浅析项目实践接触到的java并发线程池应用场景
文章目录
- 前言
- 场景一、营销场景-门店活动信息定时校验
- 场景二、算法工程依赖-批量查询数据集
- 总结
前言
最近研读《java并发编程之美》这本书8、9、11章关于线程池的部分,有很多新的收获,在此想结合项目经历,总结分析一下实践中对于线程池的应用场景。
场景一、营销场景-门店活动信息定时校验
定时执行的数据核对任务需要异步线程池处理,实现定时任务有很多种方式,比如xxl-job、scheduleX等。但是要和ScheduledThreadPoolExecutor的固定频率执行模式区分开,ScheduledThreadPoolExecutor支持三种模式:

chedule(Runnable command, long delay, TimeUnit unit)方法该方法的作用是提交一个延迟执行的任务,任务从提交时间算起延迟单位为unit的delay时间后开始执行。提交的任务不是周期性任务,任务只会执行一次,代码如下。
scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit)方法该方法的作用是,当任务执行完毕后,让其延迟固定时间后再次运行(fixed-delay任务)。
scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit)方法该方法的作用是,当任务执行完毕后,让其延迟固定时间后再次运行(fixed-delay任务)。

并且Timer也是不合理的,当一个Timer运行多个TimerTask时,只要其中一个TimerTask在执行中向run方法外抛出了异常,则其他任务也会自动终止。当任务在执行过程中抛出InterruptedException之外的异常时,唯一的消费线程就会因为抛出异常而终止,那么队列里的其他待执行的任务就会被清除。所以在TimerTask的run方法内最好使用try-catch结构捕捉可能的异常,不要把异常抛到run方法之外。其实要实现Timer功能,使用ScheduledThreadPoolExecutor的schedule是比较好的选择。如果ScheduledThreadPoolExecutor中的一个任务抛出异常,其他任务则不受影响。

ScheduledThreadPoolExecutor是并发包提供的组件,其提供的功能包含但不限于Timer。Timer是固定的多线程生产单线程消费,但是ScheduledThreadPoolExecutor是可以配置的,既可以是多线程生产单线程消费也可以是多线程生产多线程消费,所以在日常开发中使用定时器功能时应该优先使用ScheduledThreadPoolExecutor。
ScheduledFutureTask是具有返回值的任务,继承自FutureTask。FutureTask的内部有一个变量state用来表示任务的状态,一开始状态为NEW,所有状态为如下,代码涉及到状态转换。
private static final int NEW = 0; //初始状态
private static final int COMPLETING = 1; //执行中状态
private static final int NORMAL = 2; //正常运行结束状态
private static final int EXCEPTIONAL = 3; //运行中异常
private static final int CANCELLED = 4; //任务被取消
private static final int INTERRUPTING = 5; //任务正在被中断
private static final int INTERRUPTED = 6; //任务已经被中断
先复习一下七大参数以及Worker任务执行流程。


我们基于此创建一个线程池,参数设计需要根据实际业务场景去考虑。
有的时候IO密集型2*N和CPU密集型的(N+1)的理论公式的策略并不一定合理。没有固定答案,先设定预期,比如我期望的CPU利用率在多少,负载在多少,GC频率多少之类的指标后,再通过测试不断的调整到一个合理的线程数。
具体参考京东云开发者社区 https://developer.jdcloud.com/article/3267
private static final ThreadPoolExecutor EXECUTORS = ThreadPoolUtil.getThreadPool(
corePoolSize, maximumPoolSize, 0, "DataVerify", queueSize);
//getThreadPool方法通过new创建获取一个线程池
public static ThreadPoolExecutor getThreadPool(Integer corePoolSize, Integer maximumPoolSize, long keepAliveTime, String poolName, Integer queues) {
return new ThreadPoolExecutor(
corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(queues),
new NamedThreadFactory(poolName),
new ThreadPoolExecutor.AbortPolicy());
}
通常创建线程和线程池时要指定与业务相关的名称,否则日志打印的是线程固定前缀加上递增的全局编号,并发情况下无法区分,具体参考书11.7节的源码讲解。

