Python实现供应链数据分析
一、前言
A市客户有意加盟380开设连锁门店,请根据A市已有销售点的销售数据分析,给予该客户铺货支持和经营策略建议。通过对部门的运营情况、财务状况、物流管理等不同维度的分析,评估该部门健康状况和发展趋势,指导平台发现问题并进行优化。
二、任务分析
- 分析销售数据基本信息。
- 比较CBD店和社区店,确定新店铺的选址。
- 比较各商品确定新销售店的主要铺货产品。
- 分析销售数据的季节性特点,安排店员休假或培训时间以及订货量。
- 分析社区店有哪些季节性很强的产品。
三、完整代码实现
(一)预处理供应链商品销售数据
1. 导入相关库及读入数据
导入pandas、numpy、seaborn、matplotlib等库,并用pandas读入Excel文件,保存备份数据。
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
plt.style.use('ggplot') # 设置plt绘图风格
plt.rcParams['font.family'] = 'SimHei' # 设置字体
data = pd.read_excel('供应链商品销售数据.xlsx', skiprows=1, usecols='B:E')
# 数据备份
data_copy = data.copy(deep=False)
2. 添加季度列
构造月份对应季度的字典,然后将数据中月份转化为季度并存入源数据。
# 增加季度列
data_month = {'January': '第一季度', 'February': '第一季度', 'March': '第一季度',
'April': '第二季度', 'May': '第二季度', 'June': '第二季度',
'July': '第三季度', 'August': '第三季度', 'September': '第三季度',
'October': '第四季度', 'November': '第四季度', 'December': '第四季度'}
data_copy['销售季度'] = data_copy['销售月份'].map(data_month)
# 前五行数据
data_copy.head()

3. 缺失值检测
用Dataframe的isnull()方法检测缺失值,结果显示为无缺失值。
# 缺失值检测
data.isnull().sum()

4. 数据集信息描述
用Dataframe的describe()方法获得销售额的特征信息,Dataframe.info()查看数据集各列的相关信息。
# 数据集基本描述信息
data_copy.describe().T

# 数据集信息
data_copy.info()

(二)分析新开拓销售点选址
1. 绘制CBD店及社区店销售点数量柱状图
对销售店址进行汇总,发现CBD店有680家,社区店有646家。
data_address = data_copy['销售点类型'].value_counts()
data_address
plt.bar(data_address.index, data_address.values, width=0.3)
plt.xlabel('选址')
plt.ylabel('数量')
plt.title('新开拓销售点的选址情况')
for i, j in zip(data_address.index, data_address.values):
plt.text(i, j , s=j, ha='center', va='bottom')
plt.savefig('新开拓销售点的选址情况.jpg')
plt.show()

2. 绘制CBD店及社区店年销售额占比饼图
CDB店销售额占销售总额的51.98%,而社区店销售额占销售总额的48.02%。
data_address_gb = data_copy[['销售点类型', '销售额(万元)']].groupby(by='销售点类型')
goods_sum = data_address_gb.agg({'销售额(万元)': np.sum})
plt.figure(figsize=(5, 5))
plt.pie(x=goods_sum.values, autopct='%.2f %%', labels=goods_sum.index, explode=[0.01, 0.01])
plt.title('不同选址销售总额占比情况')
plt.savefig('不同选址销售总额占比情况.jpg')
plt.show()

3. 绘制CBD店及社区店年销售额柱状图
通过可视化分析,CBD店年销售额为4985.5万元,而社区店年销售额为4606.5万元,,说明CBD店所在区人流量比较多,所以新开店店址可以选择CBD店,有利于开拓市场。
plt.bar(goods_sum.index, goods_sum.values.reshape(2, ), width=0.3)
plt.xlabel('选址')
plt.ylabel('销售额')
plt.title('不同选址销售总额情况')
for i, j in zip(goods_sum.index, goods_sum.values.reshape(2, )):
plt.text(i, j , s=j, ha='center', va='bottom')
plt.savefig('不同选址销售总额情况.jpg')
plt.show()

