机器学习吴恩达编程作业题6-支持向量机
1、支持向量机
1.1示例数据集1
将ex6data1.mat文件复制到D:\Machine Learning\ex6目录下,在当前目录下建立plotData.m文件,源码与之前类似,数据与两次考试与录取结果数据集类似,绘制相应的数据集。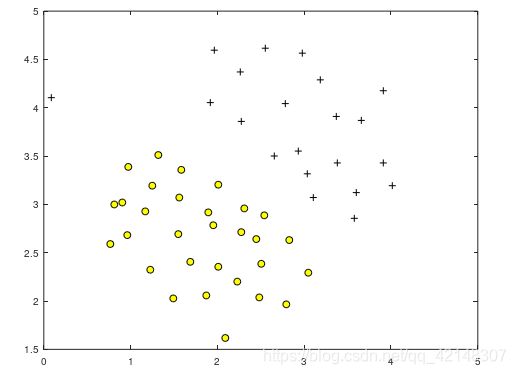
1.2不带核函数SVM
大多数支持向量机软件包(包括svmTrain.m)会自动为您添加额外的特性x0=1,并自动学习截距项θ0。所以当你把你的训练数据传递给SVM软件时,你不需要自己添加这个额外的特性x0=1。
在当前目录下建立svmTrain.m文件,该函数是SVM 的优化软件:
1、是提出参数的选择。讨论误差/方差在这方面的性质。
2、你也需要选择内核参数或你想要使用的相似函数,可以选择线性核函数或者核函数。
这里用的支持向量机软件包是已经编写好的,只用熟悉接口就行:
function [model] = svmTrain(X, Y, C, kernelFunction, ...
tol, max_passes)
%返回是训练后的模型,第三个参数是选择核函数或者线性核函数的种类,第四个是容忍度,第五个是训练次数
if ~exist('tol', 'var') || isempty(tol)
tol = 1e-3;
end
if ~exist('max_passes', 'var') || isempty(max_passes)
max_passes = 5;
end
m = size(X, 1);
n = size(X, 2);
Y(Y==0) = -1;
alphas = zeros(m, 1);
b = 0;
E = zeros(m, 1);
passes = 0;
eta = 0;
L = 0;
H = 0;
if strcmp(func2str(kernelFunction), 'linearKernel')
K = X*X';
elseif strfind(func2str(kernelFunction), 'gaussianKernel')
X2 = sum(X.^2, 2);
K = bsxfun(@plus, X2, bsxfun(@plus, X2', - 2 * (X * X')));
K = kernelFunction(1, 0) .^ K;
else
K = zeros(m);
for i = 1:m
for j = i:m
K(i,j) = kernelFunction(X(i,:)', X(j,:)');
K(j,i) = K(i,j); %the matrix is symmetric
end
end
end
fprintf('\nTraining ...');
dots = 12;
while passes < max_passes,
num_changed_alphas = 0;
for i = 1:m,
E(i) = b + sum (alphas.*Y.*K(:,i)) - Y(i);
if ((Y(i)*E(i) < -tol && alphas(i) < C) || (Y(i)*E(i) > tol && alphas(i) > 0)),
j = ceil(m * rand());
while j == i, % Make sure i \neq j
j = ceil(m * rand());
end
E(j) = b + sum (alphas.*Y.*K(:,j)) - Y(j);
alpha_i_old = alphas(i);
alpha_j_old = alphas(j);
if (Y(i) == Y(j)),
L = max(0, alphas(j) + alphas(i) - C);
H = min(C, alphas(j) + alphas(i));
else
L = max(0, alphas(j) - alphas(i));
H = min(C, C + alphas(j) - alphas(i));
end
if (L == H),
continue;
end
eta = 2 * K(i,j) - K(i,i) - K(j,j);
if (eta >= 0),
continue;
end
alphas(j) = alphas(j) - (Y(j) * (E(i) - E(j))) / eta;
alphas(j) = min (H, alphas(j));
alphas(j) = max (L, alphas(j));
if (abs(alphas(j) - alpha_j_old) < tol),
alphas(j) = alpha_j_old;
continue;
end
alphas(i) = alphas(i) + Y(i)*Y(j)*(alpha_j_old - alphas(j));
b1 = b - E(i) ...
