性能优化-一文宏观理解OpenCL
本文主要对OpenCL做一个整体的介绍、包括环境搭建、第一个OpenCL程序、架构、优化策略,希望对读者有所收获。
个人简介:一个全栈工程师的升级之路!
个人专栏:高性能(HPC)开发基础教程
CSDN主页 发狂的小花
人生秘诀:学习的本质就是极致重复!
目录
前言
1 OpenCL概述
1.1 定义
1.2 发展
1.3 OpenCL版本
1.3.1 v2.0特点
1.4 OpenCL应用领域
2 OpenCL架构与原理
2.1 OpenCL整体架构
2.2 OpenCL平台模型
2.3 OpenCL执行模型
2.4 OpenCL内存模型
2.5 OpenCL编程原理
2.6 OpenCL执行流程
3 OpenCL开发环境搭建
3.1 Intel 集成显卡 GPU
3.2 NVIDIA GPU
3.3 编写第一个OpenCL程序
4 OpenCL数据类型与运算
4.1 OpenCL数据类型
4.2 OpenCL运算符与表达式
4.3 OpenCL向量和矩阵运算
5 OpenCL并行计算优化
5.1 并行计算基本概念
5.2 OpenCL并行计算优化策略
6 OpenCL图像处理应用
6.1 图像处理基本概念
6.2 OpenCL图像处理API介绍
7 OpenCL性能分析与调试
7.1 性能分析工具介绍
7.2 性能瓶颈定位与优化方法
7.3 调试技巧与常见问题解决方案
前言
一分钟快速理解异构并行
异构并行计算包含两个方面的内容:异构和并行。
异构是指:计算单元由不同的多种处理器组成,如X86 CPU+GPU、ARM CPU+GPU、X86 CPU+FPGA、ARM CPU+DSP等。
并行是指:要发挥异构硬件平台的全部性能必须要使用并行的编程方式。这通常包含两个层次的内容:
(1)多个不同架构的处理器同时计算,要发挥异构系统中所有处理器的性能,可通过并行编程使每个处理器都参与运算,避免处理器闲置。相比于只让某一种类型的处理器参与工作,这种方式提高了性能上限,简单举例来说,在X86 CPU+GPU平台上,X86 CPU的计算能力为1TFLOPS,GPU的计算能力为4TFLOPS,如果只使用GPU,那么最大可发挥的性能是4TFLOPS,而如果加上X86 CPU,则最大可发挥的性能是5TFLOPS。
(2)同一架构的多个核的并行处理,以及对于支持SIMD操作的数据并行
1 OpenCL概述
1.1 定义
OpenCL官网
OpenCL(Open Computing Language)是一个由Khronos Group维护的异构并行计算的行业标准。它主要用于编写运行在各类异构平台上的代码,这些平台包括CPU、GPU、FPGA、DSP,以及最近几年流行的各类AI加速器等。从软件角度看,OpenCL是用于异构平台编程的框架;从规范视角看,它是异构并行计算的行业标准。
OpenCL是一种并行计算框架,它允许开发者使用类似于C语言的编程语言编写并行程序,从而利用多核处理器和GPU等加速器的计算能力。
OpenCL程序主要包含两部分:一部分是在设备上执行的程序,例如在GPU上;另一部分是在主机上运行的程序,例如在CPU上。在设备上执行的程序是OpenCL发挥其强大计算能力的地方,这部分程序通常是一个特殊的函数,被称为kernel函数,需要使用OpenCL语言编写。而主机程序则提供了API,用于管理在设备上运行的程序,主机程序可以用C或者C++编写。
