数据结构与算法_链表
链表基本
初识链表
struct Node{
int data;
Node * next;
};
以上是链表最基本的结构:一个放数据的,一个存指针的。这里的指针仅仅是C/C++的一种叫法。实际上就是为了索引下一块的一个坐标。如果有的话就写坐标,没有的话就是NULL/nullptr。
初始化
Node * CreatLinkList(int * array, int len){
Node * pre, * head, * temp;//pre是保存当前结点的前驱
head = new Node;
head->next = NULL;
pre = head;
for(int i = 0; i < len; i++){
temp = new Node;
temp->data = array[i];
temp->next = NULL;
pre->next = temp;
pre = temp;
}
return head;
}
这个头结点可以装data,也可以空着不装。我之后的程序都会默认头结点是没有装数据的。
头插法
头插法:把后建立的结点插在头部。用这种方法建立起来的链表的实际顺序与输入顺序刚好向反,输出时为倒序
Node * HeadInsert()
{
Node * head;
head = new Node; // 为头指针开辟内存空间
Node * node = NULL; // 定义新结点
int count = 0; // 创建结点的个数
head->next = NULL;
node = head->next; // 将最后一个结点的指针域永远保持为NULL
printf("Input the node number: ");
scanf("%d", &count);
for (int i = 0; i < count; i++) {
node = new Node; // 为新结点开辟内存空间
node->data = i; // 为新结点的数据域赋值
node->next = head->next; // 将头指针所指向的下一个结点的地址,赋给新创建结点的next
head->next = node; // 将新创建的结点的地址赋给头指针的下一个结点
}
return head;
}
其实头插法也是链表初始化的一种方式;
node->next = head->next; // 将头指针所指向的下一个结点的地址,赋给新创建结点的next
head->next = node; // 将新创建的结点的地址赋给头指针的下一个结点
以上是头插法的核心语句。
创建第一个结点
执行第一次循环时,第一次从堆中开辟一块内存空间给node,此时需要做的是将第一个结点与 head 连接起来。而我们前面已经说过,单链表的最后一个结点指向的是 NULL。
因此插入第一个结点时,我们需要将头指针指向的 next 赋给新创建的结点的 next , 这样第一个插入的结点的 next 指向的就是 NULL。 接着,我们将数据域,也就是 node 的地址赋给 head->next, 这时 head->next 指向的就是新创建的 node的地址。而 node 指向的就是 NULL。
接着我们创建第二个结点
因为使用的头插法,因此新开辟的内存空间需要插入 头指针所指向的下一个地址,也就是新开辟的 node 需要插入 上一个 node 和 head 之间。 第一个结点创建之后,head->next 的地址是 第一个 node 的地址。 而我们申请到新的一块存储区域后,需要将 node->next 指向 上一个结点的首地址, 而新node 的地址则赋给 head->next。 因此也就是 node->next = head->next 。
这样便将第一个结点的地址赋给了新创建地址的 next 所指向的地址。后两个结点就连接起来。
接下来再将头结点的 next 所指向的地址赋为 新创建 node 的地址。 head->next = node ,这样就将头结点与新创建的结点连接了起来。 此时最后一个结点,也就是第一次创建的结点的数据域为0,指针域为 NULL。
(看到这里,我想之后的反转链表你已经有头绪了)
尾插法
Node * TailInsert {
Node * head, * end, * node;
head = new Node; // 为头指针开辟内存空间
node = end = NULL; // 初始化头结点指向的下一个地址为 NULL
end = head; // 未创建其余结点之前,只有一个头结点
int count = 0 ; // 结点个数
printf("Input node number: ");
scanf("%d", &count);
for (int i = 0; i < count; i++) {
node = new Node; // 为新结点开辟新内存
node->data = i; // 新结点的数据域赋值
end->next = node;
end = node;
}
end->next = NULL;
return head;
}
尾插法正好与头插法相反,是正向的输出!
end->next = node;
end = node;
以上尾插法的灵魂
其实你应该已经发现:链表的初始化的程序也是使用的尾插法。
尾插法创建第一个结点
刚开始为头结点开辟内存空间,因为此时除过头结点没有新的结点的建立,接着将头结点的指针域 head->next 的地址赋为 NULL。因此此时,整个链表只有一个头结点有效,因此 head此时既是头结点,又是尾结点。因此将头结点的地址赋给尾结点 end 因此:end = head。 此时end 就是 head, head 就是 end。 end->next 也自然指向的是 NULL。
尾插法创建第二个结点
创建完第一个结点之后,我们入手创建第二个结点。 第一个结点,end 和 head 共用一块内存空间。现在从堆中心开辟出一块内存给 node,将 node 的数据域赋值后,此时 end 中存储的地址是 head 的地址。此时,end->next 代表的是头结点的指针域,因此 end->next = node 代表的就是将上一个,也就是新开辟的 node 的地址赋给 head 的下一个结点地址。
此时,end->next 的地址是新创建的 node 的地址,而此时 end 的地址还是 head 的地址。 因此 end = node ,这条作用就是将新建的结点 node 的地址赋给尾结点 end。 此时 end 的地址不再是头结点,而是新建的结点 node。
一句话,相当于不断开创新的结点,然后不断将新的结点的地址当做尾结点。尾结点不断后移,而新创的结点时按照创建的先后顺序而连接的。先来新到。
尾插法创建单链表,结点创建完毕
最后,当结点创建完毕,最后不会有新的结点来替换 end ,因此最后需要加上一条 end->next = NULL。将尾指针的指向为 NULL。
简单的总结
头插法:插入和输出的相反的,原因是你第一次插进去的数据实际上成为了链表的尾巴。
尾插法:就是大家心中默认的插入方法。插入和输出是一致的。
插入
插入是链表老生常谈的操作了
s->next = p->next;
p->next = s;
其中,s是新结点。
前插
以上操作是插入到目标结点的后面,如何插入前面呢?