- Y(i) * (alphas(i) - alpha_i_old) * K(i,j)' ...
- Y(j) * (alphas(j) - alpha_j_old) * K(i,j)';
b2 = b - E(j) ...
- Y(i) * (alphas(i) - alpha_i_old) * K(i,j)' ...
- Y(j) * (alphas(j) - alpha_j_old) * K(j,j)';
if (0 < alphas(i) && alphas(i) < C),
b = b1;
elseif (0 < alphas(j) && alphas(j) < C),
b = b2;
else
b = (b1+b2)/2;
end
num_changed_alphas = num_changed_alphas + 1;
end
end
if (num_changed_alphas == 0),
passes = passes + 1;
else
passes = 0;
end
fprintf('.');
dots = dots + 1;
if dots > 78
dots = 0;
fprintf('\n');
end
if exist('OCTAVE_VERSION')
fflush(stdout);
end
end
fprintf(' Done! \n\n');
idx = alphas > 0;
model.X= X(idx,:);
model.y= Y(idx);
model.kernelFunction = kernelFunction;
model.b= b;
model.alphas= alphas(idx);
model.w = ((alphas.*Y)'*X)';
end在这里用的是线性核函数,在当前目录下建立linearKernel.m文件:
function sim = linearKernel(x1, x2)
%返回值在 x1 和x2之间
x1 = x1(:); x2 = x2(:);
sim = x1' * x2; %点乘
end现在需要画出线性的决策边界,在当前目录下建立visualizeBoundaryLinear.m文件:
function visualizeBoundaryLinear(X, y, model)
w = model.w;
b = model.b;
xp = linspace(min(X(:,1)), max(X(:,1)), 100);
%设置决策线的两个X端点
yp = - (w(1)*xp + b)/w(2);
plotData(X, y);
hold on;
plot(xp, yp, '-b');
hold off
end在Octave中设置C值,然后画出无核SVM边界决策,也可以通过改变C的值进行观察:


2、高斯核函数SVM
要用支持向量机寻找非线性决策边界,首先需要实现高斯核函数。
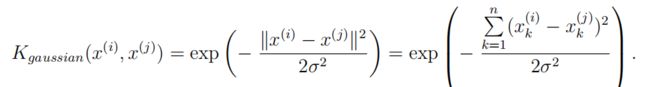
在当前目录下添加ex6data2.mat文件,然后在当前目录下建立gaussianKernel.m文件,实现高斯核函数:
function sim = gaussianKernel(x1, x2, sigma)
%第三个参数是σ
x1 = x1(:); x2 = x2(:);
sim = 0;
sim = exp(sum((x1 - x2) .^ 2) / 2 / sigma / sigma * (-1));
end在Octave中加载数据集,然后调用svmTrain向量机软件包,然后调用visualizeBoundary画出高斯核函数SVM决策边界。
在当前目录下建立visualizeBoundary.m文件:
function visualizeBoundary(X, y, model, varargin)
plotData(X, y)
x1plot = linspace(min(X(:,1)), max(X(:,1)), 100)';
x2plot = linspace(min(X(:,2)), max(X(:,2)), 100)';
%设置两个坐标轴,划分100个坐标向量
[X1, X2] = meshgrid(x1plot, x2plot);
%网格采样点的函数,形成相应点的矩阵
vals = zeros(size(X1));
for i = 1:size(X1, 2)
this_X = [X1(:, i), X2(:, i)];
vals(:, i) = svmPredict(model, this_X);
%根据model和相应的x轴中x的坐标,预测出Y的值
end
hold on
contour(X1, X2, vals, [0.5 0.5], 'b');
%画出相应的等高线图,以y为0.5为界
hold off;
end在这里中调用了svmPredict函数,该函数的作用主要是预测出y的值:
function pred = svmPredict(model, X)
%预测出y值
if (size(X, 2) == 1)
X = X';
end
m = size(X, 1);
p = zeros(m, 1);
pred = zeros(m, 1);
if strcmp(func2str(model.kernelFunction), 'linearKernel')
p = X * model.w + model.b;
%线性核函数
elseif strfind(func2str(model.kernelFunction), 'gaussianKernel')
%核函数
X1 = sum(X.^2, 2);
X2 = sum(model.X.^2, 2)';
K = bsxfun(@plus, X1, bsxfun(@plus, X2, - 2 * X * model.X'));
K = model.kernelFunction(1, 0) .^ K;
K = bsxfun(@times, model.y', K);
K = bsxfun(@times, model.alphas', K);
p = sum(K, 2);
else
for i = 1:m
prediction = 0;
for j = 1:size(model.X, 1)
prediction = prediction + ...
model.alphas(j) * model.y(j) * ...
model.kernelFunction(X(i,:)', model.X(j,:)');
end
p(i) = prediction + model.b;
end
end
pred(p >= 0) = 1;
pred(p < 0) = 0;
end
![]()
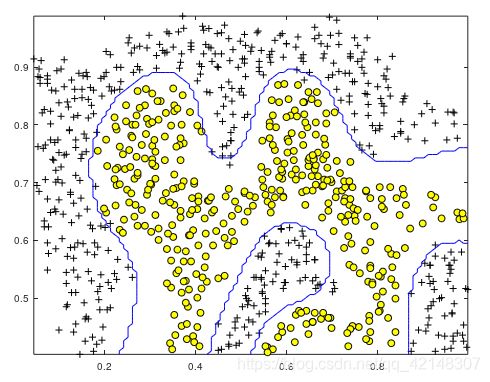
2.1交叉验证集
使用交叉验证集Xval,yval来确定要使用的最佳C和σ参数。应该尝试所有可能的C和σ值对(例如,C=0.3和σ=0.1)。例如,如果您尝试以上列出的8个值中的每一个,那么您将最终训练和评估(在交叉验证集中)总共82=64个不同的模型。在确定了要使用的最佳C和σ参数后,应该修改dataset3Params.m中的代码,填充最佳参数
- 在当前目录下添加ex6data3数据集,在当前目录下建立dataset3Params.m文件,在该文件中选择误差最小的最佳C和σ参数。
function [C, sigma] = dataset3Params(X, y, Xval, yval)
%返回值是C和σ
par = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30];
for i = 1:8,
for j = 1:8,
model = svmTrain(X, y, par(i), @(x1, x2) gaussianKernel(x1, x2, par(j)));
%par(i)代表C,par(j)代表σ
%用训练集数据训练出参数
predictions = svmPredict(model, Xval);
%预测的yval
%在交叉验证集上评估错误
mean(double(predictions ~= yval))
i,j
%输出C和σ对应数组的序号以及错误大小,从而选择错误最小的C和σ
end;
end;
C = 1;
sigma = 0.1;
%先预定设置返回值为这两个,没有实际意义
end
运行结果有64中可能。这里发现i=5、j=3时候,mean(double(predictions ~= yval))最小为0.003.也就是C = 1;sigma = 0.1;时候。
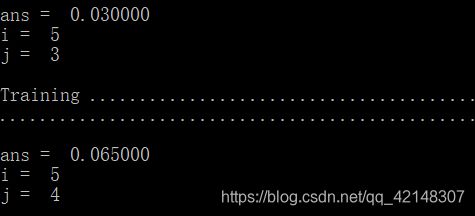
修改dataset3Params.m文件:
function [C, sigma] = dataset3Params(X, y, Xval, yval)
%返回值是C和σ
C = 1;
sigma = 0.1;
%返回值最佳的C和σ
end然后利用学习好的C = 1;sigma = 0.1;画出决策边界:


2、垃圾邮件分类
2.1电子邮件的预处理
等待处理的邮件:

大写转化为小写:整个电子邮件被转换成小写,因此忽略了大写字母(例如,指示与指示处理相同)。
剥离HTML:所有的HTML标记都将从电子邮件中删除。许多电子邮件通常带有HTML格式;我们删除了所有的HTML标记,这样只剩下内容。
规范化URL:所有URL都将替换为文本“httpaddr”。
规范化电子邮件地址:所有电子邮件地址都将替换为文本“emailaddr”。
规范化数字:所有数字均替换为文本“数字”。
美元正规化:所有美元符号($)将替换为文本“美元”。
词干分析:“include”、“includes”、“include”和“including”都会被替换为“include”。
删除非文字:非单词和标点符号已被删除。所有的空白(制表符、换行符、空格)都被修剪成一个空格字符。
得有一份邮件例子,将emailSample1.txt文件复制到当前目录中来,第一步先实现加载一份邮件,在当前目录下建立readFile.m文件:
function file_contents = readFile(filename)
%加载一份文件,返回文件的内容
fid = fopen(filename);
%打开文件
if fid
file_contents = fscanf(fid, '%c', inf);
%将文件的内容保存到file_contents中
fclose(fid);
else
file_contents = '';
fprintf('Unable to open %s\n', filename);
end
end![]()
第二步就是要根据提供的单词表,来形成邮件的索引表。

在当前目录下建立processEmail.m文件,完成上述功能:
function word_indices = processEmail(email_contents)
