Apache DolphinScheduler 3.1.8 保姆级教程【安装、介绍、项目运用、邮箱预警设置】轻松拿捏!
概述
Apache DolphinScheduler 是一个分布式易扩展的可视化 DAG 工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。
Apache DolphinScheduler 旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。解决数据研发 ETL 依赖错综复杂,无法监控任务健康状态的问题。DolphinScheduler 以 DAG(Directed Acyclic Graph,DAG)流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。

特性
1.*简单易用 *
可视化 DAG,对待用户友好,通过拖拽定义工作流的,模块化操作,轻松定制和维护。
2.丰富的使用场景
支持多种任务类型,例如:Shell、MR、Spark、SQL 等 10 余种任务类型,支持跨语言,易于扩展。
3.丰富的工作流操作
工作流程可以定时、暂停、恢复和停止,便于维护和控制全局和本地参数。
- High Reliability 高可靠性
去中心化设计,确保稳定性,原生 HA 任务队列支持,提供过载容错能力。DolphinScheduler 能提供高度稳健的环境。
5.High Scalability 高扩展性
支持多租户和在线资源管理,支持每天 10 万个数据任务的稳定运行。
去中心化设计,让系统的控制和决策权分散到不同的节点或组件,而不是集中在单一中心节点。这意味着系统中的各个组件可以独立运作和做出决策,而不必依赖于一个中心控制节点。 在 DolphinScheduler 中,去中心化的设计意味着任务调度和管理系统的各个组件能够独立运作,而不需要依赖于一个单一的中心节点。
架构
DolphinScheduler 的架构设计允许分布式任务调度和管理,以满足大规模数据处理和工作流需求。
1. Master Server(主服务器):
DolphinScheduler 主服务器是整个系统的核心,它负责调度、管理和监控所有任务和工作流。
主服务器维护任务元数据和工作流定义,包括任务依赖关系、任务类型、调度计划等信息。
主服务器接收用户提交的任务和工作流,并决定如何调度和执行它们。
2. Worker Server(工作节点):
DolphinScheduler 工作节点是执行任务的节点,它们分布在集群中,可以是物理机器或虚拟机器。
工作节点根据主服务器的调度计划执行任务,可以处理各种不同类型的任务,如 Shell 脚本、Python 脚本、Hive、Spark、Flink 等。
工作节点还负责监控任务的执行状态和性能,并将信息报告给主服务器。
3. ZooKeeper:
DolphinScheduler 使用 Apache ZooKeeper 来协调主服务器和工作节点之间的通信和状态管理。
ZooKeeper 负责维护一致性和协调,以确保系统的高可用性和容错性。
4. 数据存储:
DolphinScheduler 使用关系型数据库(如 MySQL)来存储任务元数据、工作流定义和调度计划等信息。
数据存储用于持久化和管理系统的状态和元数据。
5. Web界面:
- DolphinScheduler 提供了一个可视化的 Web 界面,用户可以使用该界面来配置任务和工作流,监控任务的执行状态,以及管理系统的权限和用户。
工作流程
整个 DolphinScheduler 系统的工作流程如下:
用户使用 Web 界面创建和配置任务和工作流。
主服务器接收用户的任务和工作流定义,然后根据定义生成调度计划。
主服务器将调度计划发送给工作节点。
工作节点执行任务,监控任务的状态和性能,并将信息报告给主服务器。
用户可以通过 Web 界面查看任务的执行状态和日志,同时系统支持告警功能,以便在任务失败或性能下降时通知管理员。
DolphinScheduler 和 Azkaban 的比较
