国家税务总局发票查验平台爬虫
文章目录
-
- 1.安装根证书
- 2.反调试
-
- 2.1.无限debugger
-
- 第一种方案
- 第二种方案
- 2.2.防止代码格式化
- 3.请求参数整体分析
- 4.key9参数解密
- 5.flwq39参数解密
- 6.fplx参数解密
- 7.url地址来源
- 8.验证码应对方案
-
- 8.1 验证码获取
- 8.2 验证码识别
- 9.主要代码实现
20210219更新—flwq39的定位
网站更新后, 无法按照以前的思路定位到flwq39,现推荐一大佬写得浏览器内存漫游工具进行快速定位, 欢迎给这位大佬star ast-hook-for-js-RE
一顿修改定位操作后
发现加密函数位于
https://inv-veri.chinatax.gov.cn/js/92da1b9c13d7432c8eae5aa66e641262.js, 打上断点
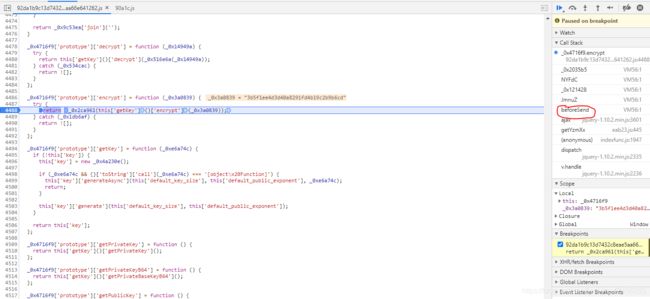
又看到了beforeSend,调试堆栈即可看到flwq39
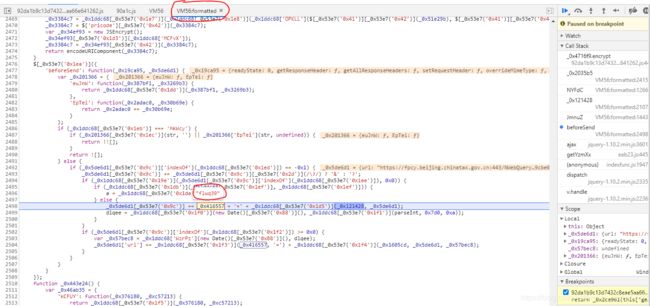
1.安装根证书
选择手动安装

2.反调试
2.1.无限debugger
第一种方案
打开控制台发现出现断点

根据右侧堆栈查找debugger产生位置
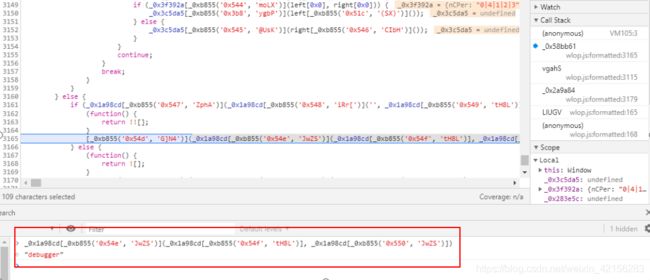
可以看到有debugger字样, 该wlop.js文件是经过sojson混淆的,可以直接用猿人学ob一键反混淆 进行代码还原, 后面会发现几乎所有js文件都是混淆过后的, 所以建议用到一个还原一个, 便于静态分析和调试。
经过还原的js片段
function _0x2a9a84(_0x2f02e9) {
function _0x58bb61(_0xf32887) {
if (typeof _0xf32887 === "string") {
return function(_0x4791b5) {}
["constructor"]("while (true) {}")["apply"]("counter");
} else {
if (("" + _0xf32887 / _0xf32887)["length"] !== 1 || _0xf32887 % 20 === 0) {
(function() {
return true;
}
)["constructor"]("debugger")["call"]("action");
} else {
(function() {
return false;
}
)["constructor"]("debugger")["apply"]("stateObject");
}
}
_0x58bb61(++_0xf32887);
}
try {
if (_0x2f02e9) {
return _0x58bb61;
} else {
_0x58bb61(0);
}
} catch (_0x51accc) {}
}
我们可以将本地文件的debugger字符串替换成其他不会执行的字符串,比如替换为debugger111,然后用fidder映射本地js文件就可以轻松过掉无限debugger了
fiddler如何替换本地文件参考下面链接https://blog.csdn.net/weixin_42156283/article/details/106731989
第二种方案