%返回索引列表
vocabList = getVocabList();
%加载单词表
word_indices = [];
% Lower case
email_contents = lower(email_contents);
% Strip all HTML
email_contents = regexprep(email_contents, '<[^<>]+>', ' ');
%regexprep函数作用用一个字符串替代另一个
% Handle Numbers
email_contents = regexprep(email_contents, '[0-9]+', 'number');
% Handle URLS
email_contents = regexprep(email_contents, ...
'(http|https)://[^\s]*', 'httpaddr');
% Handle Email Addresses
email_contents = regexprep(email_contents, '[^\s]+@[^\s]+', 'emailaddr');
% Handle $ sign
email_contents = regexprep(email_contents, '[$]+', 'dollar');
% Output the email to screen as well
fprintf('\n==== Processed Email ====\n\n');
% Process file
l = 0;
while ~isempty(email_contents)
% Tokenize and also get rid of any punctuation
[str, email_contents] = ...
strtok(email_contents, ...
[' @$/#.-:&*+=[]?!(){},''">_<;%' char(10) char(13)]);
% Remove any non alphanumeric characters
str = regexprep(str, '[^a-zA-Z0-9]', '');
% Stem the word
try str = porterStemmer(strtrim(str));
catch str = ''; continue;
end;
% Skip the word if it is too short
if length(str) < 1
continue;
end
for i = 1:length(vocabList),
if strcmp(str, vocabList{i}) == 1,
word_indices = [word_indices i];
end;
end;
%您将得到一个字符串str,它是处理过的电子邮件中的一个单词。你应该在词汇表词汇表中查找该词,
%并找出该词是否存在于词汇表中。如果单词存在,则应将该单词的索引添加到word index变量中。
%如果单词不存在,因此不在词汇表中,则可以跳过该单词。
if (l + length(str) + 1) > 78
fprintf('\n');
l = 0;
%每行输出最大的长度
end
fprintf('%s ', str);
l = l + length(str) + 1;
end
end该函数调用了getVocabList函数,在当前目录下建立getVocabList.m文件,该函数实现获得单词表,由于要获得单词表,需要将vocab.txt文件复制到当前目录下:
function vocabList = getVocabList()
fid = fopen('vocab.txt');
n = 1899;
%单词的数目
vocabList = cell(n, 1);
for i = 1:n
fscanf(fid, '%d', 1);
vocabList{i} = fscanf(fid, '%s', 1);
end
fclose(fid);
end上述函数还调用了porterStemmer函数,该函数的作用就是词法分析,在当前目录下建立porterStemmer.m文件:
function stem = porterStemmer(inString)
inString = lower(inString);
global j;
b = inString;
k = length(b);
k0 = 1;
j = k;
stem = b;
if k > 2
% Output displays per step are commented out.
