JVM性能调优工具
JVM性能调优工具
1 什么是性能调优
性能调优就是对计算机硬件、操作系统和应用有相当深入的了解,调节三者之间的关系,实现整个系统(包括硬件、操作系统、应用)的性能最大化,并能不断的满足现有的业务需求。
1.1. 为什么需要性能调优
- 一是为了获得更好的系统性能(就是你现有的系统运行的还不错,但优化一下可以运行的更好)
- 二是通过性能调优来满足不断增加的业务需求
1.2 什么时候需要性能调优
1.2.1 上线前(基本优化)
一般我们在项目实施到项目上线这段时间,不但要准备硬件服务器、安装操作系统、环境搭建,还有个很重要的问题就是进行性能优化,包括操作系统优化和应用环境优化等,我称上线前的优化为基本优化也称为经验优化。
根据你做过的项目和你工作中的经验对上线前的服务器或架构进行基本的性能优化来满足业务需求。
1.2.2 上线后(持续优化)
再有就是项目上线后的优化,在上线前我们已经经过基本的性能优化,解决大部分的性能问题,但毕竟上线前的所以测试都是模拟测试并进行相关的性能优化,与上线后的真实环境还是有相当大的区别
我们首先要做的就是对上线后的项目进行性能监控包括服务器性能监控和服务性能监控。
1.3 性能优化的流程
在性能优化这个领域,并没有一个严格的流程定义,但是对于绝大多数的优化场景,我们可以将其过程抽象为下面四个步骤。
1.3.1 准备阶段
主要工作是是通过性能测试,了解应用的概况、瓶颈的大概方向,明确优化目标
准备阶段是非常关键的一步,不能省略,首先,需要对我们进行调优的对象进行详尽的了解,所谓知己知彼,百战不殆。
1.3.1.1 对性能问题进行粗略评估
过滤一些因为低级的业务逻辑导致的性能问题
譬如,线上应用日志级别不合理,可能会在大流量时导致 CPU 和磁盘的负载飙高,这种情况调整日志级别即可
1.3.1.2 了解应用的的总体架构
比如应用的外部依赖和核心接口有哪些,使用了哪些组件和框架,哪些接口、模块的使用率较高,上下游的数据链路是怎么样的等
1.3.1.3 了解应用对应的服务器信息
如服务器所在的集群信息、服务器的 CPU/内存信息、安装的 Linux 版本信息、服务器是容器还是虚拟机、所在宿主机混部后是否对当前应用有干扰等
1.3.2 分析阶段
通过各种工具或手段,初步定位性能瓶颈点
1.3.2.1 定位问题
如果定位到了问题基本上调优就已经完成了80%
在性能调优或者改bug的时候定位问题是最困难的,反而解决问题是比较简单的,有些问题比如OOM,线程死锁,执行速度慢,并不是很简单就能找到的问题的,可能改完代码后性能并没有提高多少,有时候性能反而不升反降,这些都是没有找准问题而导致的,我们需要通过各种性能分析工具来找到问题的根源。
1.3.2.2 评估分析
找到问题并不代表马上问题就可以解决了,还需要评估分析
评估问题修改后是否可以达到预期的效果,以及修改后可能造成的问题,如果评估后发现修改后并不会打到预期的效果,那么这个问题可以先搁置,优化别的地方,然后在分析是否有更好的解决方案,以及评估分析修改后可能造成的问题,不要因为优化一个地方导致十个地方有问题。
1.3.3 调优阶段
根据定位到的瓶颈点,进行应用性能调优
到了调优阶段就是将上面我们找到问题,并且将评审过后的方案实现出来,然后本地测试,并且通过工具监控压测等手段检查是否有所优化,如果没有达到预期,重新评估分析,然后进行调优测试,一直到本地达到了预期为止。
1.3.4 测试阶段
让调优过的应用进行性能测试
调优完成后也就是我们自己验证通过了,但是这个只是我们本地或者测试环境的结果,模拟生产环境进行模拟测试检查是否达到指标,然后还需要进行功能测试,检查是否因为改bug改出了什么问题,如果一切都通过了就可以考虑上线的事项了。
2 如何调优

