Kafka消费流程
Kafka消费流程
消息是如何被消费者消费掉的。其中最核心的有以下内容。
1、多线程安全问题
2、群组协调
3、分区再均衡
1.多线程安全问题
当多个线程访问某个类时,这个类始终都能表现出正确的行为,那么就称这个类是线程安全的。
对于线程安全,还可以进一步定义:
当多个线程访问某个类时,不管运行时环境采用何种调度方式或者这些线程将如何交替进行,并且在主调代码中不需要任何额外的同步或协同,这个类都能表现出正确的行为,那么就称这个类是线程安全的。
那么如何避免生产者和消费者的线程安全问题呢?
1.1 生产者
KafkaProducer的实现是线程安全的。
KafkaProducer就是一个不可变类。线程安全的,可以在多个线程中共享单个KafkaProducer实例
所有字段用private final修饰,且不提供任何修改方法,这种方式可以确保多线程安全。

如何节约资源的多线程使用KafkaProducer实例
import com.msb.selfserial.User;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 类说明:多线程下使用生产者
*/
public class KafkaConProducer {
//发送消息的个数
private static final int MSG_SIZE = 1000;
//负责发送消息的线程池
private static ExecutorService executorService = Executors.newFixedThreadPool(
Runtime.getRuntime().availableProcessors());
private static CountDownLatch countDownLatch = new CountDownLatch(MSG_SIZE);
private static User makeUser(int id){
User user = new User(id);
String userName = "llp_"+id;
user.setName(userName);
return user;
}
/*发送消息的任务*/
private static class ProduceWorker implements Runnable{
private ProducerRecord<String,String> record;
private KafkaProducer<String,String> producer;
public ProduceWorker(ProducerRecord<String, String> record, KafkaProducer<String, String> producer) {
this.record = record;
this.producer = producer;
}
public void run() {
final String ThreadName = Thread.currentThread().getName();
try {
producer.send(record, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(null!=exception){
exception.printStackTrace();
}
if(null!=metadata){
System.out.println(ThreadName+"|" +String.format("偏移量:%s,分区:%s", metadata.offset(),
metadata.partition()));
}
}
});
//执行countDown方法,代表一个任务结束,对计数器 - 1
countDownLatch.countDown();
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
// 设置属性
Properties properties = new Properties();
// 指定连接的kafka服务器的地址
properties.put("bootstrap.servers","127.0.0.1:9092");
// 设置String的序列化
properties.put("key.serializer", StringSerializer.class);
properties.put("value.serializer", StringSerializer.class);
// 构建kafka生产者对象
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
try {
for(int i=0;i<MSG_SIZE;i++){
User user = makeUser(i);
ProducerRecord<String,String> record = new ProducerRecord<String,String>("concurrent-ConsumerOffsets",null,
System.currentTimeMillis(), user.getId()+"", user.toString());
executorService.submit(new ProduceWorker(record,producer));
}
//执行await方法,代表等待计数器变为0时,再继续执行
countDownLatch.await();
System.out.println("生产者消息发送完毕");
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close();
executorService.shutdown();
}
}
}
1.2 消费者
KafkaConsumer的实现不是线程安全的
实现消费者多线程最常见的方式: 线程封闭 ——即为每个线程实例化一个 KafkaConsumer对象,各自消费分配的分区消息
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 类说明:多线程下正确的使用消费者,一个线程一个消费者
*/
public class KafkaConConsumer {
