集合 第一章
集合
- 2.集合
-
- 2.1 List和Set的区别
-
- 2.1.1 List和Set的底层实现
- 2.2 ArrayList和LinkedList的区别
-
- 2.2.1 数组和链表
- 2.2.2 ArrayList和数组的区别
- 2.2.3 ArrayList是线程安全的吗?
- 2.2.4 为什么说ArrayList是线程不安全的?
- 2.2.5 如何线程安全地操作ArrayList
- 2.2.6 ArrayList默认的数组大小是多少?
- 2.3 ArrayList扩容
- 2.4 subList与原始List相互影响
- 2.5 List的不安全删除、安全删除
- 2.6 List的去重
- 2.7 HashMap,TreeMap,LinkedHashMap的区别
- 2.8 HashMap的原理
- 2.9 ConcurrentHashMap的原理
2.集合
2.1 List和Set的区别
List和Set是Java集合框架中的两个重要接口,它们都继承自Collection接口
| 项 | List | Set |
|---|---|---|
| 元素存储顺序 | 有序的, 元素按照插入顺序存储 | 无序的, 元素存储顺序不固定 |
| 元素重复性 | 可以包含重复元素 | 不允许包含重复元素 |
| 实现类 | ArrayList、LinkedList、Vector | HashSet、LinkedHashSet、TreeSet |
2.1.1 List和Set的底层实现
- List
- ArrayList: 底层基于动态数组实现, 支持对元素进行快速的随机访问。当数组容量不足时,会自动扩容
- LinkedList: 基于双向链表的实现,支持在链表的头部和尾部进行高效的插入和删除操作。
- Vector: 也是基于动态数组的实现,但是它是线程安全的。
- Set
- HashSet: 基于哈希表的实现,不保证元素的顺序。允许存储 null 值
- LinkedHashSet: 基于哈希表和链表的实现,维护了元素的插入顺序。
- TreeSet: 基于红黑树的实现,元素按照自然顺序或者指定的比较器进行排序
2.2 ArrayList和LinkedList的区别
| 项 | ArrayList | LinkedList |
|---|---|---|
| 底层数据结构 | 基于动态数组的实现,支持对元素进行快速的随机访问 | 基于双向链表的实现,支持在链表的头部和尾部进行高效的插入和删除操作 |
| 随机访问性能 | 随机访问性能较高,因为它是基于数组的,可以直接通过索引访问元素。 | 随机访问性能较低,因为它是基于链表的,需要遍历链表才能访问到指定位置的元素。 |
| 插入和删除性能 | 插入和删除性能较低,因为在插入或删除元素时,需要移动数组中的其他元素以维护数组的连续性 | 插入和删除性能较高,特别是在链表的头部和尾部,因为只需要修改指针就可以完成插入和删除操作 |
| 内存占用 | 占用内存较少,因为它只需要存储元素的数组和数组的长度 | 占用内存较多,因为它需要存储元素、前驱指针和后继指针 |
随机访问
指能够直接通过索引访问到集合中的任意位置的元素,而不需要从头开始遍历集合。随机访问是一种时间复杂度为 O(1) 的高效操作,也就是说,随机访问的时间开销与集合的大小无关。
ArrayList 支持随机访问是因为它的底层实现基于动态数组。在数组中,元素是按照顺序存储在连续的内存空间中的,每个元素都有一个唯一的索引,通过索引可以直接定位到数组中的任意位置的元素。
由于数组中的元素是连续存储的,因此可以通过计算偏移量来直接定位到数组中的任何位置。
2.2.1 数组和链表
| 数组 | 链表 | |
|---|---|---|
| 存储结构 | 数组是一种基于连续内存空间的数据结构,元素按顺序存储在内存中。数组具有固定的大小,一旦创建就无法改变大小。 | 链表是一种基于节点的数据结构,每个节点包含一个数据元素和一个指向下一个节点的指针。链表的节点不需要在内存中连续存储。 |
| 访问时间 | 支持随机访问,可以在 O(1) 的时间复杂度内直接通过索引访问数组中的任意元素。 | 不支持随机访问,需要从头节点开始遍历链表才能访问到指定位置的元素,时间复杂度为 O(n)。 |
| 插入和删除操作 | 插入和删除操作效率较低,因为在插入或删除元素时,需要移动数组中的其他元素以维护数组的连续性。 | 插入和删除操作效率较高,特别是在链表的头部和尾部,因为只需要修改指针就可以完成插入和删除操作 |
| 空间占用 | 占用内存较少,因为它只需要存储元素的数组和数组的长度。 | 占用内存较多,因为它需要存储元素、前驱指针和后继指针。 |
2.2.2 ArrayList和数组的区别
| 项 | ArrayList | 数组 |
|---|---|---|
| 动态性 | 动态的,它的大小可以根据需要自动增长和缩小 | 数组是静态的,一旦创建,其大小就无法改变 |
