软件工程实践第二次作业——个人实战
文章目录
-
- Gitcode项目地址
- PSP表格
- 解题思路描述
-
-
- 如何解析json文件?
- 如何获取DTO(数据传输对象)?即数据源如何选择?
- 如何进行优化?
- 如何实现缓存机制?
- 如何解决缓存带来的GC性能问题?
-
- 接口设计和实现过程
-
-
- 接口和抽象类的设计
- 类图
-
- 关键代码展示
-
-
- 初始化启动参数
- 数据源抽象类解析命令逻辑
- Lib类的单例模式实现
- 线程类命令解析
-
- 性能改进
-
-
- 使用多线程提高性能
- 使用本地数据源提高性能
- 使用缓存提高性能
- 优化GC
- 性能分析
- 最终的性能分析
-
- 单元测试
- 异常处理
-
-
- 输入文件路径异常处理
- OOM异常
-
- 心得体会
| 这个作业属于哪个课程 | 2022年福大-软件工程 |
|---|---|
| 这个作业要求在哪里 | 软件工程实践第二次作业——个人实战 |
| 这个作业的目标 | 学习PSP相关知识,单元测试和性能调优 |
| 其他参考文献 | 无 |
该作业完成对冬奥会的赛事数据的收集,并实现一个能够对国家排名及奖牌个数统计的控制台程序。
Gitcode项目地址
gitcode项目地址
PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 120 |
| • Estimate | • 估计这个任务需要多少时间 | 2400 | 3600 |
| Development | • 开发 | 2100 | 3340 |
| • Analysis | • 需求分析 (包括学习新技术) | 120 | 160 |
| • Design Spec | • 生成设计文档 | 240 | 240 |
| • Design Review | • 设计复审 | 60 | 180 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 60 | 40 |
| • Design | • 具体设计 | 60 | 180 |
| • Coding | • 具体编码 | 1000 | 1840 |
| • Code Review | • 代码复审 | 60 | 100 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 560 | 600 |
| Reporting | 报告 | 180 | 540 |
| • Test Repor | • 测试报告 | 120 | 480 |
| • Size Measurement | • 计算工作量 | 30 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 2400 | 4000 |
