postgreSQL源码分析——存储管理——内存管理(3)
2021SC@SDUSC
目录
- 概述
-
- 高速缓存机制的起源
- 源码分析
-
- 系统表元组缓存——SysCache
-
- catcacheheader结构体
- catcache结构体
- catcache如何组织缓存元组
- SysCache的初始化
-
- cachedesc结构体
- InitCatalogCache函数
- 在CatCache中查找元组
-
- 1.精确查找
- 2.部分查找
- 总结
概述
上篇博客分析完了内存上下文的相关操作,这次来分析postgreSQL的高速缓存(并非物理上的缓存)机制。
高速缓存机制的起源
由于postgreSQL在访问表时,首先需要获取模式信息(表的列名、OID等),而这些模式信息都放在了系统表中。因此,在访问表之前,就必须先访问系统表获取表的模式信息。而postgreSQL作为一个数据库系统,势必会进行大量的查询操作,从而导致对普通表和系统表的频繁访问。这种频繁访问是从硬盘读到内存中,而硬盘的读写速度是非常慢的(相较于内存和CPU)。因此,为了提高这种访问的效率,postgreSQL设立了高速缓存(Cache)。
源码分析
高速缓存实际上由两种缓存构成,分别是SysCache(系统表元组缓存)和RelCache(表模式信息缓存)。而缓存并非所有postgreSQL后端进程共享,而是每个进程都拥有自己的缓存,就像内存上下文一样。(这样设置比较合理,能够提高缓存的命中率)。这次主要分析SysCache,RelCache就留待下次分析。
系统表元组缓存——SysCache
SysCache用于缓存系统表元组。
是通过数组来实现的,数组的长度即为预定义的系统表的个数。每个数组元素的数据结构为catcache。
而catcache,根据注释,其由四个部分组成:
- struct catctup: individual tuple in the cache.
- struct catclist: list of tuples matching a partial key.
- struct catcache: information for managing a cache.
- struct catcacheheader: information for managing all the caches.
catcacheheader结构体
存储管理所有catcache的信息
源码位于src/include/utils/catcache.h中。
typedef struct catcacheheader
{
slist_head ch_caches; //指向catcache链表的头部
int ch_ntup; //链表中所有catcache中缓存元组的总数
} CatCacheHeader;
catcache链表
为了便于查找,syscache其实暗藏着一条catcache链表。链表头就在这个catcacheheader结构体中,而链表的实现就在下面的catcache中,通过一个名为cc_next的变量记录链表的next。
catcache结构体
存储管理单个catcache的信息
源码位于src/include/utils/catcache.h中。
typedef struct catcache
{
int id; //catcache的ID
int cc_nbuckets; //该catcache中hash桶的个数
TupleDesc cc_tupdesc; //对应的系统表元组描述符
dlist_head *cc_bucket; //hash桶构成的dlist链表,hash桶中实际缓存着系统表元组
CCHashFN cc_hashfunc[CATCACHE_MAXKEYS]; //用于每一个关键字的hash函数
CCFastEqualFN cc_fastequal[CATCACHE_MAXKEYS]; //每个关键字的快速判断相等函数
int cc_keyno[CATCACHE_MAXKEYS]; //每个关键字的属性数量
dlist_head cc_lists; //由catclist结构构成的dllist链表,用于缓存部分匹配的元组,每一个catclist结构保存一次部分匹配的结果元组
int cc_ntup; //缓存在该catcache中的元组数量
int cc_nkeys; //关键字的个数,取值范围为1~CATCACHE_MAXKEYS
const char *cc_relname; //catcache对应的系统表名称
Oid cc_reloid; //catcache对应的系统表的OID
Oid cc_indexoid; //catcache查找关键字上的索引OID
bool cc_relisshared; //对应的系统表是否是数据库之间共享的
slist_node cc_next; //即链表的next,用于连接到SysCache中的下一个catcache
ScanKeyData cc_skey[CATCACHE_MAXKEYS]; //为键预先填充好的ScanKey结构
//catcache使用的统计信息
#ifdef CATCACHE_STATS
long cc_searches; //总共查询该catcache的次数,每查询一次都会加一,不论是否成功。
long cc_hits; //该catcache的命中次数
long cc_neg_hits; //负元组的命中次数:如果一次查找在catcache和物理表中都没有找到匹配的元组,则会将这个未找到的元组作为一个负元组加入到catcache中
long cc_newloads; //将catcache中没有的元组载入其中的次数
//查询失败的次数即 cc_searches - (cc_hits + cc_neg_hits + cc_newloads)
long cc_invals; //该catcache中无效元组的个数
long cc_lhits; //在cc_lists中命中的次数
#endif
} CatCache;
关键字
每个catcache中都有若干个查找关键字,这些关键字及其组合可以用来在catcache中查找系统表元组,在初始化数据集簇时会在这些关键字上为系统表创建索引。
catcache如何组织缓存元组
每个catcache中的cc_bucket数组中的每一个元素都表示一个Hash桶,元组的键值通过Hash函数可以映射到cc_bucket数组的下标。每一个Hash桶都被组织成一个双向链表(dllist),其中的节点为dlist_node类型,通过在catctup(缓存元组)中添加该属性来实现hash桶。
dllist
//dlist的节点
typedef struct dlist_node dlist_node;
struct dlist_node
{
dlist_node *prev;//节点的前驱
dlist_node *next;//节点的next
//根据节点的这两个属性可以看出这是一个双向链表
};
//dlist的链表头
typedef struct dlist_head
{
dlist_node head;
//head.next会指向链表的第一个元素。如果是循环空链表则指向自己,如果是不循环的空链表则为NULL。
//head.prev会指向链表的最后一个元素。如果是循环空链表则指向自己,如果是不循环的空链表则为NULL。
} dlist_head;
catctup
typedef struct catctup
{
int ct_magic; //用于表示catctup这个结构体
#define CT_MAGIC 0x57261502 //ct_magic会被设置为这个值
uint32 hash_value; //该元组的Hash键值
Datum keys[CATCACHE_MAXKEYS];//该元组的查找关键字
//缓存中的每个元组都是存储其哈希桶元素的 dlist 的成员。每个dlist保持LRU顺序以提升重复查找的速度。
dlist_node cache_elem; //指向该元组所在的桶链表
int refcount; //对该缓存元组的引用计数
bool dead; //标记该元组是否死亡
//后续搜索不会返回死亡的元组。但是,在其引用计数refcount变为零之前,它不会从CatCache中物理删除。
//如果死亡元组同时也属于一个CatClist,则必须等到CatCList和CatCTup的refcount都变为0时才能将其从CatCache中清除。
bool negative; //标记该元组是否为负元组
HeapTupleData tuple; //缓存元组的头部信息,实际的元组数据存放在接下来的内存中(类似于内存上下文中的内存块头和内存块数据)。
struct catclist *c_list; //指向该元组所在的catclist,如果该元组不属于任何catclist则设置为NULL
CatCache *my_cache; //链接到该元组所属的catcache
} CatCTup;
负元组 实际上并不存在于系统表中,但是其键值曾经用于在CatCache中进行查找的元组。负元组只有键值,其他属性均为空。负元组的存在是为了避免反复到物理表中去查找不存在的元组所带来的I/O开销。
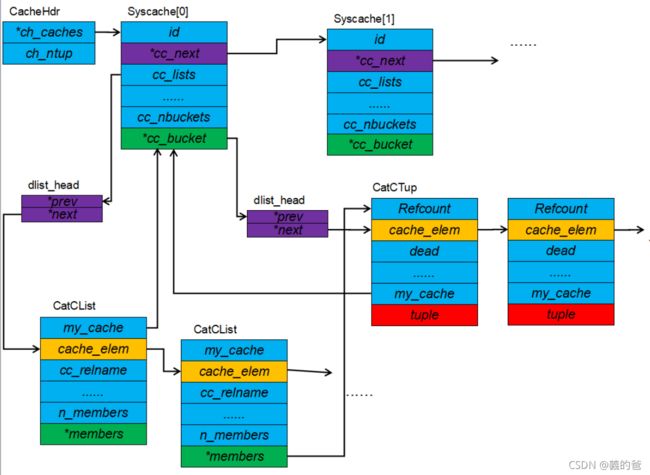
其总的结构就像图片一样。
SysCache的初始化
在postgre进程初始化时,会对SysCache进行初始化。而SysCache的初始化实际上是填充SysCache数组中每个元素的CatCache结构的过程,将查找系统表元组的关键字信息写入Syscache数组元素中。这样就可以通过关键字来快速定位到系统表元组的存储位置。
源码位于src/backend/utils/cache/syscache.c中。
而关于上面提到的SysCache数组,是以静态数组实现的,用于存放所有系统表的catcache信息。
static CatCache *SysCache[SysCacheSize];//SysCache数组
static const struct cachedesc cacheinfo[]={……}//集合中内容比较多,这里就省略了
