
- 3. Methods
-
- 3.1. Face Feature Transformation Module
-
- 3.1.1 Feature extractor
- 3.1.2 Feature Transformation
- 3.1.3 Multi-scale feature transformation
- 3.2. Face Generation Module
- 3.3. Training Objectives
- 4. Experiments
-
- 4.1. Datasets and Settings
- 4.2. Implementation Details
- 4.3. Evaluation Metrics
-
- 4.3.1 ID verification
- 4.3.2 Poses
- 4.3.3 Expressions
- 4.3.4 Shape
- 4.3.5 Quality
- 4.4. Quantitative Experiments
- 4.5. Qualitative Experiments
- 4.6. Ablation Study
-
- 4.6.1 W/o transformer
- 4.6.2 W/o multi-scale
- 4.7. Discussion
-
- 4.7.1 Swapping with the same source faces
- 4.7.2 Swapping with the same target face
- 5. Conclusion
一、前言
Kaiwen Cui, Rongliang Wu, Fangneng Zhan, Shijian Lu
【Paper】 > 【Code暂无】
这项工作的贡献是三重的。
首先 \textit{首先} 首先,我们设计了 Face-Transformer,这是一个创新网络,通过将 Transformer 引入到换脸任务中来实现精确的换脸。转换器学习源面部和目标面部之间的语义感知对应关系,这有助于从源面部到目标面部的特征顺利转移。据我们所知,这是第一个为换脸任务引入 Transformer 架构的工作。
第二 \textit{第二} 第二,我们提出了一种新颖的多尺度特征转换策略,有助于学习更强大的特征表示并实现更准确的面部交换。
第三 \textit{第三} 第三,大量的实验表明,所提出的面部变换器在数量和质量上实现了卓越的面部交换。
可以借鉴的是将Transformer架构引入一个新的任务当中即可作为一个贡献和创新点。
Abstract
背景问题:人脸交换旨在生成融合源人脸身份和目标人脸属性的交换图像。大多数现有工作通过 3D 建模或使用生成对抗网络 (GAN) 进行生成来解决这一具有挑战性的任务,但 3D 建模的重建精度有限,而 GAN 常常难以保留源面部微妙但重要的身份细节(例如肤色、面部特征) )和目标面部的结构属性(例如面部形状、面部表情)。
工作介绍:本文提出了 Face Transformer,这是一种新颖的人脸交换网络,可以在交换的人脸图像中同时准确地保留源身份和目标属性。我们为面部交换任务引入了一个变压器网络,它学习源面部和目标面部之间的高质量语义感知对应关系,并将源面部的身份特征映射到目标面部的相应区域。高质量的语义感知对应可以在对目标形状和表情进行最小修改的情况下顺利、准确地传输源身份信息。此外,我们的面部变换器采用了多尺度变换机制,可以保留丰富的精细面部细节。
实验:大量的实验表明,我们的 Face Transformer 在定性和定量上都实现了卓越的面部交换性能。
1. Introduction
人脸交换旨在生成新的人脸图像,该图像结合了源人脸的身份(包括肤色、面部特征、化妆等)以及目标人脸的属性(包括头部姿势、头部形状、面部表情、背景等)近年来,由于其在不同领域的广泛应用,例如电影构图、电脑游戏和隐私保护等,自动真实的人脸交换引起了越来越多的兴趣。然而,准确、真实地提取和真实地交换人脸仍然是一项具有挑战性的任务。融合源人脸的身份信息和目标人脸的属性特征。
大多数现有的面部交换方法可以大致分为两类,分别利用 3D 面部模型和生成对抗网络 (GAN)\cite{goodfellow2014generative}。
