爬虫笔记40之反爬系列三:复杂验证码的处理(12306图片验证码、行为验证:selenium鼠标行为链 + 算法)
一、12306图片验证码
解决方案: selenium(鼠标行为链) + 打码平台
思路:
通过selenium来加载登录页面,获取验证码图片。我就可以把验证码图片交给超级鹰打码平台进行处理。让其给我返回这张验证码正确的坐标值。拿到正确的坐标值之后去点击图片
实现步骤
第一步 使用selenium加载登录页面
第二步 对页面进行保存

第三步 截取12306图片验证码

第四步 交给超级鹰打码平台进行识别 返回正确的坐标值
第五步 根据正确的坐标值进行点击
其中:
截取12306图片验证码的细节步骤如下:
(1) 定位图片
code_img_element = driver.find_element_by_class_name('imgCode')
(2)获取图片的左上角坐标值
location = code_img_element.location
location返回值是个字典 :左上角坐标值
(3) 获取图片的宽和高
size = code_img_element.size
size返回值也是个字典:图片的宽和高
(4)获取左上角和右下角的坐标值
rangle = (int(location['x']),int(location['y']),int(location['x']+size['width']),int(location['y']+size['height']))
(5)在截图图片上裁剪验证码图片( Image模块的crop功能)
i = Image.open('code.png') #import Image
frame = i.crop(rangle) # crop() 根据指定区域进行裁剪
frame.save('yzm.png')
完整代码:
import requests
from hashlib import md5
from selenium import webdriver
from selenium.webdriver import ActionChains
from PIL import Image
import time
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
# if __name__ == '__main__':
# chaojiying = Chaojiying_Client('Jerry1234', '123456', '914400') #用户中心>>软件ID 生成一个替换 96001
# im = open('code2.png', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
# print(chaojiying.PostPic(im, 9004)['pic_str']) # 验证码的类型 #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
driver = webdriver.Chrome()
# 加载登录页面
driver.get('https://kyfw.12306.cn/otn/resources/login.html')
time.sleep(3)
# 切换登录方式 千万不要忘记点击
driver.find_element_by_xpath('/html/body/div[2]/div[2]/ul/li[2]/a').click()
time.sleep(2)
driver.maximize_window()
# 对加载的页面进行保存
driver.save_screenshot('code.png')
# 进行对12306图片验证码的裁剪
# 1 定位图片
code_img_element = driver.find_element_by_class_name('imgCode')
# 2 获取图片的左上角坐标值
location = code_img_element.location # location返回值是个字典 左上角坐标值
# 3 获取图片的宽和高
size = code_img_element.size # size也是一个字典 图片的宽和高
# 4 获取左上角和右下角的坐标值
rangle = (int(location['x']),int(location['y']),int(location['x']+size['width']),int(location['y']+size['height']))
i = Image.open('code.png')
frame = i.crop(rangle) # crop() 根据指定区域进行裁剪
frame.save('yzm.png')
# 将验证码图片交给超级鹰打码平台进行识别(就是超级鹰里被注释掉的最后4行的逻辑)
chaojiying = Chaojiying_Client('Jerry1234', '123456', '914400')
im = open('yzm.png', 'rb').read()
# print(chaojiying.PostPic(im, 9004)['pic_str'])
result = chaojiying.PostPic(im, 9004)['pic_str']
all_lst = [] # 存储要被点击的坐标值 [[],[]]
if '|' in result:
lst1 = result.split('|')
count1 = len(lst1)
for i in range(count1):
xy_lst = []
x = int(lst1[i].split(',')[0])
y = int(lst1[i].split(',')[1])
xy_lst.append(x)
xy_lst.append(y)
all_lst.append(xy_lst)
else:
x = int(result.split(',')[0])
y = int(result.split(',')[1])
xy_lst = []
xy_lst.append(x)
xy_lst.append(y)
all_lst.append(xy_lst)
# 使用鼠标行为链来进行正确图片的点击
for i in all_lst:
x = i[0]
y = i[1]
ActionChains(driver).move_to_element_with_offset(code_img_element,x,y).click().perform()
time.sleep(0.6)
备注:move_to_element_with_offset(to_element, xoffset, yoffset) ——移动到距某个元素(左上角坐标)多少距离的位置
补充:
(1)