s->next = p->next;
p->next = s;
temp = p->data;
p->data = s->data;
s->data = temp
插入完交换顺序就行了,别太死板了。
删除
按值删除
bool DeleteValue(Node * const head,int data){//head表里删除值为data的元素(把第一次出现的删了就行)
if(head->next == NULL){
return false;
}
Node * p = head->next;
Node * pre = head;//pre始终保存前驱结点的指针
while(p != NULL){
if(p->data == data){
pre->next = p->next;
delete(p);
p = pre->next;
}else{
pre = p;
p = p->next;
}
}
return true;
}
这里的思路也很简单:一个一个找,找到就删除。这里默认是全删除,具体是只删除第一次出现还是全删,看情况。其实这里的程序有一个问题:如果没找到也会返回true。你也可以先写搜索功能,在这里调用搜索函数,使用搜索函数的好处是只删除第一次出现的还是非常方便的。
按位置删除
bool DeletePos(Node * const head, int pos, int &e){//head表里删除pos位置的元素,并保存到暂存变量e中
if(head->next == NULL){
return false;
}
Node * temp = head;
for(int i = 0; i < pos-1; i++){
temp = temp->next;
}
Node * p = temp->next;
e = p->data;
temp->next = temp->next->next;
delete(p);
return true;
}
先使得指针移到那个pos-1的位置,请注意不要到pos这个位置,因为这是单项链表,我们只能前进不能后退,我们如果失去与后一个的联系会很麻烦。(如果你是C/C++请一定记得free/delete,不然会内存泄漏)
单纯结点删除
例如:LeetCode——删除中间结点。其实这道问题就是很好的案例。
实现一种算法,删除单向链表中间的某个节点(即不是第一个或最后一个节点),假定你只能访问该节点。
示例:
输入:单向链表a->b->c->d->e->f中的节点c
结果:不返回任何数据,但该链表变为a->b->d->e->f
简单的分析一下:意思就是你只有这个结点,链表你也拿不到。这就意味这你没办法访问该节点之前的结点。我们知道想删除结点是需要前一个(前驱)的帮助。但是,我们可以访问后一个(后继)。直接偷梁换柱。把后继的值赋给自己,然后把后继给干掉。(为后继默哀2秒钟)
void deleteNode(ListNode* node) {
if(node == NULL) return ;
node->val = node->next->val;
node->next = node->next->next;
}
链表的释放
链表不同于数组,可以之间使用delete []的语法释放。因为链表的空间是不连续的,所以最好的方式就是在一个循环中一个一个释放
bool DeleteAll(){
Node * temp;
while (head != NULL)
{
temp = head;
head = head->next;
delete temp;
}
}
搜索
一个一个挨个找。
int Search(Node * head,int data){
if(head == NULL){
return -1;
}
Node * temp;
int count = 0;
temp = head->next;
while(temp){
if(temp->data == data){
return count;
}
temp = temp->next;
count++;
}
return -2;
}
有关这个程序会有两个异常:head压根不存在和没找到让程序分别返回-1 和 -2.
这里使用bool类型也完全可以。需要注意的是尽可能不要使用void类型,大部分的函数都可以用bool表示(功能实现了返回true,没有实现返回false。但是具体返回什么请根据实际问题来定夺)。除非是负责测试或者是输出显示的函数。
总结和提醒
链表不能实现 随机访问,而且我们在搜索的时候还是要一个一个找,这是不如数组的地方。但是没有空间的限制,而且删除和添加都很简单。这就是链表比数组优越的地方。
我想如果以上的基础你都明白的话,也许你会知道链表的单向性实际上有的时候还是挺麻烦的,就像国际象棋中的士兵一样,只能前进不能后退。所以在使用普通的链表时,请务必仔细一点。
链表的C++实现
// LinkList.h
#include
using namespace std;
//带头结点的链表
template
class LinkList
{//链表结点定义
public:
Element data;//数据域
LinkList * next;//指针域
LinkList(Element info,LinkList * p = NULL)
{
data = info;
next = p;
}
LinkList()
{
//自己写一个无参的构造函数,如果有参构造,编译器就不给无参构造
}
};
template
class Link
{//链表本身
private:
LinkList * head, * tail;
public:
Link()
{
head = tail = new LinkList;//分配空间
head->next = NULL;
}
~Link()
{//析构要一个一个析构
LinkList * temp;
while (head != NULL)
{
temp = head;
head = head->next;
delete temp;
}
}
LinkList * SetPos(const int i)
{//返回指向第i个元素的指针,i是实际下标,当i = -1时,返回指向头结点的指针
if (i == -1)
{
return head;
}
int count = 0;
LinkList * p = head;//辅助指针
while (p != NULL && count < i)
{
p = p->next;
count++;
}
return p;
}
bool Append(const Element value)
{//在表尾插入一个元素value
LinkList * temp = new LinkList;
temp->data = value;
temp->next = NULL;
tail->next = temp;
tail = temp;
return true;
}
bool Insert(const int i, const Element value)
{//在p位置i位置插入元素value
LinkList * p = SetPos(i - 1);
if (i - 1 == NULL || i < 0)
{
return false;
}
LinkList * q = new LinkList;
q = value;
q->next = p->next;
p->next = q;
return true;
}
bool Delete(const int i)
{//删除i位置的结点
if (SetPos(i) == head || SetPos(i) == NULL)
{//头结点和空结点不能删.i本身非空且不是头结点
return false;
}//p是指i - 1 ,不是i本身
LinkList * p = SetPos(i - 1);//先找到被删除结点的前驱结点
LinkList * q = p->next;
p->next = q->next;
delete q;
return true;
}
bool SetValue(const int i, const Element value)
{//修改i位置结点的值
if (SetPos(i) == NULL)
{
return false;
}
LinkList * p = SetPos(i);
p->next->data = value;
return true;
}
bool GetValue(const int i, Element &value)
{//按位查找
if (p == head || p == NULL)
{
return false;
}
LinkNode * p = SetPos(i);
value = p->data;
return ture;
}
bool GetPos(const int &i, const Element value)
{//按值查找,给定值value,返回value的位置,若没找到,i赋值为-1
LinkList * p = head->next;
int j = 0;
while (p->next != NULL)
{
if (p->data == value)
{
i = j;
return true;
}
p = p->next;
j++;
}
i = -1;
return false;
}
void print()
{//打印链表
