K8S调用GPU资源配置指南
| 时间 | 版本号 | 修改描述 | 修改人 |
|---|---|---|---|
| 2022年6月9日15:33:12 | V0.1 | 新建K8S调用GPU资源配置指南, 编写了Nvidia驱动安装过程 |
|
| 2022年6月10日11:16:52 | V0.2 | 添加K8S容器编排调用GPU撰写 |
简介
文档描述
该文档用于描述使用Kubernetes调用GPU资源的配置过程。文档会较为详细的描述在配置过程中遇到的问题和解决方式,并且会详细描述每个步骤的验证结果,该文档对于Kubernetes的使用以及GPU资源的理解有一定的辅助意义。在行文时主要描述了TensorFlow框架调用GPU、也有Pytorch调用GPU支持的过程,文档适用于运维人员、开发人员。
配置目标描述
配置过程的主要目标是实现通过yaml文件实现对于底层GPU资源的调度。为达到此目的,需要实现如下的目标:
- 完成Nvidia GPU驱动程序的安装
- 通过Tensorflow框架示例程序验证驱动程序安装成功,即验证Docker容器对于GPU资源的调用
- 完成k8s-device-plugin的安装
- 通过示例程序验证k8s-device-plugin启动成功,即验证k8s容器编排下对于GPU资源的调用
整体架构
Docker 使用容器创建虚拟环境,以便将 TensorFlow 安装结果与系统的其余部分隔离开来。TensorFlow 程序在此虚拟环境中运行,该环境能够与其主机共享资源(访问目录、使用 GPU、连接到互联网等)。行文中,可以理解,nvidia-docker2的驱动安装在每个GPU节点上。而k8s-device-plugin为k8spod网络访问GPU的资源,这也是通过驱动nvidia-docker2实现的。

环境简介
当前环境,共两个服务器,每台服务器有8张卡,可以通过命令查看nvidia-smi查看型号NVIDIA A100-SXM4-40GB。具体如下
root@node33-a100:/mnt/nas# nvidia-smi
Thu Jun 9 07:34:17 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.129.06 Driver Version: 470.129.06 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100-SXM... Off | 00000000:07:00.0 Off | 0 |
| N/A 28C P0 59W / 400W | 31922MiB / 39538MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A100-SXM... Off | 00000000:0A:00.0 Off | 0 |
| N/A 24C P0 58W / 400W | 32724MiB / 39538MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA A100-SXM... Off | 00000000:47:00.0 Off | 0 |
| N/A 34C P0 183W / 400W | 26509MiB / 39538MiB | 58% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 3 NVIDIA A100-SXM... Off | 00000000:4D:00.0 Off | 0 |
| N/A 31C P0 83W / 400W | 14036MiB / 39538MiB | 15% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 4 NVIDIA A100-SXM... Off | 00000000:87:00.0 Off | 0 |
| N/A 29C P0 75W / 400W | 24175MiB / 39538MiB | 26% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 5 NVIDIA A100-SXM... Off | 00000000:8D:00.0 Off | 0 |
| N/A 25C P0 60W / 400W | 31039MiB / 39538MiB | 31% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 6 NVIDIA A100-SXM... Off | 00000000:C7:00.0 Off | 0 |
| N/A 24C P0 58W / 400W | 31397MiB / 39538MiB | 11% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 7 NVIDIA A100-SXM... Off | 00000000:CA:00.0 Off | 0 |
| N/A 28C P0 61W / 400W | 26737MiB / 39538MiB | 20% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
上述输出的各项指标可以参见下图:

nvidia-smi的用法可以参见Nvidia-smi简介及常用指令及其参数说明。
两台Ubuntu组成了K8S集群。
root@node33-a100:/mnt/nas# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node33-a100 Ready master 15d v1.18.2
node34-a100 Ready <none> 15d v1.18.2
NVIDIA 驱动架构
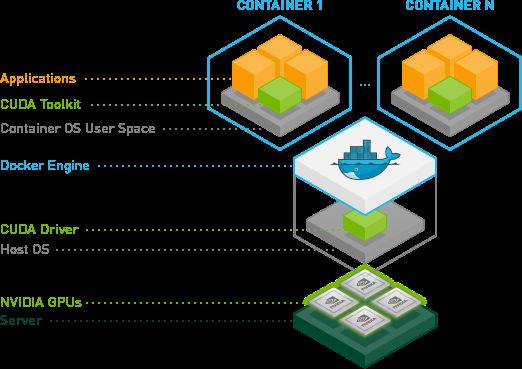
配置步骤
为了使用系统支持多版本TensorFlow,使用Docker容器环境来隔离不同版本是非常简单高效的方式。首先我们在部署了k8s的两个节点上(当然已经安装了Docker运行环境)。根据docker版本,在TensorFlow官网上指引我们要安装Nvidia 驱动。
root@node33-a100:~/gpu# docker version
Client: Docker Engine - Community
Version: 19.03.13
API version: 1.40
Go version: go1.13.15
Git commit: 4484c46d9d
Built: Wed Sep 16 17:02:36 2020
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 19.03.13
API version: 1.40 (minimum version 1.12)
Go version: go1.13.15
Git commit: 4484c46d9d
Built: Wed Sep 16 17:01:06 2020
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.4.3
GitCommit: 269548fa27e0089a8b8278fc4fc781d7f65a939b
nvidia:
Version: 1.0.0-rc92
GitCommit: ff819c7e9184c13b7c2607fe6c30ae19403a7aff
docker-init:
Version: 0.18.0
GitCommit: fec3683
然后可以通过TensorFlow官网上的例子,来验证使用Docker容器TensorFlow访问GPU是否实现。

