6.1810: Operating System Engineering 2023 <Lab7 lock: Parallelism/locking>
一、本节任务



二、要点
2.1 文件系统(file system)
xv6 文件系统软件层次如下:
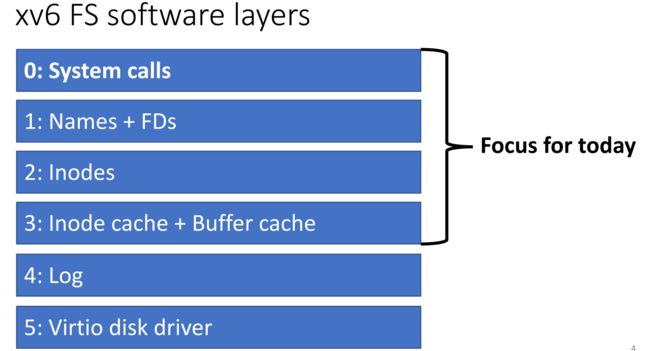
通过路径树我们可以找到相应的文件:

fd(文件描述符)是进程用来标识其打开的文件的手段,每个进程有自己的文件打开表,并且系统会维护一个全局文件打开表(系统中所有打开的文件都保存在这个全局文件打开表中)。

进程通过 fd 将文件作为一系列字节来访问,每一个 fd 都有一个光标(cursor)来指向文件的当前访问位置:

read() 和 write() 系统调用都会使光标前进:

也有一些特殊的文件,比如 pipe() 创建出来的缓冲区,其本质是一个文件,不同的进程使用 fd 对缓冲区文件进行读和写,从而实现进程间的通信:

inode(index node)索引节点用来记录一个文件的详细信息,包括:
- 记录文件的大小以及数据在磁盘上的存储位置;
- 记录文件的硬链接数量(和打开 fd 数量);
inode 可以是指磁盘上的 inode,也可能指内存上的 inode 副本(读写 inode 时会先将其读入内存中)。磁盘上的 inode 被打包到一个称为 inode 块的相邻磁盘区域中,每个 inode 大小都一样,所以通过一个索引 i 能很容易找到相应的索引节点,这个索引 i 也被称为 i-number 或 inode number。

address1~12 为直接索引,指向的为数据块,而 indrect 为间接索引,指向的为 indirect block,indirect block 里面的地址才指向数据块,这种方式可以增加文件的最大大小,并且减少 dinode 结构体的大小。

数据存储的位置?



磁盘访问是十分低效的,我们可以将 RAM 的一部分作为磁盘的 cache,每次访问磁盘会将连续的部分内容复制到 RAM 上,当再次访问的时候就不需要去访问磁盘,而是访问复制到 RAM 上的内容即可,其替换策略为 LRU(least recently used)。buffer cache 有两个作用:
- 同步对磁盘块的访问,以确保只有一个块的副本在内存中,并且一次只有一个内核线程使用该副本;
- 缓存常用的块,以便不需要从慢速磁盘上重新读取它们。
相关代码在 bio.c 中,其中主要的接口为 bread() 和 bwrite():
- bread():获取一个能在内存中读写的磁盘块的副本,使用 buf(buf.h)结构体来管理这个副本;
- bwrite():后者将修改后的缓冲区写入磁盘上的对应块;
- brelse():内核线程在使用完后这块缓冲区后需要使用 brelse() 来释放它;

磁盘布局:


xv6 文件系统在磁盘上的结构如下图。xv6将磁盘划分为几个部分,文件系统不使用 block0(它用来保存引导扇区)。block1 称为超级块(superblock),它包含有关文件系统的元数据(如块中的文件系统大小、数据块的数量、inode 的数量和 log 中的块数)。从 block2 开始的块保持 log,log 之后是 inodes,每个块有多个 inode。在这些之后,位图(bitmap)块跟踪数据库的使用情况。其余的块是数据块,每个块要么在 bitmap 中标记为空闲,要么保存文件或目录的内容。超级块由一个称为 mkfs 的单独程序填充,该程序构建一个初始文件系统。