OpenCL提供了基于任务和基于数据两种并行计算机制,它极大地扩展了GPU的应用范围,使之不再局限于图形领域。对于移动端的开发,强烈建议查看厂家的文档,例如对于高通平台可以参考Qualcomm Snapdragon Mobile Platform的文档。
1.2 发展
OpenCL最初苹果公司开发,拥有其商标权,并在与AMD,IBM,英特尔和NVIDIA技术团队的合作之下初步完善。随后,苹果将这一草案提交至Khronos Group。
2008年6月的WWDC大会上,苹果提出了OpenCL规范,旨在提供一个通用的开放API,在此基础上开发GPU通用计算软件。随后,Khronos Group宣布成立GPU通用计算开放行业标准工作组,以苹果的提案为基础创立OpenCL行业规范。5个月后的2008年11月18日,该工作组完成了OpenCL 1.0规范的技术细节。2010年6月14日,OpenCL 1.1 发布。2011年11月15日,OpenCL 1.2 发布。2013年11月19日,OpenCL 2.0发布。
1.3 OpenCL版本
v1.0->v1.1->v2.0->v3.0
现在绝大数平台支持v2.0。
1.3.1 v2.0特点
a 共享虚拟内存
主机和设备内核可以直接共享复杂的、包含指针的数据结构,大大提高编程灵活性,避免冗余的数据转移。
b 动态并行
设备内核可以在无需主机交互的情况下进行内核排队,实现灵活的工作调度,避免数据转移,大大减轻主处理器的负担。
c 通用内存空间
无需指定地址空间名称即可为引数(argument)编写函数,不用再为程序里的每一个地址空间名称编写函数。
d 图像
改进图像支持,包括sRGB、3D,内核可以读写同一图像。
e C11原子操作
新的C11原子和同步操作子集,分配在同一工作组内
f Pipes
以FIFO格式组织数据的内存对象,可以直接读写,数据结构可简单编程、高度优化。
g 安卓可安装客户端驱动扩展
安卓系统上可将OpenCL作为共享对象进行载入。
1.4 OpenCL应用领域
(1)科学计算
OpenCL可以用于高性能计算(HPC)领域,例如天气预报、基因测序等。
(2)图像处理
OpenCL可以加速图像处理算法,例如图像滤波、图像增强等。
(3)计算机视觉
OpenCL可以用于实现实时的计算机视觉算法,例如目标检测、人脸识别等。
(4)游戏开发
OpenCL可以用于游戏开发中的物理模拟、AI计算等需要高性能计算的场景。
2 OpenCL架构与原理
2.1 OpenCL整体架构
OpenCL框架由三部分组成,分别为OpenCL平台API、OpenCL运行时API、OpenCL编程语言。
OpenCL平台API:平台API定义了宿主机程序发现OpenCL设备所用的函数以及这些函数的功能,另外还定义了为OpenCL应用创建上下文的函数。
OpenCL运行时API:这个API管理上下文来创建命令队列以及运行时发生的其他操作。例如,将命令提交到命令队列的函数就来自OpenCL运行时API。
OpenCL编程语言:这是用来编写内核代码的编程语言。它基于ISO C99标准的一个扩展子集,因此通常称为OpenCL C编程语言。
把上述单独的部分汇集起来,形成OpenCL的一个全景图,如图《OpenCL执行模型》所示:
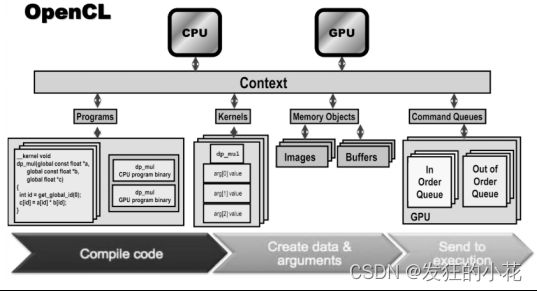 OpenCL执行模型