(2)获取全屏截图中的验证码图片
location返回值是个字典 左上角坐标值**(坐标轴是以屏幕左上角为原点,x轴向右递增,y轴像下递增)**
import requests
from selenium import webdriver
from PIL import Image
import time
driver = webdriver.Chrome(r'C:\Users\01\Desktop\chromedriver.exe')
# 加载页面
driver.get('https://www.baidu.com/')
time.sleep(3)
#最大化窗口
driver.maximize_window()
# 对加载的页面进行保存(全屏截图)
driver.save_screenshot('code.png')
# 对页面上的图片进行裁剪
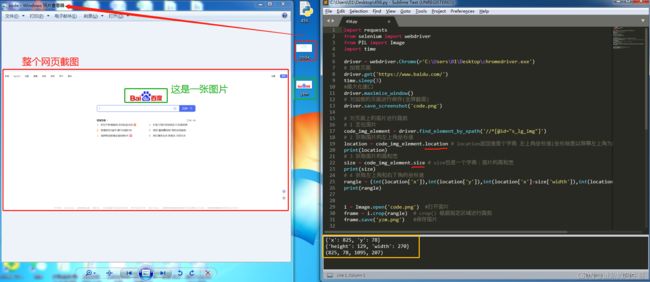
# 1 定位图片
code_img_element = driver.find_element_by_xpath('//*[@id="s_lg_img"]')
# 2 获取图片的左上角坐标值
location = code_img_element.location # location返回值是个字典 左上角坐标值(坐标轴是以屏幕左上角为原点,x轴向右递增,y轴像下递增)
print(location)
# 3 获取图片的高和宽
size = code_img_element.size # size也是一个字典:图片的高和宽
print(size)
# 4 获取左上角和右下角的坐标值
rangle = (int(location['x']),int(location['y']),int(location['x']+size['width']),int(location['y']+size['height']))
print(rangle)
i = Image.open('code.png') #打开图片
frame = i.crop(rangle) # crop() 根据指定区域进行裁剪
frame.save('yzm.png') #保存图片
二、行为验证(滑块验证)
1、拓展 :opencv图像处理框架(官网:https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_tutorials.html)
1.1特性:
(1)跨平台性(windows mac linux android…)
(2)跨语言(Java C/C++ Python Ruby oc swift…)
(3)支持功能丰富(opencv)
(4)稳定、性能高(1999年-至今 intel发布)
(5)BAT公司用在一些ai领域
1.2安装: pip install opencv-python
1.3案例:
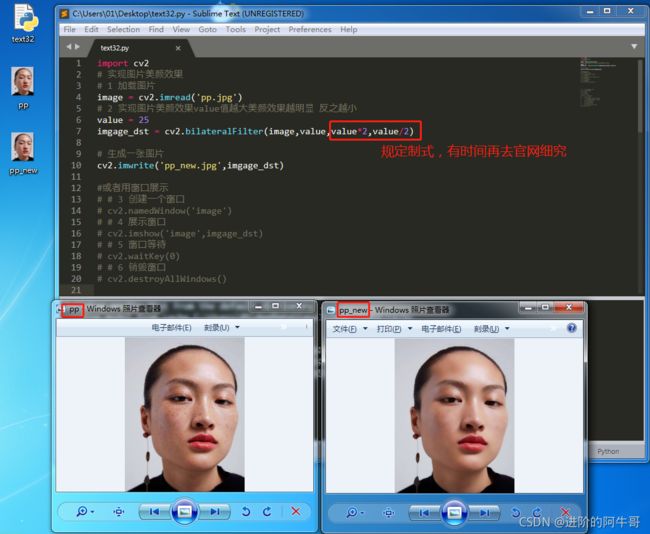
import cv2
# 实现图片美颜效果
# 1 加载图片
image = cv2.imread('pp.jpg')
# 2 实现图片美颜效果value值越大美颜效果越明显 反之越小
value = 25
imgage_dst = cv2.bilateralFilter(image,value,value*2,value/2)
# 生成一张图片
cv2.imwrite('pp_new.jpg',imgage_dst)
#或者用窗口展示
# # 3 创建一个窗口
# cv2.namedWindow('image')
# # 4 展示窗口
# cv2.imshow('image',imgage_dst)
# # 5 窗口等待
# cv2.waitKey(0)
# # 6 销毁窗口
# cv2.destroyAllWindows()
2、算法(以后遇到类似案例就可以直接调用该方法)
匀速运动公式:
(1) v=v0+at
(2) s=v0t+½at²

#拿到移动轨迹,模仿人的行为,先匀加速后匀减速
def get_tracks(distance):
v = 0 # 初速度
t = 0.3 # 以单位时间为0.3s来统计轨迹,即0.3s内的位移
tracks = [] # 位置/轨迹列表,列表内的一个元素代表0.3s的位移
current = 0 # 当前的位移
mid = distance*4/5 # 到达mid值开始减速
while current < distance:
if current < mid:
a = 2 #加速度越小,单位时间的位移越小,模拟的轨迹就越多越详细
else:
a = -3
v0 = v # 初速度
s = v0*t+0.5*a*(t**2) # 0.3秒内的位移
current += s # 当前的位置
tracks.append(round(s)) # 添加轨迹到列表
v = v0 + a*t # 速度已达到v 该速度作为下次的初速度
return tracks
print(get_tracks(27))
3、行为验证(滑块验证)的实现:以登录豆瓣为例
解决方案: selenium(鼠标行为链) + 算法
原理:完全模拟人的行为,按住滑块,拖动到目标缺口位置。
具体思路:
我们将目标图片和目标缺口的距离分成2部分。前面一部分我们就刷的一下拖过去。后面一部分我们可以先匀加速然后在匀减速,这个过程用算法来实现。
按住拖动按钮;拖动到目标缺口 ;松开。