DolphinScheduler 和 Azkaban 都是用于任务调度和工作流管理的开源工具,但它们之间存在一些区别,包括以下方面:
1. 开发背景和社区支持
DolphinScheduler 是中国社区开源项目,得到了国内外开发者和组织的积极支持和贡献。
Azkaban 是由 LinkedIn 开发的,后来成为了开源项目,得到了 LinkedIn 和其他组织的支持。
2. 历史和成熟度
Azkaban 的项目起源较早,因此在一些组织中有更广泛的应用和更成熟的生态系统。
DolphinScheduler 是一个相对较新的项目,仍在不断发展中。
3. 特性和功能
DolphinScheduler 提供了更多种类的任务类型,包括Shell、Python、Hive、Spark、Flink等,以满足不同数据处理需求。
Azkaban 也支持多种任务类型,但其生态系统不如 DolphinScheduler 多样化。
4. 去中心化和架构设计
DolphinScheduler 强调去中心化的设计,允许任务调度和管理系统的各个组件独立运作。
Azkaban 通常具有中心化的控制节点来协调任务的调度和执行。
就我个人而言更喜欢用 DolphinScheduler,去中心化的设计更加便利,生态也特别丰富,前端 UI 也十分人性化,编辑任务流等方面都比 Azkaban 使用起来更加舒适。
DolphinScheduler 分布式安装
基础环境说明与配置
官方给出的系统要求以及服务器配置如下所示:
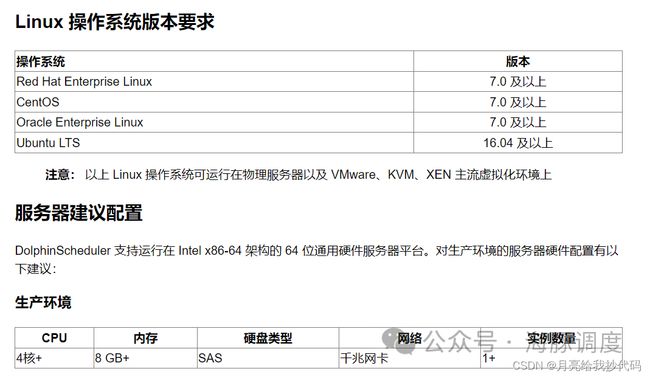
服务器资源没有那么多也无所谓,官方的配置是生产环境的配置,学习或者测试环境低点也能玩。
请在进行下列步骤前,确保集群之间已经设置好了免密登录,且指定用户具有 sudo 权限, 集群中已经安装 JDK1.8、MySQL、Zookeeper(3.4.6+) 并能正常使用。
sudo 用户权限添加
这里以创建 dolphinscheduler 用户进行举例,开始前,请先切换到 root 用户。
创建用户及授权的指令在主从节点都要执行!
# 先切换到 root 用户
su root
# 添加用于部署的用户
useradd dolphinscheduler
# 添加密码
echo "123456" | passwd --stdin dolphinscheduler
# 配置 sudo 免密
sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers
# 修改目录权限,使得部署用户对二进制包解压后的 apache-dolphinscheduler-*-bin 目录有操作权限(主节点执行)
chown -R dolphinscheduler:dolphinscheduler apache-dolphinscheduler-*-bin免密配置
因为是分布式部署,所以需要设置主机免密登录从机。
# 先切换到部署用户
su dolphinscheduler
# 在主机执行(生成公钥与私钥)
ssh-kegen -t rsa
# 在主机执行,分发公钥(主机自身也要设置免密)
ssh-copy-id hadoop120
ssh-copy-id hadoop121
ssh-copy-id hadoop122获取安装包
官网下载:DolphinScheduler V3.1.8
下拉选择二进制包:
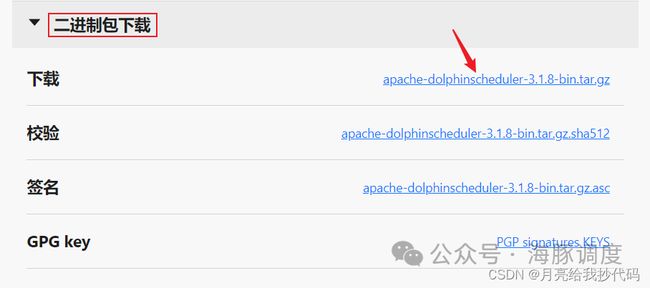
点击后跳转到 Apache 进行下载: 
下载进程树分析
# macOS 安装 pstree
# Fedora/Red/Hat/CentOS/Ubuntu/Debian 安装 psmisc
# CentOS 示例,每台机器都需要安装:
sudo yum install -y psmisc
解压缩
tar -zxvf apache-dolphinscheduler-3.1.8-bin.tar.gz -C /opt/module/解压后的文件目录如下所示:

