词法分析器 golang版本
基于Go 语言实现的词法分析程序
说明: 比较小白 ,大神勿喷!
主要识别的C语言,从代码源文件转化为Token 词元序列输出
func main() {
var filep string
filep = "D:\\testcode\\src\\main\\testC.c"
// 进行预处理操作(读入源代码文件,去除多余空格,注释)
symbList := lexical.Pretreatment(filep)
// 初始化状态机对象
sDev := lexical.CreateStateDev(symbList)
// 进行词法分析
sDev.LexAnal()
// 输出结果
for _, v := range sDev.TokenList {
fmt.Printf("类型:%-5s\t单词: %-20s \t位置: %5d\n", lexical.TypeList[v.Type], v.Literal, v.Position)
}
fmt.Println("++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++")
for _, v := range sDev.ErrList {
fmt.Println(v)
}
}
词法分析核心代码
package lexical
import (
"fmt"
"os"
"regexp"
"strconv"
)
// ########################################################### 数据存储 ###########################################################
// 状态机结构体
type stateDev struct {
symbList []word // 输入字符列表
word string // 临时存储词元
position Typosit // 记录位置
wordState string // 记录当前处理状态
index int // 字符表索引
lensyms int // 字符表长度
TokenList []Token // 输出Token序列
ErrList []string // 记录在进行词法分析时出错的单词符号信息
}
// 记录坐标
type Typosit [2]int
// 记录单词符号,位置
type word struct {
symbol rune // 单个符号
position Typosit // 记录字符位置信息
}
// 声明词元类型
// PRECMD--预处理指令1 KEYWORD--关键字2 IDENTF--标识符3 CONST--常量4 OPERAT--运算符5 LIMITER--界符6
// var typeList []string = []string{"NIL", "PRECMD", "KEYWORD", "IDENTF", "CONST", "OPERAT", "LIMITER"}
var TypeList []string = []string{"NIL", "预指令", "关键字", "标识符", "常量", "运算符", "界符"}
// 词法分析词元结构体
type Token struct {
// 记录词元
Type int // 词元类型
Literal string // 字面量
Position Typosit // 词元位置
}
// 声明C语言中的关键字
var Keywords_list []string = []string{
"auto", "break", "case", "char", "const",
"continue", "default", "do", "double", "else",
"enum", "extern", "float", "for", "goto",
"if", "int", "long", "register", "return",
"short", "signed", "sizeof", "static", "struct",
"switch", "typedef", "union", "unsigned", "void",
"volatile", "while",
}
// 声明c语言中的运算符
var Operators_list []string = []string{
"+", "-", "*", "/", "%", "++", "--", // 算术运算符
"=", "+=", "-=", "*=", "/=", "%=", "<<=", ">>=", "&=", "|=", "^=", // 赋值运算符
">", "<", ">=", "<=", "==", "!=", // 关系运算符
"&&", "||", "!", // 逻辑运算符
"&", "|", "^", "~", "<<", ">>", ":", // 位运算符
}
// ########################################################### 预处理部分 ###########################################################
// 读入源代码,去除注释以及多余空格,格式化输出
func Pretreatment(filename string) []word {
fmt.Println("开始预处理工作")
// 读取文件内容
cfile, err := os.ReadFile(filename)
if err != nil {
fmt.Println("无法读取文件: %w", err)
return nil
}
defer func() {
fmt.Println("预处理工作完成!")