(三)挑选新店铺的主要铺货产品
1. 绘制CBD店及社区店各商品销售额折线图
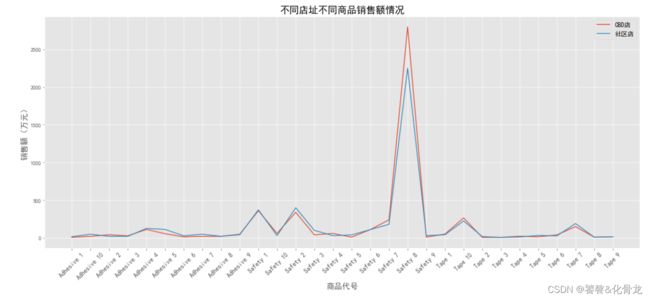
使用pandas透视表函数pivot_table()对CBD店和社区店的商品代号、销售额(万元)进行数据整合,并对两个不同店址的商品销售额进行求和,seaborn绘制折线图。发现Safety 8为销售热门产品,Safety 1、Safety 2、Tape 10及Tape 7也占有一定的市场,所以新开店可以选择这些产品作为主要铺货产品。
# 新销售店主要铺货产品
data_pt = pd.pivot_table(data=data_copy, index='商品代号', columns='销售点类型', values='销售额(万元)', aggfunc=np.sum)
data_pt.reset_index(inplace=True)
plt.figure(figsize=(20,8))
sns.lineplot(x='商品代号', y='CBD店', data=data_pt)
sns.lineplot(x='商品代号', y='社区店', data=data_pt)
plt.xlabel('商品代号', fontsize=15)
plt.ylabel('销售额(万元)', fontsize=15)
plt.xticks(rotation=45, fontsize=12)
plt.legend(['CBD店', '社区店'], fontsize=12)
plt.title('不同店址不同商品销售额情况', fontsize=18)
plt.savefig('不同店址不同不同商品销售额情况.jpg')
plt.show()
(四)分析销售季节性特点,据以安排店员年休假或培训时间
1. 绘制CBD店及社区店四个季度销售额饼图
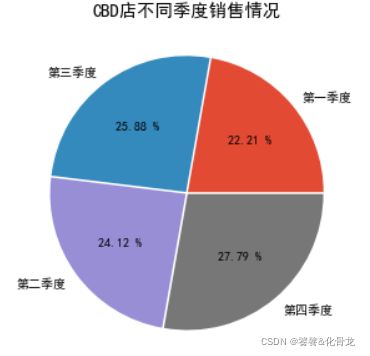
用groupby()函数聚合销售点和销售季度数据,并分为CBD店和社区店。绘制出CBD店各季度销售额占比饼图,可以看出,整体销售额占比比较接近,第一季度略少,第四季度略多。
data_mon_addre_gb = data_copy[['销售点类型', '销售季度']].groupby(by=['销售点类型', '销售季度'])
data_mon_addre = data_mon_addre_gb.agg({'销售季度': np.count_nonzero})
# 不同店址不同季度商品销售情况分析
data_cbd = data_mon_addre.loc[('CBD店')]
data_sqd = data_mon_addre.loc[('社区店')]
def pie_show(data=None, address=None):
plt.figure(figsize=(5, 5))
plt.pie(x=data.values, autopct='%.2f %%', labels=data.index, explode=[0.01]*4)
plt.title(f'{address}不同季度销售情况')
plt.savefig(f'{address}不同季度销售情况.jpg')
plt.show()
pie_show(data_sqd, 'CBD店')
同样的,利用自定义的pie_show()函数绘制出社区店各季度销售额占比饼图,可以看出,整体销售额占比仍比较接近,第四季度略少,第二季度略多。
pie_show(data_sqd, '社区店')

