Java集合之Collection知识总结
一、前言
java集合是一个较为基础的框架,本次主要是整理积累的知识,供复习使用,同时也感谢Guide大佬提供的参考文献。
目录
-
- 一、前言
- 二、整体概览
- 三、List
-
- 结构差异性
- ArrayList和Vector区别
- Arraylist 与 LinkedList 区别
- 什么是Stack?
- 四、Set
-
- 无序性和不可重复性
- 比较器Comparable和Comparator区别
- HashSet LinkedHashSet TreeSet区别
- HashSet去重
-
- hashCode()与 equals() 的相关规定
- equals的设计原则
- hashCode的设计原则
- 五、Queue
-
- 阻塞队列
-
- 常用API
- 六、小结
-
- 常用工具类
二、整体概览
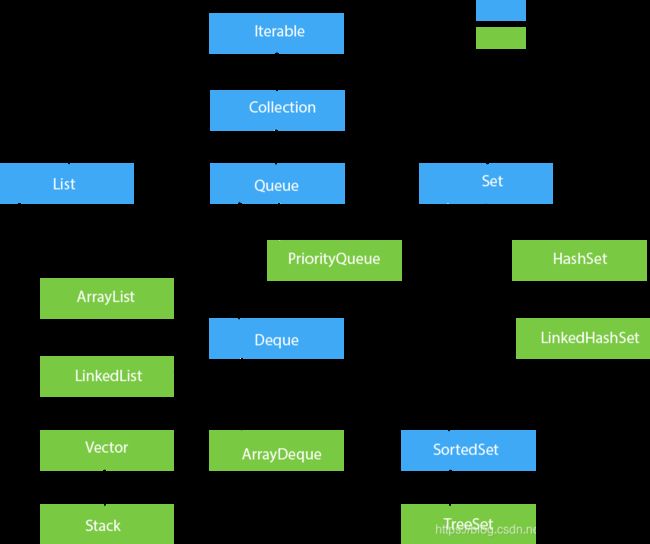
Collection接口下的子接口有List ,Queue,Set 他们各自有各自的特点。
三、List
List是一个可重复有序的集合接口,实现类有ArrayList,LinkedList,Vector;他们之间也存在一定的差异性。
结构差异性
ArrayList: Object[] 对象数组
Vector:Object[] 对象数组
LinkedList: 双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)
ArrayList和Vector区别
ArrayList 是 List 的主要实现类,底层使用 Object[ ]存储,适用于频繁的查找工作,线程不安全 ;
Vector 是 List 的古老实现类,底层使用Object[ ] 存储,线程安全的。
Arraylist 与 LinkedList 区别
1.是否保证线程安全: ArrayList 和 LinkedList 都是不保证线程安全。
2.底层数据结构: Arraylist 底层使用的是 Object 数组;LinkedList 底层使用的是双向链表数据结构。
3.插入和删除是否受元素位置的影响:
ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候,
ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i
插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。
LinkedList 采用链表存储,所以,如果是在头尾插入或者删除元素不受元素位置的影响(add(E e)、addFirst(E
e)、addLast(E e)、removeFirst() 、 removeLast()),近似 O(1),如果是要在指定位置 i插入和删除元素的话(add(int index, E element),remove(Object o)) 时间复杂度近似为 O(n),因为需要先移动到指定位置再插入。
4.是否支持快速随机访问: LinkedList 不支持高效的随机元素访问,而 ArrayList
支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。内存空间占用: ArrayList 的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList
的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
什么是Stack?
