阿里一面灵魂一问:RPC或者HTTP什么时候需要序列化和反序列化?
大家好,我是热心网友 —— 小林。
有位读者问了,我这么一个问题:
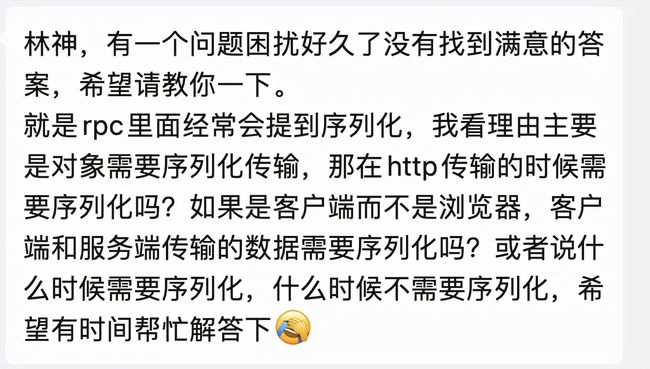
不管是 RPC 或者 HTTP,只要传输的内容是「对象」,要想在接收方还原出一摸一样的「对象」,那就需要序列化和反序列化。
那什么是序列化和反序列化呢?
RPC 能帮助我们的应用透明地完成远程调用,即调用其他服务器的函数就像调用本地方法一样。发起调用请求的那一方叫做调用方,被调用的一方叫做服务提供方。
调用方和服务提供方一般是不同的服务器,所以就需要通过网络来传输数据,并且 RPC 常用于业务系统之间的数据交互,需要保证其可靠性,所以 RPC 一般默认采用 TCP 协议来传输。同时, HTTP 协议也是建立在 TCP 之上的。
网络传输的数据必须是二进制数据,但调用方请求的出入参数都是对象,而对象是肯定没法直接在网络中传输的,需要提前把「对象转成二进制数据」进行网络传输,这个转换过程就做序列化。相反,服务提供方收到网络数据后,需要将「二进制数据转成对象」,这个转换过程就叫做反序列化。
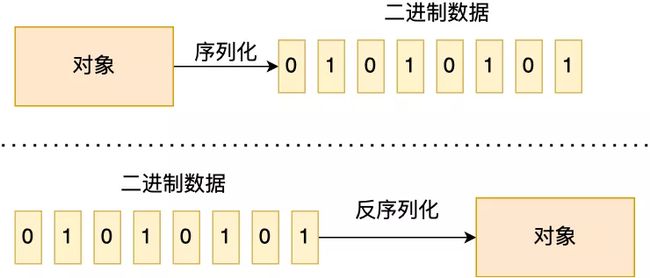
总结来说,序列化就是将对象转换成二进制数据的过程,以方便传输或存储。而反序列就是将二进制转换为对象的过程。
为什么 RPC 经常提到序列化呢?
因为网络传输的数据必须是二进制数据,所以在 RPC 调用中,对入参对象与返回值对象进行序列化与反序列化是一个必须的过程。
HTTP 什么时候需要序列化呢?
举个例子。
客户端和服务端交互的数据是什么 JSON,这时候发送方需要将 JSON 将对象转换成二进制数据发送到网络,接收方需要将接收到的二进制数据转换成 JSON 对象。
说了,这么多概念,接下来跟大家说说有哪些常用的序列化方式?