小红旗部分重点关注
2.1 发现问题
建议先从应用层入手,分析图中标注的高频指标,抓出最重要的、最可疑的、最有可能导致性能的点
首先,虽然从系统、组件、应用两个三个角度去描述瓶颈点的分布,但在实际运行时,这三者往往是相辅相成、相互影响的。系统是为应用提供了运行时环境,性能问题的本质就是系统资源达到了使用的上限,反映在应用层,就是应用/组件的各项指标开始下降;而应用/组件的不合理使用和设计,也会加速系统资源的耗尽。因此,分析瓶颈点时,需要我们结合从不同角度分析出的结果,抽出共性,得到最终的结论.
得到初步的结论后,再去系统层进行验证。这样做的好处是:很多性能瓶颈点体现在系统层,会是多变量呈现的,譬如,应用层的垃圾回收(GC)指标出现了异常,通过 JDK 自带的工具很容易观测到,但是体现在系统层上,会发现系统当前的 CPU 利用率、内存指标都不太正常,这就给我们的分析思路带来了困扰。
2.2 善用调优工具
如果瓶颈点在应用层和系统层均呈现出多变量分布,建议此时使用 ZProfiler、JProfiler 等工具对应用进行 Profiling,获取应用的综合性能信息(注:Profiling 指的是在应用运行时,通过事件(Event-based)、统计抽样(Sampling Statistical)或植入附加指令(Byte-Code instrumentation)等方法,收集应用运行时的信息,来研究应用行为的动态分析方法),譬如,可以对 CPU 进行抽样统计,结合各种符号表信息,得到一段时间内应用内的代码热点。
2.3 看懂监控指标
2.3.1 准备工作
将我们资料中的项目打包到服务器中进行运行
启动服务
nohup java -jar spring-boot-test-1.0-SNAPSHOT.jar &
2.3.2 CPU指标
和 CPU 相关的指标主要有以下几个,常用的工具有 top、 ps、uptime、 vmstat、 pidstat等
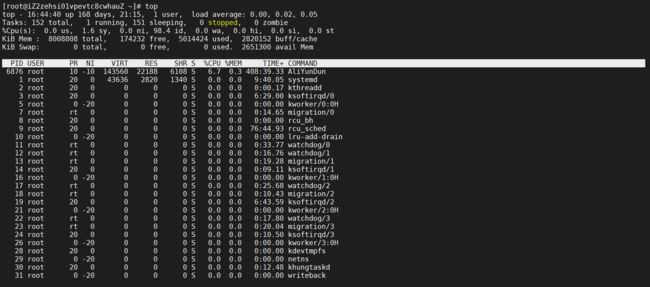
2.3.2.1 CPU指标含义
- 第一行:当前时间、系统启动时间、当前系统登录用户数目、平均负载(1分钟,10分钟,15分钟),平均负载(load average),一般对于单个cpu来说,负载在0~1.00之间是正常的,超过1.00须引起注意,在cpu中,系统平均负载不应该高于cpu核心的总数
- 第二行: 进程总数、运行进程数、休眠进程数、终止进程数、僵死进程数
- 第三行: CPU指标
- %us用户空间占用cpu百分比;
- %sy内核空间占用cpu百分比;
- %ni用户进程空间内改变过优先级的进程占用cpu百分比;
- %id空闲cpu百分比,反映一个系统cpu的闲忙程度。越大越空闲;
- %wa等待输入输出(I/O)的cpu百分比;
- %hi指的是cpu处理硬件中断的时间;
- %si值的是cpu处理软件中断的时间;
- %st用于有虚拟cpu的情况,用来指示被虚拟机偷掉的cpu时间。
- 第五行:total总的交换空间大小;used已经使用交换空间大小;free空间交换空间大小;cached缓冲的交换空间大小
- 第六行:进程显示区
- PID 进程号
- USER 运行用户
- PR:优先级,PR(Priority)所代表的值有什么含义?它其实就是进程调度器分配给进程的时间片长度,单位是时钟个数,那么一个时钟需要多长时间呢?这跟CPU的主频以及操作系统平台有关,比如linux上一般为10ms,那么PR值为15则表示这个进程的时间片为150ms。
- NI:任务nice值
- VIRT: 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
- RES: 物理内存用量
- SHR: 共享内存用量
- S :该进程的状态,其中S代表休眠状态;D代表不可中断的休眠状态;R代表运行状态;Z代表僵死状态;T代表停止或跟踪状态
- %CPU:该进程自最近一次刷新以来所占用的CPU时间和总时间的百分比
- %MEM:该进程占用的物理内存占总内存的百分比
- TIME+ :累计cpu占用时间
- COMMAND:该进程的命令名称,如果一行显示不下,则会进行截取,内存中的进程会有一个完整的命令行
2.3.2.2 查看线程
可以通过
top -Hp pid来查看哪一个进程里面的线程导致CPU很高的
top -Hp pid

2.3.3 虚拟内存
vmstat是Virtual Memory Statistics(虚拟内存统计)的缩写
利用vmstat命令可以对操作系统的内存信息、进程状态和CPU活动等进行监视,但是只能对系统的整体情况进行统计,无法对某个进程进行深入分析。
他是对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析,因为 vmstat 本身就是低开销工具,在非常高负荷的服务器上,你需要查看并监控系统的健康情况,在控制窗口还是能够使用vmstat 输出结果。
2.3.2.1 物理内存和虚拟内存区别
我们知道,直接从物理内存读写数据要比从硬盘读写数据要快的多,因此,我们希望所有数据的读取和写入都在内存完成,而内存是有限的,这样就引出了物理内存与虚拟内存的概念。
物理内存就是系统硬件提供的内存大小,是真正的内存,相对于物理内存,在linux下还有一个虚拟内存的概念,虚拟内存就是为了满足物理内存的不足而提出的策略,它是利用磁盘空间虚拟出的一块逻辑内存,用作虚拟内存的磁盘空间被称为交换空间(Swap Space)。
如果大量使用虚拟内存的话服务器性能会下降的很厉害
2.3.3.2 使用示例
vmstat 5 6

