管道进行进程间通信(中)(实现一个简单的进程池)
在上一篇的博客中我说明了一些关于管道的特征特点如下:

其中对于3和4特征这里只需要知道即可,我会在后面的博客讲解。
然后我们测试了管道的前三种情况:
第一种:读写端正常,管道为空,读端就要阻塞.
第二种:读写端正常,管道如果被写满,写端就要阻塞
第三种:读端正常,写端关闭,那么读端就会读到0,表明读到了文件(pipe)结尾,但是此时的读端是不 会被阻塞的
首先我们来检测管道的第四种情况:
管道的第四种情况
写端是正常的但是读端被关闭了。其实在这种情况下写信息已经没有必要了。
因为你写数据的目的就是为了让读端能够拿到数据,但是现在的读端都已经不再了,那么写端是没有存在的必要了。所以我们可以在这里猜测这里大概率是不会继续进行写文件的。
而在这里我们也可以将这个理念再上升一下:即我们的os是不会做低效,浪费等类似的工作的,如果做了,就是os的bug。因为os是一个底层的基础软件如果底层的软件都会出现这样浪费内存的情况,那么更何况是在这个系统上面跑的软件了。因为软件是一定需要使用os提供的系统调用的。
那么回到我们刚刚说明的那个情况此时的读端已经不存在了,那么写端自然也就没有存在的必要了。所以os会将这个进程杀掉,但是如何杀掉呢?
因为此时的写端是一个正在运行的进程(代码没有跑完)但是因为一些特别的情况os直接将这个进程杀掉了。那么os是如何杀掉这个进程呢?
![]()
os是通过信号将这个进程杀掉的。下面我们就来验证os是通过哪一个信号杀掉这个进程的呢?
这也是为什么我们在之前的代码中设定的是:

这里我们先让父进程停止读取,父进程在停止读取之后,子进程就会被os杀掉,而我们的父进程就会得到子进程死亡的详细信息。
这样我们就能知道子进程是被几号信号杀掉的了。
下面我们就来修改代码:对于写端的代码不需要修改,而读端的代码我们则在读端读取5次信息之后,让Read函数直接退出。

然后就是父进程需要做的一些改变了。

我们这里再父进程完成读取的工作之后直接让父进程关闭读端,此时子进程会被杀死,然后通过监测脚本我们应该可以看到子进程此时是处于僵尸状态的(父进程在回收子进程前会休眠10秒)。然后父进程会接收子进程死亡之后的信息,让子进程彻底的死亡,最后打印出信息之后,父进程退出。
下面是运行截图:


从中我们也可以看到我们的假设这是成立的,最后子进程的退出码是0,而子进程的退出信号则是13。这个结果是符合我们的预期的。而这个子进程的退出也符合进程退出的情况。
进程退出存在三种情况:
第一种:代码跑完结果对。
第二种:代码跑完结果不对。
第三种:代码没有跑完,进程出现异常了。
很显然是符合第三种情况的。
下面我们来看一下这个13号信号是什么信号。

从图中我们可以看到13号信号是SIGPIPE信号。
那么最终我们得到的第四个情况的结论就是,当读端关闭,写端正常的时候,os会通过13号信号将写端直接杀死。
以下就是管道的四种情况和5大特性:

下面我们来了解一下管道的应用场景:
管道的应用场景
第一种管道的应用场景自然就是我们在命令行中使用的|了。如下面这种:
![]()
这个|就是管道,这个管道和我们上面所说的pipe(管道文件)也是有关系的。有什么关系呢?我们来验证一下。
首先我们观察一下上面这三个命令的执行进程之间的关系。当然为了能够观察到执行这三个命令的进程之间的关系,我们肯定要使用执行时间比较长的命令(sleep命令),虽然使用管道将三个sleep联通起来是没有任何的意义的,但是能够让我们看到这三个进程的关系(使用简单的监控脚本)。


通过这个监控我们能够发现当我们使用管道将这些命令链接起来的时候,其一:每一个对应的命令都会直接启动成一个进程。这三个命令的ppid都是一样的。我们再来看一下这个ppid的信息。