%disp(sprintf('Word to stem: %s', b));
x = step1ab(b, k, k0);
%disp(sprintf('Steps 1A and B yield: %s', x{1}));
x = step1c(x{1}, x{2}, k0);
%disp(sprintf('Step 1C yields: %s', x{1}));
x = step2(x{1}, x{2}, k0);
%disp(sprintf('Step 2 yields: %s', x{1}));
x = step3(x{1}, x{2}, k0);
%disp(sprintf('Step 3 yields: %s', x{1}));
x = step4(x{1}, x{2}, k0);
%disp(sprintf('Step 4 yields: %s', x{1}));
x = step5(x{1}, x{2}, k0);
%disp(sprintf('Step 5 yields: %s', x{1}));
stem = x{1};
end
% cons(j) is TRUE <=> b[j] is a consonant.
function c = cons(i, b, k0)
c = true;
switch(b(i))
case {'a', 'e', 'i', 'o', 'u'}
c = false;
case 'y'
if i == k0
c = true;
else
c = ~cons(i - 1, b, k0);
end
end
function n = measure(b, k0)
global j;
n = 0;
i = k0;
while true
if i > j
return
end
if ~cons(i, b, k0)
break;
end
i = i + 1;
end
i = i + 1;
while true
while true
if i > j
return
end
if cons(i, b, k0)
break;
end
i = i + 1;
end
i = i + 1;
n = n + 1;
while true
if i > j
return
end
if ~cons(i, b, k0)
break;
end
i = i + 1;
end
i = i + 1;
end
% vowelinstem() is TRUE <=> k0,...j contains a vowel
function vis = vowelinstem(b, k0)
global j;
for i = k0:j,
if ~cons(i, b, k0)
vis = true;
return
end
end
vis = false;
%doublec(i) is TRUE <=> i,(i-1) contain a double consonant.
function dc = doublec(i, b, k0)
if i < k0+1
dc = false;
return
end
if b(i) ~= b(i-1)
dc = false;
return
end
dc = cons(i, b, k0);
function c1 = cvc(i, b, k0)
if ((i < (k0+2)) || ~cons(i, b, k0) || cons(i-1, b, k0) || ~cons(i-2, b, k0))
c1 = false;
else
if (b(i) == 'w' || b(i) == 'x' || b(i) == 'y')
c1 = false;
return
end
c1 = true;
end
% ends(s) is TRUE <=> k0,...k ends with the string s.
function s = ends(str, b, k)
global j;
if (str(length(str)) ~= b(k))
s = false;
return
end % tiny speed-up
if (length(str) > k)
s = false;
return
end
if strcmp(b(k-length(str)+1:k), str)
s = true;
j = k - length(str);
return
else
s = false;
end
function so = setto(s, b, k)
global j;
for i = j+1:(j+length(s))
b(i) = s(i-j);
end
if k > j+length(s)
b((j+length(s)+1):k) = '';
end
k = length(b);
so = {b, k};
function r = rs(str, b, k, k0)
r = {b, k};
if measure(b, k0) > 0
r = setto(str, b, k);
end
function s1ab = step1ab(b, k, k0)
global j;
if b(k) == 's'
if ends('sses', b, k)
k = k-2;
elseif ends('ies', b, k)
retVal = setto('i', b, k);
b = retVal{1};
k = retVal{2};
elseif (b(k-1) ~= 's')
k = k-1;
end
end
if ends('eed', b, k)
if measure(b, k0) > 0;
k = k-1;
end
elseif (ends('ed', b, k) || ends('ing', b, k)) && vowelinstem(b, k0)
k = j;
retVal = {b, k};
if ends('at', b, k)
retVal = setto('ate', b(k0:k), k);
elseif ends('bl', b, k)
retVal = setto('ble', b(k0:k), k);
elseif ends('iz', b, k)
retVal = setto('ize', b(k0:k), k);
elseif doublec(k, b, k0)
retVal = {b, k-1};
if b(retVal{2}) == 'l' || b(retVal{2}) == 's' || ...