早期的作品 \cite{lin2012face, nirkin2018face} 采用 3D 模型来处理源面部和目标面部之间的姿势和透视差异,估计源面部和目标面部的 3D 形状,并使用估计的 3D 形状作为面部交换的代理。然而,基于 3D 的方法在 3D 重建中的精度有限,这往往会在交换的面部图像中产生各种失真和伪影。受到 GAN \cite{goodfellow2014generative, dcgan, CGAN,cyclegan} 巨大成功的启发,一些作品 \cite{bao2017cvae, korshunova2017fast, natsume2018fsnet, natsume2018rsgan, nirkin2019fsgan, li2019faceshifter} 采用生成模型并取得了非常令人印象深刻的换脸性能。尽管基于 GAN 的网络可以生成高保真交换,但它们仍然难以保留源面部的微妙但重要的身份细节(肤色、面部特征、化妆等)和目标面部的结构属性特征(面部形状、面部表情等)。
本文提出了 Face-Transformer,这是一种创新的人脸交换网络,通过准确保留源人脸的身份细节和目标人脸的结构属性来实现卓越的人脸交换。卓越的交换性能很大程度上归功于我们在面部交换任务中引入的变压器架构。具体来说,我们使用转换器在源面部和目标面部之间建立语义感知的对应关系,从而可以将源面部的身份特征平滑且准确地映射到目标面部的相应区域。语义感知对应的构建不仅可以保留目标人脸的结构属性,而且可以实现源人脸的高保真身份,特别是对于微妙但重要的细节,如图1所示。所提出的人脸变换器由三个模块组成,包括人脸解析模块、人脸特征转换模块(FFTM)和人脸生成模块(FGM)。人脸解析模块是一个现成的模块\footnote{\url{https://github.com/zllrunning/face-parsing.PyTorch}},它预测面罩以将内部人脸与背景分开,并提取人脸语义指导 FFTM 中 Transformer 的训练。 FFTM以源人脸、目标人脸和目标人脸语义作为输入来学习两张人脸之间的语义感知对应关系,并将源人脸的身份特征映射到目标人脸的对应区域。 FGM最终基于FFTM对多尺度面部特征的变换生成高保真交换面部图像。
这项工作的贡献是三重的。
首先 \textit{首先} 首先,我们设计了 Face-Transformer,这是一个创新网络,通过将 Transformer 引入到换脸任务中来实现精确的换脸。转换器学习源面部和目标面部之间的语义感知对应关系,这有助于从源面部到目标面部的特征顺利转移。据我们所知,这是第一个为换脸任务引入 Transformer 架构的工作。
第二 \textit{第二} 第二,我们提出了一种新颖的多尺度特征转换策略,有助于学习更强大的特征表示并实现更准确的面部交换。
第三 \textit{第三} 第三,大量的实验表明,所提出的面部变换器在数量和质量上实现了卓越的面部交换。
2. Related Works
2.1. Face Swapping
近年来,换脸技术取得了显着的进步。现有的换脸方法大致可分为两类:基于 3D 的方法和基于 GAN 的方法。
2.1.1 3D-Based methods
早期的换脸任务涉及手动干预 \cite{blanz2004exchang} 直到引入自动化方法 \cite{bitouk2008face}。然而,自动化方法不能很好地保留面部表情,然后提出 Face2Face \cite{thies2016face2face} 将表情从目标面部转移到源面部。 Face2Face 的工作原理是将 3D 变形面部模型 (3DMM) 应用于源面部和目标面部,然后将表情组件从目标面部转移到源面部。为了进一步保留遮挡,Nirkin \etal \cite{nirkin2018face} 收集了数据,以监督方式训练遮挡感知的面部分割网络。然而,基于 3D 的模型在 3D 重建方面的精度有限,这往往会在交换的面部图像中产生各种失真和伪影。
2.1.2 GAN-Based methods