}()
var result []word // 返回结果word列表
// 格式化代码
func(code []uint8, result *[]word) {
codeSlice := []rune(string(code)) // 将字符串转化为unicode切片
multiComment := false // 标记多行注释状态
singleLineComment := false // 标记单行注释状态
Line := 1
Column := 1
for i := 0; i < len(codeSlice); i++ {
// 记录位置
if i != 0 && codeSlice[i-1] == '\n' {
Line++
Column = 1
} else if i != 0 {
Column++
}
// 去除注释
if singleLineComment {
if i+1 < len(codeSlice) && (codeSlice)[i+1] == '\r' {
singleLineComment = false // 单行注释结束
}
} else if multiComment {
if i+1 < len(codeSlice) && (codeSlice)[i] == '*' && (codeSlice)[i+1] == '/' {
multiComment = false // 多行注释结束
i++ // 跳过多行注释结束符
}
} else {
if i+1 < len(codeSlice) && (codeSlice)[i] == '/' && (codeSlice)[i+1] == '/' {
singleLineComment = true // 单行注释开始
i++ // 跳过单行注释符
} else if i+1 < len(codeSlice) && (codeSlice)[i] == '/' && (codeSlice)[i+1] == '*' {
multiComment = true // 多行注释开始
i++ // 跳过多行注释开始符
} else { // 去重,空格,换行
if (codeSlice)[i] == '\t' {
(codeSlice)[i] = ' '
}
if (len(*result) == 0 || (*result)[len(*result)-1].symbol == ' ' || (*result)[len(*result)-1].symbol == '\n') &&
((codeSlice)[i] == ' ') {
continue
} else if len(*result) != 0 && ((*result)[len(*result)-1].symbol == ' ') && ((codeSlice)[i] == '\r' &&
(codeSlice)[i+1] == '\n') {
(*result)[len(*result)-1].symbol = '\n'
i++
continue
}
// 记录字符位置信息
var w word
w.position[0] = Line
w.position[1] = Column
// 修改windows换行符为标准换行符
if i+1 < len(codeSlice) && codeSlice[i] == '\r' && codeSlice[i+1] == '\n' {
if len(*result) != 0 && (*result)[len(*result)-1].symbol != '\n' {
w.symbol = '\n'
(*result) = append((*result), w)
}
i++
continue
}
w.symbol = (codeSlice)[i]
(*result) = append((*result), w)
}
}
}
}(cfile, &result)
// 添加结束符
// var w word = word{position: [2]int{0, 0}}
// result = append(result, w)
if len(result) == 0 {
return nil
}
return result
}
// 初始化状态机
func CreateStateDev(symbList []word) *stateDev {
return &stateDev{
symbList: symbList, // 输入字符列表
word: "", // 初始化存储器
wordState: "", // 初始化状态标识
position: Typosit{-1, -1}, // 初始位置
index: 0, // 字符表索引
lensyms: len(symbList), // 字符表长度
}
}
// ########################################################### 字符属性判断 #########################################################
// 判断是不是字母
func evalLetter(sym rune) bool {
return (sym >= 'a' && sym <= 'z') || (sym >= 'A' && sym <= 'Z')
}
// 判断是不是数字
func evalDigit(sym rune) bool {
return sym >= '0' && sym <= '9'
}
// 判断是否是运算符
func evalNoperat(sym rune) bool {
operate := []rune{
'+', '-', '*', '/', '%', '=', '>', '<', '!', '&', '|', '^', '~',
}
for _, v := range operate {
if sym == v {
return true
}
}
return false
}
// 判断是否是界符
func evalSeparate(sym rune) bool {
sep := []rune{'(', ')', '{', '}', '[', ']', ';', ',', ':', '.'}
for _, v := range sep {
if sym == v {
return true
}
}
return false
}
// 判断当前字符是否是分割符(单词边界)
func lastWordStr(sym rune) bool {
return sym == ' ' || sym == '\n' || evalNoperat(sym) || evalSeparate(sym) //空格 换行 界符 运算符
}
// ######################################################### 单词规则判定 #############################################################