TensorFlow调用GPU
Nvidia驱动安装
Nvidia驱动的安装是在所有GPU节点都安装。
由于两个节点的操作系统为Ubuntu,因此我们可以参考Ubuntu环境安装Nvidia驱动的安装手册Installation Guide:
root@node33-a100:~/gpu# cat /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=18.04
DISTRIB_CODENAME=bionic
DISTRIB_DESCRIPTION="Ubuntu 18.04.6 LTS"
安装稳定版本,设置包仓库和GPG key:
# distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
更新包访问列表,并安装nvidia-docker2
# sudo apt-get update
# sudo apt-get install -y nvidia-docker2
在执行过程中,会出现提示是否覆盖/etc/docker/daemon.json的内容,此时注意备份,可以把daemon.json的内容和新生成的合成一体。最后的daemon.json文件内容如下所示:

重启Docker完成安装
# systemctl restart docker
安装过程问题描述
Reading from proxy failed
不知实验室网络架构,当时在执行apt-get update时,出现了如下问题:
Reading from proxy failed - read (115: Operation now in progress) [IP: *.*.*.* 443]
管理节点上执行apt-get-update可以比较顺畅的更新包列表,但是另外一个节点死活就是遇到上述的问题。当时该问题困扰了许久,尝试了另外几个节点,两个云主机可以正常执行update操作,但另外的一个k8s节点无法执行。不过不断的浏览网页最终采用禁用代理的方式解决。

apt无法获得锁
在执行安装时,出现无法活得锁的问题,参见apt install的lock问题
解决方式如下:

unboxed as root as file /root/iscos/depends/deb/InRelease
这是由于两台服务器的K8s集群采用的是指令集系统本地安装导致的,解决方式是删除了/etc/apt/的local本地源文件。
程序验证
Nvidia官网例子
在Installation Guide可以看到一个验证例子
# docker run --rm --gpus all nvidia/cuda:11.0.3-base-ubuntu20.04 nvidia-smi
能够正常打印GPU显卡信息,表明可以正确访问。
多版本TensorFlow支持
为了验证对于多个TensorFlow版本支持,本次选用了Tensorflow2和1两个版本进行验证,首先下载两个镜像:
# docker pull tensorflow/tensorflow:2.9.1-gpu
# docker pull tensorflow/tensorflow:1.15.5-gpu
使用TensorFlow官网的例子,
# docker run -it --rm tensorflow/tensorflow:2.9.1-gpu python -c "import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
2022-06-09 09:30:00.944529: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /job:localhost/replica:0/task:0/device:GPU:6 with 6026 MB memory: -> device: 6, name: NVIDIA A100-SXM4-40GB, pci bus id: 0000:c7:00.0, compute capability: 8.0
2022-06-09 09:30:00.949071: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /job:localhost/replica:0/task:0/device:GPU:7 with 10598 MB memory: -> device: 7, name: NVIDIA A100-SXM4-40GB, pci bus id: 0000:ca:00.0, compute capability: 8.0
tf.Tensor(-921.5332, shape=(), dtype=float32)
如果能像上述控制台输出tf.Tensor()则表示驱动安装成功。
上述采用了直接启动容器在容器中执行命令的方式,也可以采用如下的方式在控制台与容器交互,打印所有的GPU设备的方式来验证驱动安装的成功。


最后,也可以在交互时采用指定GPU的方式进行验证:

也可以进行接口验证:
# print (tf.test.is_gpu_available())
# tf.random.normal([2, 2])
不再赘述。
K8S容器编排调用GPU
k8s-device-plugin的项目地址位于GitHub。安装的过程参考README.md.
注意:一定要确保
/etc/docker/daemon.json中默认low-level运行时。
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
安装k8s-device-plugin.
当在k8s集群中所有的GPU节点上配置了nvidia驱动之后,可以通过部署下面的Daemonset来启动GPU支持。
在k8s管理节点上执行如下程序:
# wget https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.12.0/nvidia-device-plugin.yml
# kubectl create -f nvidia-device-plugin.yml
注意:可以简单的使用kubectl create 来部署k8s-device-plugin插件,不过官方更加推荐使用helm来部署该插件,不过在此不表了。操作了一下,也是可以实现的,需要注意的是,上述kubectl create与helm是并列关系,两者选其中一种方式即可。
使用如下命令查看插件是否运行
root@node33-a100:~/gpu# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-66bff467f8-q7pks 1/1 Running 8 15d
coredns-66bff467f8-wtm8j 1/1 Running 8 15d
etcd-node33-a100 1/1 Running 9 15d
kube-apiserver-node33-a100 1/1 Running 8 15d
kube-controller-manager-node33-a100 1/1 Running 11 15d
kube-flannel-ds-amd64-6zl2n 1/1 Running 3 3h12m
kube-flannel-ds-amd64-vl84w 1/1 Running 763 8d
kube-proxy-5nmt2 1/1 Running 9 15d
kube-proxy-j9k96 1/1 Running 8 15d
kube-scheduler-node33-a100 1/1 Running 11 15d
nvidia-device-plugin-daemonset-9tfhr 1/1 Running 0 7d1h
nvidia-device-plugin-daemonset-p27ph 1/1 Running 0 7d1h
可以看到,在k8s及群众中,两个GPU节点上都运行了nvidia-device-plugin-daemonset,其中使用的镜像就是
image: nvcr.io/nvidia/k8s-device-plugin:v0.11.0
此时,一定要通过kubectl logs查看一下插件是否启动,通过上面的控制台输出,可以看到该Daemonset位于命名空间kube-system。
root@node33-a100:~/gpu# kubectl logs nvidia-device-plugin-daemonset-p27ph
Error from server (NotFound): pods "nvidia-device-plugin-daemonset-p27ph" not found
root@node33-a100:~/gpu# kubectl logs nvidia-device-plugin-daemonset-p27ph -n kube-system
2022/06/02 09:40:59 Loading NVML
2022/06/02 09:40:59 Starting FS watcher.
2022/06/02 09:40:59 Starting OS watcher.
2022/06/02 09:40:59 Retreiving plugins.
2022/06/02 09:40:59 Starting GRPC server for 'nvidia.com/gpu'
2022/06/02 09:40:59 Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
2022/06/02 09:40:59 Registered device plugin for 'nvidia.com/gpu' with Kubelet
注意: 对于不在默认命名空间下的pod,查看pod启动日志,需要通过-n指定命名空间,不然会报错。
然后使用kubectl-describe来检查一下显示一下特定资源或者资源组的细节。
root@node33-a100:~/gpu# kubectl describe pod nvidia-device-plugin-daemonset-p27ph -n kube-system
Name: nvidia-device-plugin-daemonset-p27ph
Namespace: kube-system
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: CriticalAddonsOnly
node.kubernetes.io/disk-pressure:NoSchedule
node.kubernetes.io/memory-pressure:NoSchedule
node.kubernetes.io/not-ready:NoExecute
node.kubernetes.io/pid-pressure:NoSchedule
node.kubernetes.io/unreachable:NoExecute
node.kubernetes.io/unschedulable:NoSchedule
nvidia.com/gpu:NoSchedule
Events: <none>
为了信息的显著,上面的控制台信息有删减。可以从上述的控制台输出中查看到Conditions的输出中,判断该插件正常运行。
另外,我们也可以通过docker命令来直接查看nvidia-device-plugin容器的启动日志
root@node33-a100:~/gpu# docker ps -f name=nvidia
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6af0cf230428 6bf6d481d77e "nvidia-device-plugi…" 7 days ago Up 7 days k8s_nvidia-device-plugin-ctr_nvidia-device-plugin-daemonset-9tfhr_kube-system_58bb23d9-7692-44be-86ef-d815a7061b21_0
c8103716e8dd k8s.gcr.io/pause:3.2 "/pause" 7 days ago Up 7 days k8s_POD_nvidia-device-plugin-daemonset-9tfhr_kube-system_58bb23d9-7692-44be-86ef-d815a7061b21_0
root@node33-a100:~/gpu# docker logs 6af
2022/06/02 09:40:59 Loading NVML
2022/06/02 09:40:59 Starting FS watcher.
2022/06/02 09:40:59 Starting OS watcher.
2022/06/02 09:40:59 Retreiving plugins.
2022/06/02 09:40:59 Starting GRPC server for 'nvidia.com/gpu'
2022/06/02 09:40:59 Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
2022/06/02 09:41:00 Registered device plugin for 'nvidia.com/gpu' with Kubelet
可以看到,Docker容器的日志,与kubectl查看pods日志的输出一致。
k8s-device-plugin插件安装问题
Error from server (NotFound)
这是由于在使用kubect describe或者kubectl logs查询指定资源的信息或者日志时,默认是在default命名空间下查询的。
解决方式,添加pod对应的命名空间即可。
root@node33-a100:~/gpu# kubectl get pods nvidia-device-plugin-daemonset-9tfhr
Error from server (NotFound): pods "nvidia-device-plugin-daemonset-9tfhr" not found
root@node33-a100:~/gpu# kubectl get pods nvidia-device-plugin-daemonset-9tfhr -n kube-system
NAME READY STATUS RESTARTS AGE
nvidia-device-plugin-daemonset-9tfhr 1/1 Running 0 7d16h
root@node33-a100:~/gpu# kubectl logs nvidia-device-plugin-daemonset-9tfhr --namespace kube-system
2022/06/02 09:40:59 Loading NVML
2022/06/02 09:40:59 Starting FS watcher.
2022/06/02 09:40:59 Starting OS watcher.
2022/06/02 09:40:59 Retreiving plugins.
2022/06/02 09:40:59 Starting GRPC server for 'nvidia.com/gpu'
2022/06/02 09:40:59 Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
2022/06/02 09:41:00 Registered device plugin for 'nvidia.com/gpu' with Kubelet
Insufficient nvidia.com/gpu
在使用kubectl logs查询插件的日志时,出现了如下问题:

当出现这个问题时,请仔细检查一下是否配置了nvidia默认运行时,检查/etc/docker/daemon.json
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
检查之后,记得重启每一个GPU节点,然后重启Docker服务,不再赘述了。
另外,该问题在GitHub上也有其他人遇到。
程序验证
Tensorflow调用GPU
使用如下的yaml文件,来访问GPU资源。下面代码申请了一个GPU资源,调用了并且打印了GPU显卡信息和一个一个张量。
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: tf-test
image: tensorflow/tensorflow:2.9.1-gpu
command:
- python
- -c
- "import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000]))); gpus = tf.config.experimental.list_physical_devices(device_type='GPU'); print(gpus)"
resources:
limits:
nvidia.com/gpu: 1
tolerations:
- effect: NoSchedule
operator: Exists
使用命令创建pod
root@node33-a100:~/gpu# kubectl create -f gpu_job.yaml
pod/gpu-pod created
查看pod运行日志
root@node33-a100:~/gpu# kubectl logs gpu-pod
2022-06-10 02:50:20.852512: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-06-10 02:50:21.515055: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 5501 MB memory: -> device: 0, name: NVIDIA A100-SXM4-40GB, pci bus id: 0000:07:00.0, compute capability: 8.0
tf.Tensor(-508.727, shape=(), dtype=float32)
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
发现已经使用GPU:0号设备,并且打印了tf.Tensor张量。由于在启动Pod时,采用了Command的形式,当该命令执行完成,该Pod处于Completed状态。
Pytorch调用GPU
首先也是在集群中每个节点安装pytorch/pytorch:latest。
使用如下的yaml来验证Pytroch对于GPU资源的使用
apiVersion: v1
kind: Pod
metadata:
name: pytorch-gpu
labels:
test-gpu: "true"
spec:
containers:
- name: training
image: pytorch/pytorch:latest
Command:
- python
- -c
- "import torch as torch; print('gpu available', torch.cuda.is_available());print(torch.cuda.device_count());print(torch.cuda.get_device_name(0))"
env:
# - name: NVIDIA_VISIBLE_DEVICES
# value: none
resources:
limits:
nvidia.com/gpu: 1
tolerations:
- effect: NoSchedule
operator: Exists
上述虽然申请了一个GPU资源,并且打印0号GPU设备的名称。
使用命令启动该Pod验证pytorch对于GPU资源的可调度性
# kubectl create -f pytorch-gpu.yaml
查看pod启动日志,如下:
root@node33-a100:~/gpu# kubectl logs pytorch-gpu -f
gpu available True
1
NVIDIA A100-SXM4-40GB
这与Pod中yaml限额一致,通过输出表明Pytorch框架在k8s集群中可以正确的申请GPU资源。
总结
文档详细的讲述了为使得K8s集群发现集群中GPU资源而进行的两个配置,首先是在所有GPU节点上配置nvidia驱动nvidia-docker2,然后在k8s集群中配置k8s-device-plugin使得k8s集群可以发现底层GPU资源。通过详细记录在此过程中遇到的问题,并记录在其上建立的思考,完成本文档的撰写。
参考
本文在行文过程中重点参考的地址如下所示:
- TensorFlow安装
- nvidia container toolkit 安装指南
- k8s-device-plugin项目Readme
下载
在进行该项工作时,输出的XMind如下所示:
XMind记录配置过程