生成对抗网络 \cite{goodfellow2014generative}(GAN)在图像生成方面取得了巨大成功\cite{koksal2020rf,zhan2021unbalanced, cui2022genco,yu2022towards,huang2022masked,zhan2022bi,zhan2022marginal,zhan2019spatial}。
利用 GAN 的快速发展,有几种方法 \cite{bao2017cvae、korshunova2017fast、natsume2018fsnet、natsume2018rsgan、nirkin2019fsgan、li2019faceshifter} 将 GAN 引入换脸,并取得了相当可观的进展。
Deepfakes\footnote{\url{https://github.com/ondyari/FaceForensics/tree/master/dataset/DeepFakes}} 和 Faceswap \footnote{\url{https://github.com/ondyari/FaceForensics/tree/ master/dataset/FaceSwapKowalski}}最近在面部交换方面取得了巨大成功,但他们需要为每个新输入训练一个具有两个视频序列的新模型。为了缓解这一限制,与主体无关的面部交换引起了越来越多的兴趣。例如,Natsume \etal \cite{natsume2018rsgan} 解开了面部和头发的嵌入,并将它们重新组合以生成交换的面部。 Natsume \etal \cite{natsume2018fsnet} 利用潜在空间来保留源面部中的面部身份以及目标面部中的发型和背景区域的外观。 Nirkin \etal \cite{nirkin2019fsgan} 利用遮挡感知面部分割网络来保留面部遮挡,Li \etal \cite{li2019faceshifter} 提出了一种启发式错误确认细化网络。尽管基于 GAN 的方法可以实现高保真度的人脸交换,但大多数方法都难以保留源人脸的微妙但重要的身份细节(肤色、面部特征、化妆等)和目标人脸的结构属性(人脸形状、面部表情等)。所提出的面部变换器学习源面部和目标面部之间的语义感知对应关系,可以准确、平滑地传输源身份信息,同时对目标面部的形状和表情进行最小的修改。
2.2. Transformer
Transformer 最初是为自然语言处理任务而提出的,最近已成为广泛应用于各种视觉任务中的新兴组件。基于 Transformer 的视觉框架在捕获远距离关系方面优于卷积神经网络(CNN),已经证明了其在图像分类方面的有效性; \cite{dosovitskiy2020image,liu2021swin,deit},目标检测; \cite{DETR,DeformableDETR,MetaDETR}、图像合成\cite{esser2020taming,chen2020pre,zhan2022auto,yu2021diverse}、超分辨率\cite{yang2020learning}等。Transformer架构中的关键是注意力机制\cite{vaswani2017attention}它对输入之间的交互进行建模,而不管它们彼此之间的相对位置如何。
在这项工作中,我们利用 Transformer 架构的强大表达能力来完成具有挑战性的面部交换任务,其中主要挑战是在源面部和目标面部之间构建准确的语义感知对应关系。所提出的 Face Transformer 所实现的卓越性能表明该 Transformer 架构非常适合这项任务。
3. Methods

如图2所示,所提出的人脸变换器由三个模块组成,包括人脸解析模块、人脸特征转换模块(FFTM)和人脸生成模块(FGM)。人脸解析模块是一个现成的人脸解析模型,可生成人脸掩模和人脸语义,将内部人脸与图像背景分开,并指导学习在 FFTM 中使用的语义感知对应关系。一旦获得了内部面孔和面孔语义,
FFTM 学习源内脸和目标内脸之间的语义感知对应关系,并基于学习的语义感知对应关系将源内脸的多尺度特征转换为目标人脸的相应区域。然后,将多尺度变换后的特征逐步与目标语义特征和目标人脸背景的多尺度特征连接起来,以生成交换的人脸图像。 FFTM 和 FGM 以端到端的方式进行训练,将在接下来的小节中讨论。