// 查询方法
func (sDev *stateDev) queryTableMethod(table []string) bool {
for _, v := range table {
if v == sDev.word {
return true
}
}
return false
}
// 判断是否是预处理指令
func (sDev stateDev) evalPreCmd() bool {
precmd_list := []string{"#include", "#define", "#pragma"}
for _, v := range precmd_list {
if sDev.word == v {
return true
}
}
return false
}
// 判断是不是库函数文件名
func (sDev stateDev) evalibrayFile() bool {
// 创建一个正则表达式对象,用于匹配文件名
phoneRegex := regexp.MustCompile(`[a-zA-z]*.>`)
// 使用正则表达式匹配库函数文件
return phoneRegex.MatchString(sDev.word)
}
// 判断是否是关键字
func (sDev *stateDev) evalKeyword() bool {
for _, v := range Keywords_list {
if v == sDev.word {
return true
}
}
return false
}
// 判断是否满足标识符规则
func (sDev *stateDev) evalDentif() bool {
phoneRegex := regexp.MustCompile(`^[_a-zA-Z]\w*$`)
return phoneRegex.MatchString(sDev.word)
}
// 数字常量规则
func (sDev *stateDev) evalNumRule() bool {
phoneRegex := regexp.MustCompile(`(\b-?\d+(?:\.\d+)?(?:[eE][+-]?\d+)?\b)`) // 匹配所有的数字常量
return phoneRegex.MatchString(sDev.word)
}
// ######################################################## 状态处理转换部分 ###########################################################
// 预处理指令状态
func (sDev *stateDev) preCmdState() {
sDev.word += string(sDev.symbList[sDev.index].symbol) // 加入当前字符
if (sDev.index+1 < sDev.lensyms && lastWordStr(sDev.symbList[sDev.index+1].symbol)) || sDev.index == sDev.lensyms-1 { //判断当前字符是否结尾
if sDev.evalPreCmd() { // 判断当前词元是否合法
// 将合法的词元存入token序列
sDev.TokenStor(1)
} else {
sDev.manageErr("单词不是一个合法预处理指令: ")
}
if sDev.word == "#include" {
sDev.wordState = "ONE-tag" // 标记状态
sDev.word = ""
} else {
sDev.resetState() // 重置状态机
}
}
}
// 处理库函数文件名
func (sDev *stateDev) preCmdFileState() {
num := 0
for sDev.index+num < sDev.lensyms {
sDev.word += string(sDev.symbList[sDev.index+num].symbol) // 加入当前字符
if sDev.symbList[sDev.index+num].symbol == '>' { // 识别结束标志
if sDev.evalibrayFile() { // 判断词元合法性
// 将合法的词元存入token序列
sDev.TokenStor(1)
} else {
sDev.manageErr("库函数文件命名规则错误") // 记录报错信息
}
sDev.index += num //跳过已处理部分
sDev.resetState() // 重置状态机
return
} else if (sDev.symbList[sDev.index+num].symbol == '\n') || sDev.index+num == sDev.lensyms-1 { //判断是否出现不必要的换行,以及是否为结尾符号
sDev.manageErr("ERR出现单个: \"<\" 符号没有结束符: \">\"") // 记录报错信息
sDev.resetState() // 重置状态机
return
}
num++
}
sDev.manageErr("ER出现单个: \"<\" 符号没有结束符: \">\"") // 记录报错信息
}
// 处理关键字,标识符混合态
func (sDev *stateDev) keyAndVarible() {
sDev.word += string(sDev.symbList[sDev.index].symbol)
if (sDev.index+1 < sDev.lensyms && lastWordStr(sDev.symbList[sDev.index+1].symbol)) || sDev.index == sDev.lensyms-1 { //判断当前字符是否结尾
if sDev.evalKeyword() { // 判断是不是关键字
sDev.TokenStor(2) // 存储为关键字类型
} else if sDev.evalDentif() { // 判断能否构成一个合法的标识符
sDev.TokenStor(3) // 存储为标识符类型
} else { // 以上条件都不满足进行报错
sDev.manageErr("出现非法字符!") // 记录报错信息
}
sDev.resetState() // 重置状态机
}
}
// _标识符状态
func (sDev *stateDev) signVarble() {
sDev.word += string(sDev.symbList[sDev.index].symbol)