LinkList * p = head->next;
if (head->next == NULL)
{
cout << "本表为空表!" << endl;
}
else
{
while (p != NULL)
{
cout << p->data << " ";
p = p->next;
}
}
}
};
//请自行测试
链表扩展
链表的反转操作
我们可以使用栈来模拟这个反转的过程
ListNode* reverseList(ListNode* head) {
if(head == NULL) return NULL;
if(head->next == NULL) return head;
stack stack_listnode;
while(head != NULL) {
stack_listnode.push(head);
head = head->next;
}
ListNode* q = stack_listnode.top();
ListNode* qHead = q;
stack_listnode.pop();
while(stack_listnode.size() != 0) {
q->next = stack_listnode.top();
stack_listnode.pop();
q = q->next;
}
q->next = NULL;
return qHead;
}
也可以使用头插法来搞定
ListNode* reverseList(ListNode* head) {
if(head == nullptr) return nullptr;
if(head->next == nullptr) return head;
ListNode * h, * node;
h = new ListNode;
h->next = nullptr;
node = h;
while(head != nullptr){
node = new ListNode;
node->val = head->val;
node->next = h->next;
h->next = node;
head = head->next;
}
return newhead;
}
其实以上两种都是 重新创建一个新的链表。把新的链表递交上去。如果不想浪费空间的话,最简单的方式就是把新的链表值然后赋值回去,把新的链表delete掉,值得注意的是链表的释放在一个循环中一个一个的释放。
链表的合并操作
链表的合并操作,其实是实现多项式相加的核心思路。
链表合并的思路也很清晰:首先我们想一想所谓“合并”是指什么?这个问题要根据实际的情况来考虑。这里提供两种情况:
-
有序链表的合并
我们首先默认A B表原本就是有序的。其头指针为La,Lb。现在合并得到Lc
void MergeList_L(LinkList La, LinkList Lb, LinkList Lc){ //已知La、Lb的元素按值非递减排列 //归并La、Lb得到单链表Lc,Lc的元素也是按值非递减排列的 LinkList pa,pb,pc; pa = La->next; pb = Lb->next; Lc = pc = La;//用La的头结点作为Lc的头结点 while(pa && pb){ if(pa->data<=pb->data){ pc->next = pa; pc = pa; pa = pa->next; } else{ pc->next = pb; pc = pb; pb = pb->next; } } pc->next = pa?pa:pb;//插入剩余段 free(Lb); }链表的合并的C程序:
#include#include #include #include #include using namespace std; #define OVERFLOW -2 typedef struct Node{ int data; struct Node *next; }Node,*LinkList; int InitList(LinkList &L){ L = (LinkList)malloc(sizeof(Node)); if(!L) exit(OVERFLOW); L->next = NULL; return 1; } void CreatList(LinkList &L, int n){ LinkList p,r; r = L; int a; for(int i = 0; i < n; i++){ p = (LinkList)malloc(sizeof(Node)); scanf("%d",&a); p->data = a; r->next = p; r = p; } r->next = NULL; } void PrintList(LinkList &L){//输出单链表 LinkList q; q = L->next; while(q){ printf("%d ",q->data); q = q->next; } } void Combine(LinkList La, LinkList Lb, LinkList Lc){ LinkList pa,pb,pc; pa = La->next; pb = Lb->next; Lc = pc = La; while(pa && pb){ if(pa->data <= pb->data){ pc->next = pa; pc = pa; pa = pa->next; } else{ pc->next = pb; pc = pb; pb = pb->next; } } pc->next = pa? pa:pb; free(Lb); PrintList(Lc); } int main(){ int m,n; LinkList LA,LB; InitList(LA); InitList(LB); cout<<"请输入创建单链表LA的元素个数:"; cin>>m; CreatList(LA,m); cout<<"请输入创建单链表LB的元素个数:"; cin>>n; CreatList(LB,n); cout< -
多项式相加的合并(见后)
循环链表
概念
我们刚刚通过快慢指针已经稍微讨论一点有关环(循环链表)的问题。
其实所谓的循环链表不过是链表的尾巴->next不再是null。而是指回了头结点。形成了一个环。
本质上还是单链表。
约瑟夫环问题
据说著名犹太历史学家Josephus有过以下的故事:在罗马人占领乔塔帕特后,39 个犹太人与Josephus及他的朋友躲到一个洞中,39个犹太人决定宁愿死也不要被敌人抓到,于是决定了一个自杀方式,41个人排成一个圆圈,由第1个人开始报数,每报数到第3人,该人就必须自杀,然后再由下一个重新报数,直到所有人都自杀身亡为止。然而Josephus和他的朋友并不想遵从,他将朋友与自己安排在第16个与第31个位置,于是逃过了这场死亡游戏。
已知总人数N与报数m
单循环链表实现:创建一循环链表,尾指针指向第一个结点,去掉头结点。然后循环报数下去,当只剩下最后一人时,即当前指针的后继也是该指针时,退出循环。在循环过程中,每报到m时删除对应的结点,重新报数。
https://blog.csdn.net/sjhdxpz/article/details/81133748
void CL::Josephus(int N,int m)
{
Node *p=r;
Node *s;
while (p->next!=p)
{
int k=1;
while (k!=m)//没数到m时就一直轮下去,找到k=m时的上一结点
{
p=p->next;
k++;
}
s=p->next;//k=m对应的结点
p->next=s->next;
cout<date<<"->";
delete s;
}
cout<date< 魔术师发牌问题
一位魔术师掏出一叠扑克牌,魔术师取出其中13张黑桃,洗好后,把牌面朝下。
说:“我不看牌,只数一数就能知道每张牌是什么?”魔术师口中念一,将第一张牌翻过来看正好是A;
魔术师将黑桃A放到桌上,继续数手里的余牌,
第二次数1,2,将第一张牌放到这叠牌的下面,将第二张牌翻开,正好是黑桃2,也把它放在桌子上。
第三次数1,2,3,前面二张牌放到这叠牌的下面,取出第三张牌,正好是黑桃3,这样依次将13张牌翻出,全部都准确无误。
求解:魔术师手中牌的原始顺序是什么样子的
从1开始,每次数的数比上一个数大1,数的数是几,就翻第几张牌。由于被翻了的牌不在扑克牌之中了,所以链表实现时还要忽略已经赋值了的结点。
https://blog.csdn.net/sjhdxpz/article/details/81133748
void CL::Magician()
{
Init();//清零
Node *p=r->next;//从头结点开始
p->date=1;//初始化头结点的date为1
int count=2;//已经初始化一个了,所以从2开始数
while (count<=13)//只有13张牌
{
for (int i=1;i<=count;i++)
{
p=p->next;
if (p->date!=0)//已经赋值了的要忽略
i--;
}
p->date=count;
count++;
}
Show();
}
拉丁方阵
拉丁方阵是一种n×n的方阵,方阵中恰有n种不同的元素,每种元素恰有n个,而且每种元素在一行和一列中 恰好出现一次。
著名数学家和物理学家欧拉使用拉丁字母来作为拉丁方阵里元素的符号,拉丁方阵因此而得名。