3.1. Face Feature Transformation Module
利用提取的源内部人脸、目标内部人脸和目标语义,FFTM 学习根据源内部人脸特征和目标人脸特征之间的语义感知对应关系将源内部人脸的身份特征映射到目标内部人脸。
3.1.1 Feature extractor
FFTM 具有三个特征提取器。
第一个是 VGG 特征提取器,它采用预训练的 VGG-19 模型来提取多尺度特征 V 1 ∈ R H ∗ W ∗ C V_1\in\mathcal{R}^{H*W*C} V1∈RH∗W∗C、 V 2 ∈ R 2 H ∗ 2 W ∗ C 2 V_2\in\mathcal{R }^{2H*2W*\frac{C}{2}} V2∈R2H∗2W∗2C 和 V 3 ∈ R 4 H ∗ 4 W ∗ C 4 V_3\in\mathcal{R}^{4H*4W*\frac{C}{4}} V3∈R4H∗4W∗4C 来自源内面。然后,根据学习到的语义感知对应关系,将提取的特征映射到目标面部的相应区域。
第二个提取器是可学习的图像特征提取器,它提取源内面(K)和目标内面(Q)的特征。
第三个是可学习语义特征提取器,它从目标语义图( Q S Q_S QS)中提取特征,以指导生成语义感知的目标内脸特征 Q。可学习语义特征提取器的结合是基于对目标语义图的观察。语义捕获面部表情和形状信息,这在面部交换中至关重要。这两个可学习的特征提取器采用与 \cite{zhang2020cross} 类似的网络架构。
3.1.2 Feature Transformation
FFTM 的主要组成部分是一个转换器,它首先对源面部特征 K K K 和目标面部特征 Q Q Q 执行多头注意力。这会产生相应的特征表示 Q M Q_M QM 和 K M K_M KM。然后,变压器在 Q M Q_M QM 和 K M K_M KM 之间执行交叉注意,从而在输入 K K K 和输出 Q Q Q 之间建立连接。
与 \cite{vaswani2017attention} 类似, Q Q Q 和 K K K 上的多头注意力公式为 Q M = [ h e a d 1 , . . . , h e a d h ] W 0 Q_M = [head_1,...,head_h]W_0 QM=[head1,...,headh]W0
和
h e a d i = s o f t m a x ( ( Q W i Q ) ( K W i K ) T ∣ Q W i Q ∣ ∣ ( K W i K ) ∣ ) , \begin{align}\begin{aligned} head_i = softmax(\frac{(QW_i^Q)(KW_i^K)^T}{|QW_i^Q||(KW_i^K)|}), \end{aligned}\end{align} headi=softmax(∣QWiQ∣∣(KWiK)∣(QWiQ)(KWiK)T),其中 W W W表示可学习参数。 K M K_M KM 类似地获得。
与典型 Transformer 中的交叉注意力不同,我们首先使用 Q M Q_M QM 和 K M K_M KM 来学习对应矩阵 C C C,该矩阵表示源面部特征和目标面部特征之间的语义感知对应关系。然后将学习到的语义感知对应矩阵应用于从 VGG 特征提取器提取的面部特征。具体来说,语义感知对应矩阵 C \mathcal{C} C 可以通过将 Q M Q_M QM 中的每个通道特征与 K M K_M KM 中的所有通道特征进行点积并在点积上应用 softmax 来获得结果:
C = s o f t m a x ( Q M K M T ∣ Q M ∣ ∣ K M ∣ ) . \begin{align}\begin{aligned} \mathcal{C} = softmax{(\frac{Q_MK_M^T}{|Q_M||K_M|})}. \end{aligned}\end{align} C=softmax(∣QM∣∣KM∣QMKMT).