if (sDev.index+1 < sDev.lensyms && lastWordStr(sDev.symbList[sDev.index+1].symbol)) || sDev.index == sDev.lensyms-1 { //判断当前字符是否结尾
if sDev.evalDentif() { // 判断能否构成一个合法的标识符
sDev.TokenStor(3) // 存储为关键字类型
} else { // 条件不满足进行报错
sDev.manageErr("推测标识符出错:出现非法字符!") // 记录报错信息
}
sDev.resetState() // 重置状态机
}
}
// 运算符状态
func (sDev *stateDev) operteMthod() {
sDev.word += string(sDev.symbList[sDev.index].symbol)
if sDev.index+1 < sDev.lensyms && !evalNoperat(sDev.symbList[sDev.index+1].symbol) {
if sDev.queryTableMethod(Operators_list) {
sDev.TokenStor(5) // 存储token
} else if len(sDev.word) > 3 {
sDev.manageErr("错误类型为运算符错误!") // 记录报错信息
}
sDev.resetState()
}
}
// 数字状态
func (sDev *stateDev) digitConState() {
sDev.word += string(sDev.symbList[sDev.index].symbol)
if sDev.index+1 < sDev.lensyms && lastWordStr(sDev.symbList[sDev.index+1].symbol) { // 单词字符终止态
if sDev.evalNumRule() {
sDev.TokenStor(4) // 存储当前词元
} else {
sDev.manageErr() // 记录报错信息
}
sDev.resetState() // 重置状态机
}
}
// 字符串态
func (sDev *stateDev) strConState() {
if sDev.symbList[sDev.index].symbol == '"' {
sDev.word += string(sDev.symbList[sDev.index].symbol)
sDev.TokenStor(4)
sDev.resetState()
} else if sDev.index == sDev.lensyms-1 {
sDev.manageErr()
sDev.resetState()
} else {
sDev.word += string(sDev.symbList[sDev.index].symbol)
}
}
// 单引号处理
func (sDev *stateDev) strConStateSingal() {
if sDev.index < sDev.lensyms && sDev.symbList[sDev.index].symbol == '\'' {
sDev.word += string(sDev.symbList[sDev.index].symbol)
sDev.TokenStor(4)
sDev.resetState()
} else if sDev.index == sDev.lensyms-1 || len(sDev.word) > 2 { // 结尾还未结束 或者 超过字符限制长度 就报错
sDev.manageErr()
sDev.resetState()
} else {
sDev.word += string(sDev.symbList[sDev.index].symbol)
}
}
// ######################################################### 词法分析器主体 ##############################################################
// 存储Token的方法
func (sDev *stateDev) TokenStor(ntype int) bool {
// 将合法的词元存入token序列,ntype指定类型
sDev.TokenList = append(sDev.TokenList, Token{
Type: ntype,
Literal: sDev.word,
Position: sDev.position,
})
return true
}
// 错误处理记录
func (sDev *stateDev) manageErr(contents ...string) {
content := "不合法字符"
if len(contents) != 0 {
content = contents[0]
}
str := "位置: " + "(" + strconv.Itoa(sDev.position[0]) + "," + strconv.Itoa(sDev.position[1]) + ")" + content + ": " + sDev.word // 坐标信息
sDev.ErrList = append(sDev.ErrList, str)
}
// 重置状态机
func (sDev *stateDev) resetState() {
sDev.word = "" // 重置存储器
sDev.wordState = "" // 重置转态机
}
// 分析词法是否合规
func (sDev *stateDev) LexAnal() {
for sDev.index = 0; sDev.index < sDev.lensyms; sDev.index++ {
if sDev.word == "" { // 载入开头字符,设置状态
if sDev.symbList[sDev.index].symbol == ' ' || sDev.symbList[sDev.index].symbol == '\n' { // 跳过开头空格,换行
continue
}
sDev.word = string(sDev.symbList[sDev.index].symbol) // 存入首字符
sDev.position = sDev.symbList[sDev.index].position // 记录坐标
// 状态机入口确定
if (sDev.symbList)[sDev.index].symbol == '#' { // 预处理指令
if sDev.index+1 < sDev.lensyms && !lastWordStr(sDev.symbList[sDev.index+1].symbol) {
sDev.wordState = "ONE" // 设置当前进入预处理指令 状态1
} else {