很显然这个1626就是bash。
所以这三个进程之间的关系就是:具有血缘关系的进程。
这里bash所做的工作就是创建了两个管道,然后创建出了三个子进程,之后重定向了一下这三个子进程的输入和输出。由此就将三个命令构建出了关系。
所以我们在命令行上启动的管道其实本质就是我们在上面所说的这个管道。
使用管道实现一个简易版本的进程池
简单理解池化技术
既然我们要实现一个简易版本的进程池我们首先肯定是要知道什么是池化技术。
我们先举一个生活中的例子,在很多小区中都是有水站的,在你没有叫送水工的前提下,你自己一天需要花一桶水,然后你每天都要往返一次水站,你就觉得很烦。然后有一天你拿了一个拉车,然后一次性搬了好几桶水在家中。这几桶水够你使用好几天了,而将这好几桶水放到家中的过程你就可以认为是在你的家中建立了一个蓄水池。毫无疑问这个蓄水池的建立是为了减轻我们生活中的操作成本的(不需要每天都去一趟水站了)。同理当我们在c++中使用new申请空间的时候,一定是要经过系统调用去申请空间的。如果你向os非连续的申请了三次空间,也就意味着os需要为你调用三次系统调用。那么为什么我不直接向os要一大段的空间,然后我接下来需要使用空间的时候就直接从之前申请的这一批空间中拿取就可以了。
那么这样我们就只进行了一次系统调用,就能够减少用户层调用系统调用的次数。而系统调用也是有成本的。这个成本体现在如果每次都是我们需要多少再去调用,就会让效率有些降低。所以我们就想要减少系统调用的次数。在申请空间的时候,一次多要些空间,之后再使用空间的时候,就从之前申请的空间中拿取。而之前申请的空间的管理由用户自己来做,而这个之前申请的空间也就是内存池。所以池化技术就是为了提高我们的访问速度和响应的效率。
实现思路
那么这里的进程池就是,在没有使用进程池之前,父进程发布任务之后,在建立子进程,而现在就是在父进程发布任务之前就已经将子进程创建完成了,之后父进程发布任务就不需要重新创建子进程了,直接从我们之前创建的子进程中选择一个去执行父进程分配的任务即可。
以上就是我们的简易进程池的原理。下面就是图像表示:
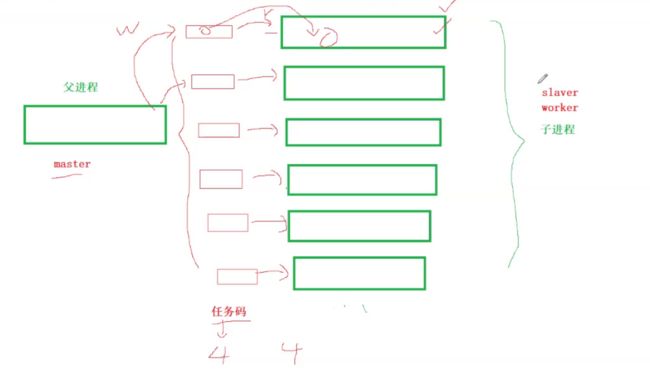
首先我们的父进程创建一批子进程然后我们的父进程和这些子进程都建立对应的管道。然后我们让每一个子进程都只向管道中进行读取。而我们的父进程则管理着这一批子进程,父进程想要往那个管道中写入内容就往哪一个管道中写入内容。

那么如果我们的父进程没有往第一个管道中写入内容那么我们的这个第一个子进程在做什么呢?
这个子进程就在等待着自己的管道中出现数据,也就是我们的这个子进程阻塞在这个管道这里,等待父进程写入对应的是数据。如果父进程往这个管道中写入了对应的数据,那么子进程就会继续往下执行对应的任务(结合写入的数据执行对应的任务)。
现在我们规定的就是父进程往子进程中写的都是一个一个的任务,具体的这个任务是什么,有我们自己设置,因为这里没有将协议加上,所以我们这里设置的任务是简单点的。
这里我们规定好,父进程在往子进程写入的时候一次只能写4个字节作为任务码。然后子进程在读取的时候也只能读取四个字节,也就是父子进程都是以等长的数据来进行写入/读取。这里我们就可以将我们的父进程称之为master,我们将子进程称之为slaver/worker。也就是我们的父进程可以向不同的子进程发布不同的任务。
在这个思路中我们的父进程要做的工作就是选择任务和选择进程。至于任务是什么我们之后再设置。首先就是创建三个文件:

这个hpp文件就是将头文件.h和源文件.cpp可以写到一起。一般而言这样写的文件都是不会打成库的。一般很多开源项目中都存在这样的文件。我们将头文件和源文件分开实现的版本,一般而言都是为了将其打包成库,给予别人使用的。
描述管道以及完成对控制模块的初始化
再将对应的头文件都包含之后我们首先就是需要描述管道。

到这里我们就将一个一个对应的管道描述起来了。
那么现在我们将对应的管道描述起来了,下面就是要将这些管道管理起来了,如何管理呢?很简单我们使用stl容器将这个channel的对象储存起来就可以了。
此时将管道管理好也就变成了只需要将这个stl容器管理好即可,也就是管理好vector的增删查改即可。

那么如果下面我们的父进程要放松任务,只需要从vector中选择一个channel对象,然后将使用这个channel对象中的字段就能将这个任务发布下去了。
那么下面我们就要根据你所想要创建的子进程的个数(设定一个宏即可),创建出一批进程,光创建好这批进程还不行必须将这些进程对应的管道也需要建立好,然后根据创建好的子进程的pid,以及管道的读写端,做一下初始化。
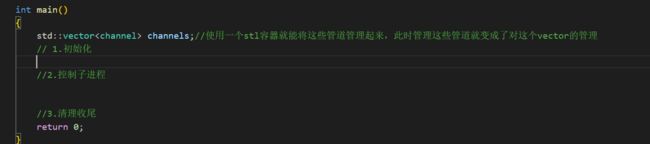
初始化的工作:创建子进程,创建子进程对应的管道,将父子进程的读写端进行处理(父进程写,子进程读),最后给与每一个子进程一个名字,根据对应的信息将其插入到channels中。

但是这样初始化其实是存在bug的这个bug我们在后面会提出。这里的processnum就是我们设置的你要建立的管道个数。
下面我们就来测试一下是否如我所料创建了对应的10个子进程。我这里将channels中的数据全部打印出来查看一遍。

测试截图:
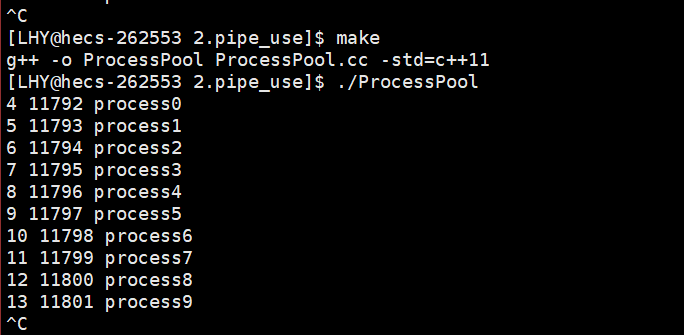

可以看到确实是创建了10个子进程。因为我这里是将子进程的worker函数写成了一个死循环,所以这里的子进程处于的是非僵尸状态。
从打印出来的信息也可以看到这些子进程对应的写端的文件描述符下标也已经设置完成了(4,5,6,,7,8等等),那么为什么是这样的数字呢?
此时对应的子进程以及和子进程沟通的xi都已经创建完毕了。但是这个代码其实是存在bug的,这个bug我们在后面会提出。
那么下面我们再将这里的所有的属于初始化的工作提取出来作为一个单独的模块。让我们的代码的可读性提高。

因为这里我们需要的是通过一个channels的vector去管理对应的channel。所以这里我们就将我们在main函数中创建的channels传递过来。通过这里的参数我们也要理解一个编码的规范。