3.1.3 Multi-scale feature transformation
我们还通过变换 V 1 ∈ R H ∗ W ∗ C , V 2 ∈ R 2 H ∗ 2 W ∗ C 2 , V 3 ∈ R 4 H ∗ 4 W ∗ C 4 V_1\in\mathcal{R}^{H*W*C}, V_2\in\mathcal{R}^{2H*2W*\frac{C}{2 }}, V_3\in\mathcal{R}^{4H*4W*\frac{C}{4}} V1∈RH∗W∗C,V2∈R2H∗2W∗2C,V3∈R4H∗4W∗4C 同时使用学习到的对应矩阵。为了解决多尺度特征之间的空间差异,我们对每个特征应用展开过程 U U U,将所有特征的空间维度统一为H*W。然后将展开的特征与对应矩阵相乘以产生变换后的特征。最后,我们通过折叠过程 F F F恢复每个特征的空间维度。我们设计多尺度特征转换有两个主要目的。
首先,变换多尺度特征有助于在交换的面部图像中保留源面部的更精细的面部细节。
其次,学习多尺度特征变换可以反过来帮助提高语义感知对应矩阵的学习。
3.2. Face Generation Module
人脸生成模块用于融合人脸特征转换模块(FFTM)转换后的多尺度特征以及目标背景( B 1 、 B 2 B_1、B_2 B1、B2和 B 3 B_3 B3)的多尺度特征,并合成最终的高保真人脸图片。为了保留目标面部的表情和形状,我们使用另一个可学习的语义特征提取器来提取语义特征作为输入。
人脸生成模块的详细架构如图3所示。
受到 \cite{yang2020learning} 的启发,在生成过程中不同尺度的特征之间交换信息可以帮助生成器学习更强大的特征表示并保留更好的纹理细节,我们的面部生成模块逐步成对地在不同尺度的特征之间交换信息,如图3所示。
3.3. Training Objectives
正如 \ref{人脸特征转换模块} 节中提到的,我们在 Q 和 Q S Q_S QS 之间采用 L1 损失来保留 Q 中的语义信息。 Q 和 Q S Q_S QS 之间的特征损失 L f \mathcal{L}_{f} Lf公式为:
L f = ∣ ∣ Q − Q S ∣ ∣ 1 . \begin{align}\begin{aligned} \mathcal{L}_{f}= ||Q - Q_S||_1. \end{aligned}\end{align} Lf=∣∣Q−QS∣∣1.为了合成视觉上真实的图像,最终交换的面部图像( f s w a p f_{swap} fswap)是在对抗性损失 L a d v \mathcal{L}_{adv} Ladv下生成的:
L a d v = m i n G m a x D E [ l o g D ( f r e a l ) ] + E [ l o g ( 1 − D ( f s w a p ) ] , \begin{align}\left.\begin{aligned} \mathcal{L}_{adv}=\mathop{min}\limits_{G}\mathop{max}\limits_{D}\mathbb{E}[logD(f_{real})] + \mathbb{E}[log(1-D(f_{swap})], \end{aligned}\right.\end{align} Ladv=GminDmaxE[logD(freal)]+E[log(1−D(fswap)],其中 f r e a l f_{real} freal是真实的人脸图像。
脸部交换任务要求交换后的脸部( f s w a p f_{swap} fswap)与目标脸部 f t g t f_{tgt} ftgt具有相同的形状和表情。因此, f s w a p f_{swap} fswap 和 f t g t f_{tgt} ftgt 在语义上应该是相似的。受 \cite{johnson2016perceptual} 的启发,我们采用感知损失 L p e r c \mathcal{L}_{perc} Lperc 来最小化语义差异:
L p e r c = ∣ ∣ ϕ l ( f s w a p ) − ϕ l ( f t g t ) ∣ ∣ 1 . \begin{align}\left.\begin{aligned} \mathcal{L}_{perc} = ||\phi_{l}(f_{swap}) - \phi_{l}(f_{tgt})||_1. \end{aligned}\right.\end{align} Lperc=∣∣ϕl(fswap)−ϕl(ftgt)∣∣1.在 \cite{zhang2020cross} 之后,我们选择 ϕ l \phi_{l} ϕl 作为 VGG-19 网络中 relu4_2 层之后的激活,因为该层与语义高度相关。
此外,我们采用上下文损失 L c o n t e x t \mathcal{L}_{context} Lcontext \cite{mechrez2018contextual} 将交换后的脸部 f s w a p f_{swap} fswap 的脸部身份(脸部颜色、纹理等)与源面 f s r c f_{src} fsrc:
L c o n t e x t = ∑ l − l o g ( C X ( ϕ l ( f s w a p ∗ m t g t ) , ϕ l ( f s r c ∗ m s r c ) ) ) , \begin{align}\left.\begin{aligned} \mathcal{L}_{context} = \sum_{l}-log(CX(\phi_{l}(f_{swap}*m_{tgt}), \phi_{l}(f_{src}*m_{src}))), \end{aligned}\right.\end{align} Lcontext=l∑−log(CX(ϕl(fswap∗mtgt),ϕl(fsrc∗msrc))),其中 m t g t m_{tgt} mtgt和 m s r c m_{src} msrc是人脸解析网络生成的目标人脸和源人脸的掩码。由于交换的人脸的背景应与目标人脸的背景相同,因此我们对交换的人脸和源人脸使用各自的掩模来过滤背景信息,并将目标人脸的掩模应用于交换的人脸(如理想情况下它们是相同的)。上下文相似度 CX 的详细信息在 \cite{mechrez2018contextual} 中定义。我们选择 ϕ l \phi_{l} ϕl 作为 relu3_2、relu4_2 和 relu5_2 之后的激活,因为低级特征与风格更相关。
所提出的 Face Transformer 的整体损失函数是
L = λ 1 L f + λ 2 L a d v + λ 3 L p e r c + λ 4 L c o n t e x t . \begin{align}\begin{aligned} \mathcal{L} = \lambda_{1}\mathcal{L}_{f} + \lambda_{2}\mathcal{L}_{adv} + \lambda_{3}\mathcal{L}_{perc} + \lambda_{4}\mathcal{L}_{context}. \end{aligned}\end{align} L=λ1Lf+λ2Ladv+λ3Lperc+λ4Lcontext.