2. 绘制CBD店及社区店四个季度销售额趋势图
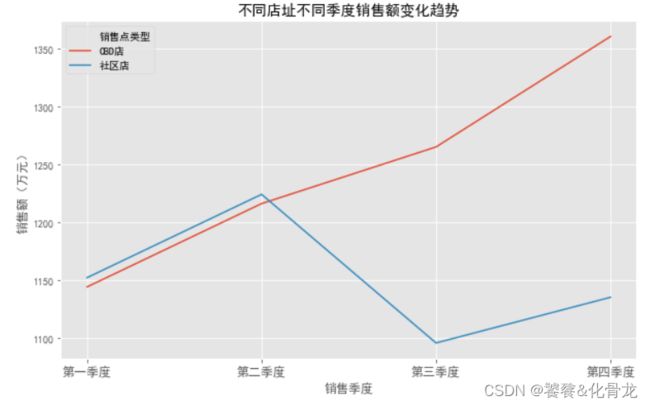
改正原季度顺序一、三、二、四。用seborn将CBD店和社区店四个季度的销售额趋势画在同一画布上。CBD店从第一季度到第四季度整体表现为上升趋势,第三季度到第四季度升幅较大。 社区店四个季度销售额整体呈波动状态,其中第一季度到第二季度为上升,第二季度到第三季度为下降,第三季度到第四季第为上升,但最终的第四季度较第一季度略少。
data_gb_qu = data_copy.groupby(by=['销售点类型', '销售季度']).agg({'销售额(万元)': np.sum})
data_qua =data_gb_qu.reset_index()
def trans(x):
if '一' in x:
return 1
elif '二' in x:
return 2
elif '三' in x:
return 3
else:
return 4
data_qua['销售季度'] = data_qua['销售季度'].apply(trans)
data_qua.sort_values(by='销售季度', inplace=True)
# 不同店址不同季节销售额情况
plt.figure(figsize=(10, 6))
sns.lineplot(x='销售季度', y='销售额(万元)', hue='销售点类型', data=data_qua)
plt.xticks([1 ,2, 3, 4], ['第一季度', '第二季度', '第三季度', '第四季度'], fontsize=12)
plt.title('不同店址不同季度销售额变化趋势')
plt.savefig('不同店址不同季度销售额变化趋势.jpg')
plt.show()
3. 绘制CBD店及社区店四个季度销售额条形图
groupby聚合CBD店和社区店各季度各月份销售数据,自定义双标签条形图。自定义并绘制CBD店不同季度月份销售额情况。结果和趋势图一致。
data_gb_qm = data_copy.groupby(by=['销售点类型', '销售季度', '销售月份']).agg({'销售额(万元)': np.sum})
data_qm = data_gb_qm.reset_index()
data_qm['销售季度'] = data_qm['销售季度'].apply(trans)
data_qm.sort_values(by='销售季度', inplace=True)
data_qm
data_qm_cbd = data_qm.loc[data_qm['销售点类型'] == 'CBD店']
data_qm_sqd = data_qm.loc[data_qm['销售点类型'] == '社区店']
def barplot_show(data=None, d=None):
plt.figure(figsize=(15, 8))
sns.barplot(x='销售额(万元)', y='销售月份', hue='销售季度', data=data)
plt.xlabel('销售额(万元)', fontsize=15)
plt.ylabel('销售月份', fontsize=15)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.title(f'{d}不同季度月份销售额情况')
plt.savefig(f'{d}不同季度月份销售额情况.jpg')
plt.show()
barplot_show(data_qm_cbd, 'CBD店')

