深度强化学习车辆重定向HMDRL: Hierarchical Mixed Deep Reinforcement Learning to Balance Vehicle Supply andDemand
HMDRL: Hierarchical Mixed Deep Reinforcement Learning to Balance Vehicle Supply and Demand
摘要
三层混合深度强化学习方法,对闲置的车辆进行重新定位
管理者在顶层,其中动作抽象是从时间维度进行的,并适应于空间可伸缩和时变的系统。
协调器位于中间层,设计了一种独立于决策顺序的并行协调机制,以提高重新定位的效
率。底层由执行人员组成,对具有混合状态的车辆进行重新定位,状态包含Agent相邻
区域的时空信息。
分别为管理者和协调者设计了两个奖励函数,旨在通过避免稀疏的奖励来提高培训效果。
Ⅰ. 介绍
车辆供需不平衡影响叫车系统效率
抬高价格会降低乘客的打车需求,订单调度只注重将订单与附近的车辆匹配,车辆在定位适合平衡跨区域供需。
闲置车辆对未来交通产生影响,从排序决策的角度考虑车辆重定位。
深度强化学习是什么?
Actor 基于概率分布选择行为, Critic 基于 Actor 生成的行为评判得分, Actor 再根据 Critic 的评分修改选行为的概率。
存在的问题:
出行需求和车辆都是动态变化的
同时互动的车很多,现有方法通常忽略车辆协调,或者按顺序重新定位
整个系统有大量的时空数据,没有得到有效的利用(相邻的车有相似的状态,很难区分)
提出了分层混合深度强化学习
主要贡献:
管理者根据全局状态动态地选择最佳协调器,并在协调器中抽象出车辆重定位的细节。
设计了一种由多个混合工作者和基于Q值的概率策略组成的并行协调机制。随着最佳重新定位动作的多样性增加,数千辆空闲车辆可以有效地并行协调。
合理设计了各agent的混合状态。它涵盖了丰富而独特的车辆时空信息。通过更准确地区分相似代理,提高了重新定位的效果。
论文结构
论文的其余部分组织如下:
- 第二节回顾了相关工作。
- 第三节介绍了分层车辆定位方法。
- 第四节设计了HMDRL的两种训练方法。
- 第五节进行了实验,并对结果进行了分析。
- 第六节给出了结论和下一步的工作。
Ⅱ. 相关工作:
A.汽车重定位方法
前面提到的基于模型的方法依赖于预先估计的参数,它们需要强有力的假设。 因此,它们很难适应复杂且动态变化的交通环境。
结合基于深度强化学习的车辆路径, 和一个请求-车辆分配方案,以优化运营成本和服务质量在拼车自主移动按需系统。
B.分层强化学习
它们的主要思想是将一个复杂的问题分解成许多子问题来解决。
C.交通预测方法
根据历史数据,LSTM预测。
Ⅲ. 车辆重定位方法
全局车辆定位问题可以建模为一个马尔可夫决策过程,每T分钟重新定位一次
一辆车可能处于空闲状态,并在几分钟后变为繁忙状态。然后在很长一段时间后,它在另一个偏远的地方又变成空闲。很难以集中的方式直接重新定位所有闲置车辆。
另一方面,供给和需求的分布模式随着时间的推移而动态变化。
常见的强化学习方法可能不适用于这样的时变系统。
