Real-Time Scene Text Detection with Differentiable Binarization
转载-原文链接
zReal-Time Scene Text Detection with Differentiable Binarization
源码参考 https://github.com/WenmuZhou/DBNet.pytorch
论文收录于AAAI 2020,链接如下:
[1911.08947] Real-time Scene Text Detection with Differentiable Binarization (arxiv.org)arxiv.org/abs/1911.08947编辑
一、论文速读
1.1 解决的问题
二值化的后处理对于基于分割的检测是必不可少的,它将分割方法产生的概率图转换为文本的边界框/区域。大多数基于分割的方法需要复杂的后处理去将像素级预测结果分组到检测到的文本实例,导致推理过程的时间成本相当。大多数现有的检测方法使用类似的后处理管道:设置一个固定的阈值,将分割网络产生的概率图转换为二值图像;一些启发式技术,如像素聚类,用于将像素分组到文本实例中。在本文中,我们提出了一个名为可微二值化(DB)的模块,该模块可以在分割网络中执行二值化过程。与DB模块一起优化,分割网络可以自适应地设置二值化的阈值,这不仅简化了后处理,而且提高了文本检测的性能。
1.2 贡献
- 提出的可微DB模块,使得二值化的过程在CNN中端到端可训练。
- 比以前的领先方法快得多,因为 DB 可以提供高度稳健的二值化图,大大简化了后处理。速度快的同时还可以检测任意形状的文本实例。
- 当使用轻量级主干时,DB工作得很好,这显著提高了ResNet-18主干的检测性能。
- 由于DB可以在推理阶段删除而不牺牲性能,因此没有额外的内存/时间成本进行测试。
1.3 缺陷
不能处理“文本内部”的情况,这意味着文本实例在另一个文本实例内部。尽管缩小的文本区域有助于文本实例不在另一个文本实例的中心区域的情况,但当文本实例恰好位于另一个文本实例的中心区域时失败。这是基于分割的场景文本检测器的一个常见限制。
二、方法
将图像输入到特征金字塔主干中。其次,金字塔特征被上采样到相同的尺度并级联以产生特征F。然后,特征F用于预测概率图 (P) 和阈值图 (T)。之后,近似二值图(^B)由P和F计算。在训练过程中,对概率图、阈值图和近似二值图进行监督,其中概率图和近似二值图共享相同的监督。在推理阶段,边界框可以很容易地从近似二值图或通过框公式模块获得。

2.1 网络结构
对应图中三个红框:

2.1.1 Self.backbone
由resnet构成,加载了多个系列模型可任意选择。Resnet中有一个可选操作可变形卷积(如下图所示):可以为模型提供灵活的感受野,这对极端纵横比的文本实例特别有益。调制可变形卷积应用于ResNet-18或ResNet-50主干中的conv3、conv4和conv5阶段的所有3×3卷积层。
![]()

2.1.2 Self.neck
代码中对应FPN类(如下图):

Reduce_conv将resnet各层输出图片通道数变为256,upsample上采样到同等大小(P5大小),smooth进行一个尺度不变的卷积平滑。
2.1.3 self.head
2.1.3.1 用于输出probability map

其中有个转置卷积:
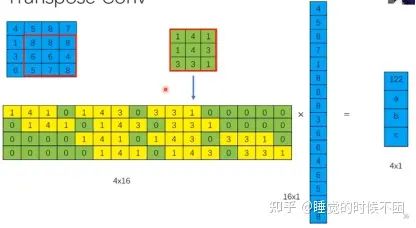
上图是普通卷积核写成矩阵乘法的形式,而转置卷积就是对这个形式进行转置,是的尺寸可以变回原尺寸(实际就等效于一个upsample,如下图所示)。转置过程中的卷积核的参数是需要学习的。

2.1.3.2 用于计算threshold map

2.1.3.3 可微分二值化
获得两张图片后进行可微分二值化并将结果连接输出:

![]()
step_function
标准二值化给定一个分割网络产生的概率图P∈RH×W,其中H和W表示地图的高度和宽度,必须将其转换为二值映射P∈RH×W,其中像素为值 1 被认为是有效的文本区域。通常,这种二值化过程可以描述如下:

(1)
可微二值化,使用近似阶跃函数执行二值化:
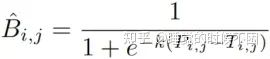
其中^B是近似二值图;T是从网络学习的自适应阈值图;k表示放大因子。k根据经验设置为50。这种近似二值化函数的行为类似于标准二值化函数(如下图),但是可微的,因此可以在训练阶段与分割网络一起进行优化。具有自适应阈值的可微二值化不仅可以帮助区分文本区域和背景,还可以分离紧密联合的文本实例。

效果举例:第二个是概率图与二值图的gt,第三个是阈值图gt。实际Tgt偏白的每个值都是不同的,都需要计算,但此处为了便于理解公式的作用效果假设偏白0.7,偏黑0.3,进行如上图所示的计算得二值图。实际得到的二值图与概率图是一样的,作用只是使之可微分并提高效果。