栈是Vector的子类,只允许在有序的线性数据集合的一端(称为栈顶 top)进行加入数据(push)和移除数据(pop)。因而按照后进先出(LIFO, Last In First Out) 的原理运作。在栈中,push 和 pop 的操作都发生在栈顶。
栈常用一维数组或链表来实现,用数组实现的栈叫作 顺序栈 ,用链表实现的栈叫作链式栈
栈的常用场景表达式计算,中缀表达式转前缀,中缀转后缀等,在后续的算法章节中对这块会进行详细的阐述。
示例:校验括号是否成对有效出现
private boolean checkBrackets(String keywords) {
Stack sc=new Stack();
char[] c=keywords.toCharArray();
for (int i = 0; i < c.length; i++) {
if (c[i]=='('||c[i]=='['||c[i]=='{') {
sc.push(c[i]);
}
else if (c[i]==')') {
if (sc.peek()=='(') {
sc.pop();
}
}else if (c[i]==']') {
if (sc.peek()=='[') {
sc.pop();
}
}else if (c[i]=='}') {
if (sc.peek()=='{') {
sc.pop();
}
}
}
if (sc.empty()) {
return true;
}
return false;
}
四、Set
Set是可以存储不重复元素的集合,有的实现类是无序,有的是有序(有序可以使用比较器进行实现)。
无序性和不可重复性
什么是无序性?无序性不等于随机性 ,无序性是指存储的数据在底层数组中并非按照数组索引的顺序添加 ,而是根据数据的哈希值决定的。
什么是不可重复性?不可重复性是指添加的元素按照 equals()判断时 ,返回 false,需要同时重写 equals()方法和
HashCode()方法。
比较器Comparable和Comparator区别
Comparable 接口实际上是出自java.lang包 它有一个 compareTo(Object obj)方法用来排序
Comparator接口实际上是出自 java.util 包它有一个compare(Object obj1, Object obj2)方法用来排序
Comparable和Comparator都是比较器,而Comparable是用于内定义,即如果一个A对象的集合调用Stream的sort排序的时候,Api有两种实现,其中一种是没有形参,这时就会调用A实现了Comparable接口里面实现的compareTo()方法。Comparator是外部定义的比较器,比如TreeMap可以传入一个比较器,而在Stream也可以根据不同的List临时匿名一个Comparator接口定义比较规则。
HashSet LinkedHashSet TreeSet区别
HashSet 是 Set 接口的主要实现类 ,HashSet 的底层是 HashMap,线程不安全的,可以存储 null 值;
LinkedHashSet 是 HashSet 的子类,能够按照添加的顺序遍历;
TreeSet 底层使用红黑树,能够按照添加元素的顺序进行遍历,排序的方式有自然排序和定制排序。
HashSet去重
当你把对象加入HashSet时,HashSet 会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的
hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode
值的对象,这时会调用equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet
就不会让加入操作成功。
hashCode()与 equals() 的相关规定
如果两个对象相等,则 hashcode 一定也是相同的
两个对象相等,对两个 equals() 方法返回 true
两个对象有相同的 hashcode 值,它们也不一定是相等的
综上,equals() 方法被覆盖过,则 hashCode() 方法也必须被覆盖
hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
equals的设计原则
对称性: 如果x.equals(y)返回是true,那么y.equals(x)也应该返回是true。
反射性: x.equals(x)必须返回是true。
类推性: 如果x.equals(y)返回是true,而且y.equals(z)返回是true,那么z.equals(x)也应该返回是true。
一致性: 如果x.equals(y)返回是true,只要x和y内容一直不变,不管你重复x.equals(y)多少次,返回都是true。
非空性: x.equals(null),永远返回是false;x.equals(和x不同类型的对象)永远返回是false。
hashCode的设计原则
在一个Java应用的执行期间,如果一个对象提供给equals做比较的信息没有被修改的话,该对象多次调用hashCode()方法,该方法必须始终如一返回同一个integer。
如果两个对象根据equals(Object)方法是相等的,那么调用二者各自的hashCode()方法必须产生同一个integer结果。
并不要求根据equals(java.lang.Object)方法不相等的两个对象,调用二者各自的hashCode()方法必须产生不同的integer结果。然而,程序员应该意识到对于不同的对象产生不同的integer结果,有可能会提高hash table的性能。
五、Queue
1.队列是一种特殊的线性表,它只允许在表的前端进行删除操作,而在表的后端进行插入操作。一个队列就是一个先入先出(FIFO)的数据结构。
2.LinkedList类实现了Queue接口,因此我们可以把LinkedList当成Queue来用,Queue的使用场景可以用于多线程中不同线程任务通讯,例如Nio多线程之间可以使用Queue来完成,当然也还有很多其他应用场景。
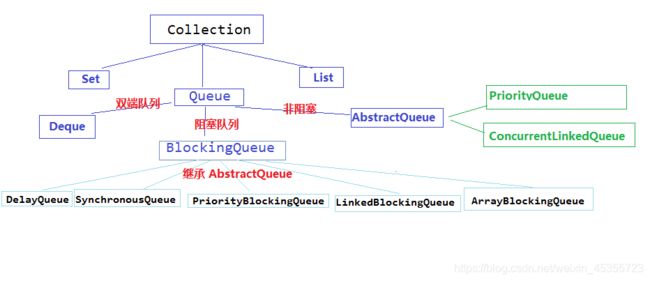
阻塞队列
队列分为阻塞队列和非阻塞队列
阻塞队列的接口BlockingQueue 其实现类主要是
ArrayBlockingQueue :一个由数组支持的有界队列。
LinkedBlockingQueue:一个由链接节点支持的可选有界队列。
PriorityBlockingQueue :一个由优先级堆支持的无界优先级队列。
DelayQueue :一个由优先级堆支持的、基于时间的调度队列。
SynchronousQueue :一个利用BlockingQueue 接口的简单聚集(rendezvous)机制。
阻塞队列在自定义线程池中根据不同的线程需求可以选择。
常用API
- add: 增加一个元索 如果队列已满,则抛出一个IIIegaISlabEepeplian异常 - remove:移除并返回队列头部的元素 如果队列为空,则抛NoSuchElementException异常
- element: 返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
- offer: 添加一个元素并返回true 如果队列已满,则返回false
- poll: 移除并返问队列头部的元素 如果队列为空,则返回null
- peek: 返回队列头部的元素 如果队列为空,则返回null
- put: 添加一个元素 如果队列满,则阻塞
- take: 移除并返回队列头部的元素 如果队列为空,则阻塞
基本API示例代码
import java.util.LinkedList;
import java.util.Queue;
public class Main {
public static void main(String[] args) {
//add()和remove()方法在失败的时候会抛出异常(不推荐)
Queue queue = new LinkedList();
//添加元素
queue.offer("a");
queue.offer("b");
queue.offer("c");
queue.offer("d");
queue.offer("e");
for(String q : queue){
System.out.println(q);
}
System.out.println("===");
System.out.println("poll="+queue.poll()); //返回第一个元素,并在队列中删除
for(String q : queue){
System.out.println(q);
}
System.out.println("===");
System.out.println("element="+queue.element()); //返回第一个元素
for(String q : queue){
System.out.println(q);
}
System.out.println("===");
System.out.println("peek="+queue.peek()); //返回第一个元素
for(String q : queue){
System.out.println(q);
}
}
}
API差异性
offer,add 区别:
一些队列有大小限制,因此如果想在一个满的队列中加入一个新项,多出的项就会被拒绝。
这时新的 offer 方法就可以起作用了。它不是对调用 add() 方法抛出一个 unchecked 异常,而只是得到由 offer()
返回的 false。poll,remove 区别:
remove() 和 poll() 方法都是从队列中删除第一个元素。remove() 的行为与 Collection 接口的版本相似,
但是新的 poll() 方法在用空集合调用时不是抛出异常,只是返回 null。因此新的方法更适合容易出现异常条件的情况。peek,element区别:
element() 和 peek() 用于在队列的头部查询元素。与 remove() 方法类似,在队列为空时, element()
抛出一个异常,而 peek() 返回 null。
六、小结
集合框架可使用的实现类有很多,在具体业务中可以根据需求选择合适的类型,当然在使用过程中集合可以配合Jdk8新特性Stream流(在后续章节会整理)做一些更加便捷的对集合进行运算处理。
常用工具类
apache
org.apache.commons
commons-lang3
hutool
cn.hutool
hutool-all