这个目录并不是最后实际使用的,它只是一个安装包目录,还需要进一步配置安装。
创建 MySQL 库
这里使用 MySQL 对 DolphinScheduler 的元数据进行管理,不使用默认的数据库 H2。
在 MySQL 中创建 DolphinScheduler 的专用用户与存储库,并给予其访问权限:
-- 创建指定存储库
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
-- 创建 DolphinScheduler 用户
CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY '000000';
-- 给予库的访问权限
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%';
flush privileges;如果提示密码安全等级过低,但还想使用该密码,则需要调整 MySQL 密码安全验证策略,如下所示:
set global validate_password_policy=0;
set global validate_password_length=4;
拷贝 MySQL 驱动文件
MySQL 驱动文件必须使用 JDBC Driver 8.0.16 及以上的版本,需要手动下载 mysql-connector-java 并移动到 DolphinScheduler 的每个模块的 libs 目录下,其中包括 5 个目录:
api-server/libsalert-server/libsmaster-server/libsworker-server/libstools/libs
# 进入解压目录中(略)
# 复制驱动
cp /opt/software/mysql-connector-j-8.0.31.jar ./api-server/libs/
cp /opt/software/mysql-connector-j-8.0.31.jar ./alert-server/libs/
cp /opt/software/mysql-connector-j-8.0.31.jar ./master-server/libs/
cp /opt/software/mysql-connector-j-8.0.31.jar ./worker-server/libs/
cp /opt/software/mysql-connector-j-8.0.31.jar ./tools/libs/修改 install_env.sh 文件
文件 install_env.sh 描述了哪些机器将被安装 DolphinScheduler 以及每台机器对应安装哪些服务。
在解压路径下 bin/env/install_env.sh 中找到此文件,配置详情如下所示:
# 进入解压目录中(略)
vim ./bin/env/install_env.sh
# 修改下列配置信息

修改 dolphinscheduler_env.sh 文件
修改文件 ./bin/env/dolphinscheduler_env.sh 中的配置,其中包括 DolphinScheduler 的数据库配置、一些任务类型外部依赖路径或库文件,如 JAVA_HOME 和 SPARK_HOME 都是在这里定义的。
# 进入解压目录中(略)
vim ./bin/env/dolphinscheduler_env.sh
# 文件配置信息如下所示:
# JAVA_HOME 用于启动 DolphinScheduler
export JAVA_HOME=${JAVA_HOME:-/opt/module/jdk}
# 数据库配置信息
export DATABASE=${DATABASE:-mysql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:mysql://hadoop120:3306/dolphinscheduler?useSSL=false&useUnicode=true&allowPublicKeyRetrieval=true&characterEncoding=UTF-8"
export SPRING_DATASOURCE_USERNAME=dolphinscheduler
export SPRING_DATASOURCE_PASSWORD=000000
# DolphinScheduler服务器相关配置,这里用默认的就好了
export SPRING_CACHE_TYPE=${SPRING_CACHE_TYPE:-none}
export SPRING_JACKSON_TIME_ZONE=${SPRING_JACKSON_TIME_ZONE:-UTC}
export MASTER_FETCH_COMMAND_NUM=${MASTER_FETCH_COMMAND_NUM:-10}
# 注册表中心配置(Zookeeper),确定注册表中心的类型和链接
export REGISTRY_TYPE=${REGISTRY_TYPE:-zookeeper}
export REGISTRY_ZOOKEEPER_CONNECT_STRING=${REGISTRY_ZOOKEEPER_CONNECT_STRING:-hadoop120:2181,hadoop121:2181,hadoop122:2181}
# 任务相关组件路径配置,如果使用相关任务,则需要更改配置
export HADOOP_HOME=${HADOOP_HOME:-/opt/module/hadoop-3.3.4}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/opt/module/hadoop-3.3.4/etc/hadoop}
export SPARK_HOME=${SPARK_HOME:-/opt/module/spark-3.3.1}
export HIVE_HOME=${HIVE_HOME:-/opt/module/hive-3.1.3}
export DATAX_HOME=${DATAX_HOME:-/opt/module/datax}
#export PYTHON_LAUNCHER=${PYTHON_LAUNCHER:-/opt/soft/python}
#export FLINK_HOME=${FLINK_HOME:-/opt/soft/flink}
# 配置路径导出
export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$DATAX_HOME:/bin:$PATH注意:上列配置中的主机地址、相关组件存储路径请修改为你的对应值!
Python 网关配置项关闭
Python 网关服务会默认与 api-server 一起启动,如果不想启动则需要更改 api-server 配置文件 api-server/conf/application.yaml 中的 python-gateway.enabled : false 来禁用它。
vim ./api-server/conf/application.yaml