Loging layer 可以帮助我们实现崩溃恢复(crash recovery)。出现这个问题的原因是,许多文件系统操作涉及对磁盘的多次写入操作,在某个写入操作后的崩溃可能会使磁盘上的文件系统处于不一致的状态。根据磁盘写入的顺序,崩溃可能会使 inode 留下对标记为 free 的块的引用(os 可能会将该 free 块分配给其他文件,这样就导致有两个文件共享同一个块,可能会导致严重的安全问题),也可能会留下已分配但未被引用的块。
xv6 通过一种简单的日志记录形式解决了文件系统操作过程中的崩溃问题。xv6 系统调用不会直接写磁盘上的文件系统数据结构,相反,它在磁盘上的日志中写入了它希望进行的所有磁盘写操作的描述,一旦系统调用在日志中记录了它所有的写入操作,它就会将一个特殊的提交记录写入磁盘,这表明该日志中包含了一个完整的操作。此时,系统调用才开始执行写磁盘上的文件系统数据结构操作。在这些写入操作完成之后,系统调用再将磁盘上的此次日志删除。
如果系统崩溃并重新启动,则文件系统代码将从崩溃中恢复。如果日志被标记为包含完整操作,则恢复代码将写入复制到磁盘文件系统中所属的位置。如果日志未标记为包含完整的操作,则恢复代码将忽略该日志。最后恢复代码再将日志删除。 所以,logging layer 能保证写操作要么执行完,要么不执行,避免出现数据不一致的情况。
系统调用一开始只会写 buffer cache, 而不是磁盘。
当系统调用完成后 —— commit:
- 将所有的更新的块写到磁盘的 log 上(在 log 上保存了更新块的副本);
- 将磁盘上的 log 设置为 committed;
- 然后再将更新的块写到要写的位置;
- 删除 log 上的记录;
当崩溃发生,reboot 后:
如果 log 被设置为 committed,将更新的块从磁盘的 log 上写到要写的位置。
三、Lab lock: Parallelism/locking
在多核机器上,锁的争用使得其性能变差,在本实验中,我们会重新设计部分代码以增加并行性。提高并行性通常需要改变数据结构和锁定策略,以减少争用。
3.1 Memory allocator (moderate)
这部分需要为每个 CPU 维护一个 freelist(kernel/kalloc.c),每个 freelist 都有自己的锁。不同 CPU 上的分配和释放可以并行运行,因为每个 CPU 将对不同的 freelist 进行操作。当一个 CPU 上的 freelist 为空,而另外一个 CPU 的 freelist 还有空闲页面时,没有空闲页面的 CPU 必须 “窃取” 另一个 CPU 的 freelist 的一部分。窃取可能会引入锁争用,但争用频率要比单个 freelist 要小很多。
首先将 kmem 变成一个数组,大小为 CPU 的个数:
struct {
struct spinlock lock;
struct run *freelist;
} kmem[NCPU];在 kinit() 函数中初始化每个结构体的锁:
void
kinit()
{
for(int i = 0; i < NCPU; i++)
{
char name[9] = {0};
snprintf(name, 8, "kmem-%d", i);
initlock(&kmem[i].lock, "kmem");
}
freerange(end, (void*)PHYSTOP);
}
使用 kfree() 来释放的页面,要注意释放的页面放到当前 CPU 的 freelist 中:
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
push_off();
int id = cpuid();
acquire(&kmem[id].lock);
r->next = kmem[id].freelist;
kmem[id].freelist = r;
release(&kmem[id].lock);
pop_off();
}
使用 kalloc() 分配页面时,需要注意的情况就是当前 CPU 的 freelist 里面没有空页面可用,这时候需要去其他 CPU 的 freelist 偷一个页面过来:
static struct run *steal_free_block(int id)
{
struct run *p = 0;
for(int i = 0; i < NCPU; i++)
{
if(i != id)
{
acquire(&kmem[i].lock);
p = kmem[i].freelist;
if(p)
{
kmem[i].freelist = p->next;
p->next = 0;
release(&kmem[i].lock);
break;
}
release(&kmem[i].lock);
}
}
return p;
}
void *
kalloc(void)
{
struct run *r;
push_off();
int id = cpuid();
acquire(&kmem[id].lock);
r = kmem[id].freelist;
if(r)
{
kmem[id].freelist = r->next;
}
release(&kmem[id].lock);
if(!r)
{
r = steal_free_block(id);
}
pop_off();
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
3.2 Buffer cache (hard)
在 kenel/bio.c 中的 bcache 结构体中的 lock 的竞争十分激烈,每次访问 bcache 结构体都需要请求这个锁,所以需要我们使用一些策略来减少竞争。