OpenCL执行模型
首先是一个定义上下文的宿主机程序。如上图中中的上下文包含两个OpenCL设备、一个CPU和一个GPU。接下来定义了命令队列。这里有两个队列,一个是面向GPU的有序命令队列,另一个是面向CPU的乱序命令队列。然后宿主机程序定义一个程序对象,这个程序对象编译后将为两个OpenCL设备(CPU和GPU)生成内核。接下来宿主机程序定义程序所需的内存对象,并把它们映射到内核的参数。最后,宿主机程序将命令放入命令队列来执行这些内核。
2.2 OpenCL平台模型
(1)平台(Platform)
OpenCL平台通常由一个或多个供应商提供,包括一套OpenCL设备、内存、命令队列和程序对象,用于执行OpenCL程序。
(2)设备(Device)
OpenCL设备可以是CPU、GPU、FPGA或其他类型的处理器,用于执行OpenCL内核。每个设备都有一个或多个计算单元,每个计算单元包含一个或多个处理元件。
(3)上下文(Context)
OpenCL上下文是一个容器,包含了执行OpenCL程序所需的所有对象,如设备、内存对象、命令队列和程序对象等。
2.3 OpenCL执行模型
(1)主机(Host)
主机是运行OpenCL程序的CPU,负责管理和调度OpenCL设备上的任务。主机通过OpenCL API与OpenCL设备进行交互。
(2)内核(Kernel)
OpenCL内核是在OpenCL设备上执行的函数,用于实现并行计算任务。内核可以使用OpenCL C编程语言编写,并通过OpenCL编译器编译成可在OpenCL设备上执行的二进制代码。
(3)命令队列(Command Queue)
命令队列是主机与OpenCL设备之间通信的桥梁,用于将主机发送的命令按照顺序在OpenCL设备上执行。命令可以包括内核执行、内存传输、同步等操作。
2.4 OpenCL内存模型
(1)全局内存(Global Memory)
全局内存是OpenCL设备中可供所有工作项共享的内存区域,用于存储输入数据、输出数据和中间结果等。全局内存的访问速度相对较慢,但容量较大。
(2)本地内存(Local Memory)
本地内存是分配给每个工作组(Work-group)的私有内存区域,用于存储工作组内的共享数据。本地内存的访问速度比全局内存快,但容量有限。
(3)私有内存(Private Memory)
私有内存是分配给每个工作项(Work-item)的私有内存区域,用于存储工作项的局部变量和临时数据。私有内存的访问速度最快,但容量最小。
2.5 OpenCL编程原理
(1)编程流程
OpenCL编程通常包括编写内核代码、创建上下文、编译内核、创建命令队列、设置内核参数、执行内核等步骤。编程过程中需要遵循一定的规范和约定,以确保程序的正确性和性能。
(2)并行计算
OpenCL支持数据并行和任务并行两种并行计算模式。数据并行模式通过将数据划分为多个独立的部分,并在多个工作项上并行处理来实现并行计算。任务并行模式则通过将任务划分为多个独立的子任务,并在多个工作组上并行执行来实现并行计算。
(3)优化策略
为了提高OpenCL程序的性能,可以采用多种优化策略,如减少全局内存访问、优化循环结构、使用向量化操作、利用硬件特性等。同时,还需要注意避免一些常见的性能瓶颈和错误用法,如内存泄漏、同步问题等。
2.6 OpenCL执行流程