初始化数据库并安装 DolphinScheduler
# 进入解压目录中(略)
# 初始化数据库
bash tools/bin/upgrade-schema.sh正常初始化完成如下所示:
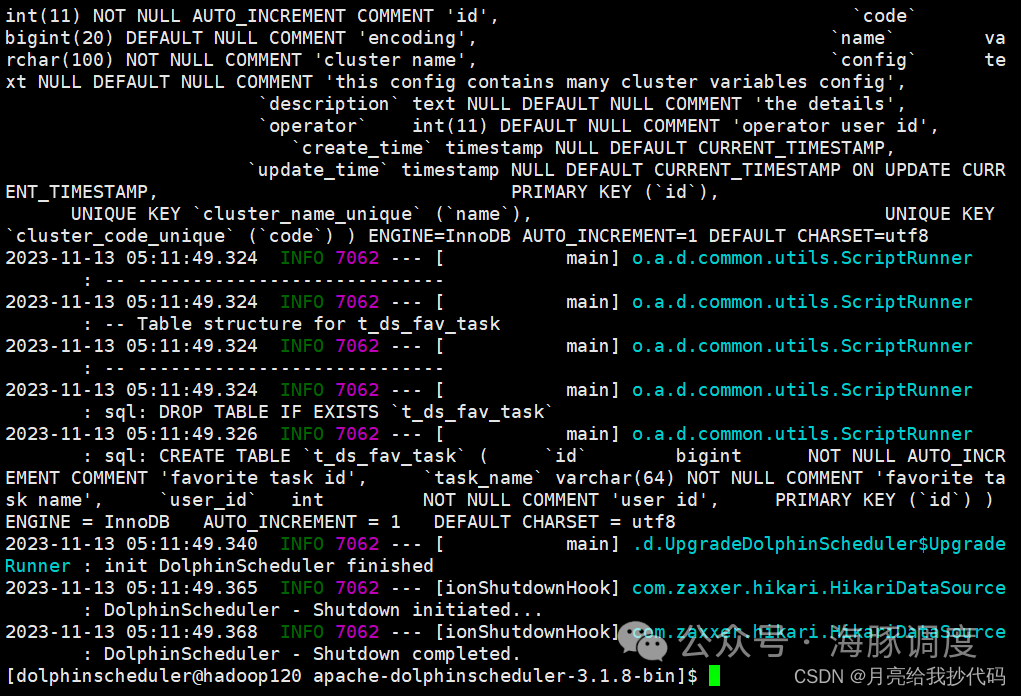
现在开始进行分布式部署,使用上面( install_env.sh 文件中)指定的部署用户执行如下命令完成部署,部署后的运行日志将存放在 logs 文件夹内。
# 先启动Zookeeper,主从节点都要启动
zkServer.sh start
bash ./bin/install.sh安装脚本执行完成后,会出现各个节点的状态信息:

我们去对应的安装目录下,可以看到已经安装好的 DolphinScheduler 相关文件夹(每台机器都在指定的相同目录下):