2.3.3.3 字段说明
Procs(进程):
r: 运行队列中进程数量
b: 等待IO的进程数量
Memory(内存):
swpd: 使用虚拟内存大小
free: 可用内存大小
buff: 用作缓冲的内存大小
cache: 用作缓存的内存大小
Swap:
si: 每秒从交换区写到内存的大小
so: 每秒写入交换区的内存大小
IO:(现在的Linux版本块的大小为1024bytes)
bi: 每秒读取的块数
bo: 每秒写入的块数
System(系统):
in: 每秒中断数,包括时钟中断。
cs: 每秒上下文切换数。
CPU(以百分比表示):
us: 用户进程执行时间(user time)
sy: 系统进程执行时间(system time)
id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。
wa: 等待IO时间
3 调优工具
3.1 JVM调优工具
运用jvm自带的命令可以方便的在生产监控和打印堆栈的日志信息帮忙我们来定位问题
虽然jvm调优成熟的工具已经有很多:jconsole、大名鼎鼎的VisualVM,IBM的Memory Analyzer等等,但是在生产环境出现问题的时候,一方面工具的使用会有所限制,另一方面喜欢装X的我们,总喜欢在出现问题的时候在终端输入一些命令来解决。所有的工具几乎都是依赖于jdk的接口和底层的这些命令,研究这些命令的使用也让我们更能了解jvm构成和特性。
3.1.1 jps
JVM Process Status Tool,显示指定系统内所有的HotSpot虚拟机进程。
3.1.1.1 参数
- -l : 输出主类全名或jar路径
- -q : 只输出LVMID
- -m : 输出JVM启动时传递给main()的参数
- -v : 输出JVM启动时显示指定的JVM参数
3.1.2 jstat
jstat(JVM statistics Monitoring)是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。
3.1.2.1 参数
- [option] : 操作参数
- LVMID : 本地虚拟机进程ID
- [interval] : 连续输出的时间间隔
- [count] : 连续输出的次数
3.1.2.2 垃圾回收统计
jstat -gc pid [interval] [count]
可以显示gc的信息,查看gc的次数,及时间,下面是显示列的具体描述
| 具体列名 | 具体描述 |
|---|---|
| S0C | 第一个幸存区的大小 |
| S1C | 第二个幸存区的大小 |
| S0U | 第一个幸存区的使用大小 |
| S1U | 第二个幸存区的使用大小 |
| EC | 伊甸园区的大小 |
| EU | 伊甸园区的使用大小 |
| OC | 老年代大小 |
| OU | 老年代使用大小 |
| MC | 方法区大小 |
| MU | 方法区使用大小 |
| CCSC:压缩类空间大小 | |
| CCSU:压缩类空间使用大小 | |
| YGC | 年轻代垃圾回收次数 |
| YGCT | 年轻代垃圾回收消耗时间 |
| FGC | 老年代垃圾回收次数 |
| FGCT | 老年代垃圾回收消耗时间 |
| GCT | 垃圾回收消耗总时间 |
3.1.2.3 老年代垃圾回收统计
jstat -gcold pid [interval] [count]
可以查看老年代的垃圾回收统计,具体列描述如下
| 具体列名 | 具体描述 |
|---|---|
| MC | 方法区大小 |
| MU | 方法区使用大小 |
| CCSC | 压缩类空间大小 |
| CCSU | 压缩类空间使用大小 |
| OC | 老年代大小 |
| OU | 老年代使用大小 |
| YGC | 年轻代垃圾回收次数 |
| FGC | 老年代垃圾回收次数 |
| GCT | 垃圾回收消耗总时间 |
整体垃圾回收情况
jstat -gcutil pid [interval] [count]
可以查看整体垃圾回收的情况
| 具体列名 | 具体描述 |
|---|---|
| S0 | 第一个幸存区的使用大小 |
| S1 | 第二个幸存区的使用大小 |
| EU | 伊甸园区的使用大小 |
| OU | 老年代使用大小 |
| MU | 方法区使用大小 |
| CCSU | 压缩类空间使用大小 |
| YGC | 年轻代垃圾回收次数 |
| YGCT | 年轻代垃圾回收消耗时间 |
| FGC | 老年代垃圾回收次数 |
| FGCT | 老年代垃圾回收消耗时间 |
| GCT | 垃圾回收消耗总时间 |
3.1.3 jmap
jmap(JVM Memory Map)命令用于生成heap dump文件,如果不使用这个命令,还可以使用
-XX:+HeapDumpOnOutOfMemoryError参数来让虚拟机出现OOM的时候·自动生成dump文件。
jmap不仅能生成dump文件,还可以查询finalize执行队列、Java堆和永久代的详细信息,如当前使用率、当前使用的是哪种收集器等。
3.1.3.1 参数
- dump : 生成堆转储快照
- finalizerinfo : 显示在F-Queue队列等待Finalizer线程执行finalizer方法的对象
- heap : 显示Java堆详细信息
- histo : 显示堆中对象的统计信息
- permstat : to print permanent generation statistics
- F : 当-dump没有响应时,强制生成dump快照
3.1.3.2 查看进程的内存映像信息
使用不带选项参数的jmap打印共享对象映射,将会打印目标虚拟机中加载的每个共享对象的起始地址、映射大小以及共享对象文件的路径全称
jmap pid
3.1.3.3 查看堆信息
打印一个堆的摘要信息,包括使用的GC算法、堆配置信息和各内存区域内存使用信息
jmap -heap pid

3.1.3.4 显示堆中对象的统计信息
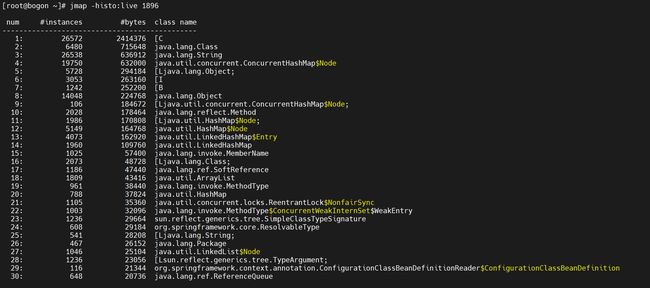
3.1.3.5 显示类加载器
打印Java堆内存的永久保存区域的类加载器的智能统计信息.
jmap -clstats pid
注意打印信息的时候服务会暂停,一般要谨慎使用

3.1.3.6 生成堆转储快照
以hprof二进制格式转储Java堆到指定filename的文件中
jmap -dump:format=b,file=heapdump.phrof pid
3.1.4 jstack
jstack用于生成java虚拟机当前时刻的线程快照,参考博客:https://juejin.cn/post/6844904152850497543
线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。
线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源。 如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。另外,jstack工具还可以附属到正在运行的java程序中,看到当时运行的java程序的java stack和native stack的信息, 如果现在运行的java程序呈现hung的状态,jstack是非常有用的。
3.1.4.1 参数
- -F : 当正常输出请求不被响应时,强制输出线程堆栈
- -l : 除堆栈外,显示关于锁的附加信息
- -m : 如果调用到本地方法的话,可以显示C/C++的堆栈
3.1.4.2 使用实例
我们可以使用以下的方式是使用
jstack
jstack pid

3.2 JConsole
Jconsole (Java Monitoring and Management Console),一种基于JMX的可视化监视、管理工具。
JConsole 基本包括以下基本功能:概述、内存、线程、类、VM概要、MBean

