python数字图像处理基础(五)——Canny边缘检测、图像金字塔、图像分割
目录
-
- Canny边缘检测
-
- 原理步骤
- 图像金字塔
-
- 1.高斯金字塔
- 2.拉普拉斯金字塔
- 图像分割
- 图像轮廓检测
-
- 1.检测轮廓
- 2.绘制轮廓
- 3.补充
Canny边缘检测
梯度是什么?
梯度就是变化的最快的那个方向
edge = cv2.Canny(image, threshold1, threshold2[, edges[, apertureSize[, L2gradient ]]])
- 第一个参数是需要处理的原图像,该图像必须为单通道的灰度图;
- 第二个参数是阈值1;
- 第三个参数是阈值2。
原理步骤
1)使用高斯滤波器,以平滑图像,滤除噪声
2)计算图像中每个像素点的梯度强度和方向
3)应用非极大值(Non-Maximum Suppression)抑制,以消除边缘检测带来的杂散响应
4)应用双阈值检测来确定真实和潜在的边缘
5)通过抑制孤立的弱边缘最终完成边缘检测
img = cv2.imread("car.png", cv2.IMREAD_GRAYSCALE)
v = cv2.Canny(img, 120, 250)
注:120,250为两个梯度值(阈值)。大于250的处理为边界;
介于120到250的,若是连有边界(大于250)的,也认为是边界,保留,否则舍弃;
小于120的,舍弃
Canny 的目标是找到一个最优的边缘检测算法,最优边缘检测的含义是:
-
最优检测:算法能够尽可能多地标识出图像中的实际边缘,漏检真实边缘的概率和误检非边缘的概率都尽可能小;
-
最优定位准则:检测到的边缘点的位置距离实际边缘点的位置最近,或者是由于噪声影响引起检测出的边缘偏离物体的真实边缘的程度最小;
-
检测点与边缘点一一对应:算子检测的边缘点与实际边缘点应该是一一对应
Canny边缘检测算法可以分为以下5个步骤:
- 应用高斯滤波来平滑图像,目的是去除噪声
- 找寻图像的强度梯度(intensity gradients)
- 应用非最大抑制(non-maximum suppression)技术来消除边误检(本来不是但检测出来是)
- 应用双阈值的方法来决定可能的(潜在的)边界
- 利用滞后技术来跟踪边界
- 这里提供一个示例:
import cv2
import numpy as np
# 读取图像
img = cv2.imread("./image/car1.jpg")
# 将图像转为灰度
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 使用Canny边缘检测
edges = cv2.Canny(gray, 120, 250)
# 寻找轮廓
contours, hierarchy = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 绘制轮廓
contour_img = np.zeros_like(img)
cv2.drawContours(contour_img, contours, -1, (0, 255, 0), 2)
# 显示原始图像、Canny边缘检测结果和带有轮廓的图像
cv2.imshow("Original Image", img)
cv2.imshow("Canny Edges", edges)
cv2.imshow("Contours", contour_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
结果如下:

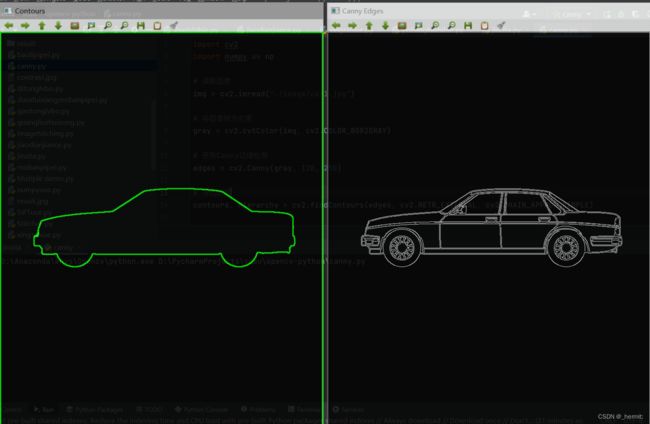
这个例子演示了以下步骤:
将彩色图像转换为灰度图像。
使用Canny边缘检测来获取图像边缘。
寻找轮廓,并将它们存储在contours中。
创建一个全黑图像,然后使用cv2.drawContours()将轮廓绘制在这个图像上。
最后,通过cv2.imshow()显示原始图像、Canny边缘检测结果和带有轮廓的图像。
图像金字塔
图像金字塔是图像多尺度表达的一种,是一种以多分辨率来解释图像的有效但概念简单的结构。
一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。
其通过梯次向下采样获得,直到达到某个终止条件才停止采样。
我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。
从上面对图像金字塔的定义来看,图像金字塔的功能之一就是对图像尺度尺度的转换,
