【架构】docker实现主从容错切换迁移【案例2/4】
实现主从容错切换迁移
在3主3从【案例1/4】的基础上,实现主从容错切换迁移,示意图如下:
一、数据读写存储
1、启动6机构成的集群并通过exec进入(任意一台都行):
docker exec -it redis-node-1 /bin/bash
2、对6381新增两个key
# 登陆任意redis(重点:此为单机登陆命令)
root@localhost:/data$ redis-cli -p 6381
# 查看数据,为空
127.0.0.1:6381> keys *
(empty array)
# 设置k1=v1 失败
127.0.0.1:6381> set k1 v1
(error) MOVED 12706 12.114.161.16:6383
# 设置k2=v2 、k3=v3 成功
127.0.0.1:6381> set k2 v2
OK
127.0.0.1:6381> set k3 v3
OK
# 设置k4=v4 失败
127.0.0.1:6381> set k4 v4
(error) MOVED 8455 12.114.161.16:6382
因为,总共有16384个槽位,平均分给3个主机,每个槽位段分别为16384/3个槽位。
所以报错原因是:登陆的第一台机器存储的槽位区间,无法存储k1和k4的值。【解决办法:见第3步】

3、集群的形式登陆【redis-cli -p 6381 -c】
登陆命令 redis-cli -p 6381 -c ,加入**-c**,代表以集群的形式登陆后,优化路由后,插入信息时,可根据哈希槽位进行自由切换。不再局限于某一台机器。
# 以集群的形式登陆(重点:此为集群登陆命令)
root@localhost:/data# redis-cli -p 6381 -c
127.0.0.1:6381> keys *
1) "k3"
2) "k2"
127.0.0.1:6381> set k1 v1
-> Redirected to slot [12706] located at 12.114.161.16:6383
OK
12.114.161.16:6383> # 已经切换到6383号机器
12.114.161.16:6383> set k4 v4
-> Redirected to slot [8455] located at 12.114.161.16:6382
OK
12.114.161.16:6382> # 已经切换到6382号机器
4、查看集群信息【redis-cli --cluster check ip地址:端口】
# 进入任意台节点机器
docker exec -it redis-node-1 /bin/bash
# 查看集群槽位信息
redis-cli --cluster check 12.114.161.16:6381
root@localhost:/data# redis-cli --cluster check 12.114.161.16:6381
# 该主机 数据值 | 哈希槽位数 | 从主机个数
12.114.161.16:6381 (6e961a47...) -> 2 keys | 5461 slots | 1 slaves.
12.114.161.16:6382 (f097fec9...) -> 1 keys | 5462 slots | 1 slaves.
12.114.161.16:6383 (78ac7be1...) -> 1 keys | 5461 slots | 1 slaves.
[OK] 4 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 12.114.161.16:6381)
M: 6e961a4765b555189708bebb69badf7dfad25cd5 12.114.161.16:6381
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 4ed46e0368698cd9d5af2ee84631c878b8ebc4d0 12.114.161.16:6386
slots: (0 slots) slave
replicates 6e961a4765b555189708bebb69badf7dfad25cd5
M: f097fec937f54d147d316c1c62e26cb67c9fd059 12.114.161.16:6382
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 0e34147ce2544cd90f5cce78d5493ae9e8625dfe 12.114.161.16:6384
slots: (0 slots) slave
replicates f097fec937f54d147d316c1c62e26cb67c9fd059
M: 78ac7be13522bd4ffd6fcf900c6c149c6938ecc2 12.114.161.16:6383
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 9bc2417a9cd6545ef2445eb4aa0610d586acd73b 12.114.161.16:6385
slots: (0 slots) slave
replicates 78ac7be13522bd4ffd6fcf900c6c149c6938ecc2
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
显示如下内容:
1、3台主机 、3台从机器的信息(id、端口、存储数据等)
2、每台主机的哈希槽位区间、和存取数值多少
二、容错切换迁移
选择任意一组“主从机器”,① 如果主机宕机后,从机是否后替补上;②如果宕机的主机再次恢复,是否会重新“夺回” 主主机地位,还是顺延作为“从机”?
