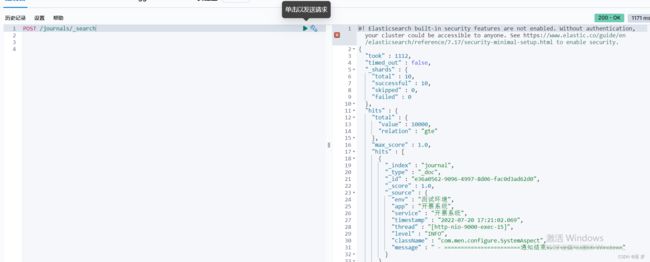
flume自定义sink写入es
flume官方没有提供写入elasticsearch的sink
所以只有自定义sink
这里采用的是flume1.9.0
elasticsearch采用的是7.17.0
1.首先创建maven项目
2.引入依赖
co.elastic.clients
elasticsearch-java
${elasticsearch.version}
org.projectlombok
lombok
1.16.22
compile
com.fasterxml.jackson.core
jackson-databind
2.12.3
org.apache.flume
flume-ng-core
1.9.0
3.编写:写入es数据的类
package com._3men.es;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch.core.CreateRequest;
import co.elastic.clients.elasticsearch.core.CreateResponse;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import com._3men.ToolUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import java.io.IOException;
/**
*对es操作简单进行封装
*/
@Slf4j
public class ElasticsearchTool{
private ElasticsearchClient client;
private String hosts;
private String defaultIndex;
public ElasticsearchTool(String hosts,String defaultIndex){
this.hosts=hosts;
this.defaultIndex=defaultIndex;
RestClient restClient = RestClient.builder(getHttpHost(hosts)).build();
ElasticsearchTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
client = new ElasticsearchClient(transport);
}
private static HttpHost[] getHttpHost(String hosts){
String[] hostsSplit = hosts.split(",");
HttpHost[] hostArr=new HttpHost[hostsSplit.length];
for (int i = 0; i < hostsSplit.length; i++) {
String[] addressSplit = hostsSplit[i].split(":");
hostArr[i]=new HttpHost(addressSplit[0],Integer.valueOf(addressSplit[1]));
}
return hostArr;
}
public CreateResponse createDocument(T t,String id,String index) throws IOException {
return client.create(new CreateRequest.Builder().document(t).index(index).id(id).build());
}
public CreateResponse createDocument(T t,String id) throws IOException {
return createDocument(t,id,defaultIndex);
}
public CreateResponse createDocument(T t) throws IOException {
String uuid = ToolUtil.uuid();
CreateResponse response = createDocument(t, uuid, defaultIndex);
return response;
}
public void stop(){
try {
client._transport().close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
4.自定义sink
package com._3men.sink;
import co.elastic.clients.elasticsearch.core.CreateResponse;
import com._3men.bean.Journal;
import com._3men.es.ElasticsearchTool;
import lombok.extern.slf4j.Slf4j;
import org.apache.flume.*;
import org.apache.flume.conf.Configurable;
import org.apache.flume.sink.AbstractSink;
@Slf4j
public class ElasticsearchSink extends AbstractSink implements Configurable {
private ElasticsearchTool tool;
@Override
public void configure(Context context) {
String hosts = context.getString("es.cluster");
String index = context.getString("es.index");
tool=new ElasticsearchTool(hosts,index);
}
@Override
public synchronized void stop() {
super.stop();
tool.stop();
}
@Override
public Status process() {
Status status = null;
Channel ch = getChannel();
Transaction txn = ch.getTransaction();
txn.begin();
try {
Event event = ch.take();
//1.解析event 然后拿到需要插入的数据, 这里有可能返回为空
if (event==null||event.getHeaders()==null){
log.info("event或者 event header为空"+event);
}else {
//数据转换 自己根据业务实现
Object o=//自定义的转换方法
tool.createDocument(o);
}
txn.commit();
status = Status.READY;
} catch (Throwable t) {
txn.rollback();
status = Status.BACKOFF;
if (t instanceof Error) {
throw (Error)t;
}
log.error("异常了:{}",t);
}finally {
txn.close();
}
return status;
}
}
4.将项目打成jar包
5.由于maven打包不会将依赖打进去,所以需要将依赖的jar包加入到flume的lib目录下,由于这里会有一些jar冲突,这里给出需要删除的jar包和添加jar包
添加:
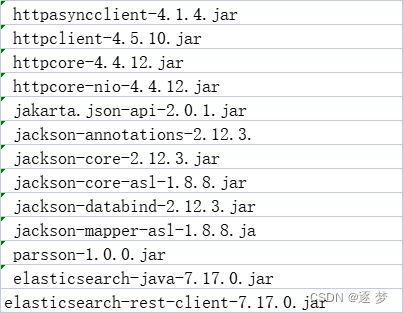
删除原来flumelib中的

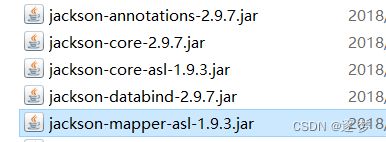
6.导出项目依赖jar包

配置文件编写
a1.sources = r1
a1.sinks = k1
a1.channels = c1
1.定义source 这里采用 TAILDIR souce
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /home/apache-flume-1.9.0/taildir_position.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.fileHeader = true
a1.sources.ri.maxBatchCount = 100
a1.sources.r1.filegroups.f1 = /home/log/smso-crm-api/.*.log
a1.sources.r1.headers.f1.env = 测试环境
a1.sources.r1.headers.f1.app = 开票系统
a1.sources.r1.headers.f1.service = 开票系统
a1.sources.r1.filegroups.f2 = /home/log/data-service/.*.log
a1.sources.r1.headers.f2.env = 测试环境
a1.sources.r1.headers.f2.app = 数据迁移中心
a1.sources.r1.headers.f2.service = 数据迁移中心
#2.定义管道 这里用内存管道
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 200
#3.定义sink
a1.sinks.k1.es.cluster=192.168.247.100:19200
a1.sinks.k1.es.index=journals
a1.sinks.k1.type = com._3men.sink.ElasticsearchSink
#sink和source 绑定管道
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
#最后启动
![]()