即放大或者缩小图片,在OpenCV中提供了两种方法:
cv2.resize() 这种方法可直接对图像进行尺度的变换
cv2.pyrUp() 对图像的向上采样操作
cv2.pyrDown() 对图像的向下采样操作
1.高斯金字塔
用来向下采样,是主要的图像金字塔
注:这里的向下,是指大图到小图,对应到金字塔实际上是从底层大的到顶端小的
img = cv2.imread('luotuo.jpg', 0) # 读为灰度图
up_img = cv2.pyrUp(img) # 上采样操作
img_1 = cv2.pyrDown(img) # 下采样操作
这里的向下与向上采样是对图像的尺度来说的 ,
相当于倒立的金字塔,向上就是图像尺寸加倍,向下就是图像尺寸减半。
需要注意的是,pyrUp和pyrDown不是互逆的,即上采样不是下采样的逆操作。
pyrDown()是一个会丢失信息的函数。为了恢复原来更高分辨率的图像,
要获得由于下采样操作所丢失的信息,这些数据就和拉普拉斯金字塔有关了。
2.拉普拉斯金字塔
拉普拉斯金字塔是图像金字塔中的一种,它主要用于图像的向上采样。拉普拉斯金字塔的构建与高斯金字塔密切相关,它表示原始图像和该图像在不同尺度上的逼近之间的差异。
拉普拉斯金字塔的构建步骤如下:
- 构建高斯金字塔。
- 对于每一层高斯金字塔,通过减去其上一层高斯金字塔的上采样版本,得到拉普拉斯金字塔。
在这里,我们可以通过下面的步骤演示拉普拉斯金字塔的构建:
import cv2
import numpy as np
# 读取图像
img = cv2.imread('luotuo.jpg')
# 构建高斯金字塔
gaussian_pyramid = [img]
for i in range(6):
img = cv2.pyrDown(img)
gaussian_pyramid.append(img)
# 构建拉普拉斯金字塔
laplacian_pyramid = [gaussian_pyramid[5]]
for i in range(5, 0, -1):
gaussian_expanded = cv2.pyrUp(gaussian_pyramid[i])
laplacian = cv2.subtract(gaussian_pyramid[i - 1], gaussian_expanded)
laplacian_pyramid.append(laplacian)
# 显示原始图像和金字塔图像
cv2.imshow('Original Image', img)
cv2.waitKey(0)
for i in range(6):
cv2.imshow(f'Gaussian Pyramid Layer {i}', gaussian_pyramid[i])
cv2.waitKey(0)
for i in range(6):
cv2.imshow(f'Laplacian Pyramid Layer {i}', laplacian_pyramid[i])
cv2.waitKey(0)
cv2.destroyAllWindows()
在上述代码中,我们首先构建了高斯金字塔,然后通过对高斯金字塔进行操作得到拉普拉斯金字塔。最后,我们分别显示了原始图像、高斯金字塔图像和拉普拉斯金字塔图像的不同层次。
图像分割
所谓图像分割是指根据灰度、彩色、空间纹理、几何形状等特征把图像划分成若干个互不相交的区域,使得这些特征在同一区域内表现出一致性或相似性,而在不同区域间表现出明显的不同。简单的说就是在一副图像中,把目标从背景中分离出来。
一般来说,用于图像分割的算法主要有五类:
第一种是阈值分割方法( threshold segmentation method)。
阈值分割是基于区域的分割算法中最常用的分割技术之一,其实质是根据一定的标准自动确定最佳阈值,并根据灰度级使用这些像素来实现聚类。**优缺点:**计算简单,效率较高;只考虑像素点灰度值本身的特征,一般不考虑空间特征,因此对噪声比较敏感,鲁棒性不高。
其次是区域增长细分( regional growth segmentation)。
区域增长算法的基本思想是将具有相似属性的像素组合以形成区域,即,首先划分每个区域以找到种子像素作为生长点,然后将周围邻域与相似属性合并其区域中的像素。**优缺点:**对复杂图像分割效果好;但是算法复杂,计算量大;分裂有可能破坏区域的边界。
第三种是边缘检测分割方法( edge detection segmentation method)。