OpenCL的工作流程大致如下:首先,查询并选择一个平台;然后在该平台上创建一个上下文;接着在该上下文上查询并选择一个或多个设备;最后,加载OpenCL内核程序并创建一个program对象,为指定的设备编译program中的kernel,创建指定名字的kernel对象,为kernel创建内存对象,为kernel设置参数,以及在指定的设备上创建command queue。
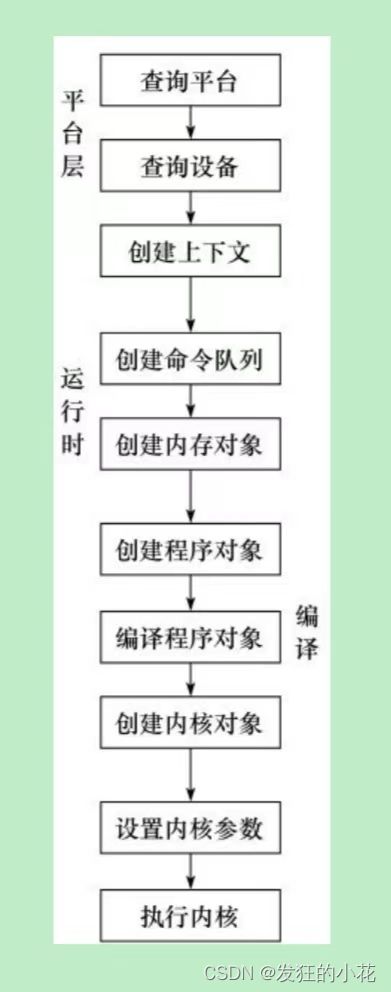 OpenCL执行流程
OpenCL执行流程
3 OpenCL开发环境搭建
本文主要介绍在x86 PC的Ubuntu18上搭建OpenCL环境,包括Intel集成显卡 GPU 和NVIDIA GPU
3.1 Intel 集成显卡 GPU
(1)Download cpu+gpu openCL sdk for intel UHD
Intel cpu +gpu OpenCL SDK
(2)解压后执行
./install.sh(3)安装依赖
mkdir neo
cd neo
wget https://github.com/intel/compute-runtime/releases/download/19.51.15145/intel-gmmlib_19.3.4_amd64.deb
wget https://github.com/intel/compute-runtime/releases/download/19.51.15145/intel-igc-core_1.0.3041_amd64.deb
wget https://github.com/intel/compute-runtime/releases/download/19.51.15145/intel-igc-opencl_1.0.3041_amd64.deb
wget https://github.com/intel/compute-runtime/releases/download/19.51.15145/intel-opencl_19.51.15145_amd64.deb
wget https://github.com/intel/compute-runtime/releases/download/19.51.15145/intel-ocloc_19.51.15145_amd64.deb安装
sudo dpkg -i *.deb(4)安装 clinfo
sudo apt-get install clinfo(5)查看安装成功与否
clinfo -l or clinfo
3.2 NVIDIA GPU
(1)Install NVIDIA Driver on Ubuntu18
step1:you can use "nvidia-detector" to detect nvidia driver for the GPU

step2:you can update and install driver on sodtware&update
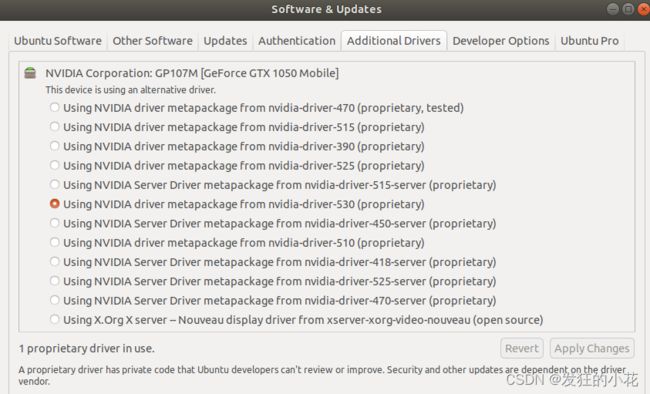
step3:you can use "nvidia-smi" to see
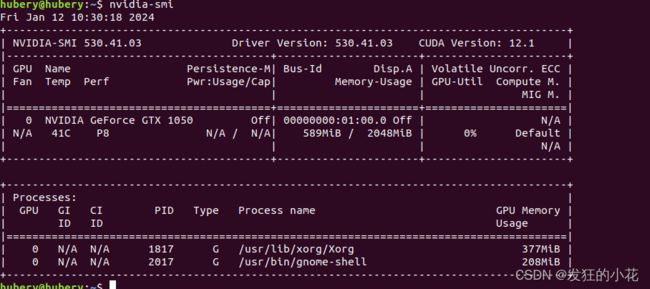
step4:you can "reboot" to see.
可能有的错误:
a. /home/hubery/lib/opencv/samples/opencl/opencl-opencv-interop.cpp:26:10: fatal error: CL/cl.h: 没有那个文件或目录
#include
解决办法:use "sudo apt install nvidia-opencl-dev " to install opencl
b. ubuntu解决libnvidia-gl-390错误
ubuntu解决libnvidia-gl-390错误
(2)NVIDIA CUDA 安装
sudo apt install nvidia-cuda-toolkit

上述表示安装成功
3.3 编写第一个OpenCL程序
这里演示在Ubuntu18上开始一个OpenCL程序。
头文件:
编译选项:-lOpenCL
(1)编写主机代码
使用C/C等语言编写主机代码,用于调用OpenCL内核并管理数据传输。
(2)编写OpenCL内核代码
使用OpenCL C语言编写内核代码,实现并行计算的功能。
(3) 编译和运行程序
使用编译器将主机代码和内核代码编译成可执行文件,并在支持OpenCL的设备上运行程序。
(4)程序
openclTest.c
#include
#include
#include
#ifdef MAC
#include
#else
#include
#endif
int main() {
/* Host data structures */
cl_platform_id *platforms;
//每一个cl_platform_id 结构表示一个在主机上的OpenCL执行平台,就是指电脑中支持OpenCL的硬件,如nvidia显卡,intel CPU和显卡,AMD显卡和CPU等
cl_uint num_platforms;
cl_int i, err, platform_index = -1;
/* Extension data */
char* ext_data;
size_t ext_size;
const char icd_ext[] = "cl_khr_icd";
//要使platform工作,需要两个步骤。1 需要为cl_platform_id结构分配内存空间。2 需要调用clGetPlatformIDs初始化这些数据结构。一般还需要步骤0:询问主机上有多少platforms
/* Find number of platforms */
//返回值如果为-1就说明调用函数失败,如果为0标明成功
//第二个参数为NULL代表要咨询主机上有多少个platform,并使用num_platforms取得实际flatform数量。
//第一个参数为1,代表我们需要取最多1个platform。可以改为任意大如:INT_MAX整数最大值。但是据说0,否则会报错,实际测试好像不会报错。下面是步骤0:询问主机有多少platforms
err = clGetPlatformIDs(5, NULL, &num_platforms);
if(err < 0) {
perror("Couldn't find any platforms.");
exit(1);
}
printf("I have platforms: %d\n", num_platforms); //本人计算机上显示为2,有intel和nvidia两个平台
/* Access all installed platforms */
//步骤1 创建cl_platform_id,并分配空间
platforms = (cl_platform_id*)
malloc(sizeof(cl_platform_id) * num_platforms);
//步骤2 第二个参数用指针platforms存储platform
clGetPlatformIDs(num_platforms, platforms, NULL);
/* Find extensions of all platforms */
//获取额外的平台信息。上面已经取得了平台id了,那么就可以进一步获取更加详细的信息了。
//一个for循环获取所有的主机上的platforms信息
for(i=0; i -1)
printf("Platform %d supports the %s extension.\n",
platform_index, icd_ext);
//释放空间
free(ext_data);
free(name);
free(vendor);
free(version);
free(profile);
}
if(platform_index <= -1)
printf("No platforms support the %s extension.\n", icd_ext);
/* Deallocate resources */
free(platforms);
return 0;
} 编译运行:
gcc openclTest.c -lOpenCL -o openclTest
./openclTest执行结果:
I have platforms: 2
The size of extension data is: 553
Platform 0 supports extensions: cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_fp64 cl_khr_3d_image_writes cl_khr_byte_addressable_store cl_khr_icd cl_khr_gl_sharing cl_nv_compiler_options cl_nv_device_attribute_query cl_nv_pragma_unroll cl_nv_copy_opts cl_nv_create_buffer cl_khr_int64_base_atomics cl_khr_int64_extended_atomics cl_khr_device_uuid cl_khr_pci_bus_info cl_khr_external_semaphore cl_khr_external_memory cl_khr_external_semaphore_opaque_fd cl_khr_external_memory_opaque_fd
Platform 0 name: NVIDIA CUDA
Platform 0 vendor: NVIDIA Corporation
Platform 0 version: OpenCL 3.0 CUDA 12.1.98
Platform 0 full profile or embeded profile?: FULL_PROFILE
Platform_index is: 0
Platform 0 supports the cl_khr_icd extension.
The size of extension data is: 1004
Platform 1 supports extensions: cl_khr_3d_image_writes cl_khr_byte_addressable_store cl_khr_fp16 cl_khr_depth_images cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_icd cl_khr_image2d_from_buffer cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_intel_subgroups cl_intel_required_subgroup_size cl_intel_subgroups_short cl_khr_spir cl_intel_accelerator cl_intel_media_block_io cl_intel_driver_diagnostics cl_khr_priority_hints cl_khr_throttle_hints cl_khr_create_command_queue cl_khr_fp64 cl_khr_subgroups cl_khr_il_program cl_intel_spirv_device_side_avc_motion_estimation cl_intel_spirv_media_block_io cl_intel_spirv_subgroups cl_khr_spirv_no_integer_wrap_decoration cl_khr_mipmap_image cl_khr_mipmap_image_writes cl_intel_unified_shared_memory_preview cl_intel_planar_yuv cl_intel_packed_yuv cl_intel_motion_estimation cl_intel_device_side_avc_motion_estimation cl_intel_advanced_motion_estimation cl_khr_int64_base_atomics cl_khr_int64_extended_atomics cl_intel_va_api_media_sharing
Platform 1 name: Intel(R) OpenCL HD Graphics
Platform 1 vendor: Intel(R) Corporation
Platform 1 version: OpenCL 2.1
Platform 1 full profile or embeded profile?: FULL_PROFILE
Platform_index is: 1
Platform 1 supports the cl_khr_icd extension.4 OpenCL数据类型与运算
4.1 OpenCL数据类型
(1)标量数据类型
OpenCL支持一系列标量数据类型,包括整型(如int、long)、浮点型(如float、double)以及布尔型等。
(2)向量数据类型
OpenCL提供向量数据类型,如float2、float3、float4等,用于表示2、3、4个同类型元素的向量。向量数据类型支持向量运算,提高计算效率。
(3)同步和原子类型
OpenCL提供同步和原子类型,用于实现多线程之间的同步和原子操作。
(4)图像和采样器类型
OpenCL专为图像处理设计了图像和采样器类型,支持图像数据的读取和写入操作。
4.2 OpenCL运算符与表达式
(1)算术运算符
OpenCL支持常见的算术运算符,如加(+)、减(-)、乘(*)、除(/)等,用于进行数值计算。
(2)关系运算符
OpenCL提供关系运算符,如等于(==)、不等于(!=)、大于(>)、小于(<)等,用于比较两个值的大小关系。
(3)逻辑运算符
OpenCL支持逻辑运算符,如逻辑与(&&)、逻辑或(||)、逻辑非(!)等,用于进行逻辑判断。
(4)位运算符
OpenCL提供位运算符,如按位与(&)、按位或(|)、按位异或(^)等,用于进行位级操作。
4.3 OpenCL向量和矩阵运算
(1)向量运算
OpenCL支持向量运算,包括向量的加、减、数乘、点积等运算。向量运算可以显著提高计算性能,特别是在处理图形和图像处理等领域。
(2)矩阵运算
