大数据学习计划【2019经典不断更新】
我为什么要学习大数据:因为我不喜欢现在国企的工作氛围,不看好这个行业,另外我通过多方渠道了解到,其中包括李笑来、凯文凯利、和各种新闻及文章,现在我们正处于大数据时代,我是一个不安于现状、喜欢探索顺应时代发展趋势学习新东西的人,希望通过努力来改变自己生活状态渴望成功的人,我喜欢与朝气蓬勃奋发向上的人一起活在未来。

很多初学者,对大数据的概念都是模糊不清的,大数据是什么,能做什么,学的时候,该按照什么线路去学习,学完往哪方面发展,想深入了解,想学习的同学欢迎加入大数据学习qq群:199427210,有大量干货(零基础以及进阶的经典实战)分享给大家,并且有清华大学毕业的资深大数据讲师给大家免费授课,给大家分享目前国内最完整的大数据高端实战实用学习流程体系。
入门之前先来看看大数据涉及到的内容
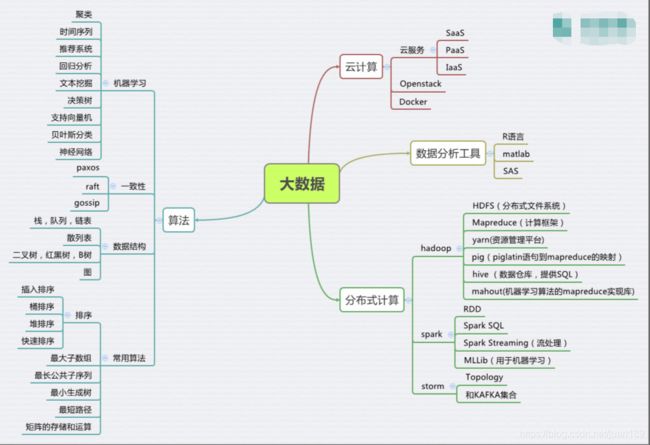
要学习并实践 Java、Scala、Hadoop、HBase、Mahout、Sqoop及Spark等大数据技术。新手学习大数据设计非常系统的路径,加入大量的动手实验,帮助大家在实验数据集上实践各种大数据工具。
学习路径:入门知识 - Java基础 - Scala基础 - Hadoop技术模块 - Hadoop项目实战 - Spark技术模块 -大数据项目实战。从基础到实战,逐层深入。
大数据方向的工作目前分为三个主要方向:
01.大数据工程师
02.数据分析师
03.大数据科学家
04.其他(数据挖掘本质算是机器学习,不过和数据相关,也可以理解为大数据的一个方向吧)
一、大数据工程师的技能要求
附上二份比较权威的大数据工程师技能图
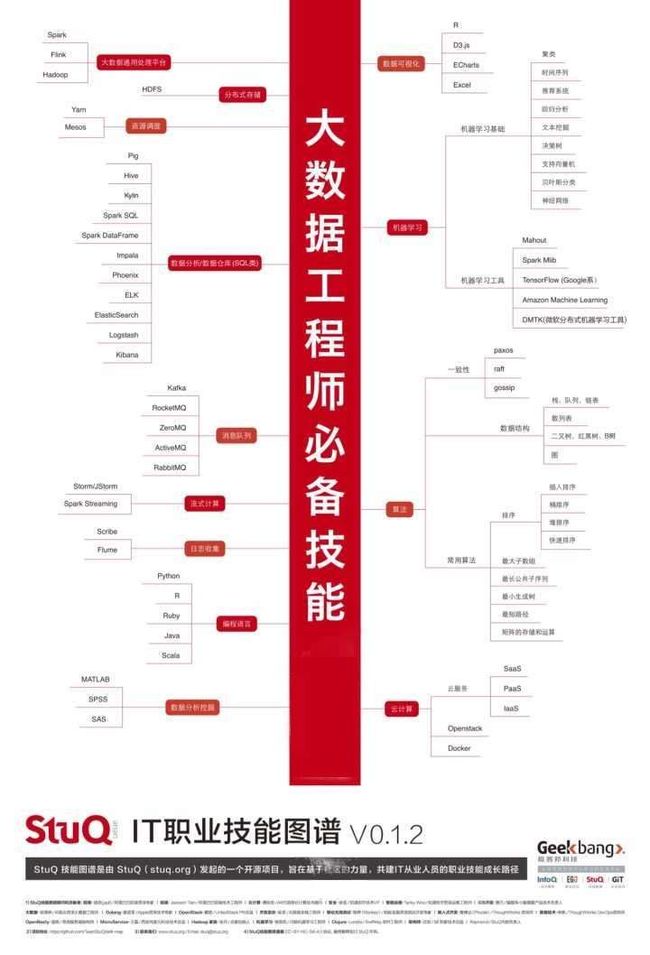
学习方法如下:
1、Linux命令基础实战
大数据架构体系结构及开源组件介绍 (要掌握)
Linux基本操作 (常见的Linux命令需要会)
2:Hadoop基础
Hadoop基础,对Hadoop架构、核心组件HDFS/YARN做了深入浅出的介绍,让你快速把握Hadoop的核心技术和工作原理,逐渐形成分布式思维;
Hadoop介绍
Hadoop运行模式
3:Hadoop集群搭建
Hadoop集群搭建——安装Linux虚拟机
Hadoop集群搭建——远程连接
Hadoop集群搭建(on Linux)——Hadoop(上)
Hadoop集群搭建(on Linux)——Hadoop(下)
Hadoop集群搭建(on Mac)——Hadoop
4:HDFS原理
番外篇-课程体系
HDFS架构原理
FS Shell命令介绍及实践
5:YARN工作原理
YARN的产生背景
YARN的设计思想
YARN的基本架构
YARN的工作流程(小结)
6:Sqoop
Sqoop,作为关系型数据库与Hadoop之间的桥梁,批量传输数据,让你自然的从关系型数据库过度到Hadoop平台,在关系型数据库与Hadoop之间游刃有余的进行数据导入导出;
Sqoop & Hive课程内容介绍
Sqoop介绍与安装
Sqoop的基本使用
Sqoop 导入参数详解
Sqoop导入实战
Sqoop增量导入(上)
Sqoop增量导入(下)
Sqoop导出实战(上)
Sqoop导出实战(下)
Sqoop Job
7:Hive
Hive,基于Hadoop大数据平台的数据仓库,可以让你实现传统数据仓库中的绝大部分数据处理、统计分析,让你在Hadoop大数据平台上感受到Hive QL带来的便利的交互式查询体验;Mars将以日志分析或其他示例带大家熟练掌握Hive的应用;