if sDev.symbList[sDev.index+1].symbol == ' ' || sDev.symbList[sDev.index+1].symbol == '\n' { // 跳过空格回车
sDev.index++
}
sDev.resetState() // 重置状态机
sDev.manageErr("出现单个 # 符号预处理指令不完整") // 记录报错信息
}
} else if sDev.index+1 < sDev.lensyms && sDev.wordState == "ONE-tag" && sDev.symbList[sDev.index].symbol == '<' { // 库函数文件名开头
if (sDev.symbList[sDev.index+1].symbol == '\n') || sDev.index == sDev.lensyms-1 {
sDev.resetState() //重置转态机
sDev.index++
sDev.manageErr("出现单个: \"<\" 符号没有结束符: \">\"") // 记录报错信息
} else {
sDev.wordState = "ONE-F"
}
} else if evalLetter(sDev.symbList[sDev.index].symbol) { // 判断是不是字母
// 字母开头 ==> 关键字,标识符
if !lastWordStr(sDev.symbList[sDev.index+1].symbol) { // 判断当前字符不是单词符号结尾字符就更新状态机为TWO状态
sDev.wordState = "TWO" // 设置为状态2
} else { // 当前为单个字母的情况,存储为标识符类型
sDev.TokenStor(3) // 存储当前词元
sDev.resetState() // 重置状态机
}
} else if (sDev.symbList)[sDev.index].symbol == '_' { // 下划线开头,标识符
if (sDev.index+1 < sDev.lensyms && lastWordStr(sDev.symbList[sDev.index+1].symbol)) ||
(sDev.index+2 < sDev.lensyms && sDev.symbList[sDev.index+1].symbol == '_' && lastWordStr(sDev.symbList[sDev.index+2].symbol)) {
sDev.TokenStor(1) // 存储当前词元
sDev.resetState() // 重置状态机
} else {
sDev.wordState = "THREE" // 设置为状态3
}
} else if evalDigit(sDev.symbList[sDev.index].symbol) { // 数字开头 ==> 数字常量
// 单数字
if sDev.index+1 < sDev.lensyms && lastWordStr(sDev.symbList[sDev.index+1].symbol) {
sDev.TokenStor(4) // 存储当前词元
sDev.resetState() // 重置状态机
} else { // 进入下一个状态
sDev.wordState = "FOUR" // 设置为状态4
}
} else if (sDev.symbList)[sDev.index].symbol == '"' { // 字符串常量
sDev.wordState = "FIVE" // 设置为状态5
} else if (sDev.symbList)[sDev.index].symbol == '\'' { // 字符类型
sDev.wordState = "FIVE-S"
} else { // 特殊符号
if evalSeparate(sDev.symbList[sDev.index].symbol) { // 判断是不是界符
// 界符
sDev.TokenStor(6) // 存入token
sDev.resetState() //重置转态机
} else if evalNoperat((sDev.symbList)[sDev.index].symbol) { // 运算符
if sDev.index+1 < sDev.lensyms && (sDev.symbList[sDev.index+1].symbol == ' ' || sDev.symbList[sDev.index+1].symbol == '\n' ||
!evalNoperat(sDev.symbList[sDev.index+1].symbol)) { // 单个运算符
sDev.TokenStor(5) // 存入token
sDev.resetState() //重置转态机
} else if sDev.index+1 < sDev.lensyms && evalNoperat(sDev.symbList[sDev.index+1].symbol) { // 多运算符组合
sDev.wordState = "SIX-O" // 开启状态机
}
} else {
// 都不满足,不合法字符,抛出异常
sDev.manageErr()
sDev.resetState() //重置转态机
}
}
} else { // 状态机入口
switch sDev.wordState {
case "ONE": // 预处理指令
sDev.preCmdState() // 调用函数进行预处理指令识别
case "ONE-F":
sDev.preCmdFileState()
case "TWO": // 关键字,标识符
sDev.keyAndVarible() // 对关键字,标识符混合态进一步识别
case "THREE": // 标识符
sDev.signVarble() // 标识符状态
case "FOUR": // 数字常量
sDev.digitConState() // 数字常量状态
case "FIVE": // 字符串
sDev.strConState() // 字符串常量状态
case "FIVE-S": // 字符常量
sDev.strConStateSingal() // 单引号字符
case "SIX-O": // 运算符
sDev.operteMthod() // 运算符状态
default:
}
}
}
}
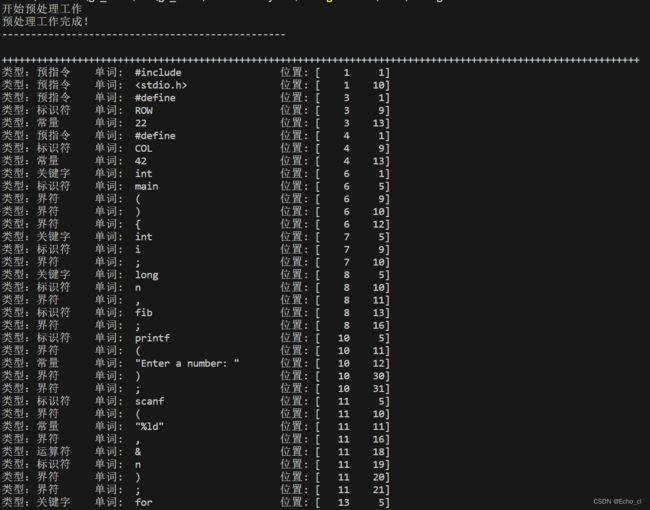
c 语言测试文件(随便搞的一段代码)
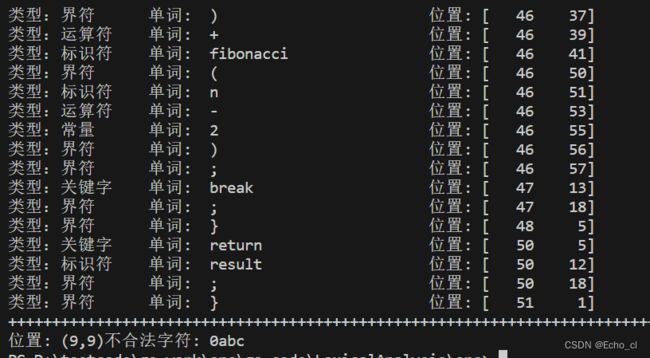
#include 输出识别后的结果:
在代码文件中写一个错误的语句:
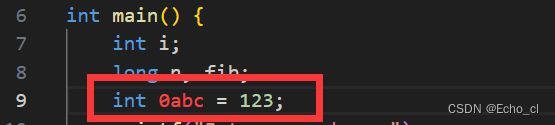
结果: 输出错误语句的位置