A. 层次化的车辆定位框架
管理者只负责选协调员,协调员控制worker做操作,操作后给管理一个全局的回馈和状态。
管理中的Critic负责评论,Actor做对应的修改
重复步骤
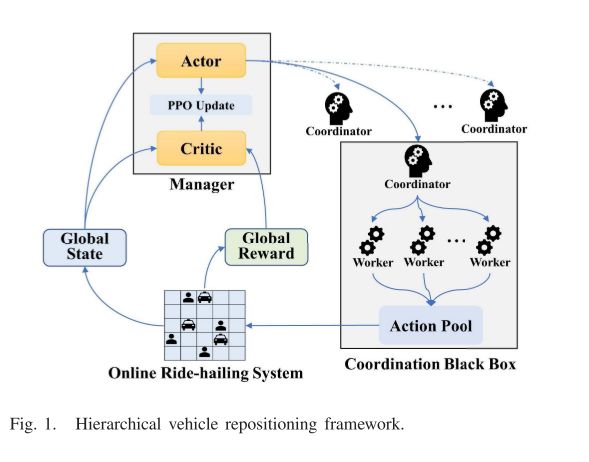
管理者根据不同重定位时间点的全局状态选择合适的协调器
不同的协调者以不同的方式协调所有的闲置车辆,管理者将获得不同的全局奖励(协调黑盒是重点)
管理者只需要选择好协调人即可
有效的方式平衡全局供需,将全局问题分解为多个据不平衡问题
每个协调器由多个不同的混合工人组成,所有空闲车辆以分散的方式重新定位。
B. 平行协调机制
每个协调器采用多个不同的混合工作者。根据同一缓冲区中的样本分别对工人进行培训。缓冲区的大小很大,每个工人随机抽样一批样本进行训练。工人的参数完全不同,使得最优动作的多样性,多个混合工作者计算成本也低,适用于大规模定位系统,每个工人都是一个MDP
获得混合状态,输出可能动作的Q值,动作空间就是移动到相邻网格或者停留在当前网格。
HMDRL并不是DQN那种选择最优Q,会考虑X(同一位置车辆多,则X高)
基于Q值的概率策略提高了车辆重新定位的灵活性和协调性能。结合了基于值的强化学习(RL)方法和基于策略的RL方法的优点。结合一下地图,并不是所有的网格都可以走
所有采样操作都被收集到操作池,代理真正操作前,操作池的多于操作和无意义操作都被删除,降低重新定位的成本
闲置车辆操作后,要把车辆的混合状态给worker和Coordinator
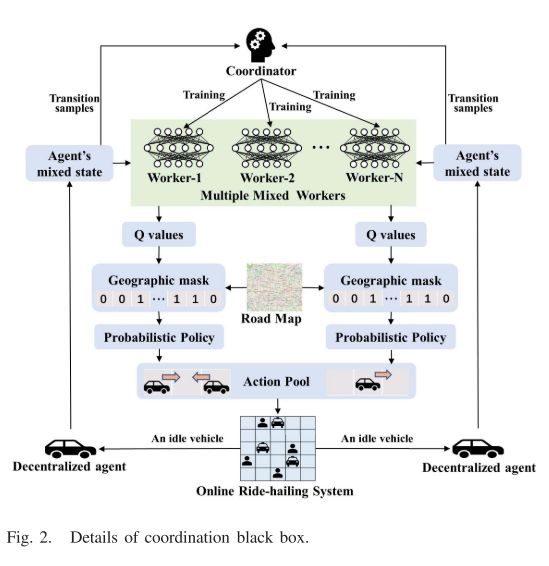
HMDRL将每一辆空闲车辆视为独立的唯一代理。每个代理的长期重新定位目标是平衡其当地的供需。所有代理进行协调,以平衡全球供需。
所有分散的代理被单独重新定位。该并行协调机制由多个混合工作者和基于Q值的概率策略两部分组成。它提高了数千辆汽车并行重新定位时的协调性能,并且不依赖于重新定位顺序。
协调器采用多个不同的混合工作者,每个工人随机抽样一批样本进行训练。长期重新定位效果是相似的,但是工人参数不同,最优动作的多样性,可以避免大量车辆冲向同一目的地,多个混合工作者也降低了计算成本,该框架适用于大规模的定位系统
同一个Worker输出的有效Q值是相同的。HMDRL不像传统的DQN那样选择Q值最优的动作,以避免大量的同质智能体涌向同一个目的地。如果有太多车辆聚集在同一位置,则X的值可能会稍高一些。基于Q值的概率策略提高了车辆重新定位的灵活性和协调性能。
如果在重新定位目的地的车辆数量达到拥堵限制CL,则该车辆将被调度到车辆最少的邻近区域。这一限制是为了避免道路拥堵。
C. 混合状态
覆盖尽可能多的时空信息,区分相似的代理人(相邻网格代理可能具有类似的时空信息,采取相同的行为)
网格距离当前代理越远,它对代理状态的影响就越小。
相邻网格的当前和历史本地供需信息,到代理的距离导致相邻的权重不同,混合状态差别很大,并且混合状态包含了丰富独特的信息
D. 奖励函数(全局奖励函数,混合奖励函数)(管理者和协调员)
全局奖励
