PPO算法实现的37个实现细节(2/3)9 Atari-specific implementation details
博客标题:The 37 Implementation Details of Proximal Policy
Optimization
作者:Huang, Shengyi; Dossa, Rousslan Fernand Julien; Raffin, Antonin; Kanervisto, Anssi; Wang, Weixun
博客地址:https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
代码github仓库地址:https://github.com/vwxyzjn/ppo-implementation-details
本文接上篇PPO算法实现的37个实现细节(1/3)13 core implementation details继续,本篇主要介绍与Atari类型的游戏环境的场景下,实现PPO算法的9个实现细节。
1. The Use of NoopResetEnv 【Environment Preprocessing】
这个wrapper在reset时通过一个1-30之间的随机数字采样初始 states
This wrapper samples initial states by taking a random number (between 1 and 30) of no-ops on reset.
该wrapper的概念来自(Mnih 等人,2015)和 Machado 等人,2018)建议 NoopResetEnv 是一种向环境注入随机性的方法。

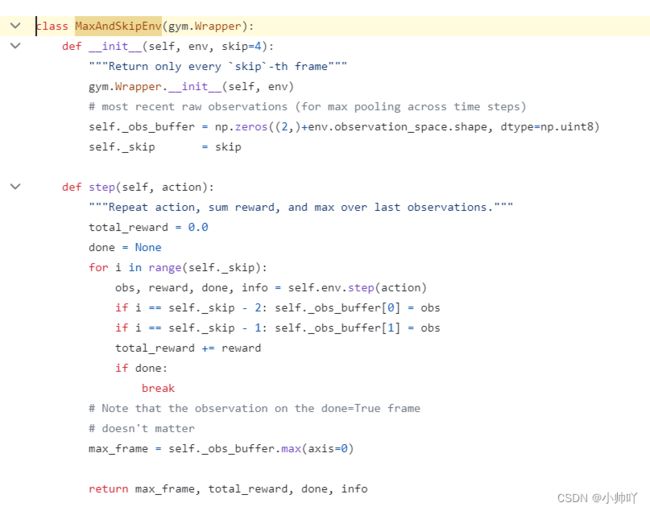
2. The Use of MaxAndSkipEnv 【Environment Preprocessing】
wrapper默认跳过 4 帧,在跳过的帧上重复agent的最后一个动作,并对跳过帧的奖励进行加总。这种跳帧技术可以大大加快算法速度,因为环境step的计算成本要低于agent的前向传递(Mnih 等人,2015)。
wrapper还会返回最后两帧的最大像素值,以帮助处理雅达利游戏的一些特殊情况(Mnih 等人,2015 年)。
如下引文所示,该wrapper的来源来自(Mnih 等人,2015 年)。
更确切的说,agent每k个帧frame观察和选择动作而不是每个帧frame,并且最后一个动作是重复的在跳过的帧frame上。由于向前运行模拟器一步所需的计算量比让代理选择一个动作要少得多,因此该技术允许代理执行大约 k次在不显着增加运行时间的情况下增加更多游戏次数。我们对于所有的游戏使用k=4。首先,在对单帧进行编码时,我们取正在编码的帧和前一帧中每个像素颜色值的最大值。在游戏中,有些物体只出现在偶数帧中,而另一些物体只出现在奇数帧中,这是由于 Atari 2600 一次能显示的npc数量有限造成的。
3. The Use of MaxAndSkipEnv 【Environment Preprocessing】
在有生命回合制的游戏中,比如闯关游戏,这个wrapper会将生命值的结束标记为episode的结束。
该wrapper的来源来自(Mnih 等人,2015 年),如下所示
For games where there is a life counter, the Atari 2600 emulator also sends the number of lives left in the game, which is then used to mark the end of an episode during training.
有趣的是,(Bellemare 等人,2016)提出此wrapper可能会损害代理的性能,而 Machado 等人,2018)建议不要使用此wrapper。

4. The Use of FireResetEnv【Environment Preprocessing】
This wrapper takes the FIRE action on reset for environments that are fixed until firing.
这个 wrapper很有意思,因为据我们所知没有任何文献参考。根据轶事对话(openai/baselines#240),DeepMind 和 OpenAI 的人都不知道这个wrapper来自哪里。

5. The Use of WarpFrame (Image transformation) 【Environment Preprocessing】
该 wrapper提取 210x160 像素图像的 Y 通道,并将其调整为 84x84。
如下引文所示,该 wrapper的来自(Mnih 等人,2015 年)。
Second, we then extract the Y channel, also known as luminance, from the RGB frame and rescale it to 84x84.