这里我们可以根据一个简单的编码的规范。
首先如果我们设计的函数需要的是一个输入型参数:那么我们使用的就是一个const &(const引用)
其次如果我们设计的函数需要的是一个输出型参数:*(如果你需要的是一个输出的话我们使用的就是指针)
最后如果我们设计的函数需要的是一个输入/输出型参数: &(如果你需要的是一个输入/输出的话直接使用一个引用就可以了)

所以我们在下面设计函数的参数的时候,特别是这种stl的参数的时候,我们会按照这种命名的规范来写。
当然这个只是建议。
然后我们再将我们刚刚做的测试的代码也专门做一下简单的封装:

封装完成之后我们再次编译运行一下:
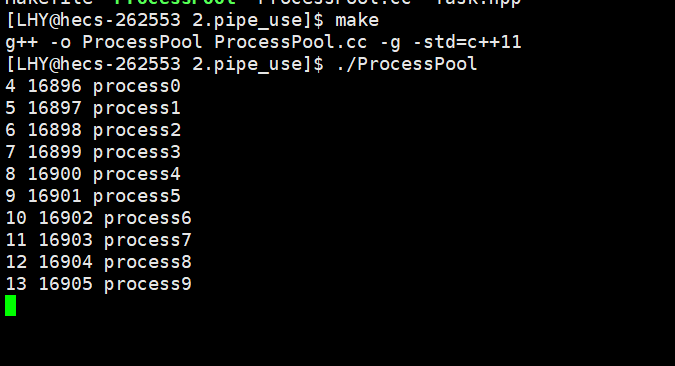
监控脚本这里就不再看了,但是这也说明我们的这个简单的封装是没有问题的。
下面我们就要来对进程进行控制了
对子进程进行控制
控制子进程也就是要告诉对应的子进程这里需要你做什么。
对于这件事情首先你就需要让子进程读到对应的内容
也就是我们的父进程要通过管道去写,而我们的子进程要通过对应的管道去读取信息。
那么为了让我们的子进程都能找到对应管道的写端,所以第一种实现的方法就是在slaver函数这里将我们每一个子进程对应的管道对应的读端作为参数传递过去。
![]()
通过这里的rfd我们的子进程就能找到自己管道对应的读端,然后从读端读取信息。
在主函数这里我们是这样做的
![]()
下面我们再来验证一下我们的子进程是否都拿到了属于自己的管道的读端。

我们可以打印一下每一个子进程对应的读端的描述符号。
运行结果:

我们可以看到我们每一个对应的子进程的读端都是3。证明我们的子进程确实拿到了自己对应的管道的读端。
通过图像中的信息我们可以看到父进程得到的文件描述符都是不一样的从4开始往后5.......13。而我们的每一个子进程得到的读端的下标都是3。那么这个现象是正常的吗?
这个是正常的,我们只需要做简单的分析即可。首先我们得父进程在创建管道的时候。3下标对应的就是管道的读端,而4下标对应的就是管道的写端。之后我们的父进程会关闭3下标对应的文件。而以这个父进程为模板创建的子进程则将4号关闭了。
那么下面我们的父进程创建第二个子进程,此时的父进程的文件描述符标中0124都已经被分配了。所以当此时的父进程再次创建管道的时候,管道的读端依旧是3而管道的写端就是5了。父进程依旧是将3关闭。而这里的子进程则是将5关闭。所以我们的子进程得到的都是3,而父进程得到的就是456789.....等等。
这是一种方法。但是我们还可以使用一种方法。我们之前应该学习过关于重定向的知识。那么我们可以将每一个子进程进行对应的输入重定向,将默认从键盘读取(0)改为默认从管道的读端(pipefd[0])进行读取信息。
做了重定向之后我们的slaver函数就不需要再带上参数了。之后我们的子进程想要拿取任务直接从0中拿取就可以了。

这里的dup2函数的作用就是子进程的文件描述符数组下标中第pipefd[0]中的内容拷贝到这个子进程的文件描述符数组中0号的位置。完成了这个工作那么这个子进程就从默认从键盘(标准输入0)读取变成了从管道的写端(文件描述数组中第pipefd[0]中对应的内容)读取。这之后你即使将子进程对应的pipefd[0]关闭了也是可以的。