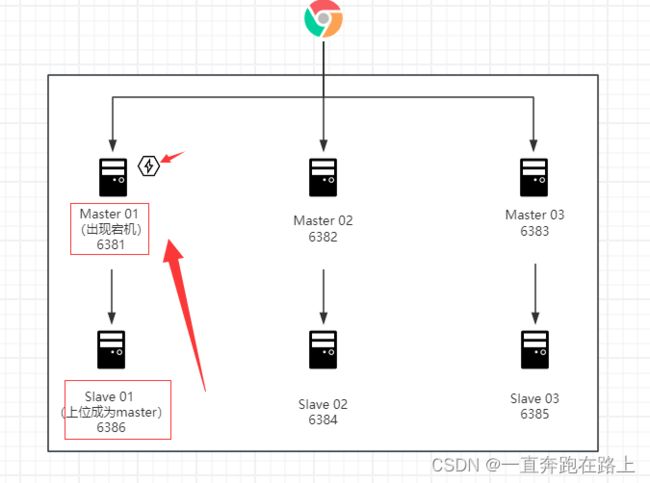
1、先停止主机redis-node-1,再次查看集群信息。命令:
# 停止主机redis-node-1
[root@localhost ~]# docker stop redis-node-1
redis-node-1
# 查看集群节点信息
12.114.161.16:6386> cluster nodes
12.114.161.16:6386> cluster nodes
f097fec937f54d147d316c1c62e26cb67c9fd059 12.114.161.16:6382@16382 master - 0 1705309024699 2 connected 5461-10922
78ac7be13522bd4ffd6fcf900c6c149c6938ecc2 12.114.161.16:6383@16383 master - 0 1705309023000 3 connected 10923-16383
6e961a4765b555189708bebb69badf7dfad25cd5 12.114.161.16:6381@16381 master,fail - 1705308720558 1705308717000 1 disconnected
0e34147ce2544cd90f5cce78d5493ae9e8625dfe 12.114.161.16:6384@16384 slave f097fec937f54d147d316c1c62e26cb67c9fd059 0 1705309024000 2 connected
4ed46e0368698cd9d5af2ee84631c878b8ebc4d0 12.114.161.16:6386@16386 myself,master - 0 1705309023000 7 connected 0-5460
9bc2417a9cd6545ef2445eb4aa0610d586acd73b 12.114.161.16:6385@16385 slave 78ac7be13522bd4ffd6fcf900c6c149c6938ecc2 0 1705309025703 3 connected
说明:
- 6381@16381 master,fail : 该主机(redis-node-1)为master,已宕机
- 6386@16386 myself,master :该主机(redis-node-6)顶替成为master
2、先还原之前的3主3从,再查看集群信息
# 停止主机redis-node-1
[root@localhost ~]# docker start redis-node-1
redis-node-1
# 查看集群节点信息
12.114.161.16:6386> cluster nodes
12.114.161.16:6386> cluster nodes
f097fec937f54d147d316c1c62e26cb67c9fd059 12.114.161.16:6382@16382 master - 0 1705309203416 2 connected 5461-10922
78ac7be13522bd4ffd6fcf900c6c149c6938ecc2 12.114.161.16:6383@16383 master - 0 1705309206000 3 connected 10923-16383
6e961a4765b555189708bebb69badf7dfad25cd5 12.114.161.16:6381@16381 slave 4ed46e0368698cd9d5af2ee84631c878b8ebc4d0 0 1705309205421 7 connected
0e34147ce2544cd90f5cce78d5493ae9e8625dfe 12.114.161.16:6384@16384 slave f097fec937f54d147d316c1c62e26cb67c9fd059 0 1705309207426 2 connected
4ed46e0368698cd9d5af2ee84631c878b8ebc4d0 12.114.161.16:6386@16386 myself,master - 0 1705309204000 7 connected 0-5460
9bc2417a9cd6545ef2445eb4aa0610d586acd73b 12.114.161.16:6385@16385 slave 78ac7be13522bd4ffd6fcf900c6c149c6938ecc2 0 1705309206422 3 connected
说明:
- 6381@16381 slave : 该主机(redis-node-1)虽然已经恢复,但沦为为slave从机器
- 6386@16386 myself,master:该主机(redis-node-6)没有变化,依然为master
总结:集群中,master主机宕机后,slave主机顶替上来,成为新master主机; 而且宕机的机器恢复后,将会成为slave机器