DB提高性能的原因:通过梯度的反向传播来解释。以二元交叉熵损失作为我们的DB函数为例:
![]()
正样本左边,负样本右边
设

其中x=Pi,j-Ti,j。那么正标签的损失l+和负标签的l−是:
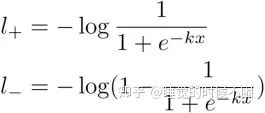
我们可以很容易地用链式法则计算损失的差异:

l+和l−的导数如图所示。我们可以从差异中看出(1)梯度由放大因子 k 增强; (2)对于大多数错误预测的区域,梯度的放大是显著的,从而促进优化并有助于产生更独特的预测。此外,当 x=Pi,j−Ti,j 时,P的梯度被T影响并重新缩放在前景和背景之间。

K=50时,当一个正样本被估计成负样本,则落在b的左边,是一个小于-10的数,带入loss很大,负样本误判同理。
2.2 标签生成
2.2.1 原理
概率图的标签生成受到PSENet的启发。给定一个文本图像,其文本区域的每个多边形由一组段描述:
![]()
n 是顶点数,在不同的数据集中可能不同(ICDAR 2015数据集为4,CTW1500数据集为 16)。然后使用Vatti裁剪算法将多边形G缩小到Gs来生成正区域。收缩的偏移量D是从原始多边形的外围L和面积A计算的:

其中r是收缩率,根据经验设置为0.4。

红色是原始的紧贴文字的区域,蓝色内部1外部0
具有相似的过程,我们可以为阈值图生成标签。首先,将文本多边形G扩展为与Gd相同的偏移量D。我们将Gs和Gd之间的差距视为文本区域的边界,其中阈值图的标签可以通过计算到G中最近段的距离来生成。

收缩扩张D是一样的。灰色中值的计算:计算该点到四条红色边的距离,最短的距离作为值,除以D进行归一化,变成绿、蓝线1,红线0,用1减去所有值得到最终标签图,中间值大,两边值小。实际的归一化不会到0-1,而是其之间的一个数,例如0.3-0.7

Threshold gt的内边所围的面积与probability白色面积相等。
2.2.2 代码实现
2.2.2.1 probability gt

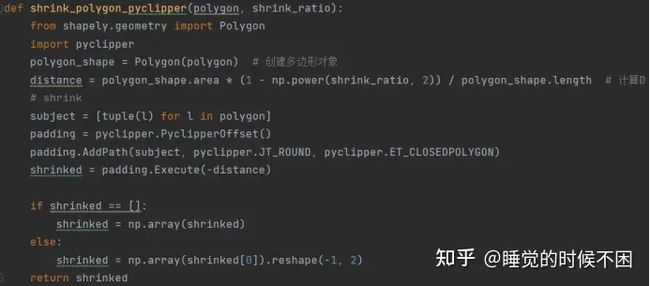

2.2.2.2 threshold gt

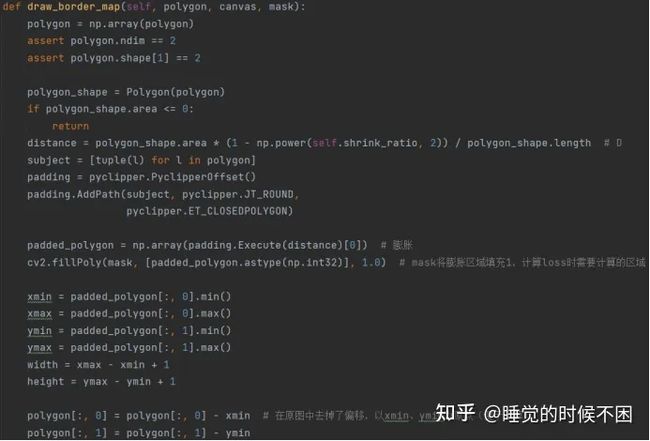


2.3 优化
损失函数L可以表示为概率图Ls的损失、二值图Lb的损失和阈值图Lt的损失的加权和:
![]()
其中Ls是概率图的损失,Lb是二值图的损失。根据损失的数值,α和β分别设置为 1.0 和 10。
我们对Ls和 Lb 应用二元交叉熵 (BCE) 损失。为了克服正负数的不平衡,通过对硬负数进行采样,在BCE损失中使用了hard negative mining。Sl是采样集,其中正负比例为1:3。


hard negative mining
Lt计算为扩张文本多边形Gd内预测标签和标签之间的L1距离之和:
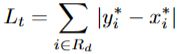
其中Rd是扩张多边形Gd内像素的一组索引(计算了扩张多边形内的所有像素);y*是阈值图的标签。
2.4 推理(后处理)
2.4.1 方法细节
我们可以使用概率图或近似二进制图来生成文本边界框,这会产生几乎相同的结果。为了提高效率,我们使用概率图,以便可以删除阈值分支(只需probability map,另两个删除)。盒子形成过程包括三个步骤:(1)概率图/近似二进制映射首先用常数阈值(0.2)进行二值化,得到二进制地图; (2)连接区域(shrunk文本区域)是从二进制地图中获得的;(3)缩小区域以偏移量D'和Vatti裁剪算法)进行扩张。D' 计算为
![]()
其中A'是收缩多边形的面积;L'是收缩多边形的周长;r'根据经验设置为1.5。
2.4.2 代码实现