NamedThreadFactory官方示例,自定义命名线程工厂,方便排查问题
/**
* 自定义命名线程工厂,方便排查问题
*/
static class NamedThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
NamedThreadFactory(String name) {
SecurityManager s = System.getSecurityManager();
group = (s ! = null) ? s.getThreadGroup() : Thread.currentThread().
getThreadGroup();
if (null == name || name.isEmpty()) {
name = "pool";
}
namePrefix = name + "-" + poolNumber.getAndIncrement() + "-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r, namePrefix + threadNumber.
getAndIncrement(), 0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() ! = Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
下面是具体定时任务执行的部分,通过注入Runnable类型的task经过execute方法交给Worker执行,结构上类似生产-消费模型。
@Override
public Result process(xxContext context) throws Exception {
//..............前置处理
for (Long storeServiceId : allStoreServiceIds) {
EXECUTORS.execute(() -> {
try {
//优惠数据校验 卡券与saas侧的数据一致性compare
//从Saas云服务ERP系统上拉取最近更新的活动数据
dataVerifyService.verify(storeServiceId, startTime, endTime);
} catch (Exception e) {
log.error("xxxxxx", e);
}
});
}
//所有异步任务提交完成
log.info("all asyc task submit over");
return new Result(SUCCESS);
}
这里顺便介绍一下execute和submmit的区别:
提交任务的类型:
execute和submit都属于线程池的方法,execute只能提交Runnable类型的任务,submit既能提交Runnable类型任务也能提交Callable类型任务。
异常:
execute会直接抛出任务执行时的异常,可以用try、catch来捕获,和普通线程的处理方式完全一致。submit会吃掉异常,可通过Future的get方法将任务执行时的异常重新抛出。也就是execute()方法在执行任务出现异常时,会直接抛出异常,而submit()方法则会捕获异常并封装到Future对象中。我们可以通过调用Future对象的get()方法,来获取执行过程中的异常。
返回值:
execute()没有返回值,submit有返回值,所以需要返回值的时候必须使用submit()方法。
execute和submmit源码分析如下:
public Future<? > submit(Runnable task) {
...
//(1)装饰Runnable为Future对象
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
//(6)返回Future对象
return ftask;
}
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
public void execute(Runnable command) {
...
//(2) 如果线程个数小于核心线程数则新增处理线程
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//(3)如果当前线程个数已经达到核心线程数则把任务放入队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//(4)尝试新增处理线程
else if (! addWorker(command, false))
reject(command); //(5)新增失败则调用拒绝策略
}
可以看到区别在于RunnableFuture包装了task,之前execute返回值是void现在变成了Future对象,底层还是封装了execute的执行逻辑。
场景二、算法工程依赖-批量查询数据集
实际开发中更多的是使用SpringBoot来开发,Spring默认也是自带了一个线程池方便我们开发,它就是ThreadPoolTaskExecutor,其更方便与Spring框架进行整合,本质还是java.util.concurrent.Executor。UML类图关系如下:
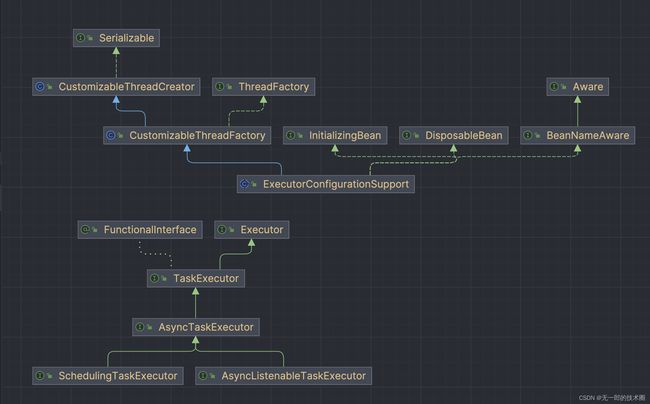
应用场景:例如查询字段和Id匹配的数据集的表的信息,这里可以给予Spring Core内置的ThreadPoolTaskExecutor来实现,特意看了一下它和JUC包的ThreadPoolExecutor区别:
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.springframework.scheduling.concurrent;
public class ThreadPoolTaskExecutor extends ExecutorConfigurationSupport implements AsyncListenableTaskExecutor, SchedulingTaskExecutor {