在我们的实现中,我们使用以下wrapper来实现相同的目的。
env = gym.wrappers.ResizeObservation(env, (84, 84))
env = gym.wrappers.GrayScaleObservation(env)
6. The Use of ClipRewardEnv【Environment Preprocessing】
该 wrapper通过符号将奖励分到 {+1、0、-1} 中。
如下引文所示,该wrapper来自(Mnih 等人,2015 年)。
As the scale of scores varies greatly from game to game, we clipped all positive rewards at 1 and all negative rewards at -1, leaving 0 rewards unchanged. Clipping the rewards in this manner limits the scale of the error derivatives and makes it easier to use the same learning rate across multiple games. At the same time, it could affect the performance of our agent since it cannot differentiate between rewards of different magnitude.

7. The Use of FrameStack【Environment Preprocessing】
这个 wrapper会堆叠 m个最后帧,这样代理就能推断出移动物体的速度和方向。
如下引文所示,该wrapper来自(Mnih 等人,2015 年)。
The function θ from algorithm 1 described below applies this preprocessing to the m most recent frames and stacks them to produce the input to the Q-function, in which m=4.

8. Shared Nature-CNN network for the policy and value functions 【Neural Network】
对于 Atari 游戏,PPO 使用了(Mnih 等人,2015 年)中相同的卷积神经网络(CNN)以及前面提到的层初始化技术(baselines/a2c/utils.py#L52-L53)来提取特征,将提取的特征扁平化flatten the extracted features,应用线性层来计算隐藏特征。之后,通过使用隐藏特征构建策略头和价值头,策略函数和价值函数共享参数。下面是一个伪代码:
hidden = Sequential(
layer_init(Conv2d(4, 32, 8, stride=4)),
ReLU(),
layer_init(Conv2d(32, 64, 4, stride=2)),
ReLU(),
layer_init(Conv2d(64, 64, 3, stride=1)),
ReLU(),
Flatten(),
layer_init(Linear(64 * 7 * 7, 512)),
ReLU(),
)
policy = layer_init(Linear(512, envs.single_action_space.n), std=0.01)
value = layer_init(Linear(512, 1), std=1)
与设置完全独立的网络(如下所示)相比,这种参数共享模式的计算速度显然更快。
policy = Sequential(
layer_init(Conv2d(4, 32, 8, stride=4)),
ReLU(),
layer_init(Conv2d(32, 64, 4, stride=2)),
ReLU(),
layer_init(Conv2d(64, 64, 3, stride=1)),
ReLU(),
Flatten(),
layer_init(Linear(64 * 7 * 7, 512)),
ReLU(),
layer_init(Linear(512, envs.single_action_space.n), std=0.01)
)
value = Sequential(
layer_init(Conv2d(4, 32, 8, stride=4)),
ReLU(),
layer_init(Conv2d(32, 64, 4, stride=2)),
ReLU(),
layer_init(Conv2d(64, 64, 3, stride=1)),
ReLU(),
Flatten(),
layer_init(Linear(64 * 7 * 7, 512)),
ReLU(),
layer_init(Linear(512, 1), std=1)
)
然而,最近的研究表明,balancing the competing policy and value objective 可能会出现问题,这正是Phasic Policy Gradient等方法试图解决的问题(Cobbe 等人,2021)。
9. Scaling the Images to Range [0, 1] 【Environment Preprocessing】
输入数据的范围是 [0,255],但应该除以 255 后得到范围 [0,1]。
我们的实验发现这种扩展很重要。如果没有它,第一次策略更新会导致 Kullback-Leibler 散度爆炸,这可能是由于层的初始化方式造成的。
为了运行实验,我们按如下方式匹配原始实现中使用的超参数。
# https://github.com/openai/baselines/blob/master/baselines/ppo2/defaults.py
def atari():
return dict(
nsteps=128, nminibatches=4,
lam=0.95, gamma=0.99, noptepochs=4, log_interval=1,
ent_coef=.01,
lr=lambda f : f * 2.5e-4,
cliprange=0.1,
)
这些超参数是

请注意,环境数量参数 N(即 num_envs)被设置为计算机的 CPU 数量(common/cmd_util.py#L167),这很奇怪。我们选择与论文中使用的 N=8 相匹配(论文中将该参数设置为 “number of actors,8”)。
如下图所示,我们对 ppo.py 进行了约 40 行代码的修改,以纳入这 9 个细节,最终生成了一个独立的 ppo_atari.py(链接),其中包含 339 行代码。下图显示了 ppo.py(左)和 ppo_atari.py(右)的文件差异。请在原博客中查看。