是通过集合的形式,将其初始化的。
根据数组的定义,为cachedesc数组,可以知道每个系统表的catcache信息,即cacheinfo的数组元素,是以cachedesc结构体来描述的。
cachedesc结构体
struct cachedesc
{
Oid reloid; //catcache对应的系统表OID
Oid indoid; //catcache用到的索引OID
int nkeys; //系统表中OID属性的个数
int key[4]; //查询关键字的属性号
int nbuckets; //该catcache需要的hash桶数
};
InitCatalogCache函数
postgres进程初始化时,会调用InitCatalogCache函数对上面的syscache数组进行初始化,并建立由cacheheader记录的catcache链表。
void
InitCatalogCache(void)
{
int cacheId;//即cacheinfo数组序号,用于循环遍历
int i,
j;
//判断SysCacheSize是否为cacheinfo数组的长度,如果不是则报错。
StaticAssertStmt(SysCacheSize == (int) lengthof(cacheinfo),
"SysCacheSize does not match syscache.c's array");
Assert(!CacheInitialized);//如果已经初始化则不能再调用该函数,会报错。
SysCacheRelationOidSize = SysCacheSupportingRelOidSize = 0;
//SysCacheSize就是cacheinfo数组的长度,即对数组中每个元素进行遍历
for (cacheId = 0; cacheId < SysCacheSize; cacheId++)
{
//调用InitCatCache函数,根据cacheinfo中的每一个元素生成catcache结构并放入SysCache数组的对应位置中。
//即每调用一次,将处理一个cachedesc结构。InitCatCache函数将首先确保CacheMemoryContext存在,如果不存在会创建。
//然后切换到CacheMemoryContext中。然后检查cacheheader是否存在,不存在也会建立。然后根据cachedesc中hash桶的数量
//为要建立的CatCache结构分配内存,并根据cachedesc结构中的信息填充CatCache的各个变量。最后将生成的CatCache链接到
//cacheheader指向的链表的头部。
SysCache[cacheId] = InitCatCache(cacheId,
cacheinfo[cacheId].reloid,
cacheinfo[cacheId].indoid,
cacheinfo[cacheId].nkeys,
cacheinfo[cacheId].key,
cacheinfo[cacheId].nbuckets);
//初始化系统表OID链表
SysCacheRelationOid[SysCacheRelationOidSize++] =
cacheinfo[cacheId].reloid;
//初始化系统表和索引OID链表
SysCacheSupportingRelOid[SysCacheSupportingRelOidSize++] =
cacheinfo[cacheId].reloid;
SysCacheSupportingRelOid[SysCacheSupportingRelOidSize++] =
cacheinfo[cacheId].indoid;
}
//通过链表长度判断OID链表是否初始化成功
Assert(SysCacheRelationOidSize <= lengthof(SysCacheRelationOid));
Assert(SysCacheSupportingRelOidSize <= lengthof(SysCacheSupportingRelOid));
//给OID数组进行排序和去重,方便使用二分搜索来加速
pg_qsort(SysCacheRelationOid, SysCacheRelationOidSize,
sizeof(Oid), oid_compare);
for (i = 1, j = 0; i < SysCacheRelationOidSize; i++)
{//这个for循环研究半天,发现实际上是去除重复。可以这样想,假如OID数组里所有OID都相同,则这个for循环什么都不会做,但大小会变为1。你就会明白这个for循环的意义了。
if (SysCacheRelationOid[i] != SysCacheRelationOid[j])
SysCacheRelationOid[++j] = SysCacheRelationOid[i];
}
SysCacheRelationOidSize = j + 1;
//这段和上面大致相同