直接在debugger处Never pause here,也可以过掉debugger,使用该方案页面调试起来比较卡顿,本案例不建议这种方案
2.2.防止代码格式化
经过上面的处理, 发现已经过掉debugger了,但是有个问题,就是当输完发票号码后验证码不会正常请求(正常情况输完发票号码,输入框失去焦点会自动请求验证码),这与检测了代码格式化有关,导致程序流程异常(可能导致不按正确流程请求或chrome内存暴增),可以按照下面方式改写。
在ast还原的后脚本中搜索RegExp这个关键字符, 其原理就是通过正则判断代码有没有格式化,所有涉及RegExp正则检测的都要修改,并通过fiddler映射本地js文件,然后就可以过掉代码格式化的检测了
修改前代码片段
(function() {
_0x46b8fc(this, function() {
var _0x184400 = new RegExp("function *\\( *\\)");
var _0x151658 = new RegExp("\\+\\+ *(?:_0x(?:[a-f0-9]){4,6}|(?:\\b|\\d)[a-z0-9]{1,4}(?:\\b|\\d))","i");
var _0x62282b = _0x2a9a84("init");
if (!_0x184400["test"](_0x62282b + "chain") || !_0x151658["test"](_0x62282b + "input")) {
_0x62282b("0");
} else {
_0x2a9a84();
}
})();
}
)();
// 此处检测是否被格式化
var _0x25be9c = function() {
return "dev";
}
, _0x5f344a = function() {
return "window";
};
var _0x24cfbd = function() {
var _0x4a338d = new RegExp("\\w+ *\\(\\) *{\\w+ *['|\"].+['|\"];? *}");
return !_0x4a338d["test"](_0x25be9c["toString"]());
};
var _0x4eeb79 = function() {
var _0x5c58a6 = new RegExp("(\\\\[x|u](\\w){2,4})+");
return _0x5c58a6["test"](_0x5f344a["toString"]());
};
修改后
(function() {
_0x46b8fc(this, function() {
var _0x184400 = new RegExp("function *\\( *\\)");
var _0x151658 = new RegExp("\\+\\+ *(?:_0x(?:[a-f0-9]){4,6}|(?:\\b|\\d)[a-z0-9]{1,4}(?:\\b|\\d))","i");
var _0x62282b = _0x2a9a84("init");
if (!true || !true) {
_0x62282b("0");
} else {
_0x2a9a84();
}
})();
}
)();
var _0x25be9c = function() {
return "dev";
}
, _0x5f344a = function() {
return "window";