JDK 原生序列化
Java 语言中 JDK 就自带有序列化的方式,举个 JDK 序列化的例子。
注意,这个例子是将 Student 对象保存到文件,保存到文件的数据是二进制数据,所以并不是说序列化只用在网络传输场景里,只要是保存数据的场景只能是二进制数据时,就需要用序列化。
import java.io.*;
public class Student implements Serializable {
//学号
private int no;
//姓名
private String name;
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"no=" + no +
", name='" + name + '\'' +
'}';
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
String basePath = "/root";
FileOutputStream fos = new FileOutputStream(basePath + "student.dat");
//初始化一个学生对象
Student student = new Student();
student.setNo(1);
student.setName("xiaolin");
//将学生对象序列化到文件里
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(student);
oos.flush();
oos.close();
//读取文件中的二进制数据,并将数据反序列化为学生对象
FileInputStream fis = new FileInputStream(basePath + "student.dat");
ObjectInputStream ois = new ObjectInputStream(fis);
Student deStudent = (Student) ois.readObject();
ois.close();
System.out.println(deStudent);
}
}
从上面的代码,我们可以知道:
- JDK 自带的序列化具体的实现是由 ObjectOutputStream 完成的;
- 而反序列化的具体实现是由 ObjectInputStream 完成的。
既然序列化是将对象转换为二进制数据,那序列化的过程的二进制数据肯定是有某种固定的格式。
比如 JDK 自带的序列化的过程如下图:
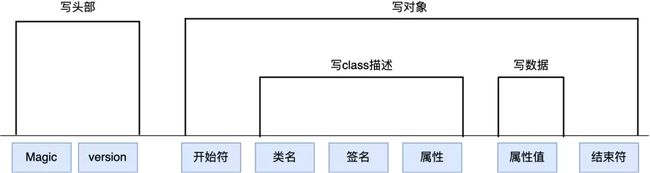
序列化过程就是在读取对象数据的时候,不断加入一些特殊分隔符,这些特殊分隔符用于在反序列化过程中截断信息。
- 头部数据用来声明序列化协议、序列化版本,用于高低版本向后兼容;
- 对象数据主要包括类名、签名、属性名、属性类型及属性值,当然还有开头结尾等数据,除了属性值属于真正的对象值,其他都是为了反序列化用的元数据
- 存在对象引用、继承的情况下,就是递归遍历“写对象”逻辑
所以,从这个例子我们可以知道,任何一种序列化的方式,其核心思想就要设计一套将对象转换成某种特定格式的二进制数据,接着反序列化的时候,就能根据规则从二进制数据解析出对象。
这么看,序列化其实就是一种协议,序列化方和反序列化方都要遵循相同的规则,否则就无法得到正常的数据。
不过,JDK 原生序列化缺陷就是不能跨语言,只能在 Java 生态里使用。
JSON
JSON 数据的格式相信大家都很熟悉了吧,在 Web 应用里特别常见,通常后端和前端的耦合就是 JSON 数据。
JSON 是典型的 Key-Value 方式,没有数据类型。很多语言都实现了 JSON 序列化的第三库,所以 JSON 序列化的方式可以跨语言。
比如,Java 语言中常用的 JSON 第三方类库有:
- Gson: 谷歌开发的 JSON 库克,功能十分全面。
- FastJson: 阿里巴巴开发的 JSON 库克,性能十分优秀。
- Jackson: 社区十分活跃且更新速度很快。
我这里说个 C++ 的 JSON 第三方库:JSON for Modern C++。

使用起来很方便,仅需要包含一个头文件“json.hpp”,没有外部依赖,也不需要额外的安装、编译、链接工作,适合快速上手开发。
因为 JSON 是 Key-Value 形式,所以 JSON for Modern C++ 的操作和标准容器 map 一样,用关联数组的“[]”来添加任意数据。
这里贴几个例子:
// 给 JSON for Modern C++ 的 json 类取个别名
using json_t = nlohmann::json;
// JSON对象
json_t j;
// "age":18
j["age"] = 18;
// "name":"xiaolin"
j["name"] = "xiaolin";
// "gear":{"suits":"2099"}
j["gear"]["suits"] = "2099";
// "jobs":["superhero"]
j["jobs"] = {"superhero"};
vector v = {1,2,3};
// "numbers":[1,2,3]
j["numbers"] = v;
map m =
{{"one", 1}, {"two", 2}};
// "kv":{"one":1,"two":2}