pg_qsort(SysCacheSupportingRelOid, SysCacheSupportingRelOidSize,
sizeof(Oid), oid_compare);
for (i = 1, j = 0; i < SysCacheSupportingRelOidSize; i++)
{
if (SysCacheSupportingRelOid[i] != SysCacheSupportingRelOid[j])
SysCacheSupportingRelOid[++j] = SysCacheSupportingRelOid[i];
}
SysCacheSupportingRelOidSize = j + 1;
CacheInitialized = true;//标记为已经初始化
}
在该函数中实际只完成了SysCache初始化的第一个阶段,后面还会有别的函数去调用InitCachePhase2函数进行第二阶段的初始化。InitCachePhase2函数将依次完善SysCache数组中的CatCache结构,主要根据对应的系统表填充CatCache结构中的元组描述符(cc_tupdesc)、系统表名(cc_relname)、查找关键字的相关字段(cc_skey、cc_hashfunc)等。
SysCache数组初始化完成之后,CatCache内是没有任何元组的,是随着系统运行,对系统表元组进行访问时动态增加的。
在CatCache中查找元组
在CatCache中查找元组是有两种方式的,我直接结合源码进行分析。
1.精确查找
这种查找方式需要所有键值,然后返回catcache中能完全匹配这个键值的元组。
HeapTuple
SearchSysCache(int cacheId,//要查找的cacheID
Datum key1,//四个键值
Datum key2,
Datum key3,
Datum key4)
{
Assert(cacheId >= 0 && cacheId < SysCacheSize &&
PointerIsValid(SysCache[cacheId]));//判断要查找的cacheID是否可用
return SearchCatCache(SysCache[cacheId], key1, key2, key3, key4);//调用SearchCatCache函数进行查找
}
//SearchCatCache函数
HeapTuple
SearchCatCache(CatCache *cache,
Datum v1,
Datum v2,
Datum v3,
Datum v4)
{
return SearchCatCacheInternal(cache, cache->cc_nkeys, v1, v2, v3, v4);//调用SearchCatCacheInternal函数进行查找
}
//SearchCatCacheInternal函数
static inline HeapTuple
SearchCatCacheInternal(CatCache *cache,
int nkeys,
Datum v1,
Datum v2,
Datum v3,
Datum v4)
{
Datum arguments[CATCACHE_MAXKEYS];//参数数组,用于存放键值
uint32 hashValue;
Index hashIndex;
dlist_iter iter;
dlist_head *bucket;
CatCTup *ct;
#ifdef CATCACHE_STATS
cache->cc_searches++;
#endif
//初始化参数数组
arguments[0] = v1;
arguments[1] = v2;
arguments[2] = v3;
arguments[3] = v4;
hashValue = CatalogCacheComputeHashValue(cache, nkeys, v1, v2, v3, v4);//计算出哈希值
hashIndex = HASH_INDEX(hashValue, cache->cc_nbuckets);//根据哈希值找到对应的哈希桶序号
bucket = &cache->cc_bucket[hashIndex];//根据刚才得到的哈希桶序号获取哈希桶
dlist_foreach(iter, bucket)//对哈希桶进行迭代
{
ct = dlist_container(CatCTup, cache_elem, iter.cur);
if (ct->dead)//忽略死亡的元组
continue;
if (ct->hash_value != hashValue)//哈希值错误则快速跳过
continue;
if (!CatalogCacheCompareTuple(cache, nkeys, ct->keys, arguments))//如果键值不匹配则跳过
continue;
//能够执行到这里说明在cache中找到了匹配的元组,将该元组移动到该哈希桶的链表头,这是为了加快后续搜索。
//为什么能加快后续搜索?这种采取了将最近访问最频繁的元素放在链表前部的做法能够使得频繁访问的元素得到快速访问。