OpenCL提供矩阵运算支持,包括矩阵的加法、减法、乘法以及转置等操作。矩阵运算是许多科学计算和工程应用中常见的操作,OpenCL的矩阵运算功能可以大大加速这些应用的执行速度。
5 OpenCL并行计算优化
5.1 并行计算基本概念
(1)并行计算定义
同时使用多种计算资源解决计算问题的过程,其主要目的是快速解决大型且复杂的计算问题。
(2)并行计算模型
包括SIMD(单指令多数据)、MIMD(多指令多数据)、SPMD(单程序多数据)等。
(3)并行计算的粒度
指并行计算中任务划分的细致程度,包括细粒度并行和粗粒度并行。
5.2 OpenCL并行计算优化策略
(1)数据并行和任务并行
数据并行是对数据进行划分并分配给不同的处理单元同时处理,任务并行是将问题划分为多个独立的子任务进行并行处理。
(2)内存访问优化
通过减少内存访问冲突、提高内存访问的局部性等方法优化内存访问效率。
(3)计算优化
利用向量化、循环展开、指令级并行等优化技术提高计算性能。
(4)同步和通信优化
减少不必要的同步和通信,采用高效的同步和通信机制,以降低并行计算的开销。
案例:矩阵乘法并行计算优化

6 OpenCL图像处理应用
6.1 图像处理基本概念
(1)像素(Pixel)
图像的基本单元,代表图像中的一个点,包含颜色信息和位置信息。
(2)分辨率(Resolution)
图像中像素的数量,通常以像素宽度和像素高度的乘积表示。
(3)颜色空间(Color Space)
用于表示图像颜色的数学模型,如RGB、HSV等。
(4)图像格式(Image Format)
定义像素数据的存储方式,包括像素的数据类型和排列顺序。
6.2 OpenCL图像处理API介绍
(1)图像对象(Image Object)
OpenCL中用于处理图像的数据结构,可以表示2D、3D或缓冲区图像。
(2)图像内存对象(Image Memory Object)
存储图像数据的内存区域,可以通过OpenCL内存对象进行读写操作。
(3)图像采样器(Image Sampler)
用于定义图像采样方式和过滤模式,如线性插值、最近邻插值等。
(4)图像API函数
OpenCL提供了一系列函数用于创建、配置和操作图像对象和采样器,如`clCreateImage`、`clSetKernelArg`等。
案例:图像滤波算法实现与优化

7 OpenCL性能分析与调试
7.1 性能分析工具介绍
(1)OpenCL Profiler
OpenCL Profiler是一个用于分析和优化OpenCL应用程序性能的工具。它提供了详细的性能数据,包括内核执行时间、内存传输时间等,帮助开发者定位性能瓶颈。
(2)Intel VTune Amplifier
Intel VTune Amplifier是一款强大的性能分析工具,支持OpenCL应用程序的分析。它可以提供全面的性能数据,包括CPU和GPU的利用率、内存访问模式等。
(3)AMD CodeXL
AMD CodeXL是AMD提供的一款免费的性能分析工具,支持OpenCL和其他并行计算API。它提供了丰富的性能数据和可视化界面,帮助开发者优化OpenCL应用程序。
7.2 性能瓶颈定位与优化方法
(1)内核性能分析
通过分析内核执行时间、内存访问模式等,定位性能瓶颈。优化方法包括优化算法、减少全局内存访问、使用向量化等。
(2)数据传输优化
减少主机与设备之间的数据传输,使用pinned memory或zero-copy memory等方法提高数据传输效率。
(3)多设备并行计算
利用多个OpenCL设备并行计算,提高应用程序的整体性能。需要考虑设备间的负载均衡和数据同步等问题。
7.3 调试技巧与常见问题解决方案
(1)调试技巧
使用printf或其他日志输出函数在内核中打印调试信息。
使用OpenCL的错误处理机制捕获和处理错误。
使用模拟器或调试器进行单步调试。
(2)常见问题解决方案
a 内存泄漏
确保在不再需要对象时释放内存,避免内存泄漏。
b 设备兼容性
检查代码是否兼容目标设备,确保使用的OpenCL特性和函数在目标设备上可用。
c 同步问题
确保在需要时使用同步原语,如barrier或fence,避免数据竞争和一致性问题。
我的分享也就到此结束啦
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
未来的富豪们:点赞→收藏⭐→关注,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!欢迎关注、关注!