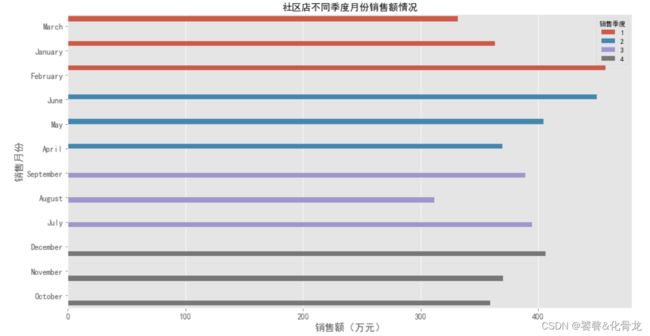
绘制社区店不同季度月份销售额情况。结果和趋势图一致。
总结:CBD店,在第一季度销售额最低,其中一月、三月、九月销售额最少,可以安排培训或休假。
社区店,在第三季度最低,其中三月和八月销售额最少,可以安排培训或休假。
barplot_show(data_qm_sqd, '社区店')
(五)分析社区店有哪些季节性很强的产品
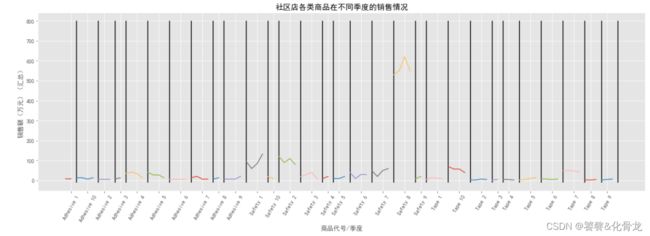
用groupby()函数聚合社区店各商品各季度的销售额。创建商品列表,循环遍历绘制各商品四个季度销售额趋势图并计数,每次遍历增加横坐标刻度并绘制下一个商品四个季度销售额趋势图。
其中商品代号为Adhesive4、Adhesive 5、safety1、safety2、safety3、safety6、safety7、safety8、tape10的商品季节性很强。
商品代号为Adhesive4的商品季节性特征为第一季度到第二季度上升,而后下降。需要在第二季度前促销出清。
商品代号为safety1、safety6、safety7的商品季节特征为第一季度到第二季度下降,而后上升。需要在 第四季度前促销出清。
商品代号为safety3、safety8的商品季节性特征为第一季度到第三季度上升,而后下降。需要在第三季度前促销出清。
商品代号为safety2、Adhesive5、tape10的商品季节性特征为第一季度奥第二季度上升,第二季度到第三季度下降,第三季度到第四季度下降。需要在第三季度前促销出清。
data_sq = data_copy.loc[data['销售点类型'] == '社区店', :]
data_sq.reset_index(drop=True)
# 按商品代号和销售季度聚合数据,销售额求和
data_goods_jd = data_sq.groupby(by=['商品代号', '销售季度'])
data_goods_ga = pd.DataFrame(data_goods_jd['销售额(万元)'].sum()).reset_index()
data_goods_ga
goods = data_goods_ga['商品代号'].unique()
plt.figure(figsize=(20, 6))
count = 0
b = []
for i in goods.tolist():
good = data_goods_ga[data_goods_ga['商品代号'] == i]
gs = len(good)
y = list(good["销售额(万元)"])
x = range(count, gs+count)
plt.plot(x, y)
plt.vlines(gs+count, -10 ,800, linestyles='-')
b.append(((count+gs)+count)//2)
count += gs
plt.xticks(b, goods, rotation=60)
plt.xlabel('商品代号/季度')
plt.ylabel('销售额(万元)(汇总)')
plt.title('社区店各类商品在不同季度的销售情况')
plt.savefig('社区店各类商品在不同季度的销售情况.jpg')
四、供应链数据分析总结
本文主要是使用Python对供应链数据进行数据处理、数据可视化操作,有效实现一份数据可视化结果,给予A市客户有效的选址建议以及铺货支持和经营策略建议。当然,本文使用的供应链数据还可以进行更深入的数据分析挖掘,数据可视化只是数据分析的简单工作,但无论多么高深的数据分析,如果能把结果可视化,都应该使用可视化的技术展现出来,让人一目了然,加之简单的文字描述使之通俗易懂。所以数据可视化是一项简单但重要的技术。