public static final int CONCURRENT_PARTITIONS_COUNT = 2;
private static ExecutorService executorService = Executors.newFixedThreadPool(CONCURRENT_PARTITIONS_COUNT);
private static class ConsumerWorker implements Runnable{
private KafkaConsumer<String,String> consumer;
public ConsumerWorker(Map<String, Object> config, String topic) {
Properties properties = new Properties();
properties.putAll(config);
//一个线程一个消费者
this.consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Collections.singletonList(topic));
}
public void run() {
final String ThreadName = Thread.currentThread().getName();
try {
while(true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for(ConsumerRecord<String, String> record:records){
System.out.println(ThreadName+"|"+String.format(
"主题:%s,分区:%d,偏移量:%d," +
"key:%s,value:%s",
record.topic(),record.partition(),
record.offset(),record.key(),record.value()));
//do our work
}
}
} finally {
consumer.close();
}
}
}
public static void main(String[] args) {
/*消费配置的实例*/
Map<String,Object> properties = new HashMap<String, Object>();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"127.0.0.1:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"c_test");
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
for(int i = 0; i<CONCURRENT_PARTITIONS_COUNT; i++){
//一个线程一个消费者
executorService.submit(new ConsumerWorker(properties, "concurrent-ConsumerOffsets"));
}
}
}
测试结果

2.群组协调
消费者要加入群组时,会向群组协调器发送一个JoinGroup请求,第一个加入群主的消费者成为群主,群主会获得群组的成员列表,并负责给每一个消费者分配分区。分配完毕后,群主把分配情况发送给群组协调器,协调器再把这些信息发送给所有的消费者,每个消费者只能看到自己的分配信息,只有群主知道群组里所有消费者的分配信息。群组协调的工作会在消费者发生变化(新加入或者掉线),主题中分区发生了变化(增加)时发生。

2.1组协调器
组协调器是Kafka服务端自身维护的。
组协调器( GroupCoordinator )可以理解为各个消费者协调器的一个中央处理器, 每个消费者的所有交互都是和组协调器( GroupCoordinator )进行的。
- 选举Leader消费者客户端
- 处理申请加入组的客户端
- 再平衡后同步新的分配方案
- 维护与客户端的心跳检测
- 管理消费者已消费偏移量,并存储至
__consumer_offset中
kafka上的组协调器( GroupCoordinator )协调器有很多,有多少个 __consumer_offset分区, 那么就有多少个组协调器( GroupCoordinator )
默认情况下, __consumer_offset有50个分区, 每个消费组都会对应其中的一个分区,对应的逻辑为 hash(group.id)%分区数。
2.2消费者协调器
每个客户端(消费者的客户端)都会有一个消费者协调器, 他的主要作用就是向组协调器发起请求做交互, 以及处理回调逻辑
- 向组协调器发起入组请求
- 向组协调器发起同步组请求(如果是Leader客户端,则还会计算分配策略数据放到入参传入)
- 发起离组请求
- 保持跟组协调器的心跳线程
- 向组协调器发送提交已消费偏移量的请求
2.3消费者加入分组的流程
1、客户端启动的时候, 或者重连的时候会发起JoinGroup的请求来申请加入的组中。
2、当前客户端都已经完成JoinGroup之后, 客户端会收到JoinGroup的回调, 然后客户端会再次向组协调器发起SyncGroup的请求来获取新的分配方案
3、当消费者客户端关机/异常 时, 会触发离组LeaveGroup请求。
当然有主动的消费者协调器发起离组请求,也有组协调器一直会有针对每个客户端的心跳检测, 如果监测失败,则就会将这个客户端踢出Group。
4、客户端加入组内后, 会一直保持一个心跳线程,来保持跟组协调器的一个感知。
并且组协调器会针对每个加入组的客户端做一个心跳监测,如果监测到过期, 则会将其踢出组内并再平衡。
2.4消费者消费的offset的存储
__consumer_offsets topic,并且默认提供了kafka_consumer_groups.sh脚本供用户查看consumer信息。
__consumer_offsets 是 kafka 自行创建的,和普通的 topic 相同。它存在的目的之一就是保存 consumer 提交的位移。
kafka-consumer-groups.bat --bootstrap-server :9092 --group c_test --describe

那么如何使用 kafka 提供的脚本查询某消费者组的元数据信息呢?