j["kv"] = m;
添加完 JSON 数据完成后,就可以调用成员函数 dump() 进行初始化,得到的 JSON 文本形式,也就是 JSON 字符串:
cout << j.dump() << endl;
反序列化也很简单,只要调用静态成员函数 parse() 就行,直接得到 JSON 对象:
// JSON文本,原始字符串
string jsonStr = R"({
"name": "xiaolin",
"age" : 18
})";
// 从字符串反序列化
json_t j = json_t::parse(jsonStr);
// 验证序列化是否正确
assert(j["age"] == 18);
assert(j["name"] == "xiaolin");
对于通常的应用来说,掌握了基本的序列化和反序列化就够用了,如果想要了解 JSON for Modern C++ 其他特性,可以去看它的 Github。
JSON 进行序列化存在的问题,因为 JSON 进行序列化的额外空间开销比较大,对于大数据量服务这意味着需要巨大的内存和磁盘开销,所以如果在传输数据量比较小的场景,就可以采用 JSON 序列化的方式。
ProtoBuffer
ProtoBuf 是由 Google 出品的,是一种轻便、高效的结构化数据存储格式,可以用于结构化数据序列化,支持 Java、Python、C++、Go 等语言。
Protobuf 使用的时候必须写一个 IDL(Interface description language)文件,在里面定义好数据结构,只有预先定义了的数据结构,才能被序列化和反序列化。
下面是一个简单的 IDl 文件格式:
syntax = "proto2"; // 使用第2版
package sample; // 定义名字空间
message Person { // 定义消息
required string name = 1; // required表示必须字段
required int32 id = 2;
optional string email = 3; // optional字段可以没有
}
写完 IDL 文件后,然后使用不同语言的 IDL 编译器,生成序列化工具类。
Protobuf 在 Github 有文档介绍了不同语言是怎么使用编译器生成序列化工具类了,我在这里就不介绍了。
这里贴 C++ 和 Java 语言使用 Protobuf 相关接口进行序列化和反序列化的例子。
C++ 进行序列化和反序列化的例子:
// 类型别名
using person_t = sample::Person;
// 声明一个Protobuf对象
person_t p;
// 设置每个字段的值
p.set_id(1);
p.set_name("xiaolin");
p.set_email("[email protected]");
// 序列化到字符串
string enc;
p.SerializeToString(&enc);
// 反序列化
person_t p2;
p2.ParseFromString(enc);
Java 进行序列化和反序列化的例子:
/**
*
* // IDl 文件格式
* synax = "proto3";
* option java_package = "com.test";
* option java_outer_classname = "StudentProtobuf";
*
* message StudentMsg {
* //序号
* int32 no = 1;
* //姓名
* string name = 2;
* }
*
*/
StudentProtobuf.StudentMsg.Builder builder = StudentProtobuf.StudentMsg.newBuilder();
builder.setNo(1);
builder.setName("xiaolin");
//把student对象转化为byte数组
StudentProtobuf.StudentMsg msg = builder.build();
byte[] data = msg.toByteArray();
//把刚才序列化出来的byte数组转化为student对象
StudentProtobuf.StudentMsg deStudent = StudentProtobuf.StudentMsg.parseFrom(data);
System.out.println(deStudent);
现在很多大厂都在使用 Protobuf,而且 gRPC 就是基于 Protobuf 来做的序列化。
总结
将对象保存到文件,或者通过网络传输给对方,都是需要将对象转换二进制数据才能完成,那么对象转二进制数据的过程就是序列化,相反的,二进制数据转对象的过程就是反序列化的过程。
我也给你介绍了几种常见的序列化方式:
- JDK 自带的序列化方式无法跨语言使用;
- JSON 序列化大多数语言都支持,JSON 优势是使用起来简单,容易阅读,应用广泛,缺点就是不适合大数据量的场景;
- ProtoBuf 使用需要定义 IDL 文件,序列化后体积相比 JSON 小很多,现在很多大公司都在用,gRPC 框架使用 protobuf 序列化。
原文链接:
https://mp.weixin.qq.com/s/12sjb3WTKdQaDc0bvEX_ow
作者:小林coding
如果觉得本文对你有帮助,可以转发关注支持一下