比如:
1 2 3
2 3 1
3 1 2
问:构造一个N阶方阵
一共循环N次,第N次从第N个节点开始再循环N次。
https://blog.csdn.net/sjhdxpz/article/details/81133748
void CL::NPrint(int N)
{
Node *p=r->next;
for (int i=1;i<=N;i++)
{
for (int j=1;j<=N;j++)
{
cout<date<<" ";
p=p->next;
}
cout<next;
}
}
三个问题合一的总程序
#include
using namespace std;
struct Node{
int date;
Node *next;
};
class CL{
private:
Node *r;
public:
CL(int N);
~CL();
void Josephus(int N,int m);
void Magician();
void Init();
void NPrint(int N);
void Show();
};
CL::CL(int N)
{
Node *head,*p,*s;
head=new Node;
head->next=NULL;
p=head;
for (int i=0;idate=i+1;
s->next=p->next;
p->next=s;
p=s;
}
p->next=head->next;//指向第一个结点
r=p;//链表的尾指针
delete head;//删掉表头
}
CL::~CL()
{
Node *p,*s;
p=r->next;//指向头结点
while (p!=r)
{
s=p;
p=p->next;
delete s;
}
delete p;
cout<<"已删除整个链表"<next!=p)
{
int k=1;
while (k!=m)//没数到m时就一直轮下去,找到k=m时的上一结点
{
p=p->next;
k++;
}
s=p->next;//k=m对应的结点
p->next=s->next;
cout<date<<"->";
delete s;
}
cout<date<next;
while (p!=r)
{
p->date=0;
p=p->next;
}
p->date=0;
}
void CL::Magician()
{
Init();//清零
Node *p=r->next;
p->date=1;//初始化第一个结点为1
int count=2;//已经初始化一个了,所以从2开始数
while (count<=13)
{
for (int i=1;i<=count;i++)
{
p=p->next;
if (p->date!=0)
i--;
}
p->date=count;
count++;
}
Show();
}
void CL::Show()
{
Node *p=r->next;
while (p!=r)
{
cout<date<<" ";
p=p->next;
}
cout<date<next;
for (int i=1;i<=N;i++)
{
for (int j=1;j<=N;j++)
{
cout<date<<" ";
p=p->next;
}
cout<next;
}
}
int main()
{
CL La(41);
CL Lb(13);
CL Lc(5);
La.Josephus(41,3);
Lb.Magician();
Lc.NPrint(5);
return 0;
}
这三个问题不仅仅可以使用链表实现。但这里并不会提供其他思路,毕竟主角是链表。
实现
//节点
struct node{
int data1;
node *next;
};
//链表类 头部文件
class singlelink{
private:
node data;
int length;
public:
singlelink(){
length=0;
data.data1=0;
data.next=&data;
}
~singlelink(){};
bool isempty(){
if(length==0)
return true;
else
return false;
}
int returnlength(){
return length;
}
bool insert(int position, int num);
bool deletenode(int position);
int returnnum(int position);
void returnallnum(int position);
bool deleteall();
void headinsert(int num);
void rearinsert(int num);
};
//方法
bool singlelink::insert(int position, int num){
if(position>length+1)
return false;
else{
node* probe=&data;
for(int i=1;inext;
}
node* newnode=new node;
newnode->data1=num;
newnode->next=probe->next;
probe->next=newnode;
length++;
}
return true;
}
bool singlelink::deletenode(int position){
if(position>length)
return false;
else{
node* probe=&data;
node* temp=NULL;
for(int i=1;inext;
}
temp=probe->next;
probe->next=probe->next->next;
free(temp);
length--;
return true;
}
}
int singlelink::returnnum(int position){
node* probe=&data;
for(int i=1;i<=position;i++){
probe=probe->next;
}
return probe->data1;
}
bool singlelink::deleteall(){
node* probehead=&data;
node* proberear=NULL;
while(probehead->next!=&data){
proberear=probehead->next;
free(probehead);
probehead=proberear;
length--;
}
free(probehead);
if(length==0)
return true;
else
return false;
}
void singlelink::headinsert(int num){
node* probe=&data;
node* newnode=new node;
newnode->data1=num;
newnode->next=probe->next;
probe->next=newnode;
length++;
}
void singlelink::rearinsert(int num){
node* probe=&data;
for(int i=1;i<=length;i++){
probe=probe->next;
}
node* newnode=new node;
newnode->data1=num;
newnode->next=&data;
probe->next=newnode;
length++;
}
void singlelink::returnallnum(int position){
int times=0;
node* probe=&data;
for(int i=1;i<=position;i++){
probe=probe->next;
}
while(timesdata1<<" ";
times++;
probe=probe->next;
}
else
probe=probe->next;
}
}
//主函数
int main(){
singlelink a1,a2;
if(a1.isempty())
cout<<"是空链表"< 循环链表的实现
双向链表
概念
我们之前描述了单链表的一个不方便的地方:只能往前不能后退。而双端链表就是一个可以前进也可以后退的链表。我们只需要增加一个指向上一个块的指针,我们可以称其为前驱,相对应的后面的一块我们叫后继。无论叫什么名字,我们总归还是觉得能前能后更加方便。
双端链表的实现
#pragma once
#include
using namespace std;
template
class DoubleNode {
public:
T data;
DoubleNode * next;
DoubleNode * prior;
DoubleNode() {
next = nullptr;
prior = nullptr;
}
DoubleNode(T info) {
data = info;
next = nullptr;
prior = nullptr;
}
};
template
class DoubleLink {
private:
DoubleNode * head;
int length, temp;
public:
DoubleLink() {
//默认head存放链表长度
head = new DoubleNode;
head->next = head->prior = nullptr;
head->data = 0;//默认长度初始化0
length = 0;
}
DoubleLink(int number, T * array, int arrLen) {
//含参数初始化,第一个参数声明第一次初始化多少个结点;第二个参数分别给各个节点赋值;第三个参数为第二个参数数组的长度
if (arrLen < number) return;
DoubleNode * tmp,* p;
p = head = new DoubleNode;
head->next = head->prior = nullptr;
length = 0;
for (int i = 0; i < number; i++) {
tmp = new DoubleNode;
tmp->data = array[i];
p->next = tmp;
tmp->prior = p;
p = p->next;
p->next = nullptr;
length++;
}
}
~DoubleLink() {
DoubleNode * tmp;
while (head != nullptr) {
tmp = head;
head = head->next;
delete tmp;
}
}
T GetTemp() const{
return this->temp;
}
bool Insert(const int position, const T data) {
if (position <= 0) return false;
//默认head不能被替换。
if (position == this->length) Append(data);
//如果位置是表尾的话,调用对应函数
DoubleNode * p, * tmp;
p = head;
for (int i = 0; i < position - 1; i++) {
p = p->next;
}
tmp = new DoubleNode;
tmp->data = data;
p->next->prior = tmp;
tmp->next = p->next;
p->next = tmp;
tmp->prior = p;
length ++;
return true;
}
bool Append(const T data) {
DoubleNode * tmp, *p;
tmp = new DoubleNode;
tmp->data = data;
p = head->next;
while (p->next != nullptr) {
p = p->next;
}
p->next = tmp;
tmp->prior = p;
p = p->next;
p->next = nullptr;
this->length++;
return true;
}
bool DeletePos(const int position) {
if (position <= 0) return false;
//不能删除head
DoubleNode * p, * tmp;
p = head;
for (int i = 0; i < position - 1; i++) {
p = p->next;
}
this->temp = p->next->data;
tmp = p->next;
if (position == head->data) {
p->next = nullptr;
}
else {
p->next->next->prior = p;
p->next = p->next->next;
}
this->length--;
delete tmp;
}
bool DeleteVal(T data) {
DoubleNode * p, * tmp;
p = head->next;
int current = 1;
while (p != nullptr) {
if (p->data == data) {
tmp = p;
if (p->next == nullptr) {
p->prior->next = nullptr;
}else {
p = p->next;
p->prior->prior->next = p;
p->prior = p->prior->prior;
}
delete tmp;
this->length--;
current++;
}else {
p = p->next;
current++;
}
}
return true;
}
int Search(const T data) const{
DoubleNode * tmp;
int currentPos = 1;
tmp = head->next;//要从头结点的下一个开始找,因为head中存储着链表长度
while (tmp != nullptr) {
if (tmp->data == data) {
return currentPos;
}else {
tmp = tmp->next;
currentPos++;
}
}
return -1;//没找到
}
void Print() const{
DoubleNode * p;
p = head->next;
cout << "该双向链表的长度为:" << this->length << endl;
while (p != nullptr) {
cout << p->data << " ";
p = p->next;
}
cout << endl;
}
};
【注意】双向链表的插入和删除思路与单链表一样,请记住一定不要出现“失去联系”的情况。在插入和删除的时候一定找确定基点的位置,然后利用next和prior指针进行操作。尤其是双向链表的的插入和删不要强行记忆。
静态链表
概念
有关静态这个词是指存储空间的大小一开始我们就预订好了。而不是像之前的链表一样,需要的时候临时创建。以后还有经常看到静态这个词。
静态链表的实现
//节点定义
struct Node{
int data;
int next;
};
//定义结构体数组,利用next来索引节点。本质上是一个hash
链表的应用
快慢指针
概念
简单的来说,快慢是一个思路。其思路的来源是利用 快指针和慢指针来制造自己所希望的差值。而这个差值可以帮助我们寻找链表上对应的结点。
找中间值
其一般思路:一个一个遍历,记录下一共有多少个,然后第二次遍历就可以找到了。
但是如果可以利用快慢指针:我们设置快指针两个两个走,慢指针一个一个走。这样其实快指针的速度是慢指针的两倍。这样当,快指针到达终点时,慢指针就正好走了一半。(讲到这里,想必不仅是中间值,其他的值只要能知道关系,也就可以使用快慢指针来寻找呢)
判断链表的环
这个思路也很简单:快指针一定会追上慢指针。这样也就可以断定是否有环了。
public boolean hasCycle(ListNode head) {
if (head == null || head.next == null) {
return false;
}
ListNode fast = head;
ListNode low = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
low = low.next;
if (low.equals(fast)) {
return true;
}
}
return false;
}
当然,这里我们还能找到环的入口点。当快指针和慢指针相遇时,慢指针一定没有遍历完或者正好走完一圈,所以我们从表头与相遇点分别设置一个指针,每次各走一步,两个指针必然相遇,这次历史性的会面告诉我们环的入口。
node* findLoopPort(node *head) {
node *fast, *slow;
fast = slow = head;
while (fast && fast->next) {
//第一步:判断链表是否存在环
slow = slow->next;
fast = fast->next->next;
if (slow == fast) { //链表存在环
break;
}
}
if ((fast == NULL) || (fast->next == NULL)) { //链表不存在环
return NULL;
}
//第二步:寻找环的入口点
slow = head; //让slow回到链表的起点,fast留在相遇点
while (slow != fast) { //当slow和fast再次相遇时,那个点就是环的入口点
slow = slow->next;
fast = fast->next;
}
return slow;
}
删除倒数第n个结点
删除倒数第n个元素,那就是等于要求我们先找出待删除元素的前一个元素,也就是第n-1个结点。结果我们再一次将问题转换成找结点问题了。但是我们在这里不能硬套上面的思路,一个快一个慢。而是两个指针一样的速度,都是一个一个的走。但是让其中一个先走n个。这样就能保证这两个指针的差值是恒定的。
public ListNode removeNthFromEnd(ListNode head, int n) {
if (head == null || head.next == null) {
return null;