Hive架构介绍(一)
Hive架构介绍(二)
Hive环境搭建(一)
Hive环境搭建(二)
Hive CLI初探
Beeline介绍
Hive数据类型
Hive表一——标准建表语句解析&内、外表
Hive表二——文件及数据格式
Hive分区&桶&倾斜概念
Hive表——Alter
Hive视图&索引简介
Hive表——show & Desc命令
Hive数据导入--load
Hive数据导入--insert
Hive分区表实战
Hive复杂数据类型的嵌套实例
Hive源码阅读环境
Hive执行原理
Hive查询优化
UDF函数实例
Hive终极实例——日志分析
(1)网站日志分析的术语、架构介绍
(2)建表及数据准备
(3)数据处理及统计分析
(4)数据采集到统计分析结果的crontab定时调度
8:HBase
HBase,列式存储数据库,提供了快速的查询方式,是Apache Kylin的默认数据存储结果;
HBase介绍及架构
HBase安装
HBase操作实战
Hive与HBase集成实战
9:Kylin
Kylin,基于Hadoop的OLAP分析引擎,在Kylin中可以实现传统OLAP的各种操作,直接读取Hive的数据或流式数据作为数据源,把这些数据根据业务模型构建成Cube,Kylin提供了基于Hadoop(MapReduce)的Cube构建,Build完成的Cube数据直接存储于HBase中。Kylin提供了Web UI供查询,包括一些图表展现,是基于大数据的完美OLAP工具;
维度建模
Kylin背景及原理架构
Kylin环境搭建
维度建模知识
Kylin Cube Build步骤解析
Kylin Cube实战
Kylin 增量Cube
Kylin 优化
10:Spark
Spark,基于内存计算的大数据计算引擎,提供了Spark SQL、Spark MLlib(基于Spark的机器学习)、SparkR等框架适应不同的应用需求,Spark专题将和大家一起实践操作各种应用和算法;
Spark集群搭建
Spark Core
Spark WordCount(Spark-shell/pyspark..)
IDEA IntelliJ搭建Spark开发环境
Spark编程实例
Spark SQL及DataFrame
Spark SQL实例
Spark Streaming
Spark Streaming实例
Spark MLlib
Spark MLlib应用实例
Spark R介绍
可以基于每个模版去查一些相应的资料 及教程,然后按照操作即可。。。
对于小白学习大数据需要注意的点有很多,但无论如何,既然你选择了进入大数据行业,那么便只顾风雨兼程。正所谓不忘初心、方得始终,学习大数据你最需要的还是一颗持之以恒的心。
我想告诉你,每一份坚持都是成功的累积,只要相信自己,总会遇到惊喜;我想告诉你,每一种活都有各自的轨迹,记得肯定自己,不要轻言放弃;我想告诉你,每一个清晨都是希望的伊始,记得鼓励自己,展现自信的魅力。
大数据的前景和意义也就不言而喻了,未来,大数据能够对大量、动态、能持续的数据,通过运用新系统、新工具、新模型的挖掘,从而获得具有洞察力和新价值的东西。源于互联网的发展,收集数据的门槛越来越低,收集数据变成一件简单的事情,这些海量的数据中是含有无穷的信息和价值的,如何更好的提炼出有价值的信息,这就体现大数据的用途了。