揭秘全球首个开源MoE模型:Mixtral-8x7B
1、Mixtral-8x7B为什么会火?
Mistral AI首个开源MoE大模型Mixtral 8x7B,无良媒体宣称,已经达到甚至超越了Llama 2 70B和GPT-3.5的水平。1年来全球发布1000+个大模型,都在卷decode-only大模型,突然有人告诉大家我换赛道了,其他人怎么想?追还是不追?
Mistral AI和大多数LLM一样,喜欢把GPT-3.5和LLaMA当中靶子。MMLU/MBPP这些评测集有用吗?可以比喻成中考的月考成绩;模型训练总需要一个loss和评测集,就好像中考的时候要用月考成绩检验平时的学习水平。

大多数开源模型不是直接拿来用的,而是进行下游任务训练的。基模型的能力,决定了下游任务的下限;我们看一下Mixtral AI的官方材料:
1、Mixtral在大多数基准测试中优于Llama 2 70B,推理速度提高了6倍。
2、在某些数据集的性能表现超过GPT-3.5
3、32k tokens上下文
2. 支持英语、法语、意大利语、德语和西班牙语。
3. 在代码生成方面表现出强大的性能。
4. 可以微调为遵循指令的模型,在MT-Bench上获得8.3的分数。
Mixtral-8x7B已经开源,可以在huggingface下载。
2、Mixtral-7B,技术报告就是要这样低调的炫耀
Mixtral-8x7B怎么实现的,没有细节。但是Mistral公开了一份技术报告《Mistral 7B》,怎么,最牛掰的论文标题不带is all your need?

Mistral 7B模型,专为性能和效率而设计:在基准评估测试集,超越了Llama2 13B模型,以及在代码生成,数学和推理超过了Llama1 34B模型,基于Apache 2.0许可进行开源发布。
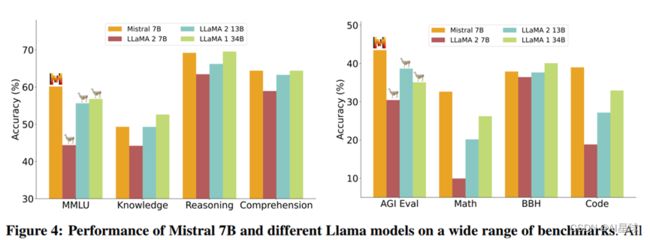
论文主要使用的是分组查询注意力(grouped-query attention,GQA)[1] 和SWA[2],降低了推理成本。
GQA
Autoregressive LLM的标准做法是缓存序列中先前标记的键(K)和值(V) 对,从而加快注意力计算速度。然而,随着上下文窗口或批量大小的增加,多头注意力 (MHA)模型中与 KV 缓存大小相关的内存成本显着增长。
下图对比了多头注意力(Multi-Head Attention)、LLaMA2中分组查询注意力(Grouped-Query Attention)、多查询注意力(Muti Query Attention)的差别
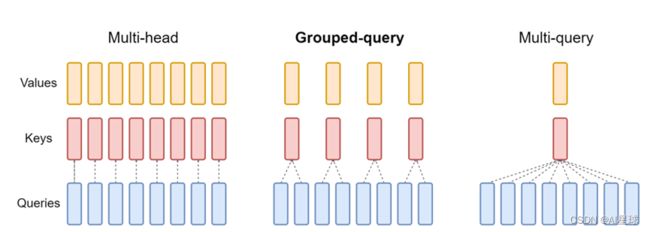
- 具有单个 KV 投影的原始多查询格式(MQA),代表大模型是ChatGLM2-6B,Google Gemini
- 具有多个 KV 投影的分组查询注意力(grouped-query attention,简称GQA),代表大模型:LLaMA2和Mistral
MAQ只使用一个键值头,虽大大加快了解码器推断的速度,但MQA可能导致质量下降,而且仅仅为了更快的推理而训练一个单独的模型可能是不可取的;
GQA一种多查询注意的泛化,它通过折中(多于一个且少于查询头的数量,比如4个)键值头的数量,使得经过强化训练的GQA以与MQA相当的速度达到接近多头注意力的质量。