3.3 VisualVM
VisualVM(All-in-One Java Troubleshooting Tool);功能最强大的运行监视和故障处理程序
3.3.1 功能描述
- 显示虚拟机进程以及进程的配置、环境信息(jps、jinfo)。
- 监视应用程序的CPU、GC、堆、方法区(1.7及以前),元空间(JDK1.8及以后)以及线程的信息(jstat、jstack)。
- dump以及分析堆转储快照(jmap、jhat)。
- 方法级的程序运行性能分析,找出被调用最多、运行时间最长的方法。
- 离线程序快照:收集程序的运行时配置、线程dump、内存dump等信息建立一个快照
3.4 jprofiler
JProfiler 是一个商业授权的 Java 剖析工具,用于分析Java EE和Java SE应用程序。
3.4.1 特点
- 使用方便
- 界面操作友好
- 对被分析的应用影响小
- CPU,Thread,Memory分析功能尤其强大
- 支持对jdbc,noSql, jsp, servlet, socket等进行分析
- 支持多种模式(离线,在线)的分析
- 跨平台
3.5 Arthas
Arthas 是Alibaba开源的Java诊断工具,采用命令行交互模式,提供了丰富的功能,是排查jvm相关问题的利器
3.5.1 特点
- 提供性能看板,包括线程、cpu、内存等信息,并且会定时的刷新。
- 根据各种条件查看线程快照。比如找出cpu占用率最高的n个线程等
- 输出jvm的各种信息,如gc算法、jdk版本、ClassPath等
- 查看/设置sysprop和sysenv
- 查看某个类的静态属性,也可以通过ognl语法执行一些语句
- 查看已加载的类的详细信息,比如这个类从哪个jar包加载的。也可以查看类的方法的信息
- dump某个类的字节码到指定目录
- 直接反编译指定的类
- 查看类加载器的一些信息
- 可以让jvm重新加载某个类
- 监控方法的执行,同时可以获取到执行的入参、出参以及抛出的异常
- 追踪方法执行的调用栈,以及各个方法的调用时间
4. 调优案例
4.1 排查消耗CPU的方法
这个也是经常面试的一个面试题,如何排查CPU超高的JAVA线程,这里我们分为开发环境以及生产环境来说
4.1.1 使用Jprofiler工具
在开发环境可以通过Jprofiler进行快速排查CPU过高的代码
4.1.1.1 打开Jprofiler工具
打开Jprofile并选择需要织入的应用服务

接着选择确认就可以看到如下界面,这样就可以监控我们的应用程序

4.1.1.2 监视CPU视图
默认情况下CPU视图是关闭的,我们需要打开才可以,点击录制开始开启CPU录制
接着就会看到如下信息
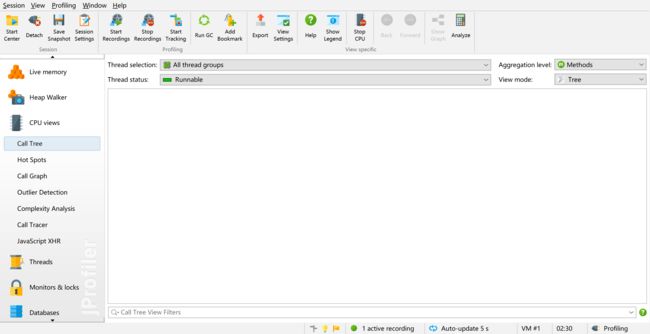
4.1.1.3 访问测试
我们需要调用接口来触发服务调用来检测性能问题

触发后我们找到了一个非常消耗系统资源的代码,我们到具体代码检查下,并且进行修复
private static final ArrayBlockingQueue<Message> queue = new ArrayBlockingQueue<>(100000);
/**
* CPU超高问题的代码
*/
public HandlerTaskCpuTooHigh() {
getExecutorService().execute(() -> {
while (true) {
handler();
}
});
}
@Override
public void execute(Message message) {
queue.offer(message);
}
public static void handler() {
Message task = queue.poll();
if (null != task) {
System.out.println(task);
}
}
4.1.2 通过命令排查
有的时候在生产环境是无法使用Jprofiler等工具的,我们只能借助jdk提供的相关命令进行排查
4.1.2.1 使用Top命令
使用Top命令排查CPU消耗很高的进行
top

通过排查可以发现进程
95891占用的CPU资源很高
4.1.2.2 查找线程
查到进程消耗的CPU很高的情况下我们可以通过以下命令来定位到哪个线程消耗的CPU高
top -H -p pid
通过这个命令可以定位到当前的这个线程消耗CPU很高

到这里我们发现
95911线程占用的CPU很高
转换16进制
因为java中查看线程号使用的是16进制我们需要将linux中的线程号转换为java中能够使用的16进制
printf "%x" 95911
![]()
执行后获取到执行16进制的pid是
176a7
查看进行运行状态
使用
jstack 进程id|grep tid转换成16进制后的数字,查看该线程是否运行
![]()
可以看出该线程一会处于运行状态
4.1.2.3 排查代码
使用
jstack pid,查看该进程中线程的详细信息,因为默认jstack会显示当前进程下的所有线程堆栈信息,所有我们只需要显示我们运行的消费CPU最高的代码即可,使用如下命令就可以显示当前线程后面CPU消耗很高的线程的堆栈信息,找到代码就可以解决问题了
jstack 95891|grep 176a7 -A20

到这里我们基本上就定位到问题了,然后解决问题
4.1.3 Arthas排查
生产环境下通过上面命令排查毕竟是比较繁琐的,如果有条件用Arthas可以让我们排查起来更加方便
4.1.3.1 运行Arthas
java -jar arthas-boot.jar
选择加载第一个java进程

4.1.3.2 dashboard
使用
dashboard来查看全局的性能监控
dashboard
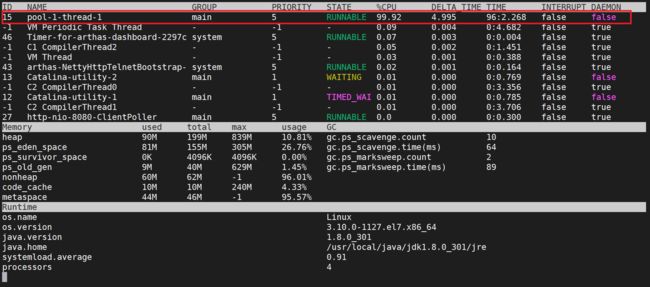
我们发现有一个线程占用CPU超高,,并且运行的时间也比较长,接下来我们用线程来看下
4.1.3.3 thread
我们发现在线程视图里面,这个线程也是占用的CPU负载是很高的
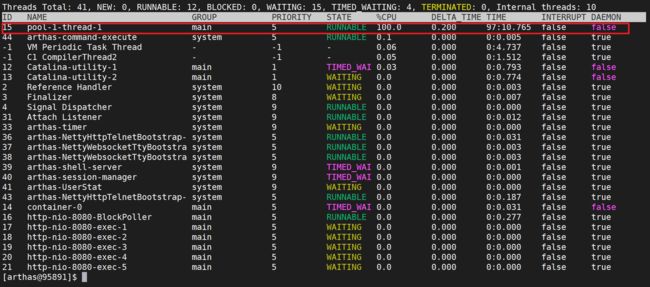
我们使用
thread pid的形式开查看具体线程内容
thread 15