}
ListNode dummyHead = new ListNode(-1);
dummyHead.next = head;
ListNode slow = dummyHead;
ListNode fast = dummyHead;
for (int i = 0; i < n + 1; i++) {
fast = fast.next;
}
while (fast != null) {
slow = slow.next;
fast = fast.next;
}
slow.next = slow.next.next;
return dummyHead.next;
}
回文链表
这里其实是LeetCode的一个题目了。
请判断一个链表是否为回文链表。
示例 1:
输入: 1->2
输出: false
示例 2:
输入: 1->2->2->1
输出: true
**思路:**现学现用使用快慢指针寻找中间值。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public boolean isPalindrome(ListNode head) {
if(head==null||head.next==null) return true;
ListNode fast = head;
ListNode slow = head;
ListNode pre = null;
//1.快慢指针,找到链表的中点。
while(fast!=null&&fast.next!=null){
slow=slow.next;
fast=fast.next.next;
}
//2.将slow之后链表反转
while(slow!=null){
ListNode next=slow.next;
slow.next = pre;
pre = slow;
slow = next;
}
//3.前后链表进行比较,注意若为奇数链表,多1一个节点,然而并不影响判断回文
while(head!=null&&pre!=null){
if(head.val!=pre.val) return false;
head=head.next;
pre=pre.next;
}
return true;
}
}
计算n的阶乘
我想看到这个阶乘的问题,许多人应该能想到各种各样的方式去实现,其中可能最普遍都会想到的解法就是:递归。但是,我想尽可能回避递归这个话题。因为递归操作可能仅仅是方便了程序员,但对于计算机而言并不一定是一件舒服的事情。我们向递归的抗争也许到树的时候会达到高潮。
问题描述
n(n≥20)的阶乘
基本要求
1.数据的表示和存储:
累积运算的中间结果和最终的计算结果的数据类型要求是整型——这是问题本身的要求。
试设计合适的存储结构,要求每个元素或结点最多存储数据的3位数值。
2.数据的操作及其实现:
基于设计的存储结构实现乘法操作,要求从键盘上输入n值;在屏幕上显示最终计算结果
3.从问题描述不难看出n值为任意值,故为使程序尽量不受限制,应采用动态存储结构
用单链表实现数据的动态存储
解决方案
结构体类定义:
struct LinkNode
{
int element;
LinkNode* next;
LinkNode() { this->next = NULL; this->element = 0; }
LinkNode(int element) { this->element = element; }
};
class Link
{
public:
Link() {};
~Link() {};
Link(int n);
void factorial();
void output();
private:
LinkNode * head;
int n;
};
核心程序:
//构造函数,
Link::Link(int n)
{
this->n = n;
head = new LinkNode();
head->element = 1;
}
//核心代码,一个节点保存三位
void Link::factorial()
{
int flag;
for (int i = 1; i <= n; ++i)//处理1~n的乘法
{
LinkNode* current = head;
flag = 0;//初始化
while (current != NULL)
{
current->element = i * (current->element) + flag;//当前的值*i 加低位的进位
//如何当前值大于1000,即需要进位,如果当前的current->next == NULL,说明需要拓展节点
if (current->element >= 1000 && current->next == NULL)
{
current->next = new LinkNode();
}
//flag作为上一位进位的数值
flag = current->element / 1000;
//当前的值处理一下,保证小于1000
current->element = current->element % 1000;
//下一个节点
current = current->next;
}
}
}
//输出函数,调用print(headNode)
void Link::output()
{
print(head);
}
//递归实现输出,逆序输出,实现正常的数据顺序
void print(LinkNode * node)
{
if (node != NULL) {
print(node->next);
if (node->next == NULL)//如果是第一位,直接输入保存的数据
printf("%d", node->element);
//因为后面保存的数据可以为000,所以格式控制输出
else printf("%03d", node->element);
}
return;
}
一元多项式合并
当我说出合并同类项的时候,你就应该明白我的需求是什么了
问题描述
数学上的一元多项式的表示是p(x) = p0 + p1 * x + p2 * x^2 + p3 * x^3 + … + pn * x^n;
用链表来表示就是p = (p0, p1, p2, … , pn);
所谓的多项式相加就是同类项的合并,也就是两条链表的合并。
采用单链表保存多项式,链表的每个结点表示多项式的每一非零项,链表应该按有序排列。
解决方案(仅加法)
https://blog.csdn.net/shujh_sysu/article/details/52150835
数学上的一元多项式的表示是p(x) = p0 + p1 * x + p2 * x^2 + p3 * x^3 + … + pn * x^n;
用链表来表示就是p = (p0, p1, p2, … , pn);
所谓的多项式相加就是同类项的合并,也就是两条链表的合并。
采用单链表保存多项式,链表的每个结点表示多项式的每一非零项,链表应该按有序排列。
结点如下:
struct PolyNode {
float coef; //存放系数
int exp; //存放指数
PolyNode * next;
};
类定义如下:
class PolyLinkList {
public:
PolyLinkList(arguments);
~PolyLinkList();
void show();
void polyAdd(PolyLinkList & LB);
};
下面先就两个一元多项式链表LP和LQ相加为例说明:
如图所示,qa, qb分别指向两条链表的当前结点,pa, pb分别指向当前结点的前驱。
开始时四个指针分别指向两个单链表的头结点和开始结点:
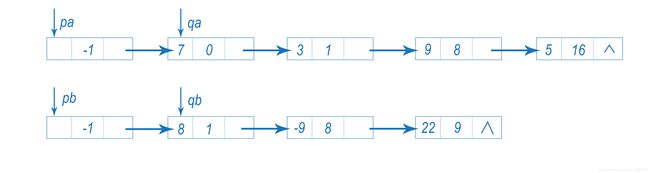
两个多项式求和实际上是对结点qa的指数和结点qb的指数进行比较,这会出现一下三种情况:
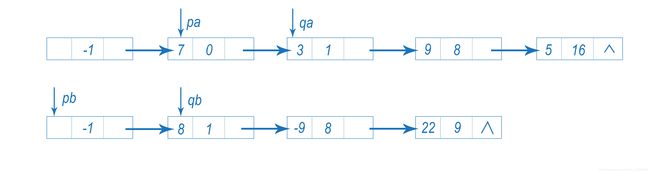
(1)qa指数<qb指数,则结点qa应为结果中的一个结点,将指针qa和pa向后移动一个结点,qb和pb不移动。如图:
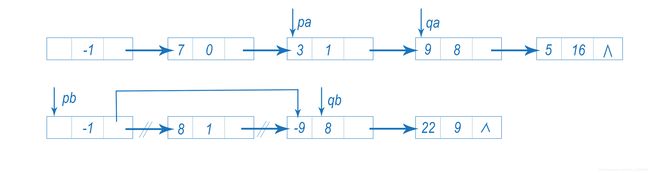
(2)qa的指数=qb的指数,则qa和qb所指向的是”同类项”。先将qb的系数加到qa上,再判断是否为零。若相加的结果不为零,则将指针qa和pa向后移,再将qb向后移,再删除原结点qb,如图:
若相加的结果为零,则表明结果中无此项,同时删除结点qa和结点qb,并个将4个指针分别后移,如图所示:
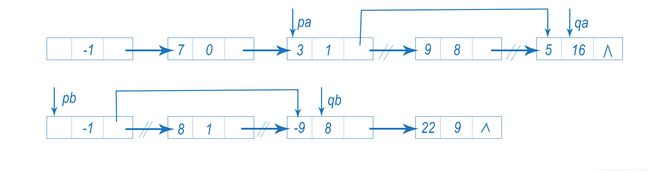
(3)qa指数>qb指数,则结点qb应为结果中的一个结点,将qb插入到第一个单链表中结点qa之前,pa指向新插入的结点,再将指针pb和qb向后移。
上述情况是针对指针qa和qb均不为空的情况,在进行指数比较的过程中,如果qa已空而qb非空,此时直接将第二个链表中剩余的结点连接到第一个链表的后面。
void PolyLinkList::polyAdd(PolyLinkList & LB) {
float sum;
PolyNode *pa, *pb, *qa, *qb;
//初始化
pa = head;
qa = pa->next;
pb = LB.head;
qb = pb->next;
while (qa != NULL && qb != NULL) {