| 功能丰富 | 提供了许多方便的方法来操作集合中的元素,如添加、删除、查找、排序等 | 数组的操作相对较简单,主要是通过索引访问元素 |
| 性能特点 | ArrayList的实现类通常提供了更好的插入和删除性能,但是在随机访问性能上可能不如数组 | 数组由于其连续的内存结构,可以在 O(1) 时间复杂度内随机访问元素 |
| 存储元素的类型 | ArrayList是泛型的,可以存储任意类型的元素。 | 数组必须存储相同类型的元素 |
2.2.3 ArrayList是线程安全的吗?
ArrayList是不安全的, 这意味着多个线程同时访问ArrayList对象可能会导致数据的不一致或数据的丢失。
2.2.4 为什么说ArrayList是线程不安全的?
为什么说ArrayList是线程不安全的?
2.2.5 如何线程安全地操作ArrayList
- Collections.synchronizedList() 方法包装 ArrayList
- CopyOnWriteArrayList 替代 ArrayList
- 访问 ArrayList 之前先获取 ArrayList 对象的锁
2.2.6 ArrayList默认的数组大小是多少?
ArrayList 默认初始化大小为 10
2.3 ArrayList扩容
ArrayList的扩容主要发生在向ArrayList集合中添加元素的时候,通过add()方法添加单个元素时,会先检查容量,看是否需要扩容
如果容量不足需要扩容则调用grow()扩容方法,扩容后的大小等于扩容前大小的1.5倍,也就是10+10/2。
比如说超过10个元素时,会重新定义一个长度为15的数组。然后把原数组的数据,原封不动的复制到新数组中,这个时候再把指向原数的地址换到新数组。
注意: 使用ArrayList时,可以 new ArrayList(大小)构造方法来指定集合的大小,以减少扩容的次数,提高写入效率。
2.4 subList与原始List相互影响
public class Demo {
public static void main(String[] args) {
List<Integer> integerList = new ArrayList<>();
integerList.add(1);
integerList.add(2);
integerList.add(3);
List<Integer> subList = integerList.subList(0, 2);
subList.set(0, 10);
integerList.set(1, 20);
System.out.println("integerList" + integerList);
System.out.println("subList" + subList);
}
}
运行结果:
integerList[10, 20, 3]
subList[10, 20]
Java的List之坑–subList与原始List相互影响
2.5 List的不安全删除、安全删除
不安全删除
import java.util.ArrayList;
import java.util.List;
public class UnsafeRemovalExample {
public static void main(String[] args) {
List<String> fruits = new ArrayList<>();
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 错误的删除方式,可能导致并发修改异常
for (String fruit : fruits) {
if (fruit.equals("Banana")) {
fruits.remove(fruit); // 不安全的删除
}
}
}
}
直接调用 remove 方法来删除元素,可能导致遍历的异常或者删除错误的元素。这是因为在使用迭代器或者增强for循环遍历List的同时,直接调用 remove 方法会破坏迭代器的状态,可能引起并发修改异常(ConcurrentModificationException)。
安全的删除
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class SafeRemovalExample {
public static void main(String[] args) {
List<String> fruits = new ArrayList<>();
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 使用迭代器进行安全的删除
Iterator<String> iterator = fruits.iterator();
while (iterator.hasNext()) {