我们就直接查找到了问题,接着我们来解决问题。
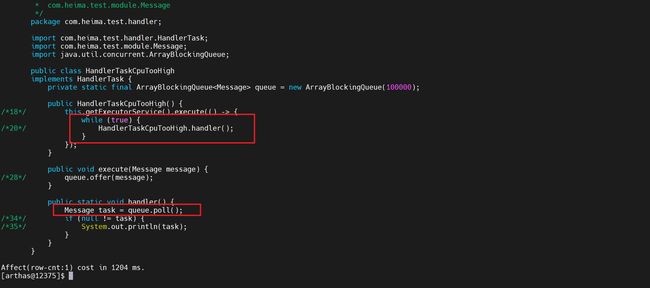
4.1.3.4 反编译代码
可以使用jad工具进行反编译,查看具体哪里有问题
jad com.heima.test.handler.HandlerTaskCpuTooHigh
通过反编译我们发现是因为阻塞队列没有使用阻塞获取方法导致不断的死循环导致系统CPU超高
导出当前的内内存中的类的原代码
jad --source-only com.heima.test.handler.HandlerTaskCpuTooHigh > /tmp/HandlerTaskCpuTooHigh.java
导出来原代码后供后面使用
4.1.3.5 跟踪方法调用
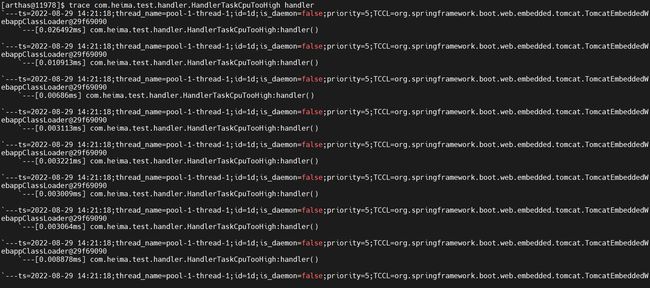
怀疑这个方法有问题,可以尝试用trace方法来进行调用一次
trace com.heima.test.handler.HandlerTaskCpuTooHigh handler
如果不清楚类的全路径,可以使用通配符*.HandlerTaskCpuTooHigh
我们发现速度特别快,可以确定就是这里的问题
4.1.3.6 修改原代码
修改刚刚解决的类的原代码
vi /tmp/HandlerTaskCpuTooHigh.java
修改原代码,解决我们发现的一个bug

4.1.3.7 查找类加载器
有的时候服务不能轻易的上线,我们可以只编译当前的类,然后替换内存中,实现快速上线
查找类加载器
我们需要用替换类的类加载器对于我们修改后的原代码进行编译
sc -d com.heima.test.handler.HandlerTaskCpuTooHigh | grep classLoaderHash
![]()
热编译
通过类加载器将我们的类进行编译
mc -c 31cefde0 /tmp/HandlerTaskCpuTooHigh.java -d /tmp
![]()
加载新类
编译后就可以在不重启的情况下加载新类,使用redefine命令重新加载新编译好的HandlerTask.class
redefine /tmp/com/heima/test/handler/HandlerTaskCpuTooHigh.class
![]()
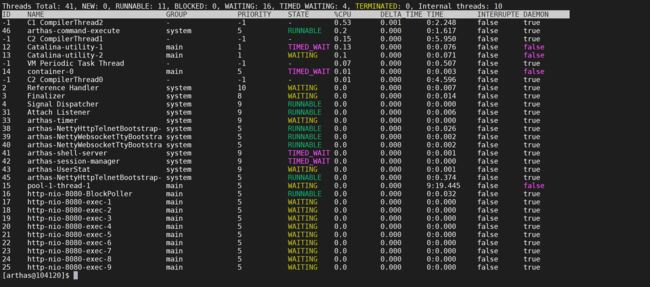
4.1.3.8 再次查看线程视图
thread
我们发现线程消耗的CPU已经下来了,做到了热更新代码,但是下次重启还是会出现问题,我们就需要马上修复了。
4.1.3.9 再次用跟踪方法
再次使用trace方法跟踪下方法执行
trace com.heima.test.handler.HandlerTaskCpuTooHigh handler

redefine的局限
- 不允许新增加 field/method
- 正在跑的函数,没有退出不能生效,比如while(true)方法内,上面代码
lmada表达式内的不会生效
4.2 排查内存泄漏
4.2.1 什么是内存泄漏
内存泄露是指:内存泄漏也称作"存储渗漏",用动态存储分配函数动态开辟的空间,在使用完毕后未释放,结果导致一直占据该内存单元,直到程序结束。(其实说白了就是该内存空间使用完毕之后未回收)即所谓内存泄漏。
也就是说内存刚开始不会出现什么问题,但是过一段时间就会频繁的进行GC,应用程序不会有什么响应,造成服务假死的情况
4.2.2 命令排查
4.2.2.1 检查FGC情况
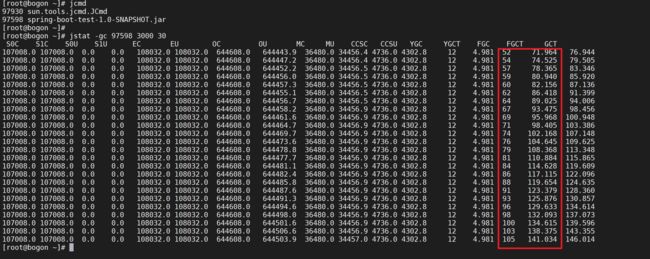
首先需要排查下FGC的情况,看看是否在频繁的进行FGC,可以使用jstat -gc pid 间隔时间 显示次数来查看GC情况
jcmd
jstat -gc 97598 3000 30
我们发现JVM在频繁的进行FGC并且FullGC的平均时间越来越长。
4.2.2.2 查看消耗CPU的线程
根据上面排查CPU的方法我们排查下哪个线程消耗的CPU比较多,一般是FGC的垃圾回收线程,对FGC做一个佐证
top

查看消耗CPU比较高的线程
top -H -p 97598

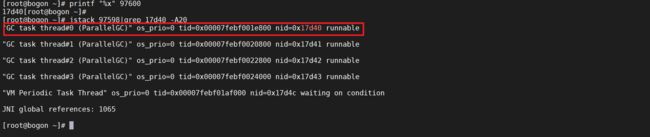
接下来将线程ID转换为对应的16进制进行排查
printf "%x" 97600
jstack 97598|grep 17d40 -A20
我们发现CPU很高的线程都是FGC线程,并且是ParallelGC,其他几个都可以排查下发现都是GC线程
4.2.3 查看内存对象
可以通过jmap导出dump转储文件,但是不推荐使用,导出的时候服务将会不响应请求,如果导出的文件很大,则可能造成服务长时间假死,可以使用jmap -histo pid来查看那些对象占用的内存大
# 列出来存活对象占用的内存大小,并且只显示前20行
jmap -histo:live 97598|head -20
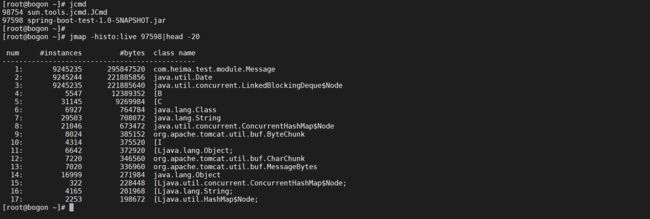
这个时候发现Message对象占用内存最大,这个时候就可以排查下调用Message对象的代码
4.3 死锁排查
死锁也是业务上可能会碰到的问题,如何排查死锁
4.3.1 jconsole排查死锁
4.3.1.1 打开jconsole控制台
在开发环境可以使用jconsole工具来排查死锁,可以在本地cmd命令行输入jsoncole命令打开图形界面
jconsole

双击对应的应用就可以进入管理页面,比较简介

4.3.1.2 检查死锁
排查死锁也比简单,点击对应的线程选项卡,选择检查死锁按钮就可以检查死锁了

点击检查死锁,然后根据显示的线程堆栈信息查看具体死锁位置就可以了

4.3.2 命令检查死锁
在生产环境下无法直接使用图形界面,我们可以使用命令行的方式来进行死锁检查
4.3.2.1 jstack 死锁检查
可以使用jstack快速进行死锁检查
jcmd
# 检查是否存在死锁
jstack -l 100460|grep "deadlock"
这样可以快速检查是否存在死锁问题

4.3.2.2 排查死锁
如果排查出现死锁问题后,接着就可以使用jstack导出堆栈信息,死锁信息就在最后
jstack -l 100460
拉到最后就可以看到死锁信息以及具体线程的堆栈信息,我们就可以针对性的找到具体代码位置

4.3.3 Arthas排查
生产环境下还可以通过Arthas来排查死锁
4.3.3.1 运行Arthas
java -jar arthas-boot.jar

4.3.3.2 排查死锁
可以使用thread -b命令来进行排查死锁
thread -b
这里面已经打印出来发现一个死锁,以及死锁阻塞的线程id
4.3.3.3 查看堆栈信息
从上面我们发现线程线程32在阻塞等待线程29,找到死锁的线程id后就可以查看具体堆栈信息了
thread 32
thread 29

找到死锁的堆栈信息接着就可以代码调优了
4.3.3.4 查看具体死锁代码
可以使用Arthas进行反编译进行查看死锁的代码
jad com.heima.test.handler.HandlerTaskDadLock
反编译后可以检查具体那个位置存在问题

