MIT6.S081 2021
MIT6.S081 2021
- 环境配置
- Xv6 and Unix utilities
-
- vscode格式化头文件排序问题
- 以地址空间的视角看待变量
- 其他
- 代码参考
- system calls
-
- trace
- Sysinfo
- page tables
-
- Speed up system calls
- Print a page table
- Detecting which pages have been accessed
- traps
-
- RISC-V assembly
- Backtrace
- Alarm
- Copy-on-Write
- Multithreading
- networking
- locks
- file system
- mmap
个人主页:www.jiasun.top
界面比CSDN简洁一点,阅读体验更好,现已将全部博客迁移到个人主页,欢迎关注!
There is a saying in computer systems that any systems problem can be solved with a level of indirection.
6.S081 lab地址
推荐博客:二十八画生征友:一起来通关6.S081/6.828吧~
piazza课程主页:https://piazza.com/mooc_self-learning_university/fall2020/6s081
access code: 6s081
环境配置
虚拟机基本配置
下载Ubuntu镜像华为镜像站, 在software&update中修改软件源(我选的是阿里源)。
更新软件:apt-get update & apt-get upgrade
创建root用户 : sudo passwd root
安装open-vm-tools-desktop 支持宿主机 虚拟机之间复制粘贴
设置ssh远程登录及公钥登录登录
安装ssh相关服务
sudo apt-get install openssh-client openssh-server
修改ssh配置文件/etc/ssh/sshd_config
Port 22
PermitRootLogin yes
PubkeyAuthentication yes
PasswordAuthentication yes
将公钥添加到authorized_keys中
gedit pub # 复制粘贴宿主机公钥
mkdir ~/.ssh # 其中~为你想用公钥登录的用户目录,我直接在root用户下创建
cat pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
sudo service sshd restart
vscode远程登录
安装Remote-ssh插件-》点击左下角图标-》Connect to Host-》Configure SSH Hosts
新建一段为
Host 6.081
HostName 192.168.252.135
Port 22
User root
虚拟机IP地址,使用ifconfig查看
而后直接Connect to Host登录即可
安装实验工具
sudo apt-get install git build-essential gdb-multiarch qemu-system-misc gcc-riscv64-linux-gnu binutils-riscv64-linux-gnu
后面发现在云服务器上安装一下qemu就好了,没必要用VMware。。
vscode crtl + p快捷键被占用,修改crtl + p快捷方式
退出qemu两种方法:
- 在另一个终端中输入 killall qemu-system-arm(网上的方法,我试着不行,使用ps -A | grep qemu找到进程id,而后kill -9 pid杀死进程)
- 在 qemu 中 输入ctrl+a 抬起后,再输入’x’。
Xv6 and Unix utilities
vscode格式化头文件排序问题
由于设置了保存时自动格式化,保存时头文件会自动排序
#include "kernel/types.h"
#include "kernel/stat.h"
// 变成了
#include "kernel/types.h"
#include "kernel/stat.h"
// 使得stat.h中uint未声明
struct stat {
int dev; // File system's disk device
uint ino; // Inode number
short type; // Type of file
short nlink; // Number of links to file
uint64 size; // Size of file in bytes
};
解决:将Clang_format_sort Include改成false
以地址空间的视角看待变量
int number
res = read(read_fd, &number, 4);
// 等价于
char number[4]
res = read(read_fd, number, 4);

把普通的变量当作数组,很巧妙的视角。
其他
fmtname函数
ls.c中fmtname函数在末尾填充空格,find.c使用这个函数时需换成在末尾加上’\0’
warning:suggest parentheses around assignment used as truth value
while(res = func()){
}
// 改成
while((res = func())){
}
加一个括号括起来就可以了
a label can only be part of a statement and a declaration is not a statement
在写代码的时候,变量的声明不应该出现在label之后。中间加上大括号即可
case T_FILE:
int a;
break;
// 改成
case T_FILE:{
int a;
break;
}
xargs
char*
gets(char *buf, int max)
{
int i, cc;
char c;
for(i=0; i+1 < max; ){
cc = read(0, &c, 1);
if(cc < 1)
break;
buf[i++] = c;
if(c == '\n' || c == '\r')
break;
}
buf[i] = '\0';
return buf;
}
这个部分是耗时最久的,刚开始我没理解题目意思,一直打算按空格分割字符串,将其拆分成多行,使用strtok函数发现并没有提供,而动态数组也不知道咋申请,如果用定长的二维数组又觉得太奇怪,故一直卡在这了。后面发现原来将参数当成一行就行了。我又直接把系统gets函数拿来用,没有发现gets函数最后还是把’\n’放在字符串里面了,使得一直显示如下的错误。所以说与其抄系统的代码,不如自己写一个。
$ sh < xargstest.sh
$ $ $ $ $ $ ./a/b // 自己测试的输出
grep: cannot open ./a/b
./c/b // 自己测试的输出
grep: cannot open ./c/b
./b // 自己测试的输出
grep: cannot open ./b
我自己实现的gets函数如下,如果不设返回值,单以字符串第一位是否’\0’判断是否结束,则\n\n会被理解为结束,故设置返回值,当读到文件末尾时返回-1。
字符串长度为0且返回值为-1时表示参数读取完毕
int my_gets(char* buf, int max) { //读取字符串,读到文件末尾时返回-1
int i, cc;
char c;
int res = 0;
for (i = 0; i + 1 < max;) {
cc = read(0, &c, 1);
if (cc < 1) {
res = -1;
break;
}
if (c == '\n') break;
buf[i++] = c;
}
buf[i] = '\0';
return res;
}
通过截图
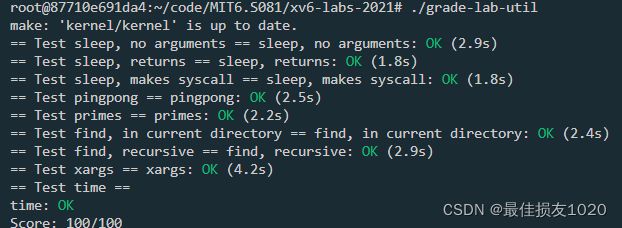
代码参考
sleep
Implement the UNIX program sleep for xv6; your sleep should pause for a user-specified number of ticks. A tick is a notion of time defined by the xv6 kernel, namely the time between two interrupts from the timer chip. Your solution should be in the file user/sleep.c.
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int main(int argc, char *argv[]) {
if (argc != 2) { // 参数格式不对
fprintf(2, "Usage: sleep ticks\n");
exit(1);
}
int ticks = atoi(argv[1]); // 将字符串转换成整数
int res = sleep(ticks);
if (res == -1) {
exit(-1);
}
exit(0);
}
pingpong
Write a program that uses UNIX system calls to ‘‘ping-pong’’ a byte between two processes over a pair of pipes, one for each direction. The parent should send a byte to the child; the child should print “: received ping”, where is its process ID, write the byte on the pipe to the parent, and exit; the parent should read the byte from the child, print “: received pong”, and exit. Your solution should be in the file user/pingpong.c.
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int main(int argc, char *argv[]) {
int p[2];
char msg = 'a';
char buf;
pipe(p);
if (fork() == 0) {
read(p[0], &buf, 1); // 读取字符
int pid = getpid();
fprintf(2, "%d: received ping\n", pid);
write(p[1], &buf, 1); // 向管道写入相同字符
close(p[0]); // 关闭读端
close(p[1]); // 关闭写端
exit(0);
} else {
write(p[1], &msg, 1); // 向管道写入字符
read(p[0], &buf, 1); // 读取字符
int pid = getpid();
fprintf(2, "%d: received pong\n", pid);
close(p[0]); // 关闭读端
close(p[1]); // 关闭写端
}
exit(0);
}
primes
Write a concurrent version of prime sieve using pipes. This idea is due to Doug McIlroy, inventor of Unix pipes. The picture halfway down this page and the surrounding text explain how to do it. Your solution should be in the file user/primes.c.