String fruit = iterator.next();
if (fruit.equals("Banana")) {
iterator.remove(); // 安全的删除
}
}
}
}
通过使用迭代器的 remove 方法,可以避免并发修改异常,确保在遍历过程中安全地删除元素
2.6 List的去重
- Stream流的distinct方法
- 转为HashSet(分不保持顺序和保持顺序两种)
- 转为TreeSet
HashSet和TreeSet的的区别
| HashSet | TreeSet | |
|---|---|---|
| 存储方式 | 使用哈希表实现, 通过哈希函数将元素映射到存储桶中. 。它是基于散列的,元素的存储顺序不是按照它们被添加的顺序。 | 使用红-黑树(一种自平衡的二叉查找树)实现,元素会按照它们的自然顺序或者通过构造方法指定的比较器进行排序 |
| 排序 | 不保证元素的顺序,因为它是基于哈希表实现的,元素的存储位置与它们的比较顺序无关 | 元素是有序的,可以按照元素的自然排序或者通过比较器指定的顺序进行排序 |
| 性能 | 插入、删除和查找操作的平均时间复杂度是 O(1),但在极端情况下可能会达到 O(n)(例如,哈希冲突较多时) | 插入、删除和查找操作的平均时间复杂度是 O(log n),因为红-黑树是自平衡的,保持了相对平衡的高度 |
| 使用场景 | 适用于需要快速查找、插入和删除操作,并且不关心元素的顺序的场景。 | 适用于需要有序集合,并且对元素的自然排序或特定排序方式有要求的场景。 |
2.7 HashMap,TreeMap,LinkedHashMap的区别
| HashMap | TreeMap | LinkedHashMap | |
|---|---|---|---|
| 数据结构 | 基于哈希表实现,使用哈希算法来存储键值对 | 基于红黑树实现,保证了元素的有序性 | 基于哈希表和双向链表实现 |
| 按插入顺序存放 | 不保证元素的存储顺序,具体顺序可能随时间而变化 | 根据键的自然顺序或通过构造方法提供的比较器进行排序。 | 保持了元素插入的顺序,迭代顺序和插入顺序一致 |
| 性能 | 基于哈希表实现,使用哈希算法来存储键值对 | 基于红黑树实现,保证了元素的有序性 | 基于哈希表和双向链表实现 |
| 使用场景 | 当你需要高性能的哈希表,而不关心元素的顺序时,可以选择; 适用于大多数情况下的键值对存储,因为它提供了平均 O(1) 时间复杂度的插入、删除和查找操作 | 当你需要按键的自然顺序或者提供的比较器进行排序时,可以选择; 适用于需要按顺序遍历键值对的场景,因为它的元素是有序的 | 当你希望保持元素插入的顺序,并且可以按照插入顺序迭代时,可以选择 |
TreeMap根据键的自然顺序或通过构造方法提供的比较器进行排序
public static void main(String[] args) {
// 创建TreeMap
TreeMap<Integer, String> treeMap = new TreeMap<>();
// 向TreeMap插入键值对
treeMap.put(3, "Three");
treeMap.put(1, "One");
treeMap.put(5, "Five");
treeMap.put(2, "Two");
treeMap.put(4, "Four");
// 使用迭代器按键的升序顺序遍历TreeMap
treeMap.entrySet().stream().forEach(t-> System.out.println(t));
}
输出结果:
1=One
2=Two
3=Three
4=Four
5=Five
linkedHashMap保持了元素插入的顺序,迭代顺序和插入顺序一致
public static void main(String[] args) {
// 创建TreeMap
LinkedHashMap<Integer, String> linkedHashMap = new LinkedHashMap<>();
// 向TreeMap插入键值对
linkedHashMap.put(3, "Three");
linkedHashMap.put(1, "One");
linkedHashMap.put(5, "Five");
linkedHashMap.put(2, "Two");
linkedHashMap.put(4, "Four");
// 使用迭代器按键的升序顺序遍历TreeMap
linkedHashMap.entrySet().stream().forEach(t-> System.out.println(t));
}
输出结果:
3=Three
1=One
5=Five
2=Two
4=Four
2.8 HashMap的原理
HashMap是基于哈希表实现
- 哈希表
hashMap底层数据结构是哈希表, 它是一个数组, 每个数组元素是一个链表或者红黑树. 数组的每个位置被称为桶, 每个桶存储一个链表或者树的头节点, 该节点包含键值对 - 哈希算法