评估管理者的行为,管理者选择特定的协调人来减少全局供需的分布失衡,全局报酬取决于所有协调人行为是否降低了全局供需的绝对值
空闲车辆当作唯一代理
混合奖励
局部奖励
独立代理的目的是平衡其未来的本地供需。使用LSTM,根据最后一个时隙的历史顺序量,预测未来T分钟的需求量。网格不一定都是有效的。局部不平衡指数,侧重于供需绝对值(不用绝对值,闲置车辆和活跃订单会被抵消),Action就是汽车移动到另一个位置。为了平衡供需分配,设计了衰减因子q,网格距离当前代理越远,对代理的局部不平衡因子的影响越小。
如果代理转移位置了,那么他的供需预测值就应该改变。如果重定位后,行动能降低局部不平衡指数,会有局部奖励。
全局奖励
代理人相互合作,很好的平衡全球供需,他们共享积极的全局回报,反之,如果表现不好就是零回报。混合报酬考虑了每个智能体的独特性和所有智能体的协调性。每个代理都会获得唯一的局部奖励,从而大大提高了样本的多样性。所有智能体共享相同的全局奖励,从而提高了协调性能。

Ⅳ. 训练方法
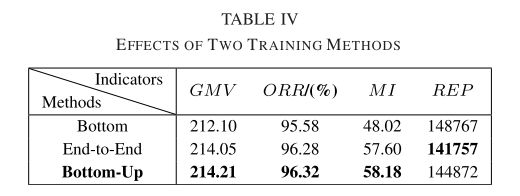
两种训练方法:自下而上,端到端
自下而上
第一步:底层培训(预先培训,协调员在培训期间重新定位车辆一段时间,不同时间供需不同,所以培训不同)
第二步:上岗培训(经理和协调员一起培训,PPO训练管理者,如何根据当前全局状态选择最佳协调器)
实验只给出了自下而上训练的有效性
端到端:
对管理者和协调者训练
A. 管理的训练
PPO算法???
B. 协调员训练
DQN worker:输入混合状态,输出可能的动作Q
从缓冲器随机抽样,每个worder有一个评估网络和目标网络,训练评估网络时,目标网络是固定的,迭代c次,用评估网络的参数更新
Ⅴ. 实验
成都1号2016年11月的真实交通订单数据,删除边缘地区订单,保留主城区订单。
前15天的平均订单数据用于训练,后15天的平均订单数据用于测试。
A. 评价指标
设计了四个指标来评价车辆重新定位的效果:
商品交易总额(GMV)、改善率(IMP)、订单响应率(ORR)、混合指数(MI)和重新定位的总数量(REP)
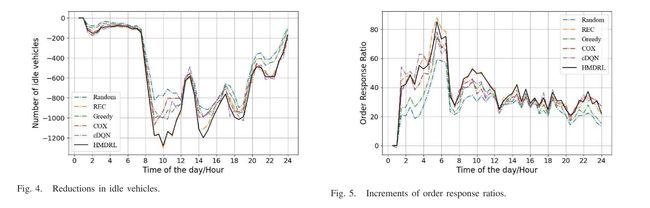
B. 实验设计和结果
作者态度:
重新定位成本最低,COX之所以在3600辆车的情况下拥有最小的REP,可能是因为COX大量的“停留”动作,车辆停留在原来的网格上。总之,HMDRL以最小的代价获得了最好的性能。
- NR:模拟器中没有重定位算法。它显示了模拟器的原始有效性,是所有重定位算法的基线。
- Random:所有空闲车辆被随机重新定位到相邻的网格。
- Greedy:所有闲置车辆都被重新定位到闲置车辆最少的相邻电网中。
- cDQN:一种适应不同上下文的大规模车辆重新定位的上下文深度Q学习方法。这是大规模车辆重新定位的最佳方法之一。
- COX:一种基于深度强化学习的上下文感知出租车调度方法。这也是大规模车辆重新定位的最佳方法之一。
- REC:这是一个针对闲置车辆的推荐系统。实验结果证明了该方法的有效性。

C. 消融实验

测试时间为10天,评价指标分别取平均值。混合指数的框图