边缘检测分割算法是指利用不同区域的像素灰度或边缘的颜色不连续检测区域,以实现图像分割。边缘检测技术通常可以按照处理的技术分为串行边缘检测和并行边缘检测。串行边缘检测是要想确定当前像素点是否属于检测边缘上的一点,取决于先前像素的验证结果。并行边缘检测是一个像素点是否属于检测边缘高尚的一点取决于当前正在检测的像素点以及与该像素点的一些临近像素点。
**优缺点:**边缘定位准确;速度快;但是不能保证边缘的连续性和封闭性;在高细节区域存在大量的碎边缘,难以形成一个大区域,但是又不宜将高细节区域分成小碎片;
第四种是基于聚类的分割( segmentation based on clustering)。
基于聚类的算法是基于事物之间的相似性作为类划分的标准,即根据样本集的内部结构将其划分为若干子类,以使相同类型的类尽可能相似、不同的类型的类尽可能不相似。同一聚类中的点使用相同颜色标记,不同聚类颜色不同。
优缺点 :传统 FCM 算法没有考虑空间信息,对噪声和灰度不均匀敏感。
最后是基于CNN中弱监督学习的分割。
它指的是为图像中的每个像素分配语义标签的问题,又称语义分割。它由三部分组成。 1)给出包含哪些对象的图像。 2)给出一个对象的边框。 3)图像中的对象区域用部分像素标记。
**优缺点:**解决图像中的噪声和不均匀问题。可以用于抑制噪声、特性提取、边缘检测、图像分割等图像处理问题,处理灰度图像;选择何种网络结构是这种方法要解决的主要问题。需要大量数据,速度非常慢,结构复杂,分割精度与数据量有关。
图像轮廓检测
1.检测轮廓
cv2.findContours(img,mode,method)
其中,
-
mode 轮廓检索模式,有以下几种
RETR_TREE:检索所有的轮廓,并重构嵌套轮廓的整个层次,最常用
RETR_EXTERNAL:只检索最外面的轮廓
RETR_LIST:检索所有的轮廓,并将其保存到一条链表当中
RETR_CCOMP:检索所有的轮廓,并将他们组织为两层:顶层是各部分的外部边界,第二层是空洞的边界 -
method 轮廓逼近方法
CHAIN_APPROX_NONE:以Freeman链码的方式输出轮廓,所有其他方法输出多边形(顶点的序列)
CHAIN_APPROX_SIMPLE:压缩水平的、垂直的和斜的部分,也就是,函数只保留他们的终点部分(图形的所有顶点)
返回值
cv2.findContours()函数返回两个值,一个是轮廓本身,还有一个是每条轮廓对应的属性。
-
contour返回值
cv2.findContours()函数首先返回一个list,list中每个元素都是图像中的一个轮廓,用numpy中的ndarray表示。这个概念非常重要。在下面drawContours中会看见。可以打印观察contours的数据类型。print (type(contours))
print (type(contours[0]))
print (len(contours)) -
hierarchy返回值
该函数还可返回一个可选的hiararchy结果,这是一个ndarray,其中的元素个数和轮廓个数相同,每个轮廓contours[i]对应4个hierarchy元素hierarchy[i] [0] ~hierarchy[i] [3],分别表示后一个轮廓、前一个轮廓、父轮廓、内嵌轮廓的索引编号,如果没有对应项,则该值为负数。
2.绘制轮廓
cv2.drawContours(image, contours, contourIdx, color[, thickness[, lineType[, hierarchy[,maxLevel[, offset ]]]]])
其中:
- 第一个参数传入所要绘制轮廓的背景图片
- 第二个参数是轮廓本身
- 第三个参数指定绘制轮廓中的哪条轮廓,如果是-1,则绘制其中的所有的轮廓。thickness表示的是轮廓的宽度,如果是-1(cv2.FILLED),表示为填充模式。
步骤:
先把彩图转化为灰度图
再转为二值图像(非黑即白)
3.补充
OpenCV中通过cv2.minEnclosingCircle()可以帮我们找到一个对象的外接圆。它是所有能够包括对象的圆中面积最小的一个。
(x,y),radius = cv2.minEnclosingCircle(contours[i])
center = (int(x),int(y))
radius = int(radius)
img = cv2.circle(img,center,radius,(0,255,0),2)
- 绘图函数cv2.line()、cv2.circle()、cv2.rectangle()、cv2.ellipse()、cv2.putText()、cv2.polylines