};
var _0x24cfbd = function() {
var _0x4a338d = new RegExp("\\w+ *\\(\\) *{\\w+ *['|\"].+['|\"];? *}");
return !true;
};
var _0x4eeb79 = function() {
var _0x5c58a6 = new RegExp("(\\\\[x|u](\\w){2,4})+");
return true;
};
即将所有正则判断改为true
_0x184400["test"](_0x62282b + "chain") → true
_0x151658["test"](_0x62282b + "input") → true
_0x4a338d["test"](_0x25be9c["toString"]()) → true
_0x5c58a6["test"](_0x5f344a["toString"]()) → true
3.请求参数整体分析
1.验证码请求参数
fpdm 发票代码
fphm 发票号码
v 版本号
callback 比当前时间减1分钟, 1分钟可以随机
_ 记录验证码请求的次数, 每次加1, 可以固定写死
r 随机数
nowtime 当前时间戳
publickey 当前时间戳
key9 加密参数
flwq39 加密参数
2.查询请求参数
callback 比当前时间减1分钟, 1分钟可以随机
key1 发票代码
key2 发票号码
key3 开票日期
key4 校验码
fplx 加密参数
yzm 验证码
yzmSj 当前时间
index 验证码请求响应值中解析
publickey 当前时间
key9 加密参数
_ 记录验证码请求的次数, 每次加1, 可以固定写死
flwq39 加密参数
4.key9参数解密
1.输入发票代码,发票号码弹出验证码

2.全局搜索key9, 并在相应位置打上断点, 然后刷新验证码, 断点断在下图位置
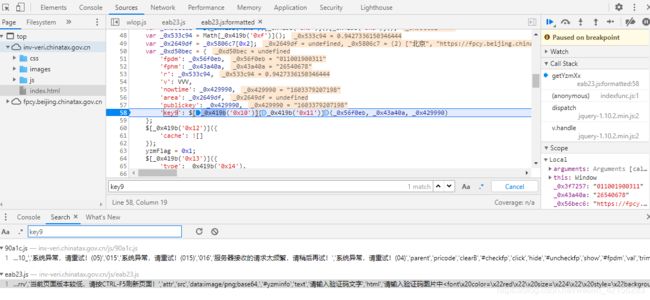
3.选中$[_0x419b(‘0x10’)][_0x419b(‘0x11’)]跳入匿名函数
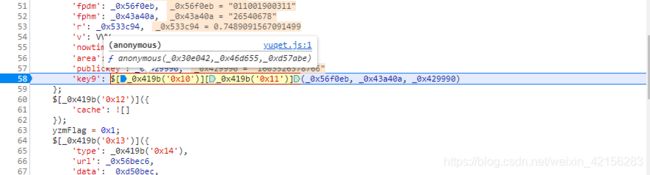
4.直接打上断点进行并进入调试,建议用ast还原后的代码进行替换调试,调试过程没有难点,缺什么补什么就可以了
还原前代码
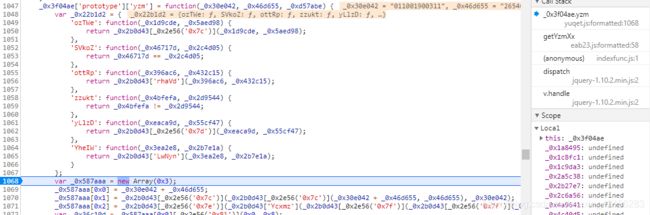
还原后代码
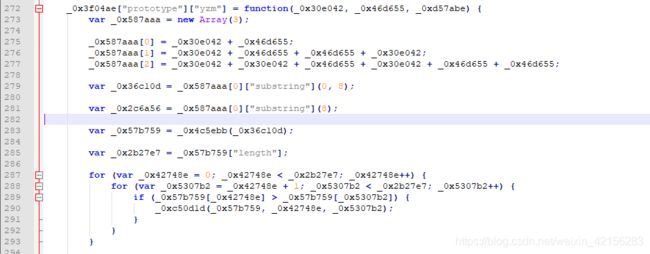
上述为验证码请求时key9生成过程,查询请求key9生成类似,不再赘述!
5.flwq39参数解密
flwq39并未在上述提交的参数列表中,全局搜索也未能搜索到,原因可能是代码被混淆后导致参数无法搜索到,将相关js文件还原后发现在emwrs.js文件中找到

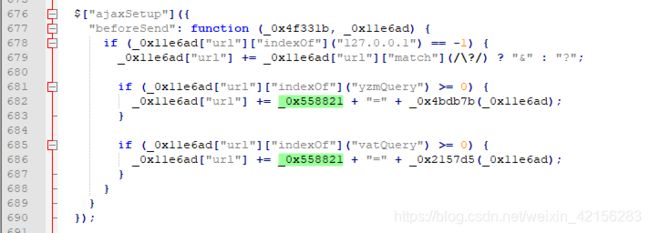
打上断点发现断下来,正是flwq39参数生成的地方, 然后缺什么补什么,过程中没有难点
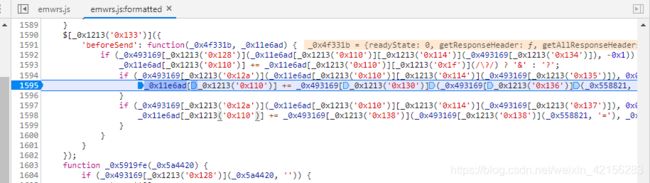
最后发现为JSEncrypt库的rsa加密,直接调用加密库即可,加密库代码参考javascript加密库jsencrypt.js,RSA.js用法

上述为验证码请求时key9生成过程,查询请求key9生成类似,不再赘述!