dlist_move_head(bucket, &ct->cache_elem);
//对该元组进行判断
if (!ct->negative)//如果该元组不是负元组
{
ResourceOwnerEnlargeCatCacheRefs(CurrentResourceOwner);
ct->refcount++;//将它的引用技术加一
ResourceOwnerRememberCatCacheRef(CurrentResourceOwner, &ct->tuple);
CACHE_elog(DEBUG2, "SearchCatCache(%s): found in bucket %d",
cache->cc_relname, hashIndex);
#ifdef CATCACHE_STATS
cache->cc_hits++;//缓存命中次数加一
#endif
return &ct->tuple;//返回该元组
}
else//如果是负元组
{
CACHE_elog(DEBUG2, "SearchCatCache(%s): found neg entry in bucket %d",
cache->cc_relname, hashIndex);
#ifdef CATCACHE_STATS
cache->cc_neg_hits++;//缓存的负元组命中加一
#endif
return NULL;//返回未找到
}
}
//如果执行到这里,说明迭代结束都没有找到匹配的元组
return SearchCatCacheMiss(cache, nkeys, hashValue, hashIndex, v1, v2, v3, v4);//缓存查找失败
}
其实最后SearchCatCacheMiss函数这里,不只是返回缓存查找失败。我来分析一下它都做了些什么:
static pg_noinline HeapTuple
SearchCatCacheMiss(CatCache *cache,
int nkeys,
uint32 hashValue,
Index hashIndex,
Datum v1,
Datum v2,
Datum v3,
Datum v4)
{
ScanKeyData cur_skey[CATCACHE_MAXKEYS];//存放扫描用关键字
Relation relation;//存放表
SysScanDesc scandesc;//系统表扫描描述符
HeapTuple ntp;//存放元组
CatCTup *ct;//即哈希桶中元组指针
Datum arguments[CATCACHE_MAXKEYS];//存放关键字参数
//初始化参数数组
arguments[0] = v1;
arguments[1] = v2;
arguments[2] = v3;
arguments[3] = v4;
//将物理系统表
memcpy(cur_skey, cache->cc_skey, sizeof(ScanKeyData) * nkeys);
cur_skey[0].sk_argument = v1;
cur_skey[1].sk_argument = v2;
cur_skey[2].sk_argument = v3;
cur_skey[3].sk_argument = v4;
//打开对应的系统表
relation = table_open(cache->cc_reloid, AccessShareLock);
//对物理系统表进行扫描,确认要查找的元组是确实不存在还是没有缓存在CatCache中
scandesc = systable_beginscan(relation,
cache->cc_indexoid,
IndexScanOK(cache, cur_skey),
NULL,
nkeys,
cur_skey);
ct = NULL;
while (HeapTupleIsValid(ntp = systable_getnext(scandesc)))//从打开的系统表中获取元组
{
ct = CatalogCacheCreateEntry(cache, ntp, arguments,
hashValue, hashIndex,
false);//将元组放入哈希桶中
ResourceOwnerEnlargeCatCacheRefs(CurrentResourceOwner);
ct->refcount++;//立刻将引用次数设置为1
ResourceOwnerRememberCatCacheRef(CurrentResourceOwner, &ct->tuple);
break;//这是break是因为默认只找一个符合的
}
systable_endscan(scandesc);//关闭描述符
table_close(relation, AccessShareLock);//关闭打开的表
if (ct == NULL)//如果刚才没有在系统表中找到对应元组
{
ct = CatalogCacheCreateEntry(cache, NULL, arguments,
hashValue, hashIndex,