/**
* 类说明:如何根据消费分组找ConsumerOffsets文件
*/
public class ConsumerOffsets {
public static void main(String[] args) {
String groupID = "c_test";
// 4
System.out.println(Math.abs(groupID.hashCode()) % 50);
}
}
__consumer_offsets 的每条消息格式大致如图所示
可以想象成一个 KV 格式的消息,key 就是一个三元组:group.id+topic+分区号,而 value 就是 offset 的值
2.5分区再均衡
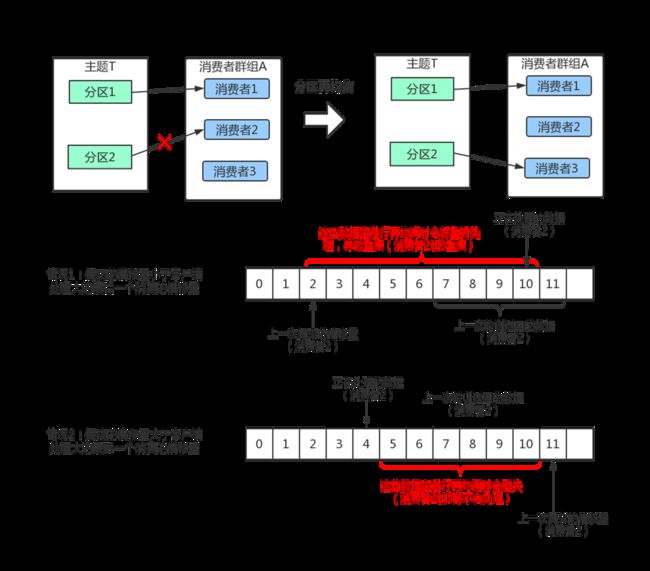
当消费者群组里的消费者发生变化,或者主题里的分区发生了变化,都会导致再均衡现象的发生。从前面的知识中,我们知道,Kafka中,存在着消费者对分区所有权的关系,
这样无论是消费者变化,比如增加了消费者,新消费者会读取原本由其他消费者读取的分区,消费者减少,原本由它负责的分区要由其他消费者来读取,增加了分区,哪个消费者来读取这个新增的分区,这些行为,都会导致分区所有权的变化,这种变化就被称为 再均衡 。
再均衡对Kafka很重要,这是消费者群组带来高可用性和伸缩性的关键所在。不过一般情况下,尽量减少再均衡,因为再均衡期间,消费者是无法读取消息的,会造成整个群组一小段时间的不可用。
消费者通过向称为群组协调器的broker(不同的群组有不同的协调器)发送心跳来维持它和群组的从属关系以及对分区的所有权关系。如果消费者长时间不发送心跳,群组协调器认为它已经死亡,就会触发一次再均衡。
心跳由单独的线程负责,相关的控制参数为max.poll.interval.ms。
2.6消费者提交偏移量导致的问题
当我们调用poll方法的时候,broker返回的是生产者写入Kafka但是还没有被消费者读取过的记录,消费者可以使用Kafka来追踪消息在分区里的位置,我们称之为 偏移量 。消费者更新自己读取到哪个消息的操作,我们称之为 提交 。
消费者是如何提交偏移量的呢?消费者会往一个叫做_consumer_offset的特殊主题发送一个消息,里面会包括每个分区的偏移量。发生了再均衡之后,消费者可能会被分配新的分区,为了能够继续工作,消费者者需要读取每个分区最后一次提交的偏移量,然后从指定的地方,继续做处理。
分区再均衡的例子:
某软件公司,有一个项目,有两块的工作,有两个码农,一个小王、一个小李,一个负责一块(分区消费),干得好好的。突然一天,小王桌子一拍不干了,老子中了5百万了,不跟你们玩了,立马收拾完电脑就走了。这个时候小李就必须承担两块工作,这个时候就是发生了分区再均衡。
过了几天,你入职,一个萝卜一个坑,你就入坑了,你承担了原来小王的工作。这个时候又会发生了分区再均衡。
1)如果提交的偏移量小于消费者实际处理的最后一个消息的偏移量,处于两个偏移量之间的消息会被重复处理,
2)如果提交的偏移量大于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息将会丢失
2.7 再均衡监听器示例
我们创建一个分区数是3的主题rebalance
kafka-topics.bat --bootstrap-server localhost:9092 --create --topic rebalance --replication-factor 1 --partitions 3

在为消费者分配新分区或移除旧分区时,可以通过消费者API执行一些应用程序代码,在调用 subscribe()方法时传进去一个 ConsumerRebalancelistener实例就可以了。
ConsumerRebalancelistener有两个需要实现的方法。
- public void
onPartitionsRevoked( Collection< TopicPartition> partitions)方法会在
再均衡开始之前和消费者停止读取消息之后被调用。如果在这里提交偏移量,下一个接管分区的消费者就知道该从哪里开始读取了
- public void
onPartitionsAssigned( Collection< TopicPartition> partitions)方法会在重新分配分区之后和消费者开始读取消息之前被调用。
具体使用,我们先创建一个3分区的主题,然后实验一下,
在再均衡开始之前会触发onPartitionsRevoked方法
在再均衡开始之后会触发onPartitionsAssigned方法
生产者
/**
* 类说明:多线程下使用生产者
*/
public class RebalanceProducer {
//发送消息的个数
private static final int MSG_SIZE = 50;
//负责发送消息的线程池
private static ExecutorService executorService = Executors.newFixedThreadPool(
Runtime.getRuntime().availableProcessors());
private static CountDownLatch countDownLatch = new CountDownLatch(MSG_SIZE);
private static User makeUser(int id){
User user = new User(id);
String userName = "llp_"+id;
user.setName(userName);
return user;
}
/*发送消息的任务*/
private static class ProduceWorker implements Runnable{
private ProducerRecord<String,String> record;
private KafkaProducer<String,String> producer;
public ProduceWorker(ProducerRecord<String, String> record, KafkaProducer<String, String> producer) {
this.record = record;
this.producer = producer;
}
public void run() {
final String ThreadName = Thread.currentThread().getName();
try {
producer.send(record, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(null!=exception){
exception.printStackTrace();
}
if(null!=metadata){
System.out.println(ThreadName+"|" +String.format("偏移量:%s,分区:%s", metadata.offset(),
metadata.partition()));
}
}
});
countDownLatch.countDown();
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
// 设置属性
Properties properties = new Properties();
// 指定连接的kafka服务器的地址
properties.put("bootstrap.servers","127.0.0.1:9092");
// 设置String的序列化
properties.put("key.serializer", StringSerializer.class);
properties.put("value.serializer", StringSerializer.class);
// 构建kafka生产者对象
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
try {
for(int i=0;i<MSG_SIZE;i++){
User user = makeUser(i);
ProducerRecord<String,String> record = new ProducerRecord<String,String>("rebalance",null,
System.currentTimeMillis(), user.getId()+"", user.toString());
executorService.submit(new RebalanceProducer.ProduceWorker(record,producer));
Thread.sleep(600);
}
countDownLatch.await();
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close();
executorService.shutdown();
}
}
}
消费者
/**
* 类说明:设置了再均衡监听器的消费者
*/
public class RebalanceConsumer {
public static final String GROUP_ID = "rebalance_consumer";
private static ExecutorService executorService = Executors.newFixedThreadPool(3);
public static void main(String[] args) throws InterruptedException {
//先启动两个消费者
new Thread(new ConsumerWorker(false)).start();
new Thread(new ConsumerWorker(false)).start();
Thread.sleep(5000);
//再启动一个消费,这个消费者 运行几次后就会停止消费
new Thread(new ConsumerWorker(true)).start();
//Thread.sleep(5000000);
}
}
/**
* 类说明:消费者任务
*/
public class ConsumerWorker implements Runnable{
private final KafkaConsumer<String,String> consumer;
/*用来保存每个消费者当前读取分区的偏移量*/
private final Map<TopicPartition, OffsetAndMetadata> currOffsets;
private final boolean isStop;
public ConsumerWorker(boolean isStop) {
// 设置属性
Properties properties = new Properties();
// 指定连接的kafka服务器的地址
properties.put("bootstrap.servers","127.0.0.1:9092");
// 设置String的反序列化
properties.put("key.deserializer", StringDeserializer.class);
properties.put("value.deserializer", StringDeserializer.class);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,RebalanceConsumer.GROUP_ID);
/*取消自动提交*/
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
this.isStop = isStop;
this.consumer = new KafkaConsumer<String, String>(properties);
//保存 每个分区的消费偏移量
this.currOffsets = new HashMap<TopicPartition, OffsetAndMetadata>();
System.out.println("consumer-hashcode:"+consumer.hashCode());
consumer.subscribe(Collections.singletonList("rebalance"), new HandlerRebalance(currOffsets,consumer));
}
public void run() {
final String id = Thread.currentThread().getId()+"";
int count = 0;
TopicPartition topicPartition = null;
long offset = 0;
try {
while(true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(500));
//业务处理
//开始事务
for(ConsumerRecord<String, String> record:records){
System.out.println(id+"|"+String.format(
"处理主题:%s,分区:%d,偏移量:%d," +
"key:%s,value:%s",
record.topic(),record.partition(),
record.offset(),record.key(),record.value()));
topicPartition = new TopicPartition(record.topic(), record.partition());
offset = record.offset()+1;
//获取偏移量
currOffsets.put(topicPartition,new OffsetAndMetadata(offset, "no"));
count++;
//执行业务sql
}
if(currOffsets.size()>0){
for(TopicPartition topicPartitionkey:currOffsets.keySet()){
HandlerRebalance.partitionOffsetMap.put(topicPartitionkey, currOffsets.get(topicPartitionkey).offset());
}
//提交事务,同时将业务和偏移量入库(使用HashMap替代)
}
if(isStop&&count>=5){ //监听线程
System.out.println(id+"-将关闭,当前偏移量为:"+currOffsets);
consumer.commitSync();
//跳出这个循环,最终执行finally中的关闭,此时消费者关闭
break;
}
consumer.commitSync();
}
} finally {
consumer.close();
}
}
}
在均衡监听器
/**
* 类说明:再均衡监听器
*/
public class HandlerRebalance implements ConsumerRebalanceListener {
/*模拟一个保存分区偏移量的数据库表*/
public final static ConcurrentHashMap<TopicPartition,Long>
partitionOffsetMap = new ConcurrentHashMap<TopicPartition,Long>();
private final Map<TopicPartition, OffsetAndMetadata> currOffsets;
private final KafkaConsumer<String,String> consumer;
//private final Transaction tr事务类的实例
public HandlerRebalance(Map<TopicPartition, OffsetAndMetadata> currOffsets,
KafkaConsumer<String, String> consumer) {
this.currOffsets = currOffsets;
this.consumer = consumer;
}
//分区再均衡之前
public void onPartitionsRevoked(
Collection<TopicPartition> partitions) {
final String id = Thread.currentThread().getId()+"";
System.out.println(id+"-onPartitionsRevoked参数值为:"+partitions);
System.out.println(id+"-服务器准备分区再均衡,提交偏移量。当前偏移量为:"
+currOffsets);
//我们可以不使用consumer.commitSync(currOffsets);
//提交偏移量到kafka,由我们自己维护*/
//开始事务
//偏移量写入数据库
System.out.println("分区偏移量表中:"+partitionOffsetMap);
for(TopicPartition topicPartition:partitions){
partitionOffsetMap.put(topicPartition, currOffsets.get(topicPartition).offset());
}
consumer.commitSync(currOffsets);
//提交业务数和偏移量入库 tr.commit
}
//分区再均衡完成以后
public void onPartitionsAssigned(
Collection<TopicPartition> partitions) {
final String id = Thread.currentThread().getId()+"";
System.out.println(id+"-再均衡完成,onPartitionsAssigned参数值为:"+partitions);
System.out.println("分区偏移量表中:"+partitionOffsetMap);
for(TopicPartition topicPartition:partitions){
System.out.println(id+"-topicPartition"+topicPartition);
//模拟从数据库中取得上次的偏移量
Long offset = partitionOffsetMap.get(topicPartition);
if(offset==null) continue;
consumer.seek(topicPartition,partitionOffsetMap.get(topicPartition));
}
}
}