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
void func(int read_fd, int write_fd) {
close(write_fd);
int first_number;
int other_number;
// 读取第一个数字,作为素数
int res = read(read_fd, &first_number, 4);
if (res == 0) { // 管道关闭,立即退出进程
close(read_fd);
exit(-1);
} else {
int p[2];
pipe(p);
if (fork() == 0) { // 创建子进程
func(p[0], p[1]);
} else {
close(p[0]);
while (1) {
// 读取其他数字,若不被第一个数字整除,则传给子进程
res = read(read_fd, &other_number, 4);
// 管道关闭,输出第一个数字后等待子进程退出,下列语句的顺序很重要
if (res == 0) {
fprintf(2, "prime %d\n", first_number);
close(p[1]);
wait((int *)0);
exit(0);
} else {
if (other_number % first_number != 0) {
write(p[1], &other_number, 4);
}
}
}
}
}
}
int main(int argc, char *argv[]) {
int p[2];
pipe(p);
if (fork() == 0) {
func(p[0], p[1]);
} else {
close(p[0]);
for (int i = 2; i <= 35; i++) { // 将数字传给子进程
write(p[1], &i, 4);
}
close(p[1]);
wait((int *)0);
}
exit(0);
}
find
Write a simple version of the UNIX find program: find all the files in a directory tree with a specific name. Your solution should be in the file user/find.c.
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
char *fmtname(char *path) {
static char buf[DIRSIZ + 1];
char *p;
// Find first character after last slash.
for (p = path + strlen(path); p >= path && *p != '/'; p--)
;
p++;
uint name_len = strlen(p);
// Return blank-padded name.
if (name_len >= DIRSIZ) return p;
memmove(buf, p, strlen(p));
buf[name_len] = 0; // 末尾加上'\0'
return buf;
}
void find(char *path, char *target_filename) {
// printf("test1: %s %s\n", path, target_filename);
char buf[512], *p;
int fd;
struct dirent de;
struct stat st;
if ((fd = open(path, 0)) < 0) {
fprintf(2, "find: cannot open %s\n", path);
return;
}
if (fstat(fd, &st) < 0) {
fprintf(2, "find: cannot stat %s\n", path);
close(fd);
return;
}
switch (st.type) {
case T_FILE: {
char *filename = fmtname(path);
// printf("test2: %s\n", filename);
if (strcmp(filename, target_filename) == 0) {
printf("%s\n", path);
}
break;
}
case T_DIR:
if (strlen(path) + 1 + DIRSIZ + 1 > sizeof buf) {
printf("find: path too long\n");
break;
}
strcpy(buf, path);
p = buf + strlen(buf);
*p++ = '/';
while (read(fd, &de, sizeof(de)) == sizeof(de)) {
if (de.inum == 0) continue;
memmove(p, de.name, DIRSIZ);
p[DIRSIZ] = 0;
if (stat(buf, &st) < 0) {
printf("find: cannot stat %s\n", buf);
continue;
}
// 判断是否为.或..
if (strcmp(de.name, ".") != 0 && strcmp(de.name, "..") != 0) {
find(buf, target_filename);
}
}
break;
}
close(fd);
}
int main(int argc, char *argv[]) {
if (argc < 3) {
fprintf(2, "Usage: find path target_filename\n");
exit(1);
}
find(argv[1], argv[2]);
exit(0);
}
xargs
Write a simple version of the UNIX xargs program: read lines from the standard input and run a command for each line, supplying the line as arguments to the command. Your solution should be in the file user/xargs.c.
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#define MAX_EXTRA_ARG_LEN 100
int my_gets(char* buf, int max) { //读取字符串,读到文件末尾时返回-1
int i, cc;
char c;
int res = 0;
for (i = 0; i + 1 < max;) {
cc = read(0, &c, 1);
if (cc < 1) {
res = -1;
break;
}
if (c == '\n') break;
buf[i++] = c;
}
buf[i] = '\0';
return res;
}
int main(int argc, char* argv[]) {
char extra_args[MAX_EXTRA_ARG_LEN];
while (1) {
int res = my_gets(extra_args, MAX_EXTRA_ARG_LEN);
// 双重判断,避免\n\n的情况
if (extra_args[0] == '\0' && res == -1) {
break;
}
if (fork() == 0) {
// 此时argv[0]为xargs,需将参数整体往前移动一位
for (int i = 0; i < argc - 1; i++) {
argv[i] = argv[i + 1];
}
argv[argc - 1] = extra_args; // 设置额外参数
exec(argv[0], argv);
exit(0);
} else {
wait((int*)0);
}
}
exit(0);
}
system calls
trace
In this assignment you will add a system call tracing feature that may help you when debugging later labs. You’ll create a new trace system call that will control tracing. It should take one argument, an integer “mask”, whose bits specify which system calls to trace. For example, to trace the fork system call, a program calls trace(1 << SYS_fork), where SYS_fork is a syscall number from kernel/syscall.h. You have to modify the xv6 kernel to print out a line when each system call is about to return, if the system call’s number is set in the mask. The line should contain the process id, the name of the system call and the return value; you don’t need to print the system call arguments. The trace system call should enable tracing for the process that calls it and any children that it subsequently forks, but should not affect other processes.
trace调用过程
trace(atoi(argv[1]))->.global trace->syscall->sys_trace->syscall
首先在用户空间调用trace函数
#include "kernel/param.h"
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int
main(int argc, char *argv[])
{
int i;
char *nargv[MAXARG];
if(argc < 3 || (argv[1][0] < '0' || argv[1][0] > '9')){
fprintf(2, "Usage: %s mask command\n", argv[0]);
exit(1);
}
if (trace(atoi(argv[1])) < 0) {
fprintf(2, "%s: trace failed\n", argv[0]);
exit(1);
}
for(i = 2; i < argc && i < MAXARG; i++){
nargv[i-2] = argv[i];
}
exec(nargv[0], nargv);
exit(0);
}
在user/user.h文件中加入函数声明
int trace(int);
此时可以通过编译过程,只需链接时找到trace函数定义即可
trace函数定义如下:
在kernel/syscall.h中定义调用号
#define SYS_trace 22
usys.pl插入函数入口点
entry("trace");
usys.S生成代码片段
.global trace
trace:
li a7, SYS_trace # 将系统调用号存入a7中
ecall # 陷入内核,跳转到syscall函数
ret
内核函数调用流程
extern uint64 sys_trace(void); // sys_trace函数在别处定义
static uint64 (*syscalls[])(void) = {
[SYS_fork] sys_fork, [SYS_exit] sys_exit, [SYS_wait] sys_wait,
[SYS_pipe] sys_pipe, [SYS_read] sys_read, [SYS_kill] sys_kill,
[SYS_exec] sys_exec, [SYS_fstat] sys_fstat, [SYS_chdir] sys_chdir,
[SYS_dup] sys_dup, [SYS_getpid] sys_getpid, [SYS_sbrk] sys_sbrk,
[SYS_sleep] sys_sleep, [SYS_uptime] sys_uptime, [SYS_open] sys_open,
[SYS_write] sys_write, [SYS_mknod] sys_mknod, [SYS_unlink] sys_unlink,
[SYS_link] sys_link, [SYS_mkdir] sys_mkdir, [SYS_close] sys_close,
[SYS_trace] sys_trace,
}; // 增加一条[SYS_trace] sys_trace
static char *sys_call_names[] = {
[SYS_fork] "fork", [SYS_exit] "exit", [SYS_wait] "wait",
[SYS_pipe] "pipe", [SYS_read] "read", [SYS_kill] "kill",
[SYS_exec] "exec", [SYS_fstat] "fstat", [SYS_chdir] "chdir",
[SYS_dup] "dup", [SYS_getpid] "getpid", [SYS_sbrk] "sbrk",
[SYS_sleep] "sleep", [SYS_uptime] "uptime", [SYS_open] "open",
[SYS_write] "write", [SYS_mknod] "mknod", [SYS_unlink] "unlink",
[SYS_link] "link", [SYS_mkdir] "mkdir", [SYS_close] "close",
[SYS_trace] "trace",
}; // 系统调用对应的名字
void syscall(void) {
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if (num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num](); // 执行sys_trace()
int test_bit = p->trace_mask & (1 << num);
if (test_bit) {
printf("%d: syscall %s -> %d\n", p->pid, sys_call_names[num],
p->trapframe->a0);
}
} else {
printf("%d %s: unknown sys call %d\n", p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
sys_trace执行流程如下
static uint64 argraw(int n) { // 将系统调用参数存于各个寄存器
struct proc *p = myproc();
switch (n) {
case 0:
return p->trapframe->a0;
case 1:
return p->trapframe->a1;
case 2:
return p->trapframe->a2;
case 3:
return p->trapframe->a3;
case 4:
return p->trapframe->a4;
case 5:
return p->trapframe->a5;
}
panic("argraw");
return -1;
}
int argint(int n, int *ip) {
*ip = argraw(n);
return 0;
}
uint64 sys_trace(void) {
int mask;
if (argint(0, &mask) < 0) return -1; // 获取参数
myproc()->trace_mask = mask; // 设置trace_mask
return 0;
}
其中trace_mask为proc结构体成员,可以在allocproc函数中将trace_mask初始化为0(不一定需要)
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// wait_lock must be held when using this:
struct proc *parent; // Parent process
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
struct trapframe *trapframe; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
int trace_mask; // add trace mask
};
static struct proc *allocproc(void) {
struct proc *p;
for (p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if (p->state == UNUSED) {
goto found;
} else {
release(&p->lock);
}
}
return 0;
found:
p->pid = allocpid();
p->state = USED;
p->trace_mask = 0; // init trace_mask
// Allocate a trapframe page.