4.4 内存溢出排查
4.4.1 什么是内存溢出
内存溢出是指程序员在申请内存时,没有足够的内存空间供其实用。
比如你申请了 2kb 的内存空间,但是给了一个需要4kb才能存下的数据,这就是内存溢出了,内存溢出就是, 你要求分配的内存超出了系统能够给你的内存,从而系统不能够满足需求,于是产生了溢出。
4.4.2 内存溢出分类
4.4.2.1 堆内存溢出
堆内存是存放由 new 创建的对象和数组,在堆中分配的内存,由 Java 虚拟机的自动垃圾回收器来管理
- 异常类型:java.lang.OutOfMemoryError: Java heap space
- 优化:通过-Xmn(最小值)–Xms(初始值) -Xmx(最大值)参数手动设置 Heap(堆)的大小
4.4.2.2 元空间溢出
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存
- 异常类型:Java.Lang.OutOfMemoryError:Metaspace
- 优化:通过调整
-XX:MaxMetaspaceSize设置元空间大小
4.4.2.3 栈溢出
栈内存在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配(更准确地说是保存了引用的堆内存空间的地址,java中的“指针”)
- 异常类型: java.lang.StackOverflowError
- 优化:通过Xss参数调整
4.4.3 调整JVM参数
一般一旦产生JVM内存溢出,服务也将会停止,这个时候需要生成内存转储文件,也需要打印一些JVM的GC参数来进行分析
#出现OOM则导出heapdump日志
-XX:+HeapDumpOnOutOfMemoryError
# 导出heapdump日志的路径
-XX:HeapDumpPath=d:/tmp/heapdump-%t.hprof
# 打印GC的详细信息
-XX:+PrintGCDetails
# 打印GC的时间戳
-XX:+PrintGCDateStamps
# 打印出幸存区中对象的年龄分布
-XX:+PrintTenuringDistribution
# 打印GC前后堆的概况
-XX:+PrintHeapAtGC
# 打印各种引用的处理时间
-XX:+PrintReferenceGC
#打印 stw 暂停时间,GC 最重要的指标
-XX:+PrintGCApplicationStoppedTime
# GC日志输出位置
-Xloggc:d:/tmp/jvm-%t.log
# 开启日志文件分割
-XX:+UseGCLogFileRotation
# 最多分割几个文件,超过之后从头开始写
-XX:NumberOfGCLogFiles=14
# 每个文件上限大小,超过就触发分割
-XX:GCLogFileSize=100M
4.5 堆内存
4.5.1 heap space
4.5.1.1 代码
private static final List<Message> list = new ArrayList<>();
@Override
public void execute(Message message) {
getExecutorService().execute(() -> {
while (true) {
list.add(MessageUtils.generate("xxxxxx"));
}
});
}
4.5.1.3 分析dump文件
通过分析因为OOM导出的dump文件,发现Message对象占用的空间最大,可以在系统中查看调用的位置
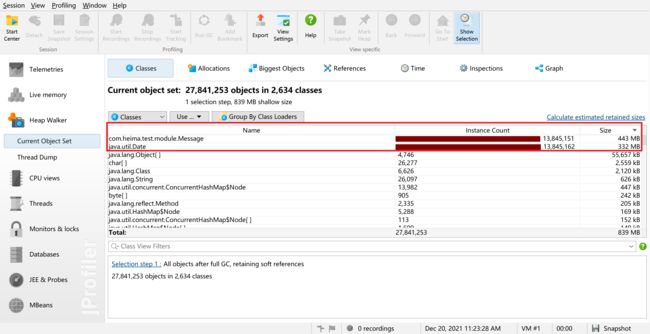
结合上问下可以看到是因为我们的message对象都扔进了list中,并且list是GC Root 所以不会被回收
4.5.2 GC overhead limit exceeded
当JVM资源利用出现问题时抛出,更具体地说,这个错误是由于JVM花费太长时间执行GC且只能回收很少的堆内存时抛出的。根据Oracle官方文档,默认情况下,如果Java进程花费98%以上的时间执行GC,并且每次只有不到2%的堆被恢复,则JVM抛出此错误。换句话说,这意味着我们的应用程序几乎耗尽了所有可用内存,垃圾收集器花了太长时间试图清理它,并多次失败。
在这种情况下,用户会体验到应用程序响应非常缓慢,通常只需要几毫秒就能完成的某些操作,此时则需要更长的时间来完成,这是因为所有的CPU正在进行垃圾收集,因此无法执行其他任务。
4.5.2.1 错误复现
这种情况下因为出现内存泄漏,无法进行回收老年代对象,GC一直处于工作状态就会出现GC overhead limit exceeded错误
/**
* 内存泄漏问题
*/
public class HandlerTaskMemoryLeak implements HandlerTask {
private static final BlockingDeque<Message> blockingDeque = new LinkedBlockingDeque<>();
@Override
public void execute(Message message) {
blockingDeque.offerFirst(message);
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
4.6 栈内存
4.6.1 StackOverFlowError
栈主要是被线程所使用的,存放着线程上下文的一些数据,这块空间相对堆来说是比较小的,对于栈是有可能出现溢出的,也就是我们熟知的StackOverFlowError,接下来用程序来模拟一下此异常,典型发生的场景就是使用不正确的递归
4.6.2 代码重现
private static final Logger logger = LoggerFactory.getLogger(HandlerTaskStackOverflow.class);
private static final AtomicLong depth = new AtomicLong();
@Override
public void execute(Message message) {
logger.info("入栈深度:{}", depth.incrementAndGet());
execute(message);
}
4.6.3 OutOfMemoryError
栈有时候也会出现OOM
很多人在做多线程开发时,当创建很多线程时,容易出现OOM(OutOfMemoryError),这时可以通过具体情况,减少最大堆容量,或者栈容量来解决问题,这是为什么呢。
下面是整个机器内存的分配情况
线程数*(最大栈容量)+最大堆值+其他内存(忽略不计或者一般不改动)<=机器最大内存
当线程数比较多时,且无法通过业务上削减线程数,那么再不换机器的情况下,你只能把最大栈容量设置小一点,或者把最大堆值设置小一点。
4.6.4 unable to create new native thread
(开发环境模拟不要用笔记本,不然死机只能重启,建议开虚拟机测试)
这也是常见的OOM类型,当应用程序无法创建新线程时会生成这种类型的异常
JVM 向操作系统申请创建新的 native thread(原生线程)时,就有可能会碰到 java.lang.OutOfMemoryError: Unable to create new native thread 错误,如果底层操作系统创建新的 native thread 失败,JVM 就会抛出相应的 OutOfMemoryError。
有以下原因会导致这个问题发生
4.6.4.1 没有可用的内存空间
内存中没有空间容纳新线程:分配的JVM内存太大,导致没有操作系统和JVM线程的映射对象无法申请
- 运行在 JVM 中的应用程序收到一个新的 Java 请求创建线程;
- JVM 系统会把创建新线程的请求转到操作系统;
- 操作系统尝试创建新线程,并为该线程分配内存;
- 如果已经超过操作系统的最大线程数限制,或者堆外内存不足,操作系统会拒绝创建线程,紧接着
java.lang.OutOfMemoryError: Unable to create new native thread error is thrown.。
可用通过增加内存或者减少JVM内存,提高堆外内存比例来解决
4.6.4.2 线程数超过操作系统限制
操作系统可以创建的线程数存在限制。
可以通过发出ulimit -u命令找到限制,在某些服务器上,这个值设置较低,例如 1024,这意味着在这台机器上总共只能创建 1024 个线程,因此,如果您的应用程序正在创建超过 1024 个线程,它将遇到java.lang.OutOfMemoryError: unable to create new native thread.在这种情况下,可以修改此限制。
![]()
4.6.4.3 错误复现
将大部分内存都设置JVM的内存,给操作系统留下较少的内存容易复现这种问题
/**
* 模拟堆内存溢出
*/
public class HandlerTaskStackOverflow implements HandlerTask {
private static final Logger logger = LoggerFactory.getLogger(HandlerTaskStackOverflow.class);
private static final AtomicLong depth = new AtomicLong();
@Override
public void execute(Message message) {
while (true) {
new Thread(() -> {
try {
Thread.sleep(Integer.MAX_VALUE);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
logger.info("创建第{}个新线程", depth.incrementAndGet());
}
}
}
4.6.4.4 监控内存变化
vmstat 5
前面随着创建线程不断消耗操作系统的内存

