ChatGPT学习
ChatPGPT网址:
https://chat.openai.com
OpenAPI网址:
https://platform.openai.com/
可获得密钥,调用api
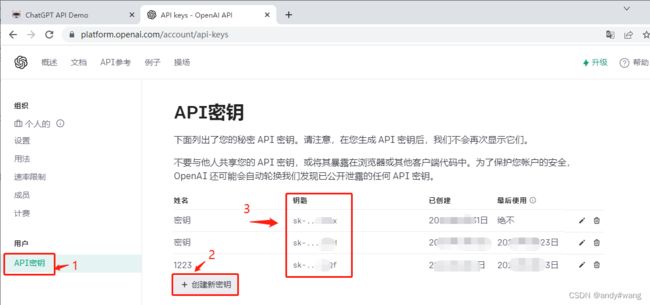
ChatPGPT 3.5本地运行Demo:
GitHub部署包

1.打开文件.env,设置SECRET_KEY,使用platform产生的密钥即可。SITE_PASSWORD为网站登录密码。
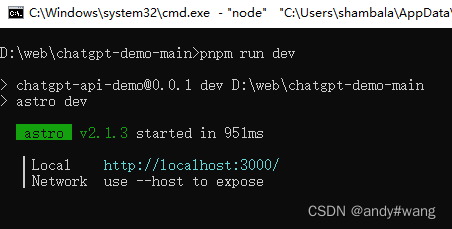
2.运行start.bat文件,运行成功后显示:
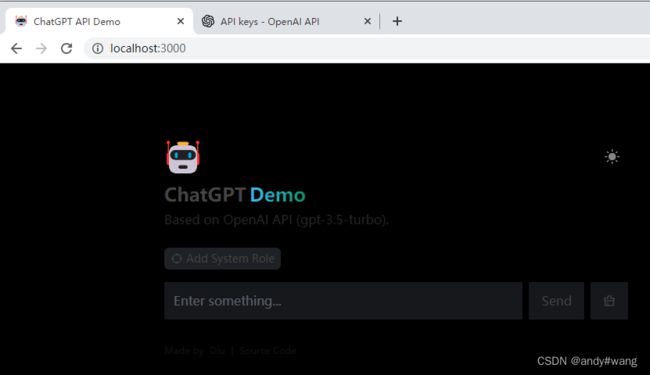
 3.地址栏输入:http://localhost:3000/
3.地址栏输入:http://localhost:3000/
国内GPT:
1.文心一言:
https://yiyan.baidu.com/welcome
2.百川大模型:
https://www.baichuan-ai.com/home
3.智谱清言:
https://zhipuai.cn/
4.讯飞星火:
https://xinghuo.xfyun.cn/
5.通义千问:
https://tongyi.aliyun.com/
免费使用:
coze:需
https://www.coze.com/
AIchatOS2:不需
https://chat18.aichatos.xyz/#/chat/1698139908144
语言大模型产生过程:
深度学习框架:
TensorFlow、PyTorch和Keras是深度学习领域的三大主流框架,它们各自具有不同的特点和适用场景。
1.TensorFlow是谷歌开发的一个开源深度学习框架,提供了强大的计算图模型,支持多种编程语言、平台和部署方式。TensorFlow的计算图模型可以自动处理并行计算和内存管理,提高计算效率。同时,TensorFlow还支持多种高级功能,如自动微分、分布式训练、模型优化等。由于其高度的灵活性和扩展性,TensorFlow在工业界和学术界都得到了广泛应用。
2.PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。PyTorch提供了一种动态计算图的编程模型,使得计算流程可以在运行时动态创建和修改,方便用户进行调试和开发。PyTorch还提供了强大的GPU加速的张量计算和自动求导系统,使得深度神经网络的训练更加高效。由于其易用性和灵活性,PyTorch在初学者和快速原型设计中非常受欢迎。
3.Keras是一个位于其他深度学习框架之上的高级API,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口。Keras的优点在于其易用性,使得定义神经网络非常直观和简单。同时,Keras还提供了丰富的模型库和可视化工具,方便用户进行模型的设计、训练、评估和部署。由于其易用性和直观性,Keras在快速原型设计和初学者入门中得到了广泛应用。
综上所述,TensorFlow、PyTorch和Keras各有特点和优势,用户可以根据具体需求选择合适的框架进行深度学习开发和部署。
模型结构:
模型结构是指深度学习模型中各层之间的连接方式和组织形式。以下是一些常见的模型结构:
1.线性模型:最简单的深度学习模型之一,通过将输入数据与学习到的权重进行线性组合来进行预测。
2.全连接神经网络:最常用的模型结构之一,由多个全连接层组成,每个全连接层将输入数据的每个特征与该层的权重进行线性组合,并通过一个非线性激活函数进行变换。
3.卷积神经网络(CNN):适用于图像和视频数据处理,通过在局部空间上应用卷积核来提取特征。
4.循环神经网络(RNN):适用于序列数据和时间序列数据处理,通过将上一个时间步的隐藏状态传递给下一个时间步来保持状态信息。
5.Transformer:一种基于自注意力机制的模型结构,通过多头自注意力机制和位置编码来捕捉输入数据的内在依赖关系。
6.GAN(生成对抗网络):由生成器和判别器两个网络组成,通过相互竞争来生成新的数据样本。
7.VAE(变分自编码器):通过编码器和解码器两个网络来学习输入数据的潜在表示和重建输入数据。
8.Autoencoder:一种无监督的神经网络模型,通过编码器和解码器两个网络来学习输入数据的压缩表示和重建输入数据。
以上是一些常见的模型结构,每种结构都有其特点和适用场景。在实际应用中,需要根据具体任务和数据特征选择合适的模型结构。
部署大模型时,都需要哪些数据?
数据主要包括:
1.模型参数:训练好的大模型的参数,这些参数是在训练过程中学习得到的。
2.模型结构:定义模型中各层和节点的结构和连接方式,以及训练过程中使用的算法和优化器等。
3.训练数据:用于训练大模型的原始数据集,这些数据集通常需要进行预处理和标注。
4.标签数据:对于需要标签的任务,需要提供相应的标签数据。
5.配置文件:包含部署过程中需要的各种配置信息,例如模型输入和输出的路径、超参数设置等。
6.依赖库和框架:部署大模型所需的深度学习框架和依赖库,例如TensorFlow、PyTorch等。