if ((p->trapframe = (struct trapframe *)kalloc()) == 0) {
freeproc(p);
release(&p->lock);
return 0;
}
// An empty user page table.
p->pagetable = proc_pagetable(p);
if (p->pagetable == 0) {
freeproc(p);
release(&p->lock);
return 0;
}
// Set up new context to start executing at forkret,
// which returns to user space.
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64)forkret;
p->context.sp = p->kstack + PGSIZE;
return p;
}
当进程创建子进程时,复制trace_mask
// Create a new process, copying the parent.
// Sets up child kernel stack to return as if from fork() system call.
int fork(void) {
int i, pid;
struct proc *np;
struct proc *p = myproc();
// Allocate process.
if ((np = allocproc()) == 0) {
return -1;
}
// Copy user memory from parent to child.
if (uvmcopy(p->pagetable, np->pagetable, p->sz) < 0) {
freeproc(np);
release(&np->lock);
return -1;
}
np->sz = p->sz;
// copy the trace mask from the parent to the child process.
np->trace_mask = p->trace_mask;
// copy saved user registers.
*(np->trapframe) = *(p->trapframe);
// Cause fork to return 0 in the child.
np->trapframe->a0 = 0;
// increment reference counts on open file descriptors.
for (i = 0; i < NOFILE; i++)
if (p->ofile[i]) np->ofile[i] = filedup(p->ofile[i]);
np->cwd = idup(p->cwd);
safestrcpy(np->name, p->name, sizeof(p->name));
pid = np->pid;
release(&np->lock);
acquire(&wait_lock);
np->parent = p;
release(&wait_lock);
acquire(&np->lock);
np->state = RUNNABLE;
release(&np->lock);
return pid;
}
接着看syscall函数
void syscall(void) {
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if (num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num](); // a0存储返回值
int test_bit = p->trace_mask & (1 << num); // 取出系统调用号相应位
if (test_bit) { // 如果不为0则输出系统调用相关信息
printf("%d: syscall %s -> %d\n", p->pid, sys_call_names[num],
p->trapframe->a0);
}
} else {
printf("%d %s: unknown sys call %d\n", p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
在测试trace时,总是出现超时的情况,显示MISSING ALL TESTS PASSED
修改gradelib.py中的timeout,将30改成100。测试通过!
def run_qemu(self, *monitors, **kw):
"""Run a QEMU-based test. monitors should functions that will
be called with this Runner instance once QEMU and GDB are
started. Typically, they should register callbacks that throw
TerminateTest when stop events occur. The target_base
argument gives the make target to run. The make_args argument
should be a list of additional arguments to pass to make. The
timeout argument bounds how long to run before returning."""
def run_qemu_kw(target_base="qemu", make_args=[], timeout=100):
return target_base, make_args, timeout
target_base, make_args, timeout = run_qemu_kw(**kw)
Sysinfo
In this assignment you will add a system call, sysinfo, that collects information about the running system. The system call takes one argument: a pointer to a struct sysinfo (see kernel/sysinfo.h). The kernel should fill out the fields of this struct: the freemem field should be set to the number of bytes of free memory, and the nproc field should be set to the number of processes whose state is not UNUSED. We provide a test program sysinfotest; you pass this assignment if it prints “sysinfotest: OK”.
sysinfo过程
// 在用户空间调用sysinfo
void sinfo(struct sysinfo *info) {
if (sysinfo(info) < 0) {
printf("FAIL: sysinfo failed");
exit(1);
}
}
user/user.h头文件中加入sysinfo声明
struct sysinfo;
int sysinfo(struct sysinfo*);
编译过程完成,链接时寻找sysinfo实际定义
kernel/syscall.h头文件插入系统调用号
#define SYS_sysinfo 23
usys.pl插入函数入口点
entry("sysinfo");
生成汇编代码:
.global sysinfo
sysinfo:
li a7, SYS_sysinfo
ecall
ret
内核函数调用过程
// syscall.c
extern uint64 sys_sysinfo(void); // 实际的系统调用函数,在sysproc.c中定义
static uint64 (*syscalls[])(void) = {
[SYS_fork] sys_fork, [SYS_exit] sys_exit, [SYS_wait] sys_wait,
[SYS_pipe] sys_pipe, [SYS_read] sys_read, [SYS_kill] sys_kill,
[SYS_exec] sys_exec, [SYS_fstat] sys_fstat, [SYS_chdir] sys_chdir,
[SYS_dup] sys_dup, [SYS_getpid] sys_getpid, [SYS_sbrk] sys_sbrk,
[SYS_sleep] sys_sleep, [SYS_uptime] sys_uptime, [SYS_open] sys_open,
[SYS_write] sys_write, [SYS_mknod] sys_mknod, [SYS_unlink] sys_unlink,
[SYS_link] sys_link, [SYS_mkdir] sys_mkdir, [SYS_close] sys_close,
[SYS_trace] sys_trace, [SYS_sysinfo] sys_sysinfo,
};
static char *sys_call_names[] = {
[SYS_fork] "fork", [SYS_exit] "exit", [SYS_wait] "wait",
[SYS_pipe] "pipe", [SYS_read] "read", [SYS_kill] "kill",
[SYS_exec] "exec", [SYS_fstat] "fstat", [SYS_chdir] "chdir",
[SYS_dup] "dup", [SYS_getpid] "getpid", [SYS_sbrk] "sbrk",
[SYS_sleep] "sleep", [SYS_uptime] "uptime", [SYS_open] "open",
[SYS_write] "write", [SYS_mknod] "mknod", [SYS_unlink] "unlink",
[SYS_link] "link", [SYS_mkdir] "mkdir", [SYS_close] "close",
[SYS_trace] "trace", [SYS_sysinfo] "sysinfo",
};
sys_sysinfo函数
// sysproc.c
#include "sysinfo.h" // 导入struct sysinfo结构体定义
uint64 sys_sysinfo(void) {
uint64 up_sysinfo; // user pointer to struct sysinfo
// 与trace调用中的argint类似,指针变量同样存储一个整数,只不过这个整数为另一个变量的地址
if (argaddr(0, &up_sysinfo) < 0) return -1;
struct sysinfo info;
info.freemem = free_memory_amount(); // 计算空余内存
info.nproc = live_process_number(); // 计算使用中的进程数
struct proc *p = myproc();
if (copyout(p->pagetable, up_sysinfo, (char *)&info, sizeof(info)) < 0)
return -1;
return 0;
}
两个统计函数的定义如下,研究同文件中其他函数可得
uint64 free_memory_amount(){
struct run *r;
uint64 cnt = 0;
acquire(&kmem.lock);
r = kmem.freelist;
while (r)
{
cnt++;
r = r->next;
}
release(&kmem.lock);
return cnt * PGSIZE;
}
uint64 live_process_number() {
uint64 cnt = 0;
struct proc *p;
for (p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if (p->state != UNUSED) {
cnt++;
}
release(&p->lock);
}
return cnt;
}
// 为了使用这两个函数,将其函数声明放在defs.h中
// kalloc.c
void* kalloc(void);
void kfree(void*);
void kinit(void);
uint64 free_memory_amount();
// proc.c
int cpuid(void);
void exit(int);
int fork(void);
int growproc(int);
void proc_mapstacks(pagetable_t);
pagetable_t proc_pagetable(struct proc*);
void proc_freepagetable(pagetable_t, uint64);
int kill(int);
struct cpu* mycpu(void);
struct cpu* getmycpu(void);
struct proc* myproc();
void procinit(void);
void scheduler(void) __attribute__((noreturn));
void sched(void);
void sleep(void*, struct spinlock*);
void userinit(void);
int wait(uint64);
void wakeup(void*);
void yield(void);
int either_copyout(int user_dst, uint64 dst, void* src, uint64 len);
int either_copyin(void* dst, int user_src, uint64 src, uint64 len);
void procdump(void);
uint64 live_process_number();
简单看一下copyout函数
#define PGROUNDDOWN(a) (((a)) & ~(PGSIZE-1))
// Copy from kernel to user.
// Copy len bytes from src to virtual address dstva in a given page table.
// Return 0 on success, -1 on error.
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
while(len > 0){
va0 = PGROUNDDOWN(dstva); // 获得逻辑页号
pa0 = walkaddr(pagetable, va0); // 逻辑页号转换成物理页号
if(pa0 == 0)
return -1;
n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
// pa0 物理页号 + dstva - va0 页内偏移地址 = 物理地址
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
测试通过截图
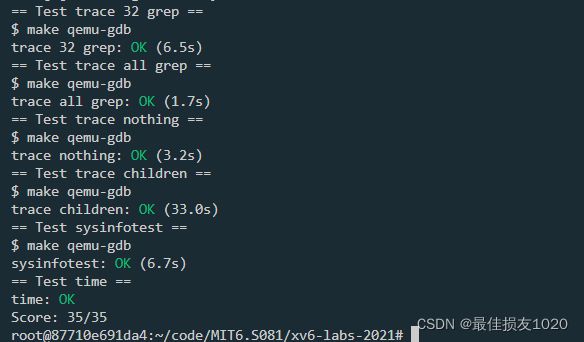
page tables
在做实验之前推荐阅读《深入理解linux内核》第一章,隔了很长时间重新写这个实验,之前看的xv6 book和代码全忘光了,但也懒得再看一遍了。
阅读xv6 book,最主要就是搞懂书中几张图的含义
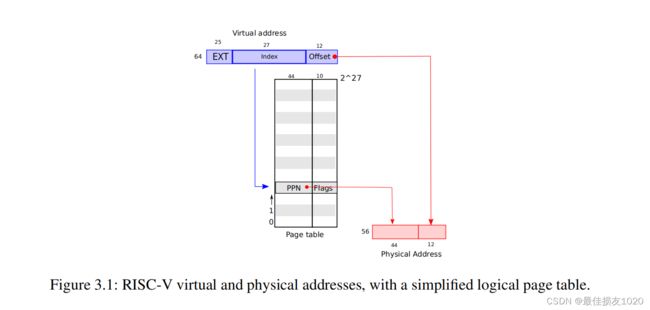
第一张图可以看出虚拟地址为64位,物理地址为56位,页大小为4kb
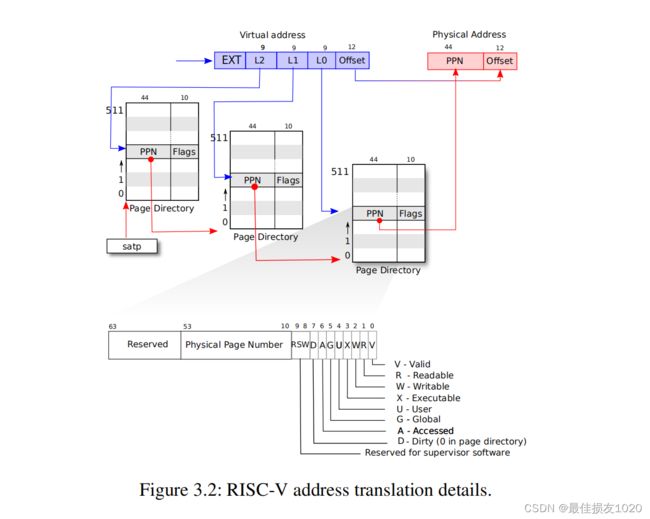
第二张图可以看出使用了3级页表,虚拟地址中使用39位用于寻址,其中27位用于页的寻址,12用作页偏移量。每一页表占用空间为一页(4KB),总共有512个表项,每一个表项占用8B(64位),其中10字节保留,44字节指向下一物理页,该物理页有可能是页表,有可能是存储真实数据的页,12位存储标志位。U代表用户态是否可以访问,X表示是否能以解释为指令执行,V表示是否有效,即是否发生缺页。
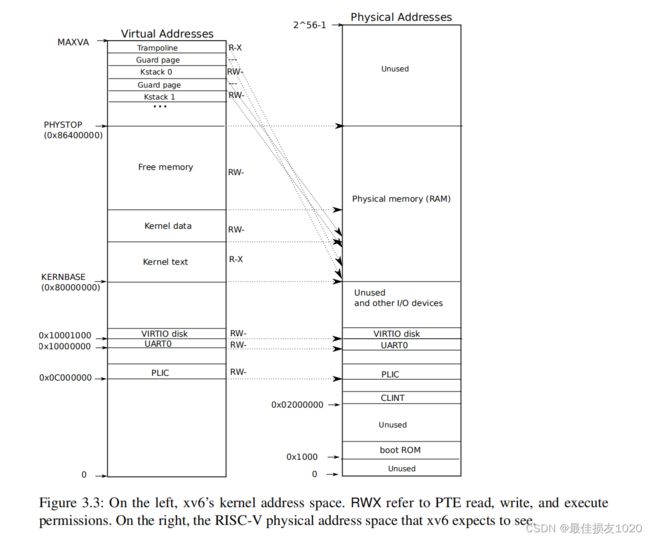
第三张图为内核地址空间与物理内存的映射关系,可以对照这张图阅读memlayout.h vm.c的代码
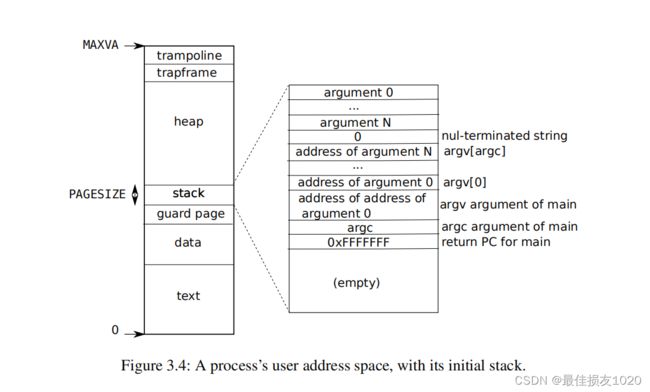
第四张图为用户地址空间分布,书中的其他内容我全忘了,毕竟是英文书籍。。。
大致阅读kern/vm.c代码,对walk mappages进行简要分析(页表的建立与查询)
要了解函数功能最快的方式就是看其最简单的分支
// Return the address of the PTE in page table pagetable
// that corresponds to virtual address va. If alloc!=0,
// create any required page-table pages.
//
// The risc-v Sv39 scheme has three levels of page-table
// pages. A page-table page contains 512 64-bit PTEs.
// A 64-bit virtual address is split into five fields:
// 39..63 -- must be zero.
// 30..38 -- 9 bits of level-2 index.
// 21..29 -- 9 bits of level-1 index.
// 12..20 -- 9 bits of level-0 index.
// 0..11 -- 12 bits of byte offset within the page.
pte_t *walk(pagetable_t pagetable, uint64 va, int alloc) {
if (va >= MAXVA) panic("walk");
for (int level = 2; level > 0; level--) {
pte_t *pte = &pagetable[PX(level, va)];
if (*pte & PTE_V) {
pagetable = (pagetable_t)PTE2PA(*pte);
} else {
if (!alloc || (pagetable = (pde_t *)kalloc()) == 0) return 0;
memset(pagetable, 0, PGSIZE);
*pte = PA2PTE(pagetable) | PTE_V;
}
}
return &pagetable[PX(0, va)];
}
简化版即为
pte_t *walk(pagetable_t pagetable, uint64 va, int alloc) {
for (int level = 2; level > 0; level--) {
pte_t *pte = &pagetable[PX(level, va)]; // 得到相应页表表项
if (*pte & PTE_V) {
pagetable = (pagetable_t)PTE2PA(*pte); // 将表项转换成物理页地址
}
}
return &pagetable[PX(0, va)]; // 返回0级页表的表项指针
}
// extract the three 9-bit page table indices from a virtual address.
#define PXMASK 0x1FF // 9 bits // 页表索引掩码
#define PXSHIFT(level) (PGSHIFT+(9*(level))) // 页表索引的位置
#define PX(level, va) ((((uint64) (va)) >> PXSHIFT(level)) & PXMASK) // 取出相应页表的索引并将其移动到低位
// shift a physical address to the right place for a PTE.
#define PA2PTE(pa) ((((uint64)pa) >> 12) << 10)
#define PTE2PA(pte) (((pte) >> 10) << 12) // 首先去除10位标志位,而后右移12位(页起始地址偏移量为0)
// Create PTEs for virtual addresses starting at va that refer to
// physical addresses starting at pa. va and size might not
// be page-aligned. Returns 0 on success, -1 if walk() couldn't
// allocate a needed page-table page.
int mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa,
int perm) {
uint64 a, last;
pte_t *pte;
if (size == 0) panic("mappages: size");
a = PGROUNDDOWN(va);
last = PGROUNDDOWN(va + size - 1);
for (;;) {
if ((pte = walk(pagetable, a, 1)) == 0) return -1;
if (*pte & PTE_V) panic("mappages: remap");
*pte = PA2PTE(pa) | perm | PTE_V;
if (a == last) break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}
简化后即为
int mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa,
int perm) {
uint64 a, last;
pte_t *pte;
a = PGROUNDDOWN(va); // 起始页
last = PGROUNDDOWN(va + size - 1); // 结束页
for (;;) { // 映射是以页的粒度
pte = walk(pagetable, a, 1); // 得到虚拟地址的页表表项指针
*pte = PA2PTE(pa) | perm | PTE_V; // 将该表项设为pa物理地址,建立映射关系,并设置标志位
if (a == last) break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}
#define PGROUNDDOWN(a) (((a)) & ~(PGSIZE-1)) // 将低12位置为0,即对页大小取整
正式进行实验,Speed up system calls 和 Print a page table是很久之前写的,不太记得了,如有遗漏的地方,望请告知!
Speed up system calls
When each process is created, map one read-only page at USYSCALL (a VA defined in memlayout.h). At the start of this page, store a struct usyscall (also defined in memlayout.h), and initialize it to store the PID of the current process. For this lab, ugetpid() has been provided on the userspace side and will automatically use the USYSCALL mapping. You will receive full credit for this part of the lab if the ugetpid test case passes when running pgtbltest.
int
ugetpid(void)
{
struct usyscall *u = (struct usyscall *)USYSCALL;
return u->pid;
}
#define USYSCALL (TRAPFRAME - PGSIZE)
// usyscall的实现对标trapframe,创建,注销的方法都与trapframe相似
struct proc {
struct trapframe *trapframe; // data page for trampoline.S
struct usyscall* usyscall; // 增加usyscall成员
};
// 比较对称的四个函数allocproc proc_pagetable freeproc proc_freepagetable
// Look in the process table for an UNUSED proc.
// If found, initialize state required to run in the kernel,
// and return with p->lock held.
// If there are no free procs, or a memory allocation fails, return 0.
static struct proc *allocproc(void) {
struct proc *p;
for (p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if (p->state == UNUSED) {
goto found;
} else {
release(&p->lock);
}
}
return 0;
found:
p->pid = allocpid();
p->state = USED;
// Allocate a trapframe page.
if ((p->trapframe = (struct trapframe *)kalloc()) == 0) {
freeproc(p);
release(&p->lock);
return 0;
}
// Allocate a usyscall page.
if ((p->usyscall = (struct usyscall *)kalloc()) == 0) {
freeproc(p);
release(&p->lock);
return 0;
}
// An empty user page table.
p->pagetable = proc_pagetable(p);
if (p->pagetable == 0) {
freeproc(p);
release(&p->lock);
return 0;
}
// Set up new context to start executing at forkret,
// which returns to user space.
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64)forkret;
p->context.sp = p->kstack + PGSIZE;
// init usyscall page
p->usyscall->pid = p->pid;
return p;
}
// Create a user page table for a given process,
// with no user memory, but with trampoline pages.
pagetable_t proc_pagetable(struct proc *p) {
pagetable_t pagetable;
// An empty page table.
pagetable = uvmcreate();
if (pagetable == 0) return 0;
// map the trampoline code (for system call return)
// at the highest user virtual address.
// only the supervisor uses it, on the way
// to/from user space, so not PTE_U.
if (mappages(pagetable, TRAMPOLINE, PGSIZE, (uint64)trampoline,
PTE_R | PTE_X) < 0) {
uvmfree(pagetable, 0);
return 0;
}
// map the trapframe just below TRAMPOLINE, for trampoline.S.
if (mappages(pagetable, TRAPFRAME, PGSIZE, (uint64)(p->trapframe),
PTE_R | PTE_W) < 0) {
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmfree(pagetable, 0);
return 0;
}
// map one read-only page at USYSCALL
if (mappages(pagetable, USYSCALL, PGSIZE, (uint64)(p->usyscall),
PTE_R | PTE_U) < 0) { // PTE_R | PTE_U 用户可以访问,可以读
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmunmap(pagetable, TRAPFRAME, 1, 0); // 取消之前的映射,这次映射未成功,不用取消
uvmfree(pagetable, 0);
return 0;
}
return pagetable;
}
// free a proc structure and the data hanging from it,
// including user pages.
// p->lock must be held.
static void freeproc(struct proc *p) {
if (p->trapframe) kfree((void *)p->trapframe);
p->trapframe = 0;
kfree((void *)p->usyscall);
p->usyscall = 0;
if (p->pagetable) proc_freepagetable(p->pagetable, p->sz);
p->pagetable = 0;
p->sz = 0;
p->pid = 0;
p->parent = 0;
p->name[0] = 0;
p->chan = 0;
p->killed = 0;
p->xstate = 0;
p->state = UNUSED;
}
// Free a process's page table, and free the
// physical memory it refers to.
void proc_freepagetable(pagetable_t pagetable, uint64 sz) {
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmunmap(pagetable, TRAPFRAME, 1, 0);
uvmunmap(pagetable, USYSCALL, 1, 0);
uvmfree(pagetable, sz);
}
Print a page table
Define a function called vmprint(). It should take a pagetable_t argument, and print that pagetable in the format described below. Insert if(p->pid==1) vmprint(p->pagetable) in exec.c just before the return argc, to print the first process’s page table. You receive full credit for this part of the lab if you pass the pte printout test of make grade.
// defs.h
void vmprint(pagetable_t pagetable);
// vm.c
void vmprint_impl(pagetable_t pagetable, int level)
{
// there are 2^9 = 512 PTEs in a page table.
for (int i = 0; i < 512; i++)
{
pte_t pte = pagetable[i];
pagetable_t next_pagetable = (pagetable_t)PTE2PA(pte);
if (pte & PTE_V) // 该页有效
{
for (int j = 2; j >= level; j--)
{
printf(" ..");
}
printf("%d: pte %p pa %p\n", i, pte, next_pagetable); // %p pointer 以十六进制整数方式输出指针的值
if ((pte & (PTE_R | PTE_W | PTE_X)) == 0) // 表示该表项指示的页存储着页表
{
vmprint_impl(next_pagetable, level - 1);
}
}
}
}
void vmprint(pagetable_t pagetable)
{
printf("page table %p\n", pagetable);
vmprint_impl(pagetable, 2);
}
//exec()
// print pid==1 info
if (p->pid == 1) vmprint(p->pagetable);
return argc; // this ends up in a0, the first argument to main(argc, argv)
其中pte & (PTE_R | PTE_W | PTE_X)) == 0让我挺疑惑的,为什么读写执行标志位全为0下一项就是页表呢。
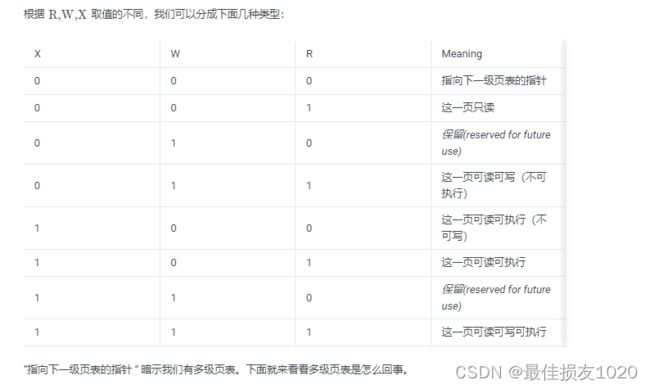
在lab2: 物理内存和页表中我找到了上表。
重新看walk函数代码
pte_t *walk(pagetable_t pagetable, uint64 va, int alloc)
{
if (va >= MAXVA)
panic("walk");
for (int level = 2; level > 0; level--)
{
pte_t *pte = &pagetable[PX(level, va)];
if (*pte & PTE_V)
{
pagetable = (pagetable_t)PTE2PA(*pte);
}
else
{
if (!alloc || (pagetable = (pde_t *)kalloc()) == 0)
return 0;
memset(pagetable, 0, PGSIZE);
*pte = PA2PTE(pagetable) | PTE_V;
}
}
return &pagetable[PX(0, va)];
}
*pte = PA2PTE(pagetable) | PTE_V;
// 表示该表项只有PTE_V置位,这表示指向页表的表项的R W X标志位确实全为0
Detecting which pages have been accessed
Your job is to implement pgaccess(), a system call that reports which pages have been accessed. The system call takes three arguments. First, it takes the starting virtual address of the first user page to check. Second, it takes the number of pages to check. Finally, it takes a user address to a buffer to store the results into a bitmask (a datastructure that uses one bit per page and where the first page corresponds to the least significant bit). You will receive full credit for this part of the lab if the pgaccess test case passes when running pgtbltest.
pgaccess系统调用的大部分代码已经写好了,只需要补全sys_pgaccess函数就可以。
系统调用路径为
// pgtbltest.c
if (pgaccess(buf, 32, &abits) < 0) // 调用pgaccess函数
// user.h
int pgaccess(void *base, int len, void *mask); // 函数声明
// syscall.h
#define SYS_pgaccess 30 // 定义调用号
// usys.S
pgaccess: // 函数入口
li a7, SYS_pgaccess
ecall
ret
// syscall.c
// 定义pgaccess内核函数原型
#ifdef LAB_PGTBL
extern uint64 sys_pgaccess(void);
#endif
static uint64 (*syscalls[])(void) = {
#ifdef LAB_PGTBL
[SYS_pgaccess] sys_pgaccess,
#endif
};
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num]();
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
// sysproc.c 函数实现
#ifdef LAB_PGTBL
int sys_pgaccess(void){
return 0;
}
#endif
sys_pgaccess函数比较简单,分为获取参数,查询PTE_A标志位并写入临时缓冲区,写入用户缓冲区三个部分。
可以参照walkaddr函数使用walk函数,获取调用参数和写入用户地址的方法与上一个实验类似。

查看手册可知PTE_A标志位在第六位
参考代码如下
// riscv.h
#define PTE_A (1L << 6)
// sysproc.c
#ifdef LAB_PGTBL
#define MAX_PGACCESS_PAGE_NUMBER 64 // 最大查询页数
int sys_pgaccess(void)
{
// lab pgtbl: your code here.
uint64 base;
int len;
uint64 mask;
// 获取参数
if (argaddr(0, &base) < 0)
return -1;
if (argint(1, &len) < 0)
return -1;
if (argaddr(2, &mask) < 0)
return -1;
len = len > MAX_PGACCESS_PAGE_NUMBER ? MAX_PGACCESS_PAGE_NUMBER : len;
uint64 tmp_buffer = 0; // 临时缓冲区
pagetable_t pagetable = myproc()->pagetable;
pte_t *pte;
for (int i = 0; i < len; i++)
{
pte = walk(pagetable, base + PGSIZE * i, 0);
// 如果页表项存在且PTE_A标志位置位
if (pte != 0 && (*pte & PTE_A) != 0)
{
tmp_buffer |= (1 << i);
*pte &= ~PTE_A; // 清空标志位
}
}
uint64 mask_size = (len - 1) / 8 + 1; // 写入用户空间的字节数,向上取整
if (copyout(pagetable, mask, (char *)&tmp_buffer, mask_size))
return -1;
return 0;
}
#endif
// defs.h
pte_t *walk(pagetable_t pagetable, uint64 va, int alloc);
编译时报错
kernel/sysproc.c:95:15: error: implicit declaration of function ‘walk’ [-Werror=implicit-function-declaration]
95 | pte = walk(pagetable, base + PGSIZE * i, 0);
| ^~~~
kernel/sysproc.c:95:13: error: assignment to ‘pte_t *’ {aka ‘long unsigned int *’} from ‘int’ makes pointer from integer without a cast [-Werror=int-conversion]
95 | pte = walk(pagetable, base + PGSIZE * i, 0);
排查后发现没有walk函数声明,在defs.h添加walk函数声明
usertests测试超时
Timeout! (300.3s)
== Test usertests: all tests ==
usertests: all tests: FAIL
...
test bigfile: OK
test dirfile: OK
test iref: OK
test forktest: OK
test bigdir: qemu-system-riscv64: terminating on signal 15 from pid 3652612 (make)
MISSING '^ALL TESTS PASSED$'
修改超时时间为1000
@test(0, "usertests")
def test_usertests():
r.run_qemu(shell_script([
'usertests'
]), timeout=1000)
测试通过截图
traps
- 在xv6书中,异常控制流的原因分为系统调用,设备中断,异常(故障),并将其统称为陷阱。
- xv6在内核中处理所有陷阱,不会移交给用户空间代码
- 对于陷阱处理,分为三种情况,分别是用户空间陷阱,内核空间陷阱,定时器中断
- 用户空间陷阱处理流程大致为uservec->usertrap->usertrapret->userret,简要看一下这四个函数,大部分代码是关于陷入前保存现场和内核处理后还原现场,有比较详尽的注释。
- 内核空间陷阱处理流程大致为kernelvec->kerneltrap->kernelvec
- trampoline page放置代码,trapframe page放置数据,这两页同时存在内核页表和进程页表中
- 系统调用:ecall指令陷入内核,执行uservec->usertrap->syscall,补全了之前分析的系统调用路径。
- 内核将物理地址直接映射成虚拟地址,故可以直接使用物理地址
- Xv6对异常的响应相当简单:如果在用户空间中发生异常,内核直接杀死该进程。如果在内核发生了异常,则中止内核。
- 如果将内核空间映射到进程页表,陷入内核空间就不需要切换页表,也可以直接使用用户空间指针,这也是现行操作系统采取的方式,但xv6为简化问题,使用单独的内核页表映射内核空间。参见内核页表学习记录
用户参数与寄存器对应代码
static uint64
argraw(int n)
{
struct proc *p = myproc();
switch (n) {
case 0:
return p->trapframe->a0;
case 1:
return p->trapframe->a1;
case 2:
return p->trapframe->a2;
case 3:
return p->trapframe->a3;
case 4:
return p->trapframe->a4;
case 5:
return p->trapframe->a5;
}
panic("argraw");
return -1;
}
RISC-V assembly
相关文章与书籍
聊聊 ARM 与 RISC-V
RISC-V手册(中科院翻译版)
只需要简单阅读即可,主要是看手册附录部分的指令列表

在附录A RISC-V 指令列表查询指令详细信息
一些用到的指令如下




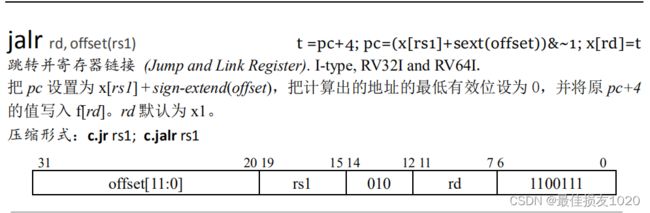

int g(int x) {
0: 1141 addi sp,sp,-16
2: e422 sd s0,8(sp)
4: 0800 addi s0,sp,16 // 保存寄存器的值
return x+3;
}
6: 250d addiw a0,a0,3 // a0寄存器既存参数,又存返回值
8: 6422 ld s0,8(sp)
a: 0141 addi sp,sp,16 // 还原寄存器的值
c: 8082 ret
000000000000000e <f>:
int f(int x) {
e: 1141 addi sp,sp,-16
10: e422 sd s0,8(sp)
12: 0800 addi s0,sp,16
return g(x);
}
14: 250d addiw a0,a0,3 // 编译器优化,进行了函数展开,即为x+3
16: 6422 ld s0,8(sp)
18: 0141 addi sp,sp,16
1a: 8082 ret
000000000000001c <main>:
void main(void) {
1c: 1141 addi sp,sp,-16
1e: e406 sd ra,8(sp)
20: e022 sd s0,0(sp)
22: 0800 addi s0,sp,16
printf("%d %d\n", f(8)+1, 13);
24: 4635 li a2,13
26: 45b1 li a1,12 // 编译期间提前进行计算,8+3+1
28: 00000517 auipc a0,0x0
2c: 7c050513 addi a0,a0,1984 # 7e8 <malloc+0xea> // 应该存储的是字符串"%d %d\n"的起始地址
30: 00000097 auipc ra,0x0
34: 610080e7 jalr 1552(ra) # 640 <printf>
exit(0);
38: 4501 li a0,0
3a: 00000097 auipc ra,0x0
3e: 27e080e7 jalr 638(ra) # 2b8 <exit>
Q1:
可以看出a0存放第一个参数,a1存放第二个参数,a2存放第三个参数,与argraw函数对应关系类似
Q2:
都进行了函数展开,在addiw a0,a0,3和li a1,12语句位置调用函数
Q3:
printf函数位于0x640的位置
Q4:
ra寄存器存放返回地址,即为0x38
后面的问题懒得看
Backtrace
Implement a backtrace() function in kernel/printf.c. Insert a call to this function in sys_sleep, and then run bttest, which calls sys_sleep. Your output should be as follows:
backtrace:
0x0000000080002cda
0x0000000080002bb6
0x0000000080002898
After bttest exit qemu. In your terminal: the addresses may be slightly different but if you run addr2line -e kernel/kernel (or riscv64-unknown-elf-addr2line -e kernel/kernel) and cut-and-paste the above addresses as follows:
$ addr2line -e kernel/kernel
0x0000000080002de2
0x0000000080002f4a
0x0000000080002bfc
Ctrl-D
You should see something like this:
kernel/sysproc.c:74
kernel/syscall.c:224
kernel/trap.c:85

Note that the return address lives at a fixed offset (-8) from the frame pointer of a stackframe, and that the saved frame pointer lives at fixed offset (-16) from the frame pointer.
这部分实验主要理清整数,地址,指针等类似概念,最好画一张示意图,便于理解。
参考代码如下
// defs.h
void backtrace(void);
// riscv.h
static inline uint64
r_fp()
{
uint64 x;
asm volatile("mv %0, s0" : "=r" (x) );
return x;
}
// printf.c
void backtrace(void)
{
printf("backtrace:\n");
uint64 *current_frame_pointer = (uint64 *)r_fp(); // 当前栈帧指针
uint64 *top_pointer = (uint64 *)PGROUNDUP((uint64)current_frame_pointer); // 页尾部
uint64 return_address;
for (uint64 *fp = current_frame_pointer; fp < top_pointer; fp = (uint64 *)(*(fp - 2)))
{
return_address = *(fp - 1); // 计算函数返回地址
printf("%p\n", return_address);
}
}
在sys_sleep函数插入backtrace
在panic函数插入backtrace(可选)
-1 -2是因为类型为uint64指针,一次加减8,相对于整数运算的-8 -16。
可以直接使用整数变量而不用指针变量,只在取值时强制转换为指针,但我觉得那样不好看。
Alarm
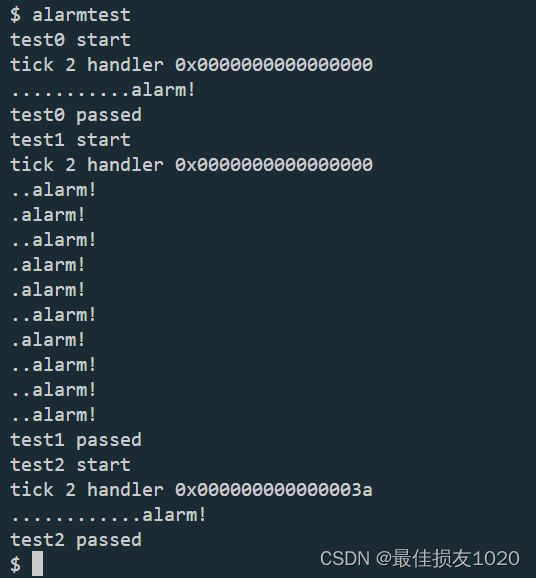
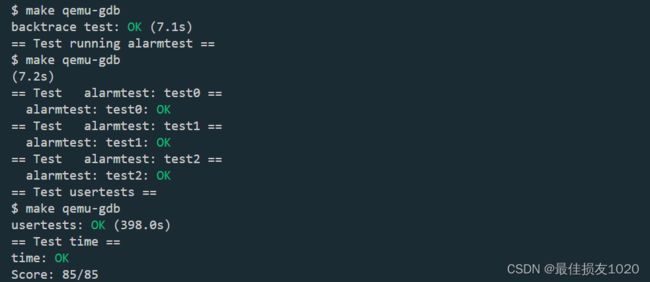
In this exercise you’ll add a feature to xv6 that periodically alerts a process as it uses CPU time. This might be useful for compute-bound processes that want to limit how much CPU time they chew up, or for processes that want to compute but also want to take some periodic action. More generally, you’ll be implementing a primitive form of user-level interrupt/fault handlers; you could use something similar to handle page faults in the application, for example. Your solution is correct if it passes alarmtest and usertests.
在这个部分我最主要错误的点是想在内核中执行用户空间的函数,而没有注意到epc(之前没认真看xv6 book),但让我奇怪的一点是handler作为一个函数指针竟然有时候是0(periodic()函数),奇怪,这个函数正好放在在0的位置吗?
没注意原来实验特地说明了这一点。。
Note that the address of the user’s alarm function might be 0 (e.g., in user/alarmtest.asm, periodic is at address 0).
// alarmtest.asm
0000000000000000 <periodic>:
}
volatile static int count;
void periodic()
依据系统调用路径编写sigalarm sigreturn系统调用
只展示相关代码
// 用户空间调用
void periodic()
{
count = count + 1;
printf("alarm!\n");
sigreturn(); // sigreturn系统调用
}
// tests whether the kernel calls
// the alarm handler even a single time.
void test0()
{
int i;
printf("test0 start\n");
count = 0;
sigalarm(2, periodic); // sigalarm系统调用
for (i = 0; i < 1000 * 500000; i++)
{
if ((i % 1000000) == 0)
write(2, ".", 1);
if (count > 0)
break;
}
sigalarm(0, 0);
if (count > 0)
{
printf("test0 passed\n");
}
else
{
printf("\ntest0 failed: the kernel never called the alarm handler\n");
}
}
// user.h 系统调用函数声明
int sigalarm(int ticks, void (*handler)());
int sigreturn(void);
// usys.pl 函数入口点
entry("sigalarm");
entry("sigreturn");
// syscall.h 系统调用号
#define SYS_sigalarm 22
#define SYS_sigreturn 23
// usys.S 最终生成的汇编代码
.global sigalarm
sigalarm:
li a7, SYS_sigalarm
ecall
ret
.global sigreturn
sigreturn:
li a7, SYS_sigreturn
ecall
ret
// syscall.c 内核的系统调用处理函数
extern uint64 sys_sigalarm(void);
extern uint64 sys_return(void);
static uint64 (*syscalls[])(void) = {
[SYS_sigalarm] sys_sigalarm,
[SYS_sigreturn ] sys_return,
};
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num]();
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
// sysproc.c 系统调用对应的处理函数
uint64 sys_sigalarm(void)
{
return 0;
}
uint64 sys_return(void)
{
return 0;
}
// Makefile 加入alarmtest对象
UPROGS=\
$U/_cat\
$U/_echo\
$U/_forktest\
$U/_grep\
$U/_init\
$U/_kill\
$U/_ln\
$U/_ls\
$U/_mkdir\
$U/_rm\
$U/_sh\
$U/_stressfs\
$U/_usertests\
$U/_grind\
$U/_wc\
$U/_zombie\
$U/_alarmtest\
首先获取ticks和handler参数是必要的,test0只需要将在特定时机将handler赋值给epc即可,test1需要保存执行handler前的进程现场,handler结束后还原现场,test2需保证在执行handler时不会再次触发alarm。
其大致实现如下
// proc.h
struct proc
{
int alarm_call_exist; // 是否存在alarm调用
int allow_trigger_alarm; // 是否允许触发alarm调用,如果现在正在处理handler函数,不能再次触发
int time_interval; // alarm间隔
uint64 handler_fn; // alarm调用函数
int elapsed_time; // 自上次调用起经历时间
struct trapframe alarm_saved_trapframe; // alarm调用前的trapframe
};
// proc.c
static struct proc *allocproc(void)
{
found:
p->alarm_call_exist = 0; // 设置成不需要触发alarm
p->allow_trigger_alarm = 0;
return p;
}
// sysproc.c
uint64 sys_sigalarm(void)
{
struct proc *p = myproc();
int ticks;
uint64 handler;
if (argint(0, &ticks) < 0) // 获取参数
return -1;
if (argaddr(1, &handler) < 0)
return -1;
if (ticks == 0) // 取消alarm调用
{
p->alarm_call_exist = 0;
return 0;
}
printf("tick %d handler %p\n", ticks, handler);
p->alarm_call_exist = 1; // 将两个标志变量均设置为有效
p->allow_trigger_alarm = 1;
p->time_interval = ticks;
p->handler_fn = handler;
p->elapsed_time = 0; // 开启计时器
return 0;
}
uint64 sys_return(void)
{
struct proc *p = myproc();
if (p->alarm_call_exist == 1) // 如果存在alarm调用
{
*p->trapframe = p->alarm_saved_trapframe; // 还原现场
p->allow_trigger_alarm = 1; // 允许触发alarm调用
}
return 0;
}
// trap.c
void usertrap(void)
{
// give up the CPU if this is a timer interrupt.
if (which_dev == 2)
{
if (p->alarm_call_exist == 1 && p->allow_trigger_alarm == 1)
{
p->elapsed_time++;
if (p->elapsed_time > p->time_interval) // 大于规定间隔时间
{
p->alarm_saved_trapframe = *p->trapframe; // 保存此时进程状态
p->trapframe->epc = p->handler_fn; // 返回地址设置为handler funtion
p->allow_trigger_alarm = 0; // handler function返回前不再触发
p->elapsed_time = 0; // 重置计时器
}
}
yield();
}
}
注意在代码中alarm调用指的是时钟中断时触发执行handler function的过程,而不是sigalarm系统调用,sigalarm系统调用更像是一个开启alarm触发机制的函数。当然这只是为了便于表述,实际上alarm调用只是时间中断的一个机制而已,并不是系统调用。
在之前我使用struct trapframe指针的形式存储alarm_saved_trapframe成员,并在allocproc函数中申请空间
类似于
if ((p->alarm_saved_trapframe= (struct trapframe *)kalloc()) == 0)
{
freeproc(p);
release(&p->lock);
return 0;
}
但忘了在freeproc中释放空间,导致usertests没有通过,后以结构体存储,通过了全部测试,当然使用指针存储并在freeproc中释放应该也可以,但kalloc申请一页的空间,还是有些浪费的。
测试通过截图
参考博客:MIT 6.S081 Lab4: traps
Copy-on-Write
MIT6.S081 2021 Copy-on-Write Fork for xv6
Multithreading
MIT6.S081 Multithreading
networking
MIT6.S081 2021 networking
locks
MIT6.S081 2021 locks
file system
MIT6.S081 2021 file system
mmap
MIT6.S081 2021 mmap