if (qa->exp < qb->exp) { //第一种情况
pa = qa;
qa = qa->next;
} else if (qa->exp > qb->exp) { //第三种情况
pb->next = qb->next;
qb->next = qa;
pa->next = qb;
pa = qb;
qb = pb->next;
} else { //第二种情况
sum = qa->coef + qb->coef;
if (sum == 0) { //系数和为0,删除结点qa和qb
pa->next = qa->next;
delete qa;
qa = pa->next;
pb->next = qb->next;
delete qb;
qb = pb->next;
} else { //系数和不为0,只删除结点qb
qa->coef = sum;
pa = qa;
qa = qa->next;
pb->next = qb->next;
delete qb;
qb = pb->next;
}
}
}
if (qb != NULL) {
qa->next = qb; //插入剩余的部分
}
}
解决方案(进阶)
多项式的class定义+多项式加法+多项式乘法
#include
#include
using namespace std;
struct Term {
float coef;
int exp;
Term * link;
//多项式节点的定义
Term(float c, int e, Term * next = NULL) { //构造函数
coef = c; //系数
exp = e; //指数
link = next; //指向下一个节点的指针
}
Term * InsertAfter(float c, int e);
friend ostream & operator << (ostream&, const Term&);
};
class Polynomal {
public:
Polynomal(){ first = new Term(0, -1); } //构造函数
Polynomal(Polynomal &R); //复制构造函数
int maxOrder(); //计算最大阶数
Term * getHead() const { return first; } //取得多项式单链表的表头指针
private:
Term *first;
friend ostream & operator << (ostream &, const Polynomal &);
friend istream & operator >> (istream &, Polynomal &);
friend Polynomal operator + (Polynomal &, Polynomal &);
friend Polynomal operator * (Polynomal &, Polynomal &);
};
//函数定义
Term * Term::InsertAfter(float c, int e) {
//在当前由this指针指示的项(即调用此函数的对象)后面插入一个新项
link = new Term(c, e, link); //创建一个新节点,自动连接
return link; //返回新节点,以便下一次追加使用
}
ostream & operator << (ostream & out, Term & x) {
//Term的友元函数,输出一个项x的内容到输出流out中
if (0 == x.coef) { //如果这一项的系数为0,则不输出
return out;
}
out << x.coef;
switch (x.exp) { //不同指数的格式控制
case 0: break;
case 1: out << "X"; break;
default: out << "X^" << x.exp; break;
}
return out;
}
Polynomal::Polynomal(Polynomal & R) {
//复制构造函数 : 用已有的多项式对象R初始化当前多项式对象
first = new Term(0, -1);
Term *destptr = first, *srcptr = R.getHead()->link;
while (NULL != srcptr) {
destptr->InsertAfter(srcptr->coef, srcptr->exp); //在destptr所指节点后插入新节点
srcptr = srcptr->link;
destptr = destptr->link;
}
}
int Polynomal::maxOrder() {
//计算最大阶数,当多项式按照升序排序时,最后一项的指数最大
Term *current = first;
while (NULL != current->link) {
current = current->link; //表为NULL的时候,current停留在first,否则指向尾节点
}
return current->exp;
}
istream & operator >> (istream & in, Polynomal & x) {
//Polynomal class 的友元函数,从输入流in输入各项,用顺序法建立一个多项式
Term *rear = x.getHead();
int c, e;
while (true) {
cout << "Input a term(coef, exp) : " << endl;
in >> c >> e;
if (e < 0) {
break; //指数是负数作为结束的标志
}
rear = rear->InsertAfter(c, e); //链接到rear所指节点后
}
return in;
}
ostream & operator << (ostream & out, Polynomal & x) {
//Polynomal class 的友元函数 : 输出带附加头节点的多项式链表x
Term *current = x.getHead()->link; //先令current指向当前多项式的开始节点
cout << "这个多项式是 : " << endl;
bool h = true;
while (NULL != current) {
if (current->coef > 0 && h == false) {
cout << "+";
}
h = false;
out << *current;
current = current->link;
}
cout << endl;
return out;
}
Polynomal operator + (Polynomal & A, Polynomal & B) {
//友元函数:两个带附加头节点的按升幂排序的多项式链表的头指针分别是A.first and B.first
//返回的结果是两个多项式的和链表
Term *pa, *pb, *pc, *p;
float temp;
Polynomal C;
pc = C.first; //pc是结果多项式C在创建过程中的尾指针
pa = A.getHead()->link;
pb = B.getHead()->link; //pa,pb定位在A,B两个多项式的相应节点
while (pa != NULL && pb != NULL) { //对两个子多项式的节点指数逐一比较
if (pa->exp == pb->exp) { //相等的情况
temp = pa->coef + pb->coef; //系数相加
if (fabs(temp) > 0.001) { //相加后系数不等于0
pc = pc->InsertAfter(temp, pa->exp); //提取指数与系数追加在和多项式之后
}
pa = pa->link;
pb = pb->link; //检测指针向后一个节点移动
}
else if (pa->exp < pb->exp) { //指数不想等的两种大小关系
pc = pc->InsertAfter(pa->coef, pa->exp);
pa = pa->link; //仅pa检测指针向后一个节点移动
}
else {
pc = pc->InsertAfter(pb->coef, pb->exp);
pb = pb->link;
}
}
//检查是否有剩余链表,若有直接链接到和链表C后
if (pa != NULL) { //借助p指针标记剩余链表,待之后做链接
p = pa;
}
else {
p = pb;
}
while (p != NULL) {
pc = pc->InsertAfter(p->coef, p->exp);
p = p->link;
}
return C;
}
Polynomal operator * (Polynomal & A, Polynomal & B) {
//将一元多项式A 和 B相乘,乘积用带附加头节点的单链表存储
//返回值为指向存储乘积多项式的单链表
Term *pa, *pb, *pc;
int AL, BL, i, k, maxExp;
Polynomal C;
pc = C.getHead();
AL = A.maxOrder(); //首先计算乘积后的最大指数
BL = B.maxOrder();