解题思路描述
程序顺序图:
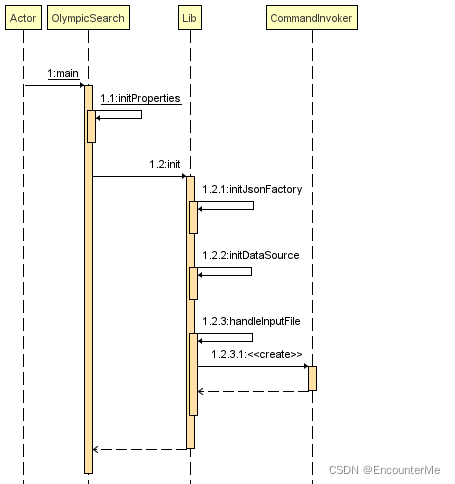
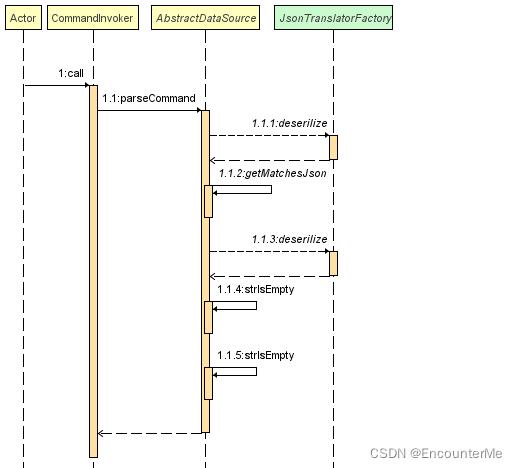
如何解析json文件?
- 调用第三方库,但需要选择最适合本项目的解析器,将对各种解析器分别进行单元测试,选择最适合的解析器作为项目默认json解析器,可选解析器有:Gson(最终选择)、FastDFS、Jackson。
- 因为有多种解析器可供选择,所以可以使用设计模型解耦合,减少代码量,也易于单元测试。
如何获取DTO(数据传输对象)?即数据源如何选择?
如果不考虑完全缓存的话,目前有两种解决方案:
- 调用冬奥API
分析:GET请求API,中间涉及到发起网络请求。网络IO可能会是程序的瓶颈段,可以通过多线程异步请求提高吞吐量。因为使用多线程,所以需要线程池管理线程。 - 读取本地数据
分析:根据需求可知,需要的数据已经不会再更新了,因此可以将静态数据文件存放在本地中,在需要时调用操作系统IO读取文件即可。文件IO可能会是程序的瓶颈段,仍然可以通过多线程异步请求IO提高吞吐量,仍然需要线程池。
如何进行优化?
- 根据数据源的两种选择策略可知,程序瓶颈段都会在IO处,所以可以考虑并发读取数据,设置线程池减少线程创建的性能消耗,因此优化时需要考虑核心线程数和选择最优的阻塞队列。
- 考虑到输入文件中可能会有重复的命令,因此可以使用缓存技术减少IO。但是还有一点很重要:如果input文件中重复的命令非常多,程序主要的瓶颈段会变成缓存查找,会转变为CPU密集型任务,核心线程数应该越少越好,减少线程切换次数。
如何实现缓存机制?
-
基于LinkedHashMap实现LRU算法的缓存,效率会稍低于HashMap,但不会发生内存泄漏。
-
使用HashMap,虽然使用HashMap会造成内存泄漏,但本程序非长期运行,只运行一次就结束,因此可以使用。但是会产生线程安全问题,所有需要使用ConcurrentHashMap。
如何解决缓存带来的GC性能问题?
- 可以借助性能分析工具调整堆的大小以及选择最优的垃圾回收算法等减少GC次数。
接口设计和实现过程
接口和抽象类的设计
Json解析器接口设计:
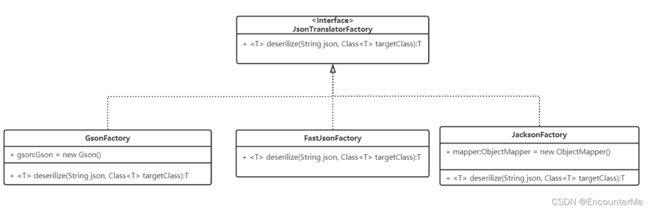
为了程序支持不同的Json解析器,使用适配器设计模式,将每个第三方库的反序列化方法统一成deserilize方法进行解耦合,不需要改动代码则可以切换解析器,也易于单元测试。
经过测试,GsonFactory是解析最快的解析工厂。点此查看测试结果
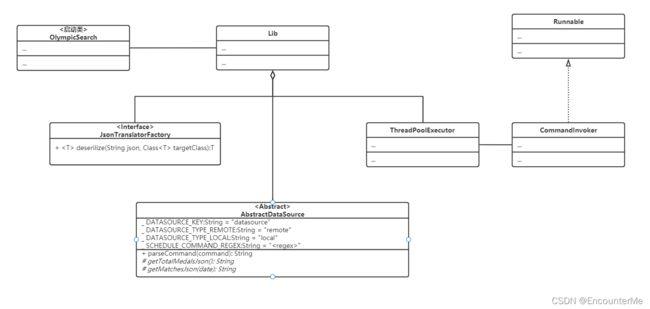
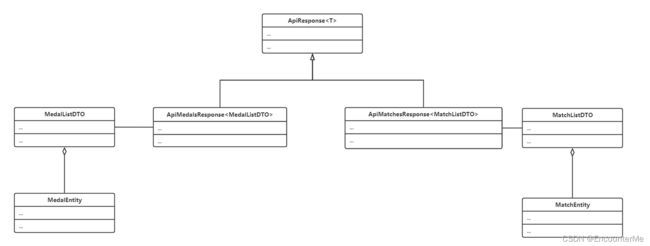
数据源接口设计:

为支持多种数据源,设计出AbstractDataSource抽象类,封装解析命令的方法,而由实例类实现获取奖牌榜json字符串和赛况json字符串的方法。
经过测试,LocalDataSource会比RemoteDataSource提高了1334.6%的运行速度。点此查看测试结果
类图
关键代码展示
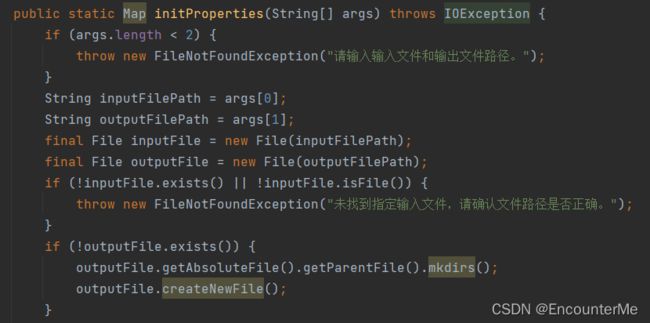
初始化启动参数
在main函数启动时,初始化启动参数。会把输入文件和输出文件地址放入应用程序环境中,也会读取启动时设置的json解析器和数据源。
public static void main(String[] args) {
try {
Map properties = initProperties(args);
Lib lib = Lib.getInstance();
lib.init(properties);
} catch (IOException e) {
/**
* 文件路径很重要,错了这个程序就没用了,一定要输入正确。
*/
System.err.println(e.getMessage());
}
}
/**
* 初始化启动参数
*
* @param args 程序启动传入的参数
*/
public static Map initProperties(String[] args) throws IOException {
if (args.length < 2) {
throw new FileNotFoundException("请输入输入文件和输出文件路径。");
}
String inputFilePath = args[0];
String outputFilePath = args[1];
final File inputFile = new File(inputFilePath);
final File outputFile = new File(outputFilePath);
if (!inputFile.exists() || !inputFile.isFile()) {
throw new FileNotFoundException("未找到指定输入文件,请确认文件路径是否正确。");
}
if (!outputFile.exists()) {
outputFile.getAbsoluteFile().getParentFile().mkdirs();
outputFile.createNewFile();
}
HashMap<String, String> appEnvironments = new HashMap<>();
appEnvironments.put(INPUT_FILE_PATH_KEY, inputFilePath);
appEnvironments.put(OUTPUT_FILE_PATH_KEY, outputFilePath);
for (int i = 2; i < args.length; i++) {
String arg = args[i];
if (arg.length() > 0) {
final String[] split = arg.split("=");
if (split.length == 2) {
appEnvironments.put(split[0], split[1]);
}
}
}
return appEnvironments;
}
数据源抽象类解析命令逻辑
command由外部传入,可保证前后不含空格。
解析流程如下:
- 判断是否为total命令,不是则判断是否符合schedule命令格式。
- 判断schedule命令格式分为两步:判断格式正确、判断日期正确,这两次判断均使用正则表达式判断。
- 如果schedule命令格式也错误,则返回Error。
- 如果是total命令,则向数据源获取奖牌榜数据,解析后返回。
- 如果schedule命令格式正确,而日期不符合正常日期格式,则直接返回N/A,如果符合正常日期格式,则向数据源获取对应日期数据。
- 如果数据源返回对应日期数据为空,则说明输入日期不在冬奥会期间,没有赛况信息,返回N/A,否则使用数据源的日期数据进行解析后返回。
public String parseCommand(String command) {
if ("total".equals(command)) {
String responseJson = getTotalMedalsJson();
if (responseJson == null) {
return "N/A\n" + "-----\n";
}
ApiMedalsResponse medalsResponse = Lib.getInstance()
.getJsonTranslatorFactory()
.deserilize(responseJson, ApiMedalsResponse.class);
MedalListDTO medalListDTO;
if (medalsResponse == null ||
(medalListDTO = medalsResponse.getData()) == null ||
medalListDTO.getMedalsList().isEmpty()) {
return "N/A\n" + "-----\n";
}
StringBuilder sb = new StringBuilder();
int i = 1;
for (MedalEntity medalEntity : medalListDTO.getMedalsList()) {
if (medalEntity != null) {
sb.append("rank").append(i++).append(":").append(medalEntity.getCountryid()).append("\n");
sb.append("gold:").append(medalEntity.getGold()).append("\n");
sb.append("silver:").append(medalEntity.getSilver()).append("\n");
sb.append("bronze:").append(medalEntity.getBronze()).append("\n");