案例:豆瓣登录
(1)切换iframe标签:switch_to.frame()


(2)点击选择登录方式:账号密码登录

(3)我们发现整个滑块验证图片,又是在一个iframe标签中,

所以我们接着切换iframe标签:

(4)定位滑块拖钮,并用鼠标行为链来拖动它:


(5)调用算法来移动剩下的距离
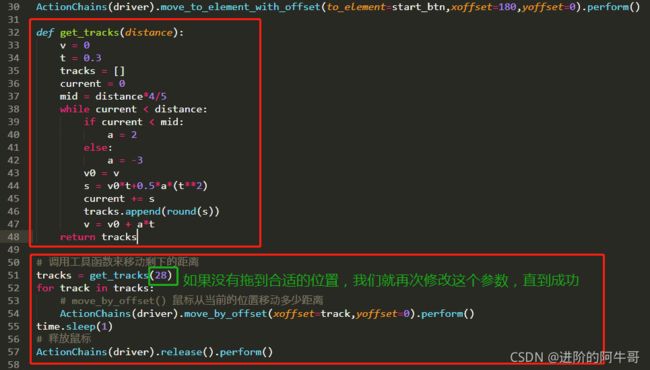
move_to_element_with_offset():鼠标移动到距某个元素(左上角坐标)多少距离的位置
move_by_offset() :鼠标从当前的位置移动多少距离
(6)为了更加自动、循环验证,以致成功,我们也可以编写一个循环(一次验证不成功时,需要点击刷新按钮更新验证图片)。
完整代码:
from selenium import webdriver
from selenium.webdriver import ActionChains
import time
def get_tracks(distance):
v = 0
t = 0.3
tracks = []
current = 0
mid = distance*4/5
while current < distance:
if current < mid:
a = 2
else:
a = -3
v0 = v
s = v0*t+0.5*a*(t**2)
current += s
tracks.append(round(s))
v = v0 + a*t
return tracks
driver = webdriver.Chrome(r'C:\Users\Administrator\Desktop\chromedriver_win32\chromedriver.exe')
driver.get('https://www.douban.com/')
# 切换iframe 登录
login_frame = driver.find_element_by_xpath('//*[@id="anony-reg-new"]/div/div[1]/iframe')
driver.switch_to.frame(login_frame)
# 切换登录方式
driver.find_element_by_class_name('account-tab-account').click()
time.sleep(2)
# 定位账号和密码 并输入内容
driver.find_element_by_id('username').send_keys('15989356970')
time.sleep(1)
driver.find_element_by_id('password').send_keys('zq15982197825')
# 点击登录按钮
driver.find_element_by_class_name('btn').click()
# 滑块验证图片需要加载
time.sleep(5)
verify_iframe = driver.find_element_by_xpath('//*[@id="tcaptcha_iframe"]')
driver.switch_to.frame(verify_iframe)
time.sleep(2)
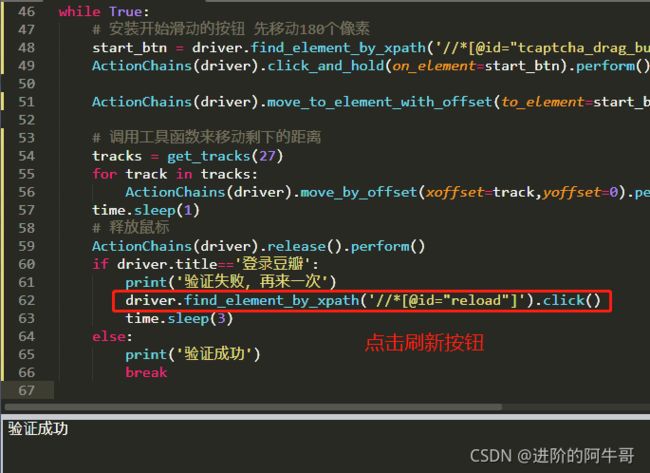
while True:
# 安装开始滑动的按钮 先移动180个像素
start_btn = driver.find_element_by_xpath('//*[@id="tcaptcha_drag_button"]')
ActionChains(driver).click_and_hold(on_element=start_btn).perform()
ActionChains(driver).move_to_element_with_offset(to_element=start_btn,xoffset=180,yoffset=0).perform()
# 调用工具函数来移动剩下的距离
tracks = get_tracks(27)
for track in tracks:
ActionChains(driver).move_by_offset(xoffset=track,yoffset=0).perform()
time.sleep(1)
# 释放鼠标
ActionChains(driver).release().perform()
if driver.title=='登录豆瓣':
print('验证失败,再来一次')
driver.find_element_by_xpath('//*[@id="reload"]').click()
time.sleep(3)
else:
print('验证成功')
break
结果: