《数据结构与算法的C语言实现》数据结构篇(一)顺序表
目录
零,前言
一,线性表
二,顺序表
1,顺序表的概念
2,顺序表的实现
3,顺序表的增删查改
初始化
销毁
头删,头插
尾插,尾删
查找
插入
删除
修改
四,顺序表总结
零,前言
数据结构和算法是计算机的基础,他们的互相联系和作用就形成了程序。可以说,程序=算法+数据结构。因此我创建了《数据结构与算法的C语言实现》这一专栏,不仅为了之后自己的复习同时将自己的知识分享给大家。本专栏将着重于基础的数据结构的同时,拓展一些典型的基础算法,例如排序,枚举,双指针等。希望与大家多多交流。
本文主要介绍线性表中的顺序表与链表。
一,线性表
学习数据结构之前,我们应当了解线性表这个概念。线性表是一个总称不是某个具体的表,而是属于一个类别。
常见的线性表有顺序表,链表,队列等等。线性表在逻辑上是线性结构,是连续的,但是其结构不一定连续。例如链表,只是逻辑上的连续,其数据并不是紧挨着一个个存放的。
以下有一些线性表的例子:1)一个班级按照学号大小排列的列表。2)班级同学按照考试分数递减顺序排列的分数表。
对于任意的线性表,我们都可以执行以下操作:
1)创建一个线性表。 2)删除该线性表。 3)判断表中是否为空。 3)计算线性表有多少元素。4)通过某种索引查找表中元素。 5)通过索引删除表内的元素。6)在线性表中插入一个元素。 7)输出线性表中所有元素。 8)通过索引改变表内元素的值。
这些操作就是我们所听说的数据结构中的增删查改。我们所要在数据结构中学习的就是如何创建一个数据结构类型,以及如何实现该类型的增删查改。增删查改也是数据结构中的基础,能够熟练实现增删查改就能很轻松的学习数据结构中较难算法。
二,顺序表
1,顺序表的概念
顺序表是在一段连续的物理地址上依次存储元素的线性结构。顺序表的每个元素的地址在内存中都是依次连续的。也就是说,顺序表就是数组。
顺序表分为静态的顺序表和动态的顺序表。其两者差别为,静态的顺序表在一开始创建表时就已经规定了该表中能存储多少个元素,如果其存储元素达到最大容量则无法继续向其增加元素。而动态的顺序表由于通过malloc来动态开辟空间,如果达到最大容量可以再次开辟。因此动态顺序表中不会限制其最大容量。
由于静态顺序表和动态顺序表都差不多,因此本文着重介绍动态顺序表的实现。
顺序表在内存空间的结构如图:
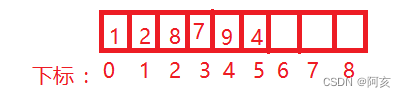
顺序表不是实际意义上的数组,元素可以在数组中指定下标存储。而顺序表中,元素只能依次连续存储,不能在中间留空的空间。
2,顺序表的实现
在C 语言中实现顺序表通常使用结构体:
typedef int DateType;//将int型重命名为DateType
typedef struct SeqList //将结构体这个关键字重命名为SeqList,便于后面的操作
{
SLDateType* a;
int size; //表中数据个数
int capacity;//表的最大容量
}SL;结构体中包含有首元素地址,数据个数和最大容量,实现完顺序表接下来要实现增删查改具体操作。
3,顺序表的增删查改
初始化
对于每个表,我们都要进行表的初始化,否则表中的整型是随机值并且不会开辟空间。
由于是动态开辟内存,因此初始化时我们要用malloc
void SLInit(SL* psl)
{
assert(psl);
psl->a = (SLDateType*)malloc(sizeof(SLDateType)*4) //先给顺序表创建四个空间,每个空间大小是一个顺序表的大小
psl->capacity = psl->size = 0;//容量和数据个数初始化为0
}注意代码段中的assert叫断言,如果assert内的值为空程序终止。assert在之后的程序里会非常常见。我们一般会在程序内不可能为空的指针p上运用:assert(指针p)防止p万一为空时导致最后程序的崩溃。能快速报错。
我们如果将其改为
void SLInit(SL p)
{
assert(psl);
p.a = NULL;
p.capacity = p.size = 0;
}这是错误的。因为在函数中的传值传参后只是改变其在栈空间的值,函数结束后栈空间就被销毁,无法影响其本身的值。因此要将结构体的地址传入,通过指针解引用来改变结构体内的值。
销毁
既然初始化了顺序表必然有顺序表的销毁,将内存还给操作空间。
void SLDestroy(const SL* psl)
{
assert(psl);//此时要防止其为空指针,否则下面free的时候会报错
free(psl);//用free释放动态空间
psl = NULL;//使指针指向空
}头删,头插
顾名思义将首地址上的元素删去。
进行头删和头插都要进行判断。判断表中数据是否为空以及判断表中元素是否达到最大容量
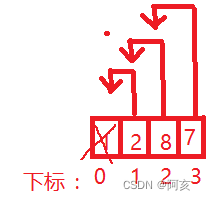 删去后,需要将后面的元素全部向前移一位。
删去后,需要将后面的元素全部向前移一位。
头删
void SLPopFront(SL* psl)
{
assert(psl);
int i = 0;
for (i = 0; i < psl->size - 1; i++)
{
psl->a[i] = psl->a[i + 1];//遍历全部元素,从前向后向前移一位
}
psl->size--;//数据数目减1
}
头插
相反,头插需要将头插后所有元素向后移一位。插入前,需要判断元素是否达到最大容量,否则需要扩容。
void SLPushFront(SL* psl, SLDateType x)
{
assert(psl);
if(psl->capacity == psl->size) //判断是否扩容
{
int newcapacity = psl->capacity ==0 ?4:psl->capacity*2;//如果表中空间为0则将空间扩大为4,如果表中原来就有空间则每次扩容扩两倍
SLDataType*temp = (SLDataType*) realloc(psl->a,newcapacity*sizeof(SLDatatype));
if(temp ==NULL) //判断扩容是否失败
{
perror("realloc fail");
return; //报错并结束程序
}
else
psl->a = temp;
}
int end = ps->size-1;
//将数据整体向后移动一位
while (end > 0)
{
ps->a[end+1] = ps->a[end]; //从后往前挪动
end--;
}
ps->a[0] = x;
ps->size++; //数据个数加一
}
为什么扩容扩二倍?因为
如果一次扩多了,会造成空间的浪费
扩的少了就需要频繁扩容,降低了程序的效率。
因此综合两种情况,扩成原来的二倍是比较合理的。
注意,realloc函数扩容有三种可能性。1)在原有空间的位置后增加空间。2)创建新的空间,其空间大小是扩容后空间的大小。3)没有这么多空间,扩容失败,返回一个空指针。 所以为了防止扩容失败导致原来的指针变为空指针,我们要先创建一个临时变量储存扩容后的指针,如果扩容成功才将该指针赋值给原指针。
尾插,尾删
将元素插入到首元素的地址以及将元素插入到尾部地址,尾插和尾删均不需要挪动数据。
尾插
void SLPushBack(SL*psl,SLDataType x)
{
assert(psl);
if(psl->capacity == psl->size) //判断是否扩容
{
int newcapacity = psl->capacity ==0 ?4:psl->capacity*2;
SLDataType*temp = (SLDataType*) realloc(psl->a,newcapacity*sizeof(SLDatatype));
if(temp ==NULL)
{
perror("realloc fail");
return; //报错并结束程序
}
else
psl->a = temp;
}
psl->capacity =newcapacity;
psl->a[psl->size] = x ;
psl->size++;
}尾删
void SLPopBack(SL* psl)
{
assert(psl);
assert(psl->size > 0); //判断表内元素是否为0,防止程序出现问题。
psl->size--; //数据个数减一
}查找
例如,给你一个元素x,要求查找该元素的下标
int SLFind(SL* psl,SLDataType x)
{
assert(psl);
for(int i = 0; isize;i++)//遍历所有元素
{
if( psl[i] = x)
return i;
}
return -1;//没有找到就返回-1
} 插入
给定一个下标,要求在该下标插入一个元素x。
void SLInsert(SL* psl,int pos, SLDataType x)
{
assert(psl);
assert(psl < psl->size); //既然是插入,所以我们要保证插入的下标两边都有元素。
int end = psl->size - 1;
while (end >= pos)
{
psl->a[end + 1] = psl->a[end];
end--;
}
psl->a[pos] = x;
psl->size++;
}删除
给定一个下标,删除该下标下对应的元素。
void SLErase(SL* psl, size_t pos)
{
assert(psl);
assert(pos < psl->size); //保证在该下标下存在元素
while (pos < psl->size - 1)
{
psl->a[pos] = psl->a[pos + 1];
pos++;
}
psl->size--;
}
修改
给定一个下标和修改后的值,将该下标下元素修改为修改后的值。
void SLModify(SL* psl, size_t pos, SLDateType x)
{
assert(psl);
assert(pos < psl->size);
psl->a[pos] = x;
}四,顺序表总结
实际上顺序表的一些功能实在差强人意,头插,头删和查找需要遍历所有数据,将其移位。若数据量较大时会导致其时间复杂度也较大。但其优势是在元素中间插入操作的时间复杂度是O(1),较为简便。
如何优化顺序表的查找算法?下一篇文章将会介绍二分查找。