true);//构建一个负元组
CACHE_elog(DEBUG2, "SearchCatCache(%s): Contains %d/%d tuples",
cache->cc_relname, cache->cc_ntup, CacheHdr->ch_ntup);
CACHE_elog(DEBUG2, "SearchCatCache(%s): put neg entry in bucket %d",
cache->cc_relname, hashIndex);
//由于返回未找到,因此引用计数不必加一
return NULL;//返回未找到
}
CACHE_elog(DEBUG2, "SearchCatCache(%s): Contains %d/%d tuples",
cache->cc_relname, cache->cc_ntup, CacheHdr->ch_ntup);
CACHE_elog(DEBUG2, "SearchCatCache(%s): put in bucket %d",
cache->cc_relname, hashIndex);
#ifdef CATCACHE_STATS
cache->cc_newloads++;//缓存载入次数加一
#endif
return &ct->tuple;//返回装入ct数据结构中的元组
}
分析完这个函数,负元组的作用一下就明朗了。就是为搜索提速用的。如果要查找的键值对在物理系统表中也不存在,则为了下一次查找该键值对时也能够提速(不至于遍历完缓存再去遍历物理系统表,从而花费大量时间),就创造性的设计了一个负元组,用来根据要查找的键值对记录不存在的元组,从而也能够像普通元组一样使用LRU方式加速。
所以,整个搜索的流程就是:
- 先在缓存中搜索,如果找到则返回在缓存中的元组。
- 如果缓存中没有找到,则查找物理系统表,找到则返回生成的元组。否则将要查找的元组设置为负元组放入缓存。
2.部分查找
这种查找方式需要数个键值。
共有四种方法。
//第一种,一个键的部分搜索
HeapTuple
SearchSysCache1(int cacheId,
Datum key1)
{
Assert(cacheId >= 0 && cacheId < SysCacheSize &&
PointerIsValid(SysCache[cacheId]));
Assert(SysCache[cacheId]->cc_nkeys == 1);
return SearchCatCache1(SysCache[cacheId], key1);
}
//第二种,两个键的部分搜索
HeapTuple
SearchSysCache2(int cacheId,
Datum key1, Datum key2)
{
Assert(cacheId >= 0 && cacheId < SysCacheSize &&
PointerIsValid(SysCache[cacheId]));
Assert(SysCache[cacheId]->cc_nkeys == 2);
return SearchCatCache2(SysCache[cacheId], key1, key2);
}
//第三种,三个键的部分搜索
HeapTuple
SearchSysCache3(int cacheId,
Datum key1, Datum key2, Datum key3)
{
Assert(cacheId >= 0 && cacheId < SysCacheSize &&
PointerIsValid(SysCache[cacheId]));
Assert(SysCache[cacheId]->cc_nkeys == 3);
return SearchCatCache3(SysCache[cacheId], key1, key2, key3);
}
//第四种,四个键的部分搜索(我感觉和精确查找没有区别)
HeapTuple
SearchSysCache4(int cacheId,
Datum key1, Datum key2, Datum key3, Datum key4)
{
Assert(cacheId >= 0 && cacheId < SysCacheSize &&
PointerIsValid(SysCache[cacheId]));
Assert(SysCache[cacheId]->cc_nkeys == 4);
return SearchCatCache4(SysCache[cacheId], key1, key2, key3, key4);
}
当然,第二步也会调用SearchCatCacheInternal函数,只不过把没有的key用0代替。其余步骤都和精确搜索一样。
总结
大概了解了postgreSQL的SysCache的机制,就是对系统表的缓存。模拟操作系统的缓存机制,但实际上还是通过内存来实现的。我觉得比较受益的地方就是这个负元组的设计,非常巧妙。将某个不在缓存也不在物理系统表中的元组,变成一个“元组”放在缓存中,从而使得下次再查找这个元组也能够加速,避免了无意义的多次查表。