b(retVal{2}) == 'z'
retVal = {retVal{1}, retVal{2}+1};
end
elseif measure(b, k0) == 1 && cvc(k, b, k0)
retVal = setto('e', b(k0:k), k);
end
k = retVal{2};
b = retVal{1}(k0:k);
end
j = k;
s1ab = {b(k0:k), k};
% step1c() turns terminal y to i when there is another vowel in the stem.
function s1c = step1c(b, k, k0)
global j;
if ends('y', b, k) && vowelinstem(b, k0)
b(k) = 'i';
end
j = k;
s1c = {b, k};
function s2 = step2(b, k, k0)
global j;
s2 = {b, k};
switch b(k-1)
case {'a'}
if ends('ational', b, k) s2 = rs('ate', b, k, k0);
elseif ends('tional', b, k) s2 = rs('tion', b, k, k0); end;
case {'c'}
if ends('enci', b, k) s2 = rs('ence', b, k, k0);
elseif ends('anci', b, k) s2 = rs('ance', b, k, k0); end;
case {'e'}
if ends('izer', b, k) s2 = rs('ize', b, k, k0); end;
case {'l'}
if ends('bli', b, k) s2 = rs('ble', b, k, k0);
elseif ends('alli', b, k) s2 = rs('al', b, k, k0);
elseif ends('entli', b, k) s2 = rs('ent', b, k, k0);
elseif ends('eli', b, k) s2 = rs('e', b, k, k0);
elseif ends('ousli', b, k) s2 = rs('ous', b, k, k0); end;
case {'o'}
if ends('ization', b, k) s2 = rs('ize', b, k, k0);
elseif ends('ation', b, k) s2 = rs('ate', b, k, k0);
elseif ends('ator', b, k) s2 = rs('ate', b, k, k0); end;
case {'s'}
if ends('alism', b, k) s2 = rs('al', b, k, k0);
elseif ends('iveness', b, k) s2 = rs('ive', b, k, k0);
elseif ends('fulness', b, k) s2 = rs('ful', b, k, k0);
elseif ends('ousness', b, k) s2 = rs('ous', b, k, k0); end;
case {'t'}
if ends('aliti', b, k) s2 = rs('al', b, k, k0);
elseif ends('iviti', b, k) s2 = rs('ive', b, k, k0);
elseif ends('biliti', b, k) s2 = rs('ble', b, k, k0); end;
case {'g'}
if ends('logi', b, k) s2 = rs('log', b, k, k0); end;
end
j = s2{2};
% step3() deals with -ic-, -full, -ness etc. similar strategy to step2.
function s3 = step3(b, k, k0)
global j;
s3 = {b, k};
switch b(k)
case {'e'}
if ends('icate', b, k) s3 = rs('ic', b, k, k0);
elseif ends('ative', b, k) s3 = rs('', b, k, k0);
elseif ends('alize', b, k) s3 = rs('al', b, k, k0); end;
case {'i'}
if ends('iciti', b, k) s3 = rs('ic', b, k, k0); end;
case {'l'}
if ends('ical', b, k) s3 = rs('ic', b, k, k0);
elseif ends('ful', b, k) s3 = rs('', b, k, k0); end;
case {'s'}
if ends('ness', b, k) s3 = rs('', b, k, k0); end;
end
j = s3{2};
% step4() takes off -ant, -ence etc., in context <c>vcvc<v>.