当我们向HashMap中放入键值对时, HashMap会通过哈希算法计算键的哈希码, 哈希码将被用作数组的索引, 以确定将键值对放置在哪个桶中, java中的hashCode()方法用于生成哈希码 - 冲突解决
不同的键可能产生相同的哈希码,这就是哈希冲突。为了解决冲突,HashMap 使用链表或红黑树。当多个键映射到同一个桶时,它们将形成一个链表。当链表的长度达到一定阈值(默认为8),链表将被转化为红黑树,以提高查找性能。 - 扩容
当哈希表中的元素数量超过容量乘以负载因子时,HashMap 将进行扩容。扩容会导致数组大小翻倍,并且所有的键值对需要重新计算哈希码并分布到新的桶中。扩容是一个相对耗时的操作,但它确保了 HashMap 在不同负载因子下的性能平衡 - 链表与树的转换
在 Java 8 中引入了红黑树来代替链表,以提高查找性能。当链表的长度达到一定阈值时,链表将被转换为红黑树。当红黑树的节点数量降到较低水平时,红黑树将再次转换为链表。
HashMap和ArrayList底层基于数组实现, ArrayList的数组元素可以是任意对象, 而HashMap的数组元素是链表或者红黑树(这种数据结构也被称为即哈希表), 它存储了链表的头节点, 该节点包含了键值对的信息, 当我们向HashMap中存入键值对, HashMap会通过哈希算法计算键的哈希码, 并基于当前数组的容量计算出索引, 以确定将键值对放在哪个索引, 为了解决哈希冲突, 使用了链表, 当多个键映射到同一个索引, 它们会形成一个链表, 当链表长度达到一定的阈值(默认为8), 链表会转换为红黑树, 以提高查找性能.
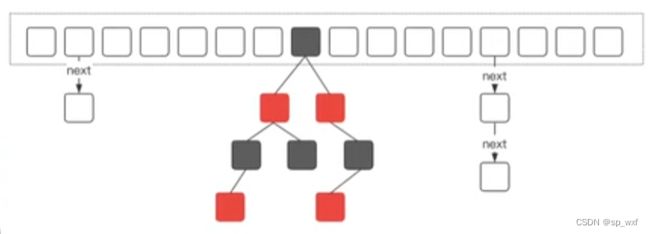
当HashMap进行扩容时,会更改键值对在数组中的存储位置
在扩容时会创建一个新的更大的数组,并将已有的键值对重新分配到新的数组中。这是为了保持负载因子在一个合理的范围内,避免哈希冲突的增多,保持 HashMap 的性能。
扩容的过程主要包括以下步骤:
- 创建新数组: HashMap 创建一个新的数组,通常是当前数组大小的两倍。新数组的大小是一个 2 的幂,这有助于通过位运算更有效地计算哈希码的索引。
- 重新哈希: 对于原数组中的每个非空桶,将桶中的键值对重新计算哈希码,并放入新数组的相应位置。这一过程可能会导致原本哈希码相同的键值对在新数组中的存储位置发生改变。
- 替换旧数组: 将新数组替换为 HashMap 的内部数组,以使其成为新的工作数组
2.9 ConcurrentHashMap的原理
JDK8中ConcurrentHashMap结构基本上和HashMap一样, 都是采用了哈希表作为底层结构, 为了实现线程安全, 它在读操作使用volatile,写操作使用synchronized 和CAS
一、读操作使用volatile
使用volatile关键字的作用
- 保证可见性
当一个变量被声明为 volatile 时,表示它是一个共享变量,多个线程都可以看到它的最新值。当一个线程修改了 volatile 变量的值,这个新值对于其他线程是立即可见的。这是因为 volatile 会告诉编译器不要对这个变量进行优化,要求每次都从内存中读取最新的值。 - 禁止指令重排序
编译器和处理器在执行指令时可能会对指令进行重排序,这可能导致在子线程中看到的执行顺序与实际的执行顺序不一致。因此,即使变量在主内存中被修改,子线程也可能在不同的时刻看到不同的值。
二、在多线程环境中,一个线程对变量的修改可能对其他线程不可见(代码验证)
public class VolatileVisibilityExample {
private static boolean flag = false;
public static void main(String[] args) {
// 线程1:修改 flag 的值
Thread writerThread = new Thread(() -> {
try {
Thread.sleep(2000); // 等待一段时间
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = true; // 修改 flag 的值
System.out.println("Flag is set to true.");
});
// 线程2:检查 flag 的值
Thread readerThread = new Thread(() -> {
while (!flag) {
// 等待 flag 的值变为 true
}
System.out.println("Flag is now true.");
});
// 启动线程
writerThread.start();
readerThread.start();
}
}
输出结果:
Flag is set to true.