sb.append("total:").append(medalEntity.getCount()).append("\n");
sb.append("-----").append("\n");
}
}
return sb.toString();
} else {
Matcher errMatcher = SCHEDULE_ERR_PATTERN.matcher(command);
if (errMatcher.find()) {
Matcher naMatcher = SCHEDULE_NA_PATTERN.matcher(command);
if (naMatcher.find()) {
String month;
String day;
String date;
if ((month = naMatcher.group(1)) != null && (day = naMatcher.group(2)) != null) {
date = "2022" + month + day;
String responseJson = getMatchesJson(date);
if (responseJson == null || responseJson.length() == 0) {
return "N/A\n" + "-----\n";
}
ApiMatchesResponse matchesResponse = Lib.getInstance()
.getJsonTranslatorFactory()
.deserilize(responseJson, ApiMatchesResponse.class);
MatchListDTO matchListDTO;
if (matchesResponse == null ||
(matchListDTO = matchesResponse.getData()) == null ||
matchListDTO.getMatchList().isEmpty()) {
return "N/A\n" + "-----\n";
}
StringBuilder sb = new StringBuilder();
for (MatchEntity matchEntity : matchListDTO.getMatchList()) {
sb.append("time:").append(DATE_FORMAT.format(matchEntity.getStartdatecn())).append("\n");
sb.append("sport:").append(matchEntity.getItemcodename()).append("\n");
sb.append("name:").append(matchEntity.getTitle());
if (strIsEmpty(matchEntity.getHomename()) && strIsEmpty(matchEntity.getAwayname())) {
sb.append(" ").append(matchEntity.getHomename()).append("VS").append(matchEntity.getAwayname()).append("\n");
} else {
sb.append("\n");
}
sb.append("venue:").append(matchEntity.getVenuename()).append("\n");
sb.append("-----").append("\n");
}
return sb.toString();
} else {
return "N/A\n" + "-----\n";
}
} else {
return "N/A\n" + "-----\n";
}
} else {
return "Error\n" + "-----\n";
}
}
}
Lib类的单例模式实现
用于在多线程下获取单例实例
public class Lib {
private static volatile Lib instance;
public static Lib getInstance() {
if (instance == null) {
synchronized (Lib.class) {
//防止并发访问时CAS获取锁失败,所以需要二次验null
if (instance == null) {
instance = new Lib();
return instance;
}
}
}
return instance;
}
}
线程类命令解析
在线程类中处理缓存,如果命令结果已缓存则直接返回缓存,没有则使用数据源解析命令并缓存。
缓存实现中存在线程安全问题,所以使用ConcurrentHashMap。
对key的处理这里去掉了所有的空格,可以减少重复意义的键值对:
比如 schedule 0215和schedule 0215两种命令就可以用一个key:schedule0215所表示出来。
public String call() {
String cacheKey = command.replaceAll(" ", "");
if (commandCache.containsKey(cacheKey)) {
return commandCache.get(cacheKey);
}
String rst;
String commandRst = Lib.getInstance().getDataSource().parseCommand(this.command);
if (commandRst == null || commandRst.length() == 0) {
rst = "\n";
commandCache.put(cacheKey, rst);
return rst;
}
//解析命令的过程中可能其他线程已经放入结果了,所以需要二次check,
if (!commandCache.containsKey(cacheKey)) {
commandCache.put(cacheKey, commandRst);
}
return commandRst;
}
性能改进
使用多线程提高性能
测试环境:CPU 12核 、JVM采用默认参数、Gson解析器、本地数据源、线程池阻塞队列为100容量的ArrayBlockingQueue
测试数据:
所有命令值各不相同,不会使用到缓存。
单线程执行:



线程池核心线程数为CPU核数两倍:



单线程平均运行时间:210.67ms
多线程平均运行时间:131.00ms
提高了60.1%的运行速度。
选择最优阻塞队列:
ArrayBlockingQueue 队列大小为100
- ArrayBlockingQueue测试结果如下



- LinkedBlockingQueue测试结果如下



- SynchronousQueue测试结果如下



可以看出三者的运行花费速度相差不大,但是考虑到ArrayBlockingQueue和LinkedBlockingQueue会创建队列项,而SynchronousQueue是直接传递任务,在任务数较少的情况下,会稍快一点(已经测试过了),所以最终选择的是SynchronousQueue阻塞队列。
使用本地数据源提高性能
测试环境:CPU 12核 、JVM采用默认参数、Gson解析器、线程池阻塞队列为100容量的ArrayBlockingQueue、核心线程数为CPU核数两倍
远程数据源:



本地数据源:
采用上面的数据。
远程数据源平均运行时间:1879.33ms
本地数据源平均运行时间:131.00ms
提高了1334.6%的运行速度。
使用缓存提高性能
缓存可以减少IO的次数,因此可以提高运行速度。
优化GC
测试环境:jvm启动参数如下

设置堆的大小为20M,可知年轻代的大小为8M。打印GC日志如下:

一共发生3次young gc,没有发生full gc,gc总耗费时间13.3ms。
jvisualvm可视化堆内存如下
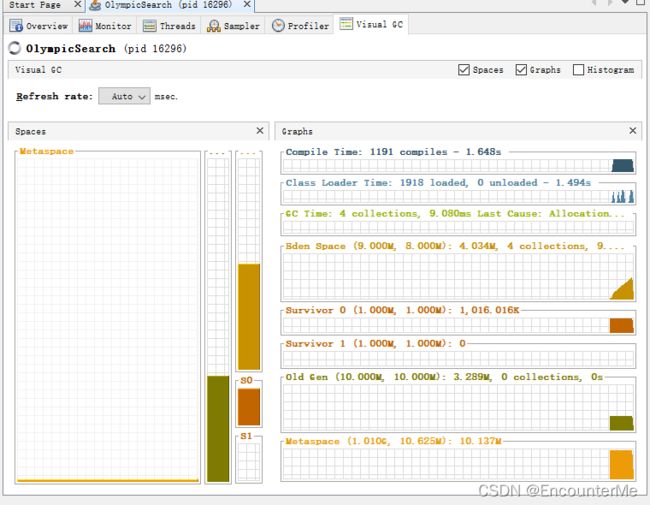
可知可以通过提高jvm堆内存大小减少gc次数。
将堆内存设为默认值:

使用jvm默认参数值不会发生GC:


因此针对GC的改进方案是:使用jvm默认堆内存和GC收集器即可。
性能分析
测试环境:input.txt文件110w行命令、线程池核心线程数为CPU核数+1、使用Gson解析器、本地数据源、机械硬盘(硬盘极限速度93MB/s)
运行花费44586ms
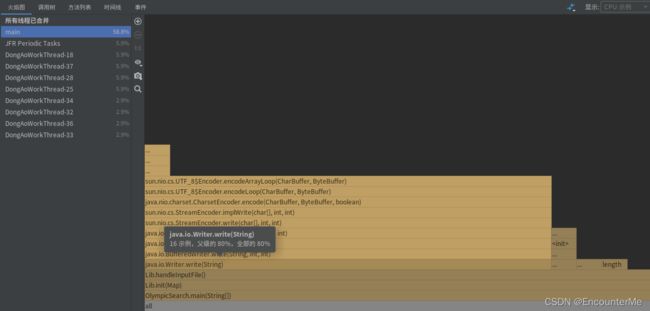
根据火焰图可知,是主线程中的handleInput方法中的write方法占用了主线程80%的运行时间,它就是本程序运行时间的瓶颈段。
找到该方法的所在位置:
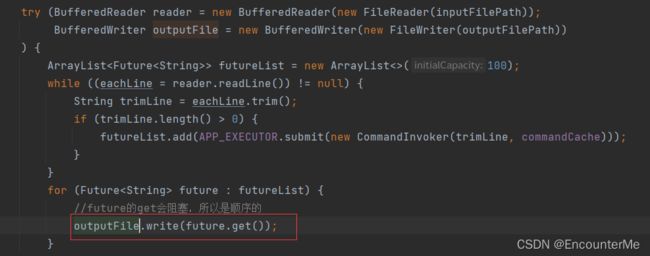
思考后有以下几种解决方案:
- 多线程使用支持随机读写的IO流写入output文件。
- 提高BufferedWriter的缓冲区大小。
- 解决方案一:分析可得,源程序运行速度慢是因为IO次数多,因为原逻辑是每一行命令就会进行一次IO写入文件,且为顺序执行。如果采用多线程,IO次数不会减少,可是可以并发执行,IO吞吐量增大,理论上可以减少运行时间,但是要维护每一行命令对应的返回字符串在输出文件中的顺序,还是需要顺序执行,达不到并发执行的效果,运行时间甚至会增加线程切换的时间,该解决方案不可取。
- 解决方案二:分析可得,每次write是当BufferedWriter的缓冲区满时就flush一次,进行一次IO,因此可以增大BufferdWriter的缓冲区,减少flush次数。
扩大BuffedWriter的缓冲区:
BufferedWriter outputFile = new BufferedWriter(new FileWriter(outputFilePath), 1024 * 8 * 8);
运行花费时间42386ms
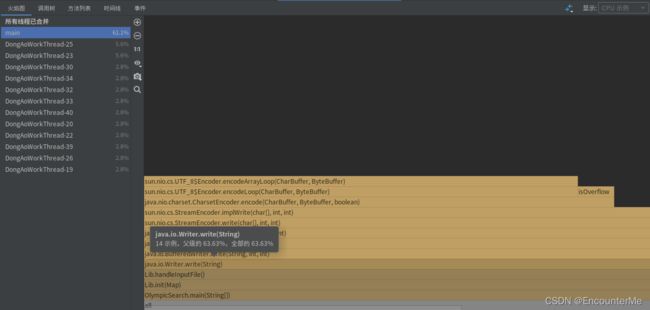
运行时间只占主线程的63%,运行速度确实得到了提升,但是考虑到测试的随机性,速度的提升可能并不大。
优化后的静态性能消耗图:

最终的性能分析
因为本项目未给出具体的数据量,而优化程序跟实际输入数据有很大的关系,给出如下结论:
- 当输入数据较少,处于50条以下,且命令结果基本不重复,未利用到缓存,程序主要为IO密集型任务,进行文件IO或网络IO,多线程环境下,核心线程数根据《java并发编程实践》中的核心线程数大小公式Nthreads=NcpuUcpu(1+w/c) (W/C=等待时间与计算时间的比率)得出,大概为3倍CPU核心数。
- 当输入数据较大,在数千、万、十万以上,程序充分利用缓存,转变为计算密集型任务,主要进行哈希运算,核心线程数为CPU核数+1。
- 因此为适应两种极端情况,线程池配置如下:
public static final int THREAD_POOL_CORE_THREAD_NUMS = Runtime.getRuntime().availableProcessors() + 1;
public static final int THREAD_POOL_MAXIMUM_THREAD_NUMS = Runtime.getRuntime().availableProcessors() * 3;
private Lib() {
APP_EXECUTOR = new ThreadPoolExecutor(
THREAD_POOL_CORE_THREAD_NUMS,
THREAD_POOL_MAXIMUM_THREAD_NUMS,
THREAD_POOL_KEEP_ALIVE_TIME,
TimeUnit.MILLISECONDS,
// new ArrayBlockingQueue<>(WORK_QUEUE_MAX_NUMS),
new LinkedBlockingQueue<>(),
// new SynchronousQueue<>(),
r -> {
Thread thread = new Thread(r);
thread.setName("DongAoWorkThread-" + thread.getId());
//设置为前台线程
thread.setDaemon(false);
return thread;
}
);
}
最终在110w条命令下执行结果如下:
生成3.2G的输出文件。
机械硬盘下:

固态硬盘下:

单元测试
覆盖率测试
Gson解析器、本地数据源的覆盖率:
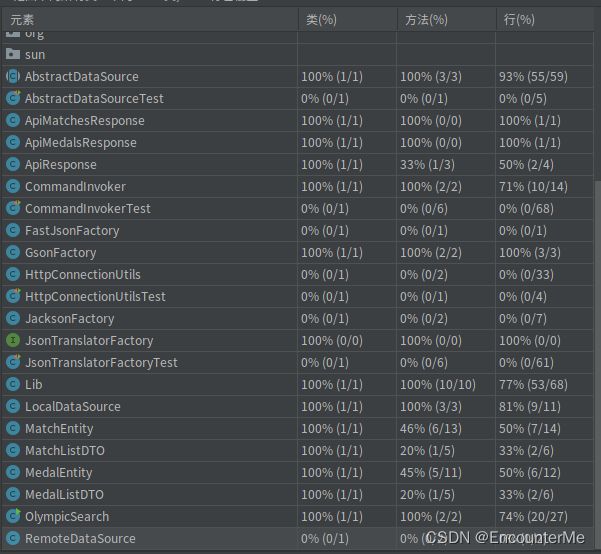
可以看出除了实体类和数据传输类以及非相关实现类的覆盖率都很低,比较正常。
测试各种json解析器解析json的速度:

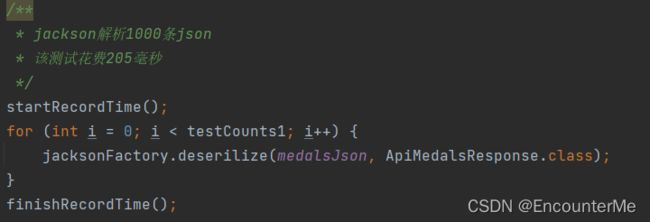
解析1000条json:
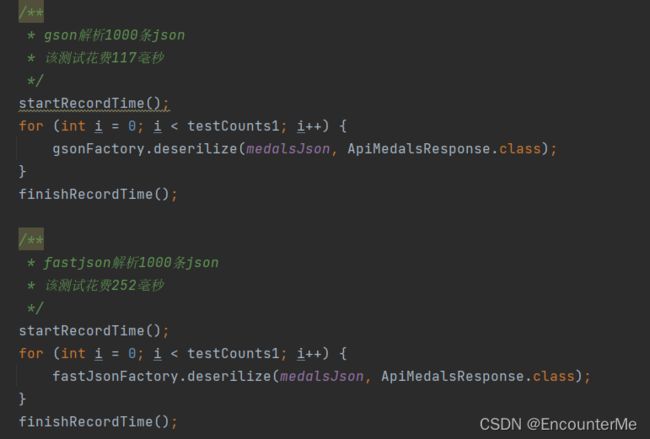
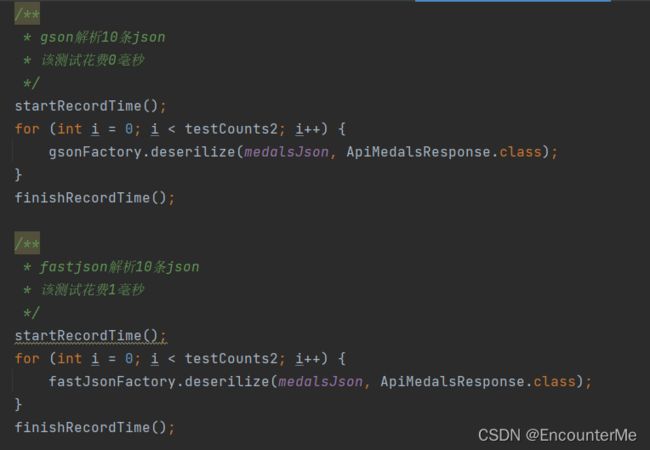
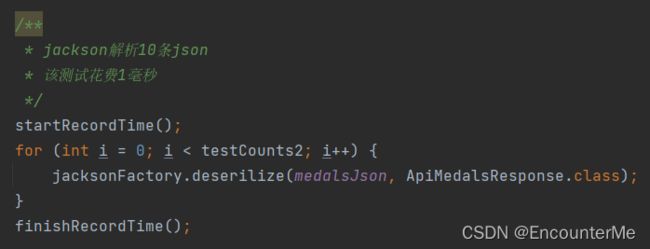
解析10条json:
解析1000000条json:
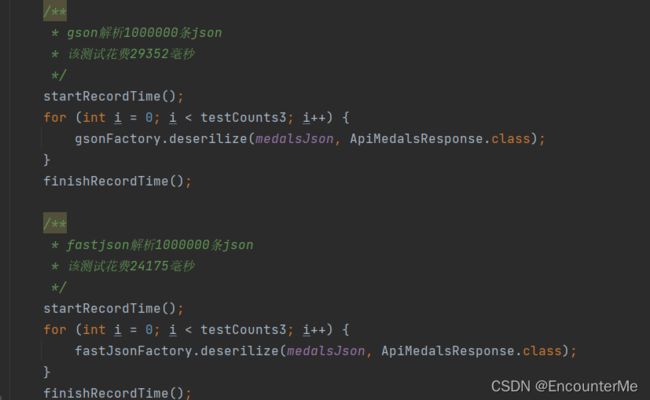
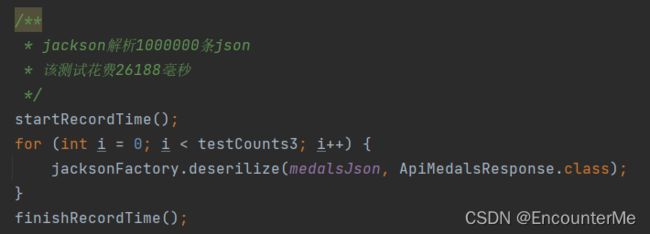
测试得出gson最适合本项目的json解析,因为本项目采用缓存,最高多解析次数即解析所有不同日期的赛况数据,数量比较小,所有采用gson作为默认json解析器。
异常处理
输入文件路径异常处理
该项目有一个可能会出现的比较严重的异常,即启动应用时输入文件路径异常,该异常不能由程序修复,应抛出异常并让用户知道。
初始化应用环境时会检测输入文件路径是否异常,如果输入文件不存在,则会抛出异常并提示用户输入正确的输入文件路径。如果输出文件路径对应的文件不存在,会自动创建中间目录和文件。启动时输入的路径参数支持相对jar包的路径和绝对路径。

OOM异常
在输入数据极大的极端情况下,程序使用缓存字符串的策略,不会造成字符串数据过大造成堆内存溢出的情况。
心得体会
通过本次作业:我学习到了
- 从设计角度上:我了解到了PSP表格如何填写,以及第一次实现项目和文档共同构建。
- 从工程角度上:
- 我更理解了各种设计模式对应用扩展性和健壮性起到的重要作用。
- 复习了许多Java基础的API。
- 这也是我第一次将学习到的jvm相关的知识用在了项目中,虽然jvm的默认参数已经是最优的了,但我还是清楚了jvm调优的工作流程,相信在以后的学习工作中会发挥更大的用处。
- 从现实角度上:我更理解了工作中会遇到的与甲方相处的过程:需求的变化和具体化让程序员不停地修改代码与文档。