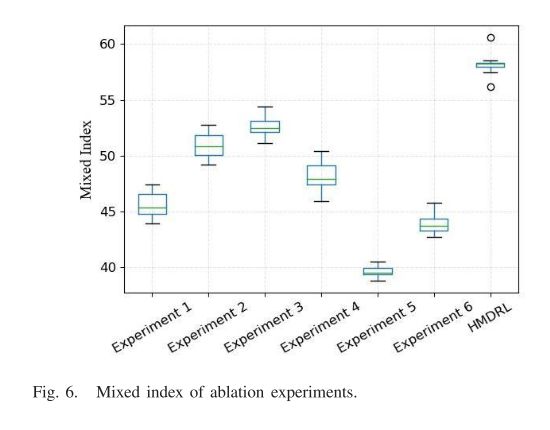
D. 两种训练方法的实验结果
E. 订单匹配假设的影响
重新定位方式和派单方式对网约车系统的效率都有显著影响

即使在现实生活中有足够的订单,也不是所有闲置的车辆都能接受订单。车辆-订单匹配假设的效果如表V所示。进行了两个对比实验,车辆接受订单的概率分别为0.70∼0.85和0.80∼0.95。
Ⅵ. 结论和展望
结论
分层混合深度强化学习方法
- 管理者:选择最佳协调人
- 协调人:并行协调机制协调大量闲置车辆,降低计算开销,
- 工人:每辆车当作一个代理,重新定位车。每个代理包含丰富的时空信息,以便于区分相邻的代理。
为管理者和协调人设计奖励函数。
展望
- 在图形结构地图上重建仿真环境,对每条路的动态状态建模。
- 研究预测算法,并利用图神经网络对不同区域之间的关系进行建模。还将研究如何确定当前供需和预测需求的权重。
- 将改进重新定位算法,增加更多考虑因素,如拼车、交通拥堵等。
- 在设计框架时将引入更多的创新,如人工交通系统、并行学习等。
个人总结
深度强化学习结合了 DL特征提取 和 RL的决策能力
深度强化学习分为基于值函数、基于策略梯度和AC算法。
目前广泛应用的是Actor Critic算法,结合了两种的优点:
Actor 基于概率分布选择行为, Critic 基于 Actor 生成的行为评判得分, Actor 再根据 Critic 的评分修改选行为的概率。

上图深度强化学习框架中,智能体与环境进行交互,智能体通过深度学习对环境状态进行特征提取,将结果传递给强化学习进行决策并执行动作,执行完动作后得到环境反馈的新状态和奖惩进而更新决策算法。此过程反复迭代,最终使智能体学到获得最大长期奖惩值的策略。
- 因为出行需求和车辆都是动态的,要充分
结合时空信息。 - 本文复杂的问题通过分层来解决,分层后对于不同层给予奖励机制(局部最优和全局最优)
- 但是把地图信息放到网格做处理,可能会使得网格很大。
- 虽然平行协调机制结合了真实的地图,但是训练过程没有结合,只是决策后的Q动作值,结合一下真实路网能不能走得通。
管理的训练方法:PPO没看明白(第四节详细展开)
整个城市被划分为许多方形网格,网格大小为M*M
供需是数值吗?
Nt ij表示Gij在时间t的净值。正值表示额外的车辆数量,负值表示额外订单的数量
车辆调度?
agent所有的操作都收集到操作池,在代理真正执行其操作之前,操作池中的多余操作和无意义操作将被删除。
一旦代理确定其操作,则在操作真正执行之前将相应地确定其新状态。这是为了避免其他代理的操作影响当前代理的新状态,并扰乱该操作和状态之间的关联。
操作池中,车辆调度是所有车的车辆一起运行还是单个Agent的操作运行?
操作池应该是所有Agent的操作,
但是真正操作时,要先确定每个Agent没有多余无意义的操作,然后在对Agent进行操作
worker用什么训练?
DQN训练
每个工人随机抽样一批样本进行训练。
DQN的输入是每个智能体的混合状态,它输出九个可能动作的Q值。每次收集A个转变样本,所有工人都被训练,批大小为B。