启停命令
启动 DolphinScheduler 前,请先启动 Zookeeper 服务!
下列部分命令注意与 Hadoop 中的进行区分,脚本名字是一样的,不要启动错了。
# 进入 DolphinScheduler 安装后的目录
# 一键开启集群所有服务
bash ./bin/start-all.sh
# 一键停止集群所有服务
bash ./bin/stop-all.sh
# 启停 Master
bash ./bin/dolphinscheduler-daemon.sh stop master-server
bash ./bin/dolphinscheduler-daemon.sh start master-server
# 启停 Worker
bash ./bin/dolphinscheduler-daemon.sh start worker-server
bash ./bin/dolphinscheduler-daemon.sh stop worker-server
# 启停 Api
bash ./bin/dolphinscheduler-daemon.sh start api-server
bash ./bin/dolphinscheduler-daemon.sh stop api-server
# 启停 Alert
bash ./bin/dolphinscheduler-daemon.sh start alert-server
bash ./bin/dolphinscheduler-daemon.sh stop alert-server执行脚本启动命令(bash ./bin/start-all.sh)后,如果运行正常,可以通过 jps 命令查询到节点的启动情况,如下所示:

到此为止,DolphinScheduler 分布式就已经部署完成了。
登录 DolphinScheduler
通过浏览器访问地址 http://hadoop120:12345/dolphinscheduler/ui 即可登录系统UI(替换为你的主机地址),进入网站后会来到登录界面:

默认的用户名和密码是:admin / dolphinscheduler123,该用户为管理员用户。
登录成功后,进入首页,如下所示:

登录 DolphinScheduler 操作完成。
安全中心介绍
安全中心只有管理员账户才有权限操作,其中包括 Yarn 队列管理、租户管理、用户管理、告警组管理、worker 分组管理、令牌管理等功能,在用户管理模块可以对资源、数据源、项目等授权
租户管理
租户管理允许管理员配置和管理不同租户的权限和资源使用情况。
租户是 DolphinScheduler 中的一个概念,其实就是对应着 Linux 系统的一个用户,代表着一个独立的业务单位或用户组。
添加租户
添加需要执行任务的租户,为其分配队列,如果当前 Yarn 中没有配置多个队列,那么就只有 default 默认队列。
用户管理
用户管理模块允许管理员创建、编辑和删除用户账户,并配置用户的访问权限。通过用户管理,可以细粒度地控制用户对 DolphinScheduler 的操作权限。
添加用户
设置登录 DolphinScheduler 的新用户,关联指定租户、队列、邮件以及手机号。

告警组与告警实例管理
告警组管理用于配置系统中的告警组,定义告警的接收人和通知方式。这样,在系统出现异常或故障时,相关人员可以迅速得到通知,以便及时采取行动。
添加告警实例
定义一个告警的类别以及实例信息,填写对应的信息。

添加告警组
为设置的告警实例分配告警组。
Worker 分组管理
Worker 分组管理允许管理员对 DolphinScheduler 中的 Worker 节点进行分组和管理,这有助于优化任务调度和资源利用。
添加 Worker 分组管理

Yarn 队列管理
DolphinScheduler 允许管理员配置和管理 YARN 中的队列。
队列是资源管理的基本单位,通过它可以为不同的工作流、任务或用户分配不同的资源配额。
添加 Yarn 队列
环境管理
用于自定义环境信息,为某些任务定制处理环境。
添加环境

令牌管理
令牌管理模块用于生成和管理访问令牌,这些令牌可以作为一种身份验证凭据,限制对敏感操作的访问。
添加令牌管理
监控中心介绍
用于查看当前主从节点的运行状态,其中包括 CPU与内存的使用情况、磁盘可用空间、负载量等信息。