通过上面的分析可以总结一下:加密参数可以通过ajax beforeSend函数中添加,可以通过直接搜索beforeSend快速定位
6.fplx参数解密
全局搜索fplx,并打下断点,此时点击查询按钮并不会断下来,需要清空输入的数据,单独输入发票代码,输入框失去鼠标焦点后会断下来
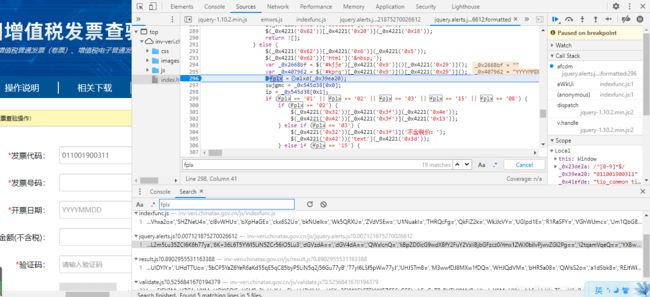
**跳入加密函数,即为生成fplx的函数 **

7.url地址来源
上述获取fplx过程中发现对发票代码进行了一系列的校验,其中关键函数getSwjg对不同地区对应的url进行的匹配获取
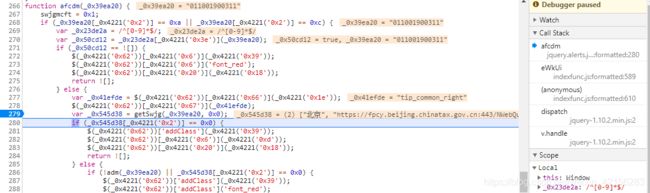

可以直接改为python代码
def get_fpdm_area(fpdm):
citys = [{
'code': '1100',
'sfmc': '北京',
'Ip': 'https://fpcy.beijing.chinatax.gov.cn:443/NWebQuery',
'address': 'https://fpcy.beijing.chinatax.gov.cn:443'
}, {
'code': '1200',
'sfmc': '天津',
'Ip': 'https://fpcy.tjsat.gov.cn:443/NWebQuery',
'address': 'https://fpcy.tjsat.gov.cn:443'
}, ......
swjginfo = []
if len(fpdm) == 12:
dqdm = fpdm[1: 5]
else:
dqdm = fpdm[0: 4]
if dqdm != "2102" and dqdm != "3302" and dqdm != "3502" and dqdm != "3702" and dqdm != "4403":
dqdm = dqdm[0: 2] + "00"
for info_dict in citys:
if dqdm == info_dict['code']:
swjginfo.append(info_dict['sfmc'])
swjginfo.append(info_dict['Ip'].replace(':443', ''))
return swjginfo
8.验证码应对方案
8.1 验证码获取
图片数据是响应数据的key1值,只需将replaceStr函数抠出即可
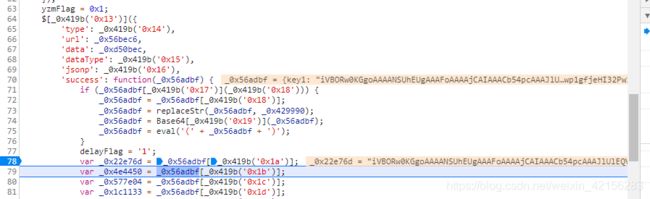
8.2 验证码识别
本案例通过训练识别难度很大,我们可以将验证码处理后交给打码平台处理
从js文件中得知验证码共分为4类:输入所有验证码,输入红色字体,输入黄色字体,输入蓝色字体
if (_0x1c1133 == "00") {
$("#yzminfo")["text"]("请输入验证码文字");
} else {
if (_0x1c1133 == "01") {
$("#yzminfo")["html"]("请输入验证码图片中红色文字");
} else {
if (_0x1c1133 == "02") {
$("#yzminfo")["html"]("请输入验证码图片中黄色文字");
} else {
if (_0x1c1133 == "03") {
$("#yzminfo")["html"]("请输入验证码图片中蓝色文字");
}
}
}
}
图片处理思路:新生成一张空白图片,添加相关文字说明,然后再和验证码合成一张图片,效果如下:

测试打码平台为超级鹰,测试20张图片,识别率100%
9.主要代码实现
# -*- coding: utf-8 -*-
import time
import execjs
import random
import requests
import urllib3
import re
import base64
import json
from datetime import datetime, timedelta
import cv2
from PIL import ImageFont, ImageDraw, Image
import numpy as np
import os
from get_area import get_fpdm_area
from chaojiying import Chaojiying_Client
chaojiying_obj = Chaojiying_Client('你自己的信息', '你自己的信息', '你自己的信息')
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
s = requests.session()
s.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
with open('./key9.js', encoding='utf-8') as f1:
ctx1 = execjs.compile(f1.read())
with open('./flwq39.js', encoding='utf-8') as f2:
ctx2 = execjs.compile(f2.read())
with open('./get_capture_data.js', encoding='utf-8') as f3:
ctx3 = execjs.compile(f3.read())
with open('./fplx.js', encoding='utf-8') as f4:
ctx4 = execjs.compile(f4.read())
capture_dict = {
'00': ['所有', (0, 0, 0)],
'01': ['红色', (0, 0, 255)],
'02': ['黄色', (0, 200, 200)],
'03': ['蓝色', (255, 0, 0)]
}
def generate_capture(color, rgb, capture_name, temp_capture_name, final_capture_name):