在这个例子中, readerThread在一个循环中等待flag变为true, 问题在于: 当writerThread 将flag修改为true时, 这个修改不一定会立即被readerThread察觉到. 这是因为在 Java 中存在指令重排序和线程本地缓存的问题, 这可能导致readerThread无法及时看到flag的变化。
当writerThread执行 flag = true; 语句时,这个操作可能被重排序,导致修改的结果在主内存中并未立即生效。而readerThread在while (!flag) 的循环中,由于没有使用volatile关键字修饰flag,它可能会在本地缓存中一直读取flag的旧值,而不会去主内存中获取最新的值。
三、线程本地缓存(Thread Local Cache)
线程本地换成指每个线程独立维护的存储区域,用于存储共享变量的副本。这个存储区域是线程私有的,不同线程之间不共享这个存储空间。
在多线程编程中,线程本地缓存的存在是为了提高程序的性能。当一个线程访问共享变量时,它会首先尝试从自己的本地缓存中获取这个变量的值。如果在本地缓存中找到了最新的值,线程就可以直接使用这个值而不必访问主内存,因为在多级缓存的层次结构中,本地缓存通常比主内存的访问速度更快。
线程本地缓存的使用可以提高读取和写入的速度,并减少线程之间因共享变量而引起的竞争。这有助于提高程序的并发性能。然而,线程本地缓存也引入了一些问题,最主要的是可见性问题,即一个线程对共享变量的修改何时对其他线程可见。在需要保证可见性的场景中,需要使用适当的同步机制或者使用volatile关键字来确保正确的线程间通信。
四、线程本地缓存的时机
- 初始化时
当线程启动时, 会将共享变量从主内存中加载到线程的本地缓存中, 形成副本 - 读取操作时
当线程执行读取操作时, 会首先从本地缓存中查找共享变量的值, 如果在本地缓存中找到最新的值, 线程会直接使用这个值, 而不必访问主内存 - 写入操作时
当线程执行写入操作时,会将修改后的值写入本地缓存,并在适当的时机将这个值刷新回主内存。刷新回主内存的时机是由编译器和处理器决定的,并不一定是立即进行的。 - 锁定和解锁时
在使用锁的情况下,线程在获取锁的时候会将共享变量的值从主内存加载到本地缓存中,而在释放锁的时候会将修改后的值刷新回主内存。
五、线程本地缓存的值, 什么时候刷新到主内存?
- volatile关键字
如果一个变量被声明为volatile,则对该变量的写操作会立即刷新到主内存,而读操作会从主内存中获取最新的值。这确保了对volatile变量的修改对其他线程是可见的。 - 锁机制
在使用锁(例如synchronized关键字)的情况下,释放锁的时候会将本地缓存中的值刷新到主内存,而获取锁的时候会将主内存中的值加载到本地缓存。这种同步机制确保了在临界区内对共享变量的修改对其他线程可见。 - 线程结束
当线程结束时,其工作内存中的内容可能会被刷新到主内存。这确保了线程结束时的最终状态对其他线程是可见的。但需要注意,并不是所有的线程结束时都会导致工作内存的内容刷新到主内存,具体取决于线程的实现和操作系统的策略。 - 显式同步操作
通过显式的同步操作,比如await()和signal()等,也可能会引起工作内存和主内存之间的数据同步。