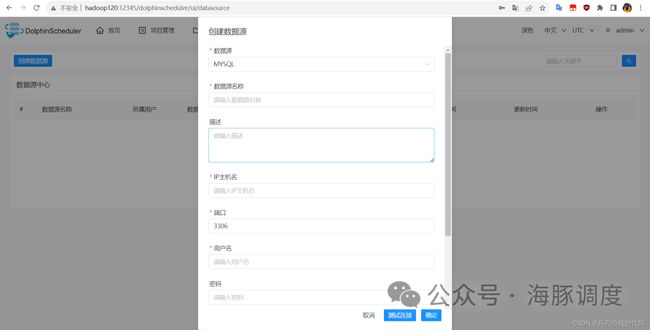
数据源中心介绍
DolphinScheduler 的数据源中心(Data Source Center)是一个重要模块,主要用于集中管理和配置各种数据源的连接信息,为工作流和任务提供可靠的数据访问。
数据质量介绍
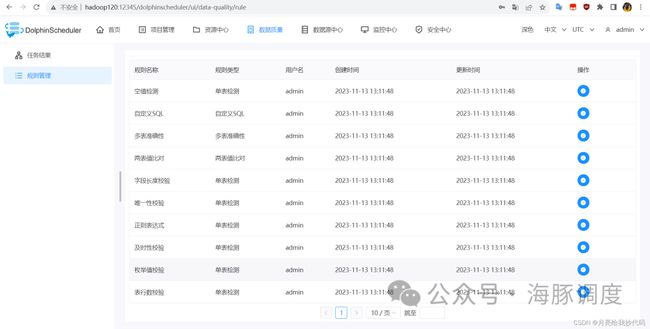
数据质量任务是用于检查数据在集成、处理过程中的数据准确性。本版本的数据质量任务包括单表检查、单表自定义SQL检查、多表准确性以及两表值比对。
官方说明:数据质量任务的运行环境为 Spark2.4.0,其他版本尚未进行过验证,用户可自行验证。
资源中心介绍
DolphinScheduler 的资源中心包括文件管理、UDF 管理以及任务组管理,其作用主要就是管理这些资源,让用户管理起来更加方便、简洁明了。

资源中心默认不开启,上传文件或新建文件时会提示【存储未启用】:

如果想要使用,需要修改配置文件参数,以集群模式或者伪集群模式部署 DolphinScheduler,要对 DolphinScheduler 安装路径下的两个文件进行配置:
api-server/conf/common.propertiesworker-server/conf/common.properties


这两个文件修改的参数一样。
如果是分布式,修改完成后,需要进行分发,同步这两个文件到其它机器上。
# 进入 DolphinScheduler 安装目录
cd /opt/module/dolphinscheduler
rsync api-server/conf/common.properties hadoop121:/opt/module/dolphinscheduler/api-server/conf/
rsync api-server/conf/common.properties hadoop122:/opt/module/dolphinscheduler/api-server/conf/
rsync worker-server/conf/common.properties hadoop121:/opt/module/dolphinscheduler/worker-server/conf
rsync worker-server/conf/common.properties hadoop122:/opt/module/dolphinscheduler/worker-server/conf在 HDFS 上创建指定资源存储路径并授权:
# 创建资源存储目录
hadoop fs -mkdir -p /dolphinscheduler
# 创建文件夹组设定为 DolphinScheduler 的用户
hadoop fs -chown -R dolphinscheduler:dolphinscheduler /dolphinscheduler
# 添加权限
hadoop fs -chmod 777 /dolphinscheduler最后,重启 DolphinScheduler 即可完成:
# 进入 DolphinScheduler 的安装目录,注意与Hadoop的启动命令进行区分!
cd /opt/module/dolphinscheduler
# 一键停止集群所有服务
bash ./bin/stop-all.sh
# 一键开启集群所有服务
bash ./bin/start-all.sh项目管理介绍
在 DolphinScheduler 中,项目是一个逻辑上的容器,用于组织和管理相关联的任务和工作流。项目提供了一种层次结构,帮助用户将调度系统中的任务按照业务或项目的逻辑进行划分。
在项目中,用户可以创建和组织各种任务和工作流。任务可以是简单的脚本任务、MapReduce 任务等,而工作流则可以是一系列有序的任务组合。通过项目管理,用户可以更好地组织和管理这些任务和工作流,实现更加清晰的任务调度和执行。

项目运用
创建租户与用户
使用管理员账户进入安全中心,创建租户与用户,后面创建项目都是使用普通用户进行操作,而不是直接使用管理用户进行创建。
创建租户
创建用户
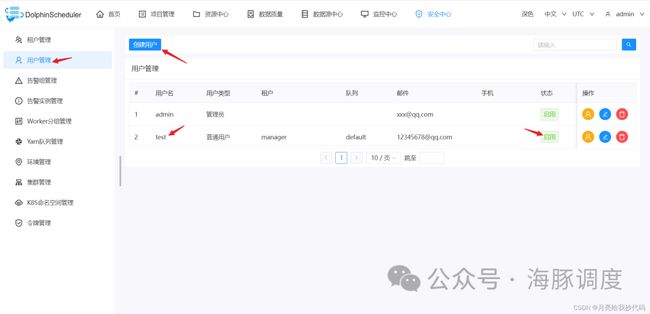
注意,用户创建完成后,需要启用,否则不生效。
创建项目
点击【项目管理】—— 【创建项目】