SWA滑动窗口注意力机制
在普通注意力机制中,操作次数与序列长度呈二次关系,而内存随着标记数量的增加呈线性增长。在推理时,这会导致更高的延迟和更小的吞吐量,因为缓存可用性降低。
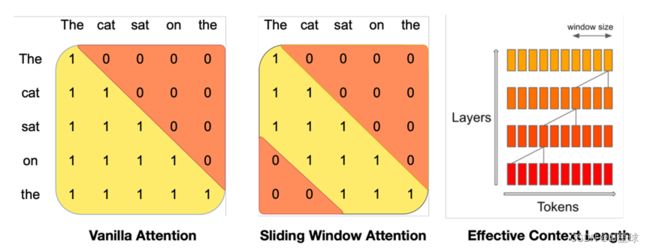
为了缓解这个问题,我们使用滑动窗口注意力(Sliding Window Attention,SWA):每个token最多可以关注到前一层的 W 个token(这里,W = 3)。请注意,滑动窗口之外的token仍然会影响下一个单词的预测。在每个注意力层,信息可以向前移动 W 个token。因此,在 k 个注意力层之后,信息最多可以向前移动 k × W 个token,既总的窗口记忆长度token。
这方法的缺点也很明显,放弃了与远距离token的直接关联:在效率和性能之间做了平衡。
Rolling buffer cache
固定的注意力窗口意味着我们可以使用滚动缓冲区缓存来限制缓存大小。缓存的固定大小为 W,时间步长 i 的键和值存储在缓存的 i mod W 位置。因此,当位置 i 大于 W 时,缓存中的过去值将被覆盖,缓存大小停止增加。我们在图 2 中提供了一个 W = 3 的示例。在长度为 32k 个标记的序列上,这将缓存内存使用量减少了 8 倍,而不影响模型质量。
凭什么是它?主角MoE?
Mixtral 是一个稀疏的专家混合网络。它是一个decode-only模型,其中feedforward block从 8 个不同的参数组中进行选择。在每一层,对于每个token,路由器网络选择两个这样的组(“专家”)来处理token并将它们加权后输出。这种技术在控制成本和延迟的同时增加了模型的参数数量,因为模型每个token只使用总参数集的一部分。坊间传言,GPT4就是MoE架构实现的。
具体来说,Mixtral 的总参数为 46.7B,但每个token只使用 12.9B 参数。因此,它以与 12.9B 模型相同的速度和成本处理输入并生成输出。Mixtral 是在从开源数据集中提取的数据上进行预训练的。
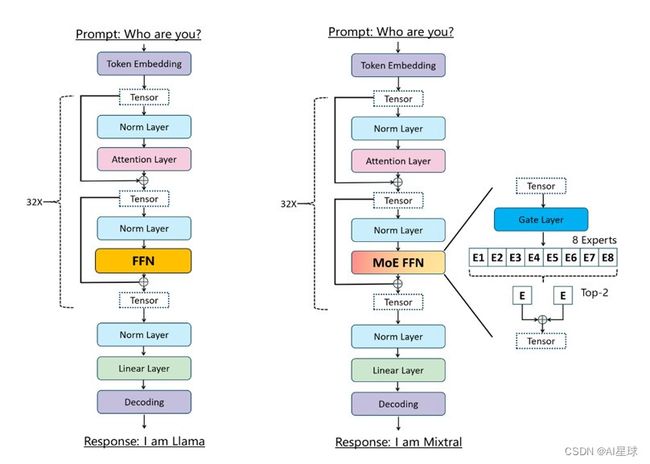
Mixtral-8x7B最终效果怎么样?除了开源评测集评测,最重要的是在下游任务中训练,在同样数据集下,表现是否真的比Lllama 70B效果好。也许不久的将来,会开源Mixtral-8x7B的训练方法。
[1]Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and
Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head
checkpoints. arXiv preprint arXiv:2305.13245, 2023
[2] Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer.arXiv preprint arXiv:2004.05150, 2020.
[3] Jiang A Q, Sablayrolles A, Mensch A, et al. Mistral 7B[J]. arXiv preprint arXiv:2310.06825, 2023.