private final Object poolSizeMonitor = new Object();
private int corePoolSize = 1;
private int maxPoolSize = Integer.MAX_VALUE;
private int keepAliveSeconds = 60;
private int queueCapacity = Integer.MAX_VALUE;
private boolean allowCoreThreadTimeOut = false;
@Nullable
private TaskDecorator taskDecorator;
@Nullable
private ThreadPoolExecutor threadPoolExecutor;
private final Map<Runnable, Object> decoratedTaskMap;
public ThreadPoolTaskExecutor() {
this.decoratedTaskMap = new ConcurrentReferenceHashMap(16, ReferenceType.WEAK);
}
这里解释一下这个decoratedTaskMap:
decoratedTaskMap 是 ThreadPoolTaskExecutor 中的一个成员变量,用于存储任务(Runnable 对象)和关联的装饰器(Object 对象)之间的映射关系。具体来说,decoratedTaskMap 的作用是为了在任务执行前后应用装饰器,以对任务进行一些额外的处理。
在 Spring 的 ThreadPoolTaskExecutor 中,装饰器的使用场景通常涉及任务执行的一些扩展需求,例如:
任务监控和记录: 通过装饰器可以在任务执行前后记录任务的执行信息、运行时间等,用于性能监控和日志记录。
任务上下文传递: 在多线程环境下,任务可能需要访问一些上下文信息,通过装饰器可以在任务执行前将上下文信息传递给任务,以保证任务执行时上下文正确。
任务异常处理: 装饰器可以用于在任务执行时捕获异常,进行特定的异常处理逻辑,而不影响原始任务。
任务计数器和统计: 通过装饰器可以实现任务的计数、统计功能,用于监控线程池的运行状态。在 ThreadPoolTaskExecutor 中,使用 decoratedTaskMap 存储任务和装饰器之间的映射关系,可以确保对于相同的任务不会重复应用装饰器,同时能够有效地管理装饰器的生命周期。这个映射关系使用了 ConcurrentReferenceHashMap,它是一个并发安全的、支持弱引用的哈希表,可以有效地管理映射关系,防止内存泄漏。
总的来说,decoratedTaskMap 提供了一种灵活的机制,允许开发者通过装饰器对线程池中的任务进行一些额外的处理,以满足特定需求。
具体参考 https://zhuanlan.zhihu.com/p/346086161 https://blog.csdn.net/qq_40386113/article/details/127581333
可以看到它的构造器是不传参的,需要我们通过set方法设置内部threadPoolExecutor属性对象的核心参数,应用的时候在方法上添加@Async注解,然后还需要在@SpringBootApplication启动类或者@Configuration注解类上 添加注解@EnableAsync启动多线程注解,@Async就会对标注的方法开启异步多线程调用,注意,这个方法的类一定要交给Spring容器来管理。
或者直接通过@Resource(name=“xxxxExecutor”)
private AsyncTaskExecutor xxxxExecutor; 进行bean注入调用也是可以的。
@Configuration
public class xxxExecutor {
@Bean("xxxExecutor")
public AsyncTaskExecutor xxxExecutor() {
ThreadPoolTaskExecutor asyncTaskExecutor = new CustomThreadPoolTaskExecutor();
asyncTaskExecutor.setMaxPoolSize(MAX_POOL_SIZE);
asyncTaskExecutor.setCorePoolSize(CORE_POOL_SIZE);
asyncTaskExecutor.setThreadNamePrefix("xxxxx");
asyncTaskExecutor.setQueueCapacity(MAX_QUEUE_SIZE);
asyncTaskExecutor.setThreadFactory(new NamedThreadFactory());
asyncTaskExecutor.initialize();
return asyncTaskExecutor;
}
}
返回一个AsyncTaskExecutor对象,继承自Executor,并且可以通过继承重写它的execute和submit方法,源码参考如下。


应用的时候执行批量查询的部分,这个过程可能是走数据库执行SQL查询的,也可能是基于API经过OkHttpClient调用相关方法进行返回。
public List<xxxx> searchDataSet(){
//........参数校验 图数据库向量组装 前置处理
List<Future<xxxxResult>> futures = new ArrayList<>();
for(SearchResult xxxxResult : allResults){
futures.add(asyncTaskExecutor.submit(() -> xxxxxSearch(xxxxSearchRequest)));
}
}
//........对象转换 日志记录 后置处理
return futures;
}
总结
本文根据最近研读《java并发编程之美》这本书8、9、11章关于线程池的部分与实际项目经历,分析了java并发线程池具体应用场景,并结合个人的思考进行了一定的拓展,记录的过程也是对知识的一种巩固和加强,以便于对并发编程有更深入的理解。