首先是 bcache 结构体需要使用 hash 桶 buf_table 来装入不同 blockno 的块,每个桶对应一个 lock:
#define NBUCKET 13
struct {
struct spinlock lock[NBUCKET];
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
//struct buf head;
struct buf buf_table[NBUCKET];
} bcache;初始化每个桶和每个桶对应的锁:
void
binit(void)
{
struct buf *b;
for(int i = 0; i < NBUCKET; i++){
char name[9] = {0};
snprintf(name, 8, "bcache-%d", i);
initlock(&bcache.lock[i], name);
bcache.buf_table[i].prev = &bcache.buf_table[i];
bcache.buf_table[i].next = &bcache.buf_table[i];
}
int i;
for(i = 0,b = bcache.buf; i < NBUF && b < bcache.buf+NBUF; i++,b++){
int index = i % NBUCKET;
b->next = bcache.buf_table[index].next;
b->prev = &bcache.buf_table[index];
initsleeplock(&b->lock, "buffer");
bcache.buf_table[index].next->prev = b;
bcache.buf_table[index].next = b;
}
}
bget 函数会先根据 blockno 找到对应的 hash 桶,若块已被缓存到对应的桶中,则直接返回,若不存在则循环遍历各个桶找到空闲的块(b->refcnt == 0),若该块在其他桶中,则需要把该块放到当前 blockno 对应的桶中:
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
int index = blockno % NBUCKET;
acquire(&bcache.lock[index]);
// Is the block already cached?
for(b = bcache.buf_table[index].next; b != &bcache.buf_table[index]; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.lock[index]);
acquiresleep(&b->lock);
return b;
}
}
release(&bcache.lock[index]);
for(int i = index; ; i = (i+1) % NBUCKET){
acquire(&bcache.lock[i]);
for(b = bcache.buf_table[i].next; b != &bcache.buf_table[i]; b = b->next){
if(b->refcnt == 0) {
// change bucket
if(i != index){
b->next->prev = b->prev;
b->prev->next = b->next;
release(&bcache.lock[i]);
acquire(&bcache.lock[index]);
b->next = bcache.buf_table[index].next;
b->prev = &bcache.buf_table[index];
bcache.buf_table[index].next->prev = b;
bcache.buf_table[index].next = b;
}
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
release(&bcache.lock[index]);
acquiresleep(&b->lock);
return b;
}
}
release(&bcache.lock[i]);
}
panic("bget: no buffers");
}
下面几个函数根据 block 中的 blockno 来得到对应的桶:
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
int index = b->blockno % NBUCKET;
acquire(&bcache.lock[index]);
b->refcnt--;
release(&bcache.lock[index]);
}
void
bpin(struct buf *b) {
int index = b->blockno % NBUCKET;
acquire(&bcache.lock[index]);
b->refcnt++;
release(&bcache.lock[index]);
}
void
bunpin(struct buf *b) {
int index = b->blockno % NBUCKET;
acquire(&bcache.lock[index]);
b->refcnt--;
release(&bcache.lock[index]);
}
最后 kalloctest 和 bcachetest 还有 usertest 全部通过。