function s4 = step4(b, k, k0)
global j;
switch b(k-1)
case {'a'}
if ends('al', b, k) end;
case {'c'}
if ends('ance', b, k)
elseif ends('ence', b, k) end;
case {'e'}
if ends('er', b, k) end;
case {'i'}
if ends('ic', b, k) end;
case {'l'}
if ends('able', b, k)
elseif ends('ible', b, k) end;
case {'n'}
if ends('ant', b, k)
elseif ends('ement', b, k)
elseif ends('ment', b, k)
elseif ends('ent', b, k) end;
case {'o'}
if ends('ion', b, k)
if j == 0
elseif ~(strcmp(b(j),'s') || strcmp(b(j),'t'))
j = k;
end
elseif ends('ou', b, k) end;
case {'s'}
if ends('ism', b, k) end;
case {'t'}
if ends('ate', b, k)
elseif ends('iti', b, k) end;
case {'u'}
if ends('ous', b, k) end;
case {'v'}
if ends('ive', b, k) end;
case {'z'}
if ends('ize', b, k) end;
end
if measure(b, k0) > 1
s4 = {b(k0:j), j};
else
s4 = {b(k0:k), k};
end
% step5() removes a final -e if m() > 1, and changes -ll to -l if m() > 1.
function s5 = step5(b, k, k0)
global j;
j = k;
if b(k) == 'e'
a = measure(b, k0);
if (a > 1) || ((a == 1) && ~cvc(k-1, b, k0))
k = k-1;
end
end
if (b(k) == 'l') && doublec(k, b, k0) && (measure(b, k0) > 1)
k = k-1;
end
s5 = {b(k0:k), k};2.2从电子邮件中提取特征

在当前目录下建立emailFeatures.m文件,完成特征向量的建立:
function x = emailFeatures(word_indices)
n = 1899;
x = zeros(n, 1);
for i = 1:length(word_indices),
x(word_indices(i)) = 1;
end;
end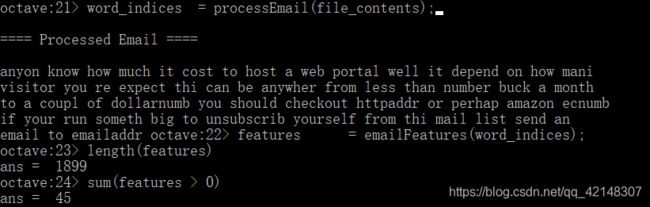
2.3垃圾邮件分类的训练支持向量机
spamTrain.mat包含4000个垃圾邮件和非垃圾邮件的培训示例,而垃圾测试垫包含1000个测试示例。使用processEmail和emailFeatures函数对每个原始电子邮件进行处理,并将其转换为向量x(i)∈R。
将spamTrain训练集中的数据进行训练,加载数据集后,将继续训练支持向量机,以便在垃圾邮件(y=1)和非垃圾邮件(y=0)之间进行分类。一旦训练完成,您应该看到分类器获得了大约99.8%的训练准确率和98.5%的测试准确率。
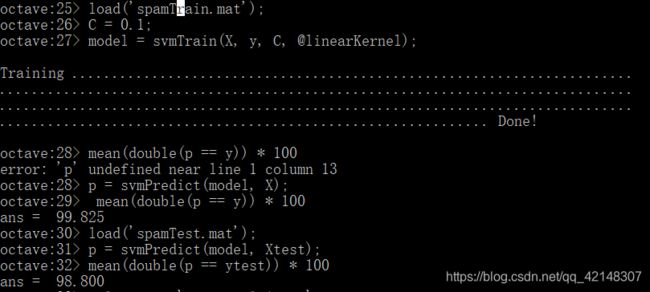
开始在你自己的电子邮件上试用了,在这里包含了两个电子邮件示例(emailSample1.txt和emailSample2.txt)和两个垃圾邮件示例(spamSample1.txt和spamSample2.txt)
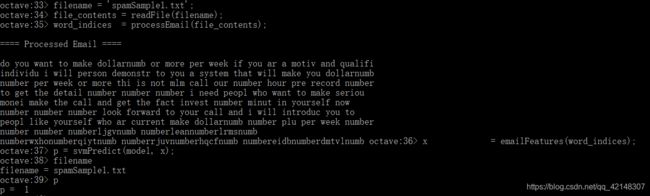
然后成功地预测了spamSample1.txt是一个垃圾邮件。