都后面突然增加是因为操作系统将JVM进程给杀死了

查看日志
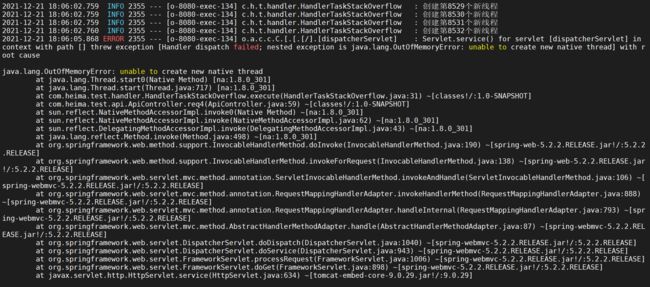
具体原因发现是因为无法分配内存

4.7 元空间
Jdk8以后开始把类的元数据放在本地堆内存中,这一块区域就叫做Metaspace,该区域在jdk7及以前是属于永久带的,元空间和永久代都是用来存储class相关信息,包括class对象的Method,Field等,元空间和永久代其实都是方法区的实现,只是实现有所不同,所以说方法区其实只是一种JVM的规范。
默认情况下,类元数据只受可用的本地内存限制(容量取决于是32位或是64位操作系统的可用虚拟内存大小
适时地监控和调整元空间对于减小垃圾回收频率和减少延时是很有必要的。持续的元空间垃圾回收说明,可能存在类、类加载器导致的内存泄漏或是大小设置不合适。
4.7.1 OutOfMemoryError
这个java.lang.OutOfMemoryError:Metaspace表示为Java类元数据分配的本机内存量已被耗尽
4.7.1.1 问题复现
一般来说,可以在命令行上设置MaxMetaSpaceSize,如果不设置则会随着class文件增多耗尽操作系统内存
-XX:MetaspaceSize=1024m
-XX:MaxMetaspaceSize=1024m
/**
* 模拟元空间溢出
*/
public class HandlerTaskMetaspaceOverflow extends ClassLoader implements HandlerTask {
private static final AtomicLong aLong = new AtomicLong();
@Override
public void execute(Message message) {
for (int i = 0; i < 20000; i++) {
aLong.incrementAndGet();
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(OomObject.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
return proxy.invoke(obj, args);
}
});
Object o=enhancer.create();
}
}
}
4.7.1.2 启动服务
nohup java -jar -XX:MetaspaceSize=100m -XX:MaxMetaspaceSize=100m spring-boot-test-1.0-SNAPSHOT.jar &
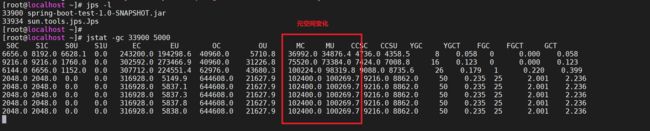
4.7.1.3 监控元空间变化
jstat -gc 33900 5000
4.7.1.4查看日志文件

5 arthas高级使用(扩展)
5.1 动态调整日志等级
线上环境一般都是打印INFO级别的日志信息,但是出现问题的时候为了打印debug信息一般需要重启服务,临时使用的话可以尝试通过arthas来调整日志等级
5.1.1 打印日志代码
默认是打印INFO级别的信息,这些信息是输出不出来的
public static void handler(Message task) {
logger.debug("输出消息{}", task.getMessage());
}
5.1.2 监控日志打印
tail -f nohup.out
发现没有日志输出
5.1.3 查找类
因为有时候不太清楚类的完全包名,可以通过sc进行查找
sc -d *.HandlerTaskNormal
这种方式可以打印类的详细信息

我们需要获取classLoaderHash 还可以使用以下命令
sc -d com.heima.test.handler.HandlerTaskNormal | grep classLoaderHash
![]()
5.1.4 查看日志级别
通过logger命令可以查看当前类的日志级别
logger -c 31cefde0

5.1.5 修改日志级别
通过logger是可以动态修改类的日志等级
logger -c 31cefde0 --name ROOT --level debug
![]()
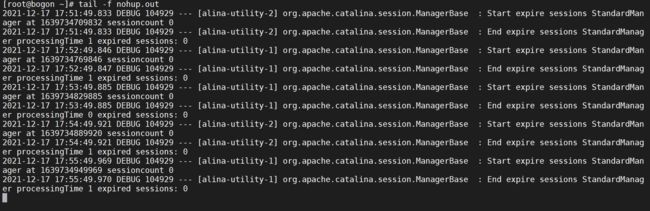
5.1.6 查看日志输出
tail -f nohup.out
5.2 动态打印参数
有的时候发现问题,有些地方正好没有打印日志,这个时候在修改再上线会很麻烦,并且容易引起其他地方的问题,这个时候可以考虑使用watch来打印参数
5.2.1 启动arthas
java -jar arthas-boot.jar
5.2.2 查找方法
我们知道我们的入口类是ApiController,我们先通过sc查找类,然后对于该类进行反编译,查看我们需要查询的方法
sc *ApiController
jad com.heima.test.api.ApiController
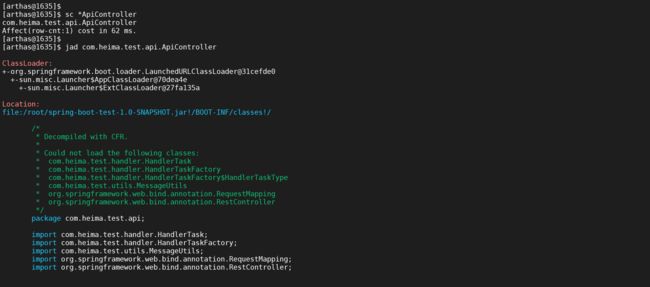
经过查看源码,我们发现我们需要查找的源码是req方法
5.2.3 监听req方法参数
我们可以通过监听req方法的如,查看具体输入输出参数
watch com.heima.test.api.ApiController req

我们发现参数有点多,我们可以通过以下参数只观察入参和出参
watch com.heima.test.api.ApiController req {params[0],returnObj}
但是呢这样打印的需要每一个参数都需要拦截,但是我们只需要拦截特定的参数可以通过以下方法来实现
watch com.heima.test.api.ApiController req {params[0],returnObj} 'params[0]=="XXYY"'
只有入参是XXYY才打印参数其他情况是不打印参数的

还有些情况下调用速度非常快,如果这样操作很容易刷屏,这种情况下可以考虑加入-n参数限制打印行数
watch com.heima.test.api.ApiController req {params[0],returnObj} 'params[0]=="XXYY"' -n 3