我们按照\cite{zhang2020cross}中的设置设置 λ 2 \lambda_{2} λ2 = 10, λ 3 \lambda_{3} λ3=0.001和 λ 4 \lambda_{4} λ4 = 1。然后我们根据经验调整 λ 1 \lambda_{1 } λ1 为 5。
4. Experiments
4.1. Datasets and Settings
与现有作品相似\cite{li2019faceshifter, nirkin2019fsgan},我们在公共数据集 Faceforensics++\cite{rossler2019faceforensics++ 上评估和比较所提出的 Face Transformer 与最先进的面部交换方法 DeepFakes、FaceSwap 和 FaceShifter\cite{li2019faceshifter} }。 DeepFakes 和 FaceSwap 直接使用 Faceforensics++ 进行训练,而 FaceShifter 和提出的 Face Transformer 与主题无关。具体来说,Faceshifter 使用三个数据集 CelebA-HQ~\cite{liu2018large}、FFHQ \cite{karras2019style} 和 VGGFace~\cite{parkhi2015deep} 进行训练
而所提出的 Face Transformer 仅在 CelebA-HQ \cite{liu2018large} 上进行训练。
CelebA-HQ是一个大规模人脸图像数据集,拥有3万张高分辨率人脸图像。 FFHQ 由 70K 张高质量图像组成,其中在年龄、种族和图像背景方面存在相当大的差异。 VGGFace 由 260 万张高分辨率图像组成,分布超过 2600 个身份。
注意 Faceforensics++ \cite{rossler2019faceforensics++} 是一个公共数据集,包含 1000 个不同身份的视频。在我们的实验中,我们按照\cite{li2019faceshifter}从每个视频中均匀采样10帧,形成一个测试集,该测试集由10K张人脸图像组成。
4.2. Implementation Details
继\cite{nirkin2019fsgan,li2019faceshifter}之后,我们使用五点地标\cite{chen2014joint}来裁剪和对齐面部图像。在模型训练中,裁剪后的图像大小调整为 256 × \times × 256。
我们使用 PyTorch \cite{paszke2017automatic} 来实现所提出的面部变换器。采用 Adam 优化器 \cite{kingma2014adam} 作为优化器, β 1 \beta_{1} β1=0.5, β 2 \beta_{2} β2= 0.999。
批量大小设置为 4。我们以 0.0002 的固定学习率训练模型 20 个时期。
4.3. Evaluation Metrics
我们对先前研究中使用的几个指标进行定量评估和比较。指标包括 ID verification 、 pose 、 express 、 shape 和 quality 。 \textit{ID verification}、\textit{pose}、\textit{express}、\textit{shape} 和 \textit{quality}。 ID verification、pose、express、shape和quality。
4.3.1 ID verification
ID验证指标检查交换的人脸图像是否保留了源人脸的身份信息。它是根据交换的人脸图像和源人脸图像的身份特征之间的欧几里德距离进行评估的,这些图像是通过预先训练的人脸识别模型\cite{wang2018cosface}提取的。
距离越小表明身份保存越好。我们没有遵循使用 dlib 提取身份特征的 \cite{nirkin2019fsgan},因为 \cite{wang2018cosface} 在人脸识别方面具有更好的性能。
4.3.2 Poses
姿势度量评估交换的脸部如何保留目标脸部的头部姿势。它是通过目标面部的头部姿势与交换的面部之间的欧几里得距离来计算的。在\cite{li2019faceshifter}之后,每个人脸图像的头部姿势由\cite{ruiz2018fine}估计。距离越小表明姿势保持得越好。
4.3.3 Expressions
表情指标检查交换的脸部如何保留目标脸部的表情。它是通过目标面部的 2D 地标与交换面部之间的欧几里得距离来评估的,如 \cite{nirkin2019fsgan} 中所示。在我们的实验中,我们使用开源软件 dlib \cite{king2009dlib} 来检测面部标志。距离越小表明表达保存越好。
4.3.4 Shape
形状度量检查交换的面部如何保留目标面部的面部形状。由于最先进的方法不会比较这些指标,因此我们通过计算目标面部掩模和交换面部掩模之间的欧几里得距离来自行设计。我们使用 \cite{nirkin2019fsgan} 中的分割网络来提取面罩。距离越小表明形状相似性越好。
4.3.5 Quality
质量指标评估交换的面部图像的感知质量。按照\cite{nirkin2019fsgan},我们使用结构相似性指数(SSIM)来衡量图像质量。 SSIM 越高表示图像质量越好。
4.4. Quantitative Experiments
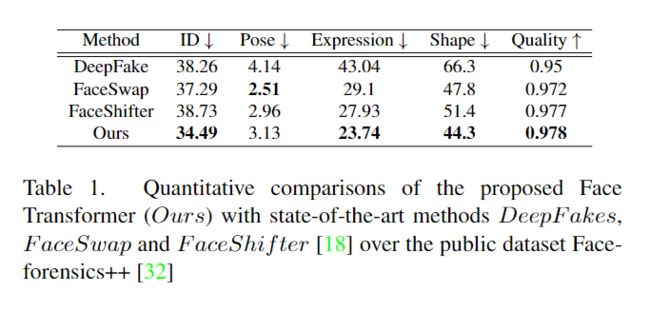
我们在数据集 Faceforensics++ \cite{rossler2019faceforensics++} 上对所提出的 Face Transformer 与最先进的方法 DeepFakes、FaceSwap 和 FaceShifter \cite{li2019faceshifter} 进行定量评估和比较。
表1显示定量实验结果。可以看出,所提出的Face Transformer在\textit{ID验证}、\textit{shape}、\textit{express}和\textit{quality}方面优于最先进的技术,展示了其明显的优越性实现高保真、准确的换脸。然而,所提出的 Face Transformer 在测量目标面部的预测 3D 姿势向量与交换面部的预测 3D 姿势向量之间的差异的姿势度量(3.13 vs 2.51)方面表现不佳。较低的姿势精度很大程度上是由于我们遵循\cite{li2019faceshifter}基于图像强度\cite{ruiz2018fine}估计3D姿势向量。然而,所提出的面部变换器在交换的面部中保留了更好的源面部肤色,这实际上扩大了目标面部和交换的面部之间的强度差异,并进一步降低了当前姿势度量下的性能。
4.5. Qualitative Experiments
图4显示定性实验结果。由于 DeepFakes 和 FaceSwap 首先合成内部面部区域并将其与交换面部的目标面部背景混合,因此它们往往会在合成面部中产生混合不一致,如第 1、2、3、6 和 7 列中的示例图像所示。 FaceShifter \cite{li2019faceshifter} 从源人脸中提取身份特征,从目标人脸中提取属性特征,并采用注意力机制自适应地整合它们以进行人脸交换。然而,对注意力机制的强烈依赖常常会误导交换生成,交换人脸的身份特征与源人脸的身份特征有所偏差,例如肤色(在所有样本图像中)和鼻子形状(在第 1、2 列的样本图像中) 、4、5)。与 FaceShifter \cite{li2019faceshifter} 不同,所提出的 Face Transformer 首先学习源面部特征和目标面部特征之间的语义感知对应关系,并将源面部的身份特征显式映射到目标面部的相应区域以获得变换后的特征。然后将变换后的特征和背景特征融合,直接生成最终交换的人脸。由于人脸特征已经映射到正确的区域,生成过程变得更加容易,并且可以实现更准确的人脸交换。它还消除了混合操作,从而有效地消除了混合不一致问题。