这里我就选择了第二种方法。
那么这我们的父子进程的写入关系就变成了:我们的父进程从管道往子进程中写入内容,而我们的子进程则通过标准输入读取父进程写入的信息。这里不仅仅是为了让salver这个函数不需要参数,也是为了弱化在子进程这里的管道的概念。
那么这里我们的子进程就直接从标准输入中读取即可。那么读取什么呢?怎么读呢?
这里我们就做一层规定:我们规定我们的父进程每次只会往管道中写入固定的四字节的内容(你也可以设置为1字节/2字节或者是更多的),因为管道是面向字节流的可能会发生我们的父进程写了好几字节的数据,而我们的子进程一次性全部读取进来了,这里我们读入四个字节一个整型作为一个任务码。
最后我们来完成我们的slaver函数
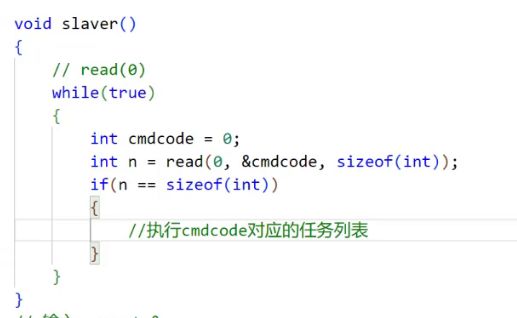
在这里我们再打印观看一下每一个对应的子进程得到的自己对应的任务码。

这里如果我们的父进程不给对应的子进程发送信息那么这个信息就在read函数这里进行阻塞等待。

到这里我们就已经完成了对子进程的创建以及对于每一个子进程的初步的工作。
下面我们就需要父进程去选择任务然后去进行发布了。
即我们的父进程要去控制我们的子进程了。
首先这里假设我们的父进程需要发送100个任务。那么我们就写一个循环代表父进程会发送100次任务。
而我们这里要完成对应的控制子进程的任务,要完成的就是下面的任务。

然后因为我们这里的每一个任务都是以任务码作为标记的。所以这里我们就直接搞一个随机数作为任务码即可。到这里我们就完成了选择任务的工作。

这里我们设定的是我们的任务编号是从0到19的。
需要注意在使用rand函数之间我们是种了一个随机数种子的。
srand()用于栽种随机数种子。
![]()
这个函数中间的^只是为了让数字更为接近随机而已。
到这里完成了对任务的选择,下面就是要选择进程。
那么如何选择一个进程呢?
因为所有的进程都在我们的channels中管理,所以这里的选择一个进程其实说白了就是选择一个channels中的下标而已。
但是我们选择下标依旧是存在两个方法,因为我们不能只选择一个进程就只让这一个进程去执行,那样的话其余的进程就会长期处于闲的状态。所以我们需要将我们选择的任务较为均衡的分配给所有的子进程。
而这样的处理也就是负载均衡。也就是让我们的子进程都能享有到一定的任务。
而这里我们选择进程依旧是具有两个方法第一个方法:随机数

第二个方法:轮询
第二种方法会在后面写。
那么现在已经选择了任何和进程了,下面就是需要发送我们的信息了。

下面我们就来打印一些信息检测一下我们的这个过程是否出现错误

在发送这个任务之前我们让我们对应的父进程打印一些信息,然后我们再让我们对应的子进程打印打印信息。
下面是运行截图:

此时的这里就是父进程发送了一个任务码给子进程而子进程最后接收到了这个任务码。
那么到这里还存在最后一个问题就是子进程虽然已经能够被父进程唤醒了,但是现在的问题是我的子进程没有能够做的任务,即我们需要设计一批任务来让我们的子进程去执行,关于任务我们就在Task.hpp中写了。
下面我们就来写一些简单的任务。
使用函数指针制作一些简单的任务
这里我们使用的方法是使用function包装器和lambada表达式。

然后我们在我们的主函数中创建一个全局的vector

然后我们的main函数选择任务码的时候模取得也就是这个vector的size了
最后当我们的子进程拿到对应的任务码之后,再去执行这个任务。当然为了防止子进程拿到错误的任务码,我们还是可以再进行一层判断。

最后为了防止出现我的父进程先退出了,而子进程没有退出(我这里的子进程是一个死循环)的情况。我最后让父进程休眠一段时间。
然后就是运行截图:

那么到这里我们的父进程就可以控制子进程去完成对应的任务了。
此时父进程只需要写任务码即可,而我们的子进程则根据对应的任务码去执行对应的任务。如果子进程暂时无法运行也没有关系,父进程是写在管道中的,什么时候子进程能够运行了再从管道中读取即可。那么这个管道就相当于一个队列了,而我们的父子进程也就构建了一个基于管道的队列了。
到这里我们就完成了对子进程的控制,下面我们再将这一个控制的代码再封装成一个单独的函数。
在封装的同时将选择子进程的轮询代码也写到这里

收尾工作
最后我们肯定要对父进程和子进程进行收尾工作


再运行简单测试一下:为了测试我将ctrl处父进程的死循环设置成了运行一段时间自动退出。

没有问题。
到这里我们也已经能够正常的完成我们的退出功能了。
现在我们已经有了对应的任务,如果我们在完成一个简单的界面
然后让用户来选择对应的任务。
代码:
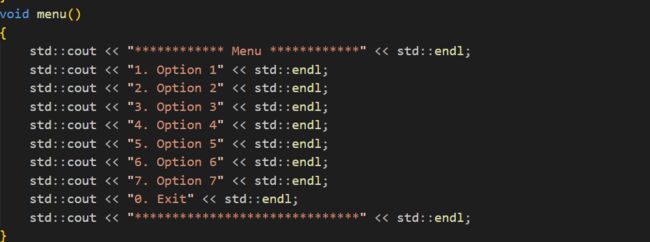


运行截图:

到这里就基本完成了但是这个代码在初始化那里是存在bug的。
代码的bug
那么这个简单进程池的代码在哪里呢?我们先改一下我们的最后收尾阶段的代码,为什么我们的进程池在回收的时候,是将父进程控制的每一个子进程先都关闭了,再让父进程去等待每一个子进程结束呢?

为什么不能是父进程关闭一个子进程之后,就直接wait这个子进程将这个子进程处理完毕呢?
我们来尝试一下:

运行截图:

可以看到其它的功能没有出现问题,但是当我们输入0退出的时候,发现父进程直接在这里卡死了,这是为什么呢?我们画一张图就能够理解了。

也就是后面创建的子进程都会保留有上面管道的写端,也就是上面的管道除了父进程会指向之外,后面以父进程为模板创建的子进程也会指向前面创建的管道的写端。
那么为什么我们之前写的那个代码能够运行呢?即先将父进程所有的写端关闭,然后再循环等待的代码是没有问题的呢?因为父进程创建的子进程一定会存在最后一个管道这个管道的写端,只由父进程指向,父进程关闭写段之后,这最后一个管道指向的子进程就会自动退出,然后由下向上所有的子进程都会进入到退出环节。
所以我们的代码如果你是从最后一个子进程开始往前一边关闭管道写端,一边将子进程回收,就不会出现问题。

运行截图:

可以看到正常的退出了。
但是这个代码并没有解决问题。
我们的问题是:后面创建的子进程会指向前面建立的管道的写端,我这里的解决方法就是,每一次都让新创建的子进程关闭掉这些写端就是了。
代码如下:

这里的思路就是在初始化的这个模块中,创建一个vector数组oldfd,这个数组,会储存父进程开启的所有的写端接口,然后对应的子进程每一次都关闭这个写端接口。
现在我们再将我们的最后收尾的代码修改为:

最后是运行截图:

很明显我这里显示出现了一些bug,但是影响不算大。到这里最大的bug就已经被解决了。
这篇博客也就到这里结束了。
完整代码:
#include"Task.hpp"
#include
#include
#include
#include
#include
#include
#include
#include
const int processnum = 5;//我们默认的创建的子进程的个数
std::vector> task; // 声明一个全局的task对象,让父子进程都能够看到这个任务列表
//首先就是将对应的管道描述起来
class channel
{
public:
channel(int cmdfd,pid_t slaverid,std::string& slavername)
:_cmdfd(cmdfd),_slaverid(slaverid),_slavername(slavername)
{}//创建对应的构造函数用于创建对应的channel对象
int _cmdfd; // 发送任务的文件描述符号,即我们的父进程往什么地方发送对应的指令,能够让我们的子进程得到对应的命令
pid_t _slaverid; // 需要发送给哪一个子进程
std::string _slavername; // 子进程的名字 -- 方便我们打印日志
};//到这里我们就将一个管道描述完成了,下面就是要将创建的管道的对象管理起来
//管理
void worker()
{
while(true)
{
int cmdcode = 0;
// 在完成了重定向之后我们的子进程只需要从标准输入中读取对应的信息即可
//这里我们在规定每一个父进程只会写四个字节的内容,而我们的子进程也就直接读取四个字节的内容即可。
int n = read(0,&cmdcode,sizeof(int));
if(n == sizeof(int))//如果这里没有读到四个字节的内容那么就继续去读
{
if(cmdcode>=0&&cmdcode* channels)
{
std::vector oldfd;//创建一个储存之前创建的写端的vector
for(int i = 0;ipush_back(channel(pipefd[1],id,name));
}
}
void quict(std::vector& channels)
{
for(int i = 0;i& channels)
//因为这里只是单纯需要一个简单的输入即可,所以使用的是const &
{
for(const auto& e:channels)
{
std::cout<& channels)
{
//以下选择进程的方式是以随机数的方式选择的我们也可以使用轮询的方式
/*
while(true){
//选择任务
int cmdcode = rand()%task.size();//现在我们已经存在了任务,选择任务就直接从stl从选取下标即可
//选择进程
//第一种方法:随机数
int peocessfd = rand()%channels.size();//模上vector的大小防止出现选择不存在的进程
//第二种方法轮询:
//发送任务
std::cout<<"father say:"<<" cmdcode: "<>cmdcode;//让用户来选择任务
if(cmdcode == 0)
{
break;//代表用户选择了退出
}
if(cmdcode<0||cmdcode>=task.size())
{
std::cout<<"error enter"< channels;//使用一个stl容器就能将这些管道管理起来,此时管理这些管道就变成了对这个vector的管理
// 1.初始化
//如何做初始化呢?也就是根据你要创建的子进程的个数创建对应的子进程同时为每一个子进程创建属于自己的管道即可
Initchannelse(&channels);//将我们的channelse数组传递过去就能够完成创建子进程和管道的工作。//存在bug
//Debug(channels);
//sleep(1000);//为了不让父进程退出让我们的监控脚本能够看到我们对应的这些创建出来的进程。
//2.控制子进程
ctrlworker(channels);//将对应的控制子进程的任务封装成为一个函数
//这里假设我们的父进程会发布100次任务
//3.清理收尾
quict(channels);
return 0;
}
#pragma once
#include
#include
#include
void LoadingTask(std::vector> *tasks)
{
// 添加任务函数示例
std::function task1 = []() {
std::cout<<"任务1逻辑"< task2 = []() {
std::cout<<"任务2逻辑"< task3 = [](){
std::cout<<"任务3逻辑"< task4 = []() {
std::cout<<"任务4逻辑"< task5 = []() {
std::cout<<"任务5逻辑"< task6 = []() {
std::cout<<"任务6逻辑"< task7 = []() {
std::cout<<"任务7逻辑"<push_back(task1);
tasks->push_back(task2);
tasks->push_back(task3);
tasks->push_back(task4);
tasks->push_back(task5);
tasks->push_back(task6);
tasks->push_back(task7);
} 希望这篇博客能对你有所帮助,写的不好请见谅,最后是完整的代码。如果发现了任何的错误欢迎在评论区指出。