if (AL != -1 || BL != -1) {
maxExp = AL + BL;
float *result = new float[maxExp + 1]; //开辟辅助数组用来存储相关指数项的系数
for (i = 0; i <= maxExp; i ++) {
result[i] = 0; //初始化辅助数组
}
pa = A.getHead()->link;
while (pa != NULL) { //双重循环实现两个多项式相乘
pb = B.getHead()->link;
while (pb != NULL) {
k = pa->exp + pb->exp; //乘积的指数
//注意此处是累加
result[k] = result[k] + pa->coef * pb->coef; //计算乘积后的系数并存储在相应指数序号的数组中
pb = pb->link; //向后一个节点移动
}
pa = pa->link; //向后一个节点移动
}
//将指数——系数数组中的数据存储到新的单链表中,组成乘积多项式
for (i = 0; i <= maxExp; i ++) {
if (fabs(result[i]) > 0.001) {
pc = pc->InsertAfter(result[i], i);
}
}
delete[] result; //释放资源数组
}
pc->link = NULL;
return C;
}
Code:LinkList.cpp
#include
#include
using namespace std;
struct Node{
int data;
Node * next;
};
Node * CreatLinkList(int * array, int len){
Node * pre, * head, * temp;//pre是保存当前结点的前驱
head = new Node;
head->next = NULL;
pre = head;
for(int i = 0; i < len; i++){
temp = new Node;
temp->data = array[i];
temp->next = NULL;
pre->next = temp;
pre = temp;
}
return head;
}
//实现反转操作
void Opposite(Node * head,int len){
Node * temp;
temp = head->next;
int * ans = new int[len];
printf("\n");
int i = 0;
while(temp){
ans[i++] = temp->data;
temp = temp->next;
}
printf("\n");
for(int i = len-1; i >= 0; i--){
printf("%d ",ans[i]);
}
delete [] ans;
}
int Search(Node * head,int data){
if(head->next == NULL){
return -1;
}
Node * temp;
int count = 0;
temp = head->next;
while(temp){
if(temp->data == data){
return count;
}
temp = temp->next;
count++;
}
return -2;
}
bool Insert(Node * head, int pos, int data){//在head表里面pos位置,插入data元素
if(head->next == NULL){
return false;
}
Node * p = head;
for(int i = 0; i < pos-1; i++){
p = p->next;
}
Node * q = new Node;
q->data = data;
q->next = p->next;
p->next = q;
return true;
}
bool DeletePos(Node * const head, int pos, int &e){//head表里删除pos位置的元素,并保存到暂存变量e中
if(head->next == NULL){
return false;
}
Node * temp = head;
for(int i = 0; i < pos-1; i++){
temp = temp->next;
}
Node * p = temp->next;
e = p->data;
temp->next = temp->next->next;
delete(p);
return true;
}
bool DeleteValue(Node * const head,int data){//head表里删除值为data的元素(把第一次出现的删了就行)
if(head->next == NULL){
return false;
}
Node * p = head->next;
Node * pre = head;//pre始终保存前驱结点的指针
while(p != NULL){
if(p->data == data){
pre->next = p->next;
delete(p);
p = pre->next;
}else{
pre = p;
p = p->next;
}
}
return true;
}
Node * headcreat()
{
Node * head;
head = new Node; // 为头指针开辟内存空间
Node * node = NULL; // 定义新结点
int count = 0; // 创建结点的个数
head->next = NULL;
node = head->next; // 将最后一个结点的指针域永远保持为NULL
printf("Input the node number: ");
scanf("%d", &count);
for (int i = 0; i < count; i++) {
node = new Node; // 为新结点开辟内存空间
node->data = i; // 为新结点的数据域赋值
node->next = head->next; // 将头指针所指向的下一个结点的地址,赋给新创建结点的next
head->next = node; // 将新创建的结点的地址赋给头指针的下一个结点
}
return head;
}
Node * Creat_list() {
Node * head, * end, * node;
head = new Node; // 为头指针开辟内存空间
node = end = NULL; // 初始化头结点指向的下一个地址为 NULL
end = head; // 未创建其余结点之前,只有一个头结点
int count = 0 ; // 结点个数
printf("Input node number: ");
scanf("%d", &count);
for (int i = 0; i < count; i++) {
node = new Node; // 为新结点开辟新内存
node->data = i; // 新结点的数据域赋值
end->next = node;
end = node;
}
end->next = NULL;
return head;
}
void SearchTest(int * array, int len){//搜索测试程序
int d;
printf("请输入你要值:");
scanf("%d",&d);
if(Search(CreatLinkList(array,len),d) == -2){
printf("你要找的元素不存在!");
}else if(Search(CreatLinkList(array,len),d) == -1){
printf("尼玛的!表都没有找个jer啊!");
}else{
printf("你要寻找的元素 %d 是第 %d 号",d,Search(CreatLinkList(array,6),d)+1);
}
}
void Show(Node * head){
Node * temp;
temp = head;
temp = temp->next;
while(temp != NULL){
printf("%d ",temp->data);
temp = temp->next;
}
}
void Print(Node * head){
Node * temp;
temp = head->next;
while(temp != NULL){
printf("%d ",temp->data);
temp = temp->next;
}
}
int main(){
/*
int array[] = {4,2,1,6,7,9};
Node * L = CreatLinkList(array,6);
Show(L);
printf("\n");
Insert(L,3,3);
Show(L);
printf("\n");
int e;
DeletePos(L,3,e);
Show(L);
printf("e = %d\n",e);
DeleteValue(L,1);
Show(L);
*/
Print(Creat_list());
return 0;
}