因此,所提出的人脸变换器更好地保留了源人脸的身份(例如,第 1-5 列样本图像中的肤色,第 1、2、5 列样本图像中的眼睛、鼻子和嘴巴形状等面部特征,以及第1、4、5列样本图像中的妆容)以及目标人脸的属性(例如第1、4列样本图像中的张嘴程度)。我们还在另外两个数据集 FFHQ \cite{karras2019style} 和 VGGFace \cite{parkhi2015deep} 上评估了所提出的 Face Transformer,直接将训练好的模型应用于两个数据集,无需进行微调。如图1所示,所提出的人脸变换器可以处理各种条件下的人脸图像,例如大头部姿势和不同的照明条件。这进一步证明了我们的 Face Transformer 的有效性。
4.6. Ablation Study
我们定量和定性地进行了两项消融研究,以证明我们设计的变压器和多尺度特征转换的有效性。

4.6.1 W/o transformer
我们首先将所提出的 Face Transformer 与不使用 Transformer 的基线模型进行比较。与我们的 Face Transformer 类似,它使用人脸解析模块来分离背景和内脸,从源内脸和目标背景中提取多尺度特征,并将提取的特征输入到我们的人脸生成模块。表2中的第一行显示定量结果。可以看出,所提出的 Face Transformer 在所有指标上都表现明显更好。更好的结果很大程度上是因为我们设计的转换器准确地将源面部特征映射到目标面部的相应区域,从而改善了交换面部的生成。
4.6.2 W/o multi-scale
我们还将提出的人脸变换器与不使用我们提出的多尺度变换的模型进行比较。该模型使用相同的转换器设计,但仅在面部生成中转换特征 V 1 V_1 V1。如表 2所示,所提出的 Face Transformer 始终表现得更好。如果没有所提出的多尺度变换,交换面部的保真度会明显降低。
我们从两个方面总结多尺度性能更好的原因。首先,多尺度可以保留更精细的面部细节。其次,学习多尺度特征变换可以反过来帮助提高语义感知对应矩阵的学习。
4.7. Discussion
4.7.1 Swapping with the same source faces
图5显示了所提出的 Face Transformer 的面部交换,其中相同的源面部被交换为多个目标面部。可以看出,Face Transformer 成功地将源人脸的身份特征转移到目标人脸的相应区域,同时保留了目标人脸的正确姿势和表情(而目标人脸的表情和姿势非常不同)。
4.7.2 Swapping with the same target face
图6显示所提出的面部变换器可以实际地将不同的源面部交换为相同的目标面部。虽然源面孔的肤色有很大不同,但我们交换的面孔可以通过调整背景(例如,在第一个样本中调整颈部的颜色)来保留肤色,同时保持其与背景的兼容性。这一独特的功能很大程度上归功于我们的面部转换器中的转换器设计,它在生成交换面部之前将源内面部的身份特征映射到目标面部的相应区域。特征变换有利于生成模型的学习,使其能够生成高保真、真实的人脸交换。
5. Conclusion
在本文中,我们提出了一种名为 Face Transformer 的新型人脸交换框架,用于在交换的人脸图像中同时准确地保留源身份和目标属性。
我们为面部交换任务引入了变压器网络,它可以学习源面部和目标面部之间的高质量语义感知对应关系,并准确地将源身份信息与目标属性相结合。
此外,我们的面部变换器利用多尺度变换机制来保留更精细的面部细节。
大量实验表明,所提出的面部变换器可以生成准确且真实的面部交换结果。