"""处理验证码图片, 添加说明文字, 使其符合打码平台要求"""
# 生成一张空白图片
img = Image.new('RGB', (90, 20), (255, 255, 255))
img.save(temp_capture_name)
bk_img = cv2.imread(temp_capture_name)
# 设置需要显示的字体
fontpath = "simsun.ttc"
font = ImageFont.truetype(fontpath, 12)
img_pil = Image.fromarray(bk_img)
draw = ImageDraw.Draw(img_pil)
# 绘制文字信息
draw.text((0, 3), "请输入", font=font, fill=(0, 0, 0))
draw.text((38, 3), color, font=font, fill=rgb)
draw.text((65, 3), "文字", font=font, fill=(0, 0, 0))
bk_img = np.array(img_pil)
cv2.imwrite(temp_capture_name, bk_img)
# 合并图片
photo_one = cv2.imread(temp_capture_name)
photo_two = cv2.imread(capture_name)
photo = np.vstack((photo_one, photo_two))
cv2.imwrite(final_capture_name, photo)
timestamp = int(round(time.time() * 1000))
timestamp_pre = str((timestamp / 1000 - 60) * 1000).replace('.0', '')
# 验证码请求
fpdm = '011001900311' # 发票代码
fphm = '26540678' # 发票号码
v = 'V2.0.04_004' # 版本号
callback = 'jQuery110209376690644705499_{}'.format(timestamp_pre) # 比当前时间减1分钟(1分钟可以随机)
_ = str(int(timestamp_pre) + 1) # 记录验证码请求的次数(每次加1, 可以固定写死)
r = '0.' + ''.join(str(random.choice(range(10))) for _ in range(16)) # 随机数
nowtime = str(timestamp)
publickey = str(timestamp)
key9 = ctx1.call("key9_yzm", fpdm, fphm, nowtime)
flwq39 = ctx2.call("flwq39_yzm", fpdm, fphm, nowtime)
area = get_fpdm_area(fpdm)
if not area:
print('发票代码错误')
area_url = area[1]
capture_url = f'{area_url}/yzmQuery?' \
f'callback={callback}&' \
f'fpdm={fpdm}&fphm={fphm}&' \
f'r={r}&' \
f'v={v}&' \
f'nowtime={nowtime}&' \
f'publickey={publickey}&' \
f'key9={key9}&' \
f'_={_}&' \
f'flwq39={flwq39}'
print(capture_url)
resp = s.get(url=capture_url, verify=False)
data = re.findall('data":"(.+?)"', resp.text)[0]
data = ctx3.call("replaceStr", data, nowtime)
data = base64.b64decode(data)
data_dict = json.loads(data.decode('utf-8'))
print(data_dict)
key1 = data_dict['key1']
image_data = base64.b64decode(key1)
random_num = ''.join(str(random.choice(range(10))) for _ in range(10))
capture_name = 'capture_{}.png'.format(random_num)
temp_capture_name = 'temp_capture_{}.png'.format(random_num)
final_capture_name = 'final_capture_{}.png'.format(random_num)
with open(capture_name, 'wb') as f:
f.write(image_data)
capture_type = data_dict['key4']
capture_info = capture_dict[capture_type]
color = capture_info[0]
rgb = capture_info[1]
# 处理验证码图片, 生成新的验证码图片
generate_capture(color, rgb, capture_name, temp_capture_name, final_capture_name)
# 发送验证码到打码平台
with open(final_capture_name, 'rb') as f:
capture_content = f.read()
code_dict = chaojiying_obj.PostPic(capture_content, 6004)
code = code_dict['pic_str']
print('获取验证码成功:', code)
# 删除验证码图片
os.remove(capture_name)
os.remove(temp_capture_name)
os.remove(final_capture_name)
# 查询请求
callback = 'jQuery1102030589417870189517_{}'.format(timestamp_pre)
key1 = '011001900311'
key2 = '26540678'
key3 = '20190708'
key4 = '316342'
fplx = ctx4.call("fplx", key1)
yzm = code
yzmSj = (datetime.utcnow() + timedelta(hours=8)).strftime("%Y-%m-%d %H:%M:%S")
index = data_dict['key3']
publickey = yzmSj
key9 = ctx1.call("key9_vat", fpdm, fphm, yzmSj)
_ = str(int(timestamp_pre) + 1)
flwq39 = ctx2.call("flwq39_vat", fpdm, fphm, yzmSj)
query_url = f'{area_url}/vatQuery?' \
f'callback={callback}&' \
f'key1={key1}&' \
f'key2={key2}&' \
f'key3={key3}&' \
f'key4={key4}&' \
f'fplx={fplx}&' \
f'yzm={yzm}&' \
f'yzmSj={yzmSj}&' \
f'index={index}&' \
f'publickey={publickey}&' \
f'key9={key9}&' \
f'_={_}&' \
f'flwq39={flwq39}'
print(query_url)
resp = s.get(url=query_url, verify=False)
res_json = re.findall('\((.+?)\)', resp.text)[0]
res_dict = json.loads(res_json)
print(res_dict)
"""
{
"key1": "001",
"key2": "6≡20190708≡江苏圆周电子商务有限公司北京分公司≡91110302585816506R≡北京市北京经济技术开发区荣华中路7号院3号楼十层1015 62648622≡交行北京海淀支行 110060576018150114912≡北方工业大学≡1211000040086596XB≡≡≡78875685883799316342≡0.00≡69.49≡≡661620039941≡69.49≡0≡≡",
"key3": "*印刷品*人月神话(40周年中文纪念版)█无██0.000█69.50000000█69.50█1.00000000█0.00█1█1060201019900000000≡*印刷品*人月神话(40周年中文纪念版)███0.000██-0.01██0.00█1█1060201019900000000",
"key4": "订单号:99127168673",
"key5": "1"
}
"""
# 解析数据
final_summarys = []
summarys = res_dict['key3'].split('≡')
for index, summary in enumerate(summarys):
summary_list = summary.split('█')
summary_dict = dict()
summary_dict['index'] = index + 1 # 序号
summary_dict['name'] = summary_list[0] # 名称
summary_dict['type'] = summary_list[1] # 规格型号
summary_dict['unit'] = summary_list[2] # 单位
summary_dict['amount'] = summary_list[6] # 数量
summary_dict['priceUnit'] = summary_list[4] # 单价
summary_dict['priceSum'] = summary_list[5] # 金额
summary_dict['taxRate'] = '免税' # 税率
summary_dict['taxSum'] = '***' # 税额
final_summarys.append(summary_dict)
key2_list = res_dict['key2'].split('≡')
item = dict()
item['check_num'] = key2_list[10] # 校验码
item['machine_num'] = key2_list[14] # 机器编号
item['sum_price'] = key2_list[15] # 合计金额
item['sum_tax'] = key2_list[16] # 合计税额
item['order_num'] = res_dict['key4'].replace('订单号:', '') # 订单号
item['buyer'] = {
'name': key2_list[6], # 名称
'taxpayer_identification_num': key2_list[7], # 纳税人识别号
'address_phone': key2_list[8], # 地址、电话
'bank_and_num': key2_list[9], # 开户行及账号
}
item['seller'] = {
'name': key2_list[2], # 名称
'taxpayer_identification_num': key2_list[3], # 纳税人识别号
'address_phone': key2_list[4], # 地址、电话
'bank_and_num': key2_list[5], # 开户行及账号
}
item['summarys'] = final_summarys # 具体事项
print(item)