后处理详情:SegDetectorRepresenter(),把网络输出的概率图得到最终的文字框

以输出多边形为例讲解,矩形框操作类似:

三、数据集
SynthText是合成数据集,由800k张图像组成,是从8k背景图像合成的。仅用于预训练模型。
MLT-2017是一个多语言数据集。它包括9种语言代表6个不同的脚本。该数据集中有7,200个训练图像、1800个验证图像和9,000个测试图像。我们在微调阶段同时使用训练集和验证集。
ICDAR 2015数据集由1000张训练图像和500张测试图像组成,这些图像由谷歌眼镜捕获,分辨率为720×1280。文本实例在单词级别进行标记。
MSRA-TD500数据集是一个多语言数据集,包括英文和中文。有300个训练图像和200个测试图像。文本实例在文本行级别进行标记。按照之前的方法,包括来自HUSTTR400的额外400个训练图像。
CTW1500是一个专注于弯曲文本的数据集。它由1000个训练图像和500个测试图像组成。文本实例在文本行级别进行注释。
Total-Text包含各种形状的文本,包括水平、多方向和弯曲。它们是1255个训练图像和300个测试图像。文本实例在单词级别进行标记。
四、实施细节
对于所有模型,我们首先使用SynthText数据集对它们进行100k次迭代的预训练。然后,我们在相应的真实世界数据集上微调模型1200个epoch。训练批次大小设置为16。我们遵循多学习率策略,其中当前迭代的学习率等于初始学习率乘以
![]()
其中初始学习率设置为0.007,功率设置为0.9。我们使用0.0001的权重衰减和0.9的动量。max_iter表示最大迭代次数,这取决于最大epoch。
训练数据的数据增强包括:(1)角度范围为(-1、1、10)的随机旋转;(2) 随机裁剪;(3) 随机翻转。所有处理后的图像都重新缩放为640×640,以获得更好的训练效率。
在推理阶段,我们通过为每个数据集设置合适的高度来保持测试图像的方面比并重新大小输入图像。推理速度以1的批大小进行测试,在单个线程中使用单个1080ti GPU。推理时间成本由模型前向时间成本和后处理时间成本组成。后处理时间成本约为推理时间的30%。
五、消融实验
可微二值化与转置卷积:
阈值图的监督:

六、结果比较

Total-Text数据集上的检测结果。括号中的值表示输入图像的高度。“*”表示在多个尺度上进行测试。“MTS”和“PSE”是Mask TextSpotter和PSEN的缩写
CTW1500的检测结果。带有“*”的方法是从(Liu et al. 2019a)收集的。括号中的值表示输入图像的高度。

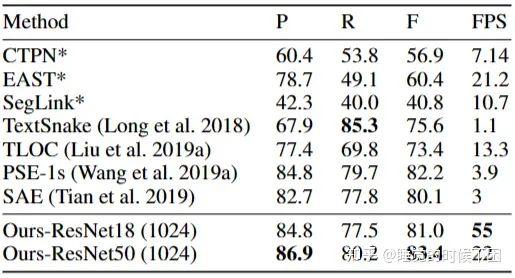
ICDAR 2015数据集上检测结果。括号中的值表示输入图像的高度。“TB”和“PSE”是TextBoxes++和PSENet的缩写。

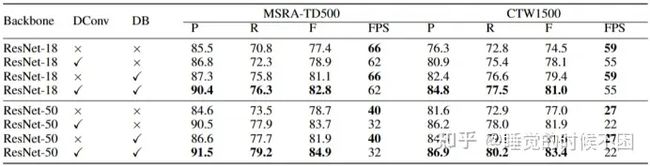
MSRA-TD500数据集上的检测结果。括号中的值表示输入图像的高度。

MLT-2017数据集上的检测结果。带有“*”的方法是从 (Lyu et al. 2018b) 收集的。在我们的方法中,MLT-2017 数据集中的图像被重新调整为768×1024。“PSE”是PSENet的缩写。
七、Rethink
- 本文总体通过网络提取概率图与阈值图,进行可微分二值化得到二值图,推理阶段通过后处理从概率图扩张得到矩形框。其中概率图与阈值图的gt由shrink生成。
- 从输出结果上看,召回率在多个数据集上的效果都不算太好,可能是标签生成中忽略太小的文字块导致的,可以对过小的文字块进行专门的处理,减小D?