项目创建完成后,点击项目名称,进入工作流的设置界面:

创建工作流
点击工作流定义,选择需要创建的工作流类型,然后编辑工作流相关参数。

多个节点之间如果要建立依赖关系,可以直接通过鼠标拖动的方式来实现,将鼠标放置到圆点上,就会出现一个 + 号,然后连接到需要关联的任务。

也可以直接双击某个节点建立依赖关系,在任务的编辑窗口中,下拉到最后面,可以看到有个前置任务的选项:

我这里创建了三个 Shell 任务,每个任务打印它们的节点名称,设置依赖关系:A > B > C,如下所示:
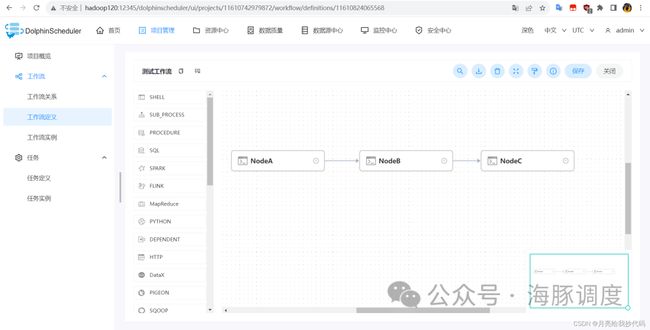
添加完成后,一定要点击保存,不然刚刚设置的内容都要重新配置。

点击执行策略,选择你需要的策略,然后点击【确定】。
授权
如果你上面的几步操作是在管理员用户中进行的,那么你需要进行授权,通过普通用户去执行任务(这里不建议直接用管理员账户执行工作流)。
授权

指定授权项目
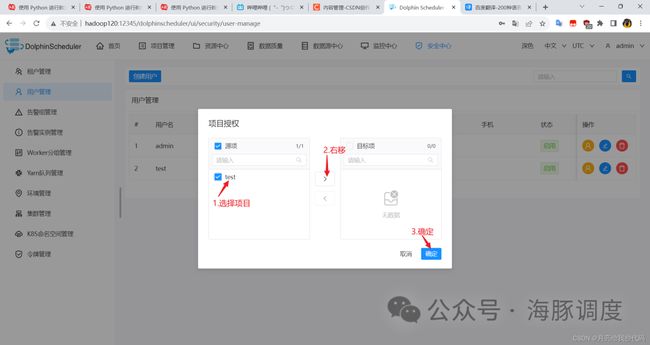
授权完成后,使用刚刚授权的普通用户登录到 DolphinScheduler。
工作流上线
工作流创建完成后,默认为下线状态,也就是不可使用的状态,如果我们需要使用工作流,需要先进行上线操作,激活该工作流。

直接点击上线按钮,无需进行确定,即可进行上线。
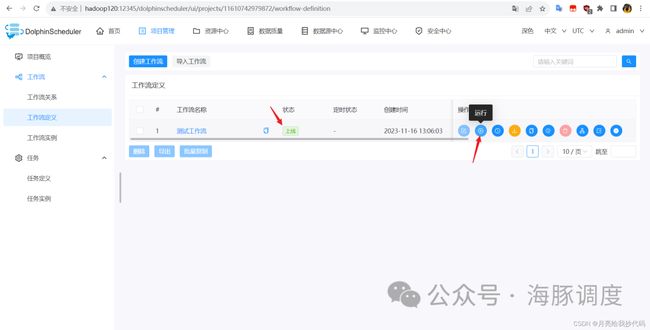
执行工作流
上线完成后,点击运行按钮,将开始运行定义的工作流。
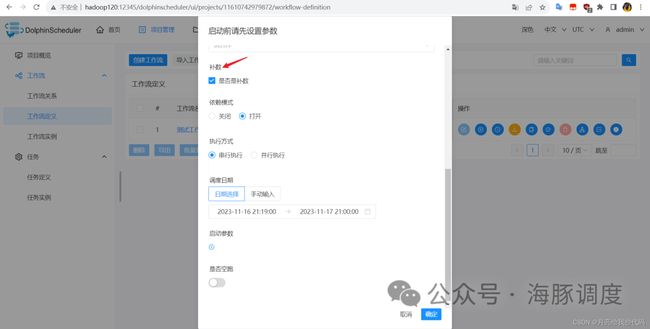
点击运行按钮后,弹出窗口,需要设置相关启动参数,点击【是否是补数】,选择依赖模式、执行方式以及调度日期。
开始运行后,可以点击工作流实例,查看任务的执行状态:

点击工作流实例名称,可以查看各个节点的执行状态:

邮箱预警设置
1. 开启 SMTP 服务
进入发送者邮箱的服务网站,这里以为网易 163 邮箱进行举例。
登录后,点击邮箱设置:
跳转到邮箱安全设置,点击【POP3/SMTP/IMAP】选项,进入管理界面,开启 IMAP/SMTP 服务与 POP3/SMTP 服务。
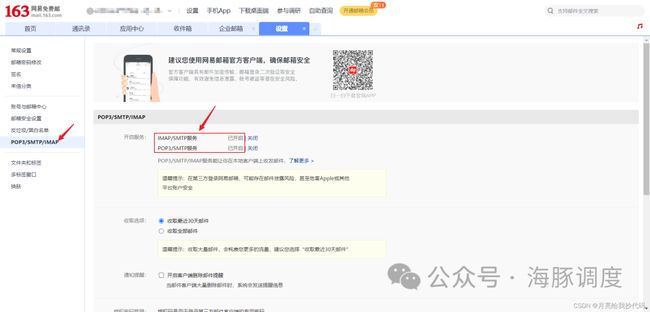
下滑选择授权码管理,新增一个授权码: 
授权码生成后马上复制保存起来(授权密码只显示一次),防止丢失或遗忘,不然又得重新搞个授权码。
2.创建告警实例
使用管理员账户登录 DolphinScheduler,点击【安全中心 —— 告警实例管理】,创建一个告警实例,类型选择【Email】。

还没有填完,下拉继续填:
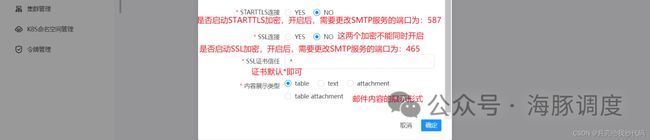
注意,加密策略前提是需要该邮箱服务器支持。
全部填写完成后,点击确定。
3.创建告警组
告警实例创建完成之后,还需要将其放到告警组里面,点击【安全中心 —— 告警组管理】,创建一个告警组。

4.执行工作流
切换到普通用户,任意创建一个项目并定义一个工作流,这里不再赘述。
工作流创建完成后,点击保存并上线该工作流,点击运行,设置启动参数,为其分配告警组:
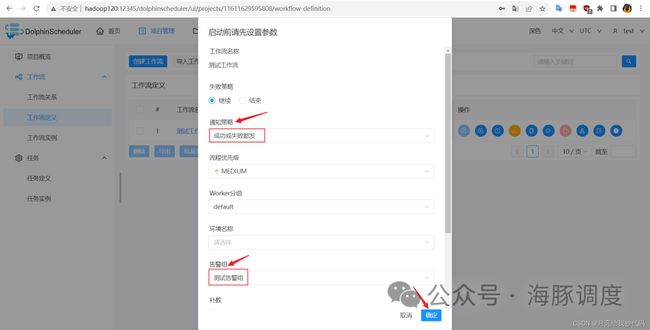
我这里选择的通知策略是不管成功或失败都发送通知,设置完成后,点击确定,等待工作流执行完成后,就会收到发送过来的通知邮件了(有 10 秒左右的延迟)。

邮箱预警设置完成。
本文由 白鲸开源科技 提供发布支持!