elastic search query dsl查询语法总结
elastic search query DSL 关键字很多,什么场景对应选择合适的DSL并不容易。
文章目录
-
- 核心概念
-
- 概念1
- 概念2
- 概念3
- 概念4
- 子查询语句
-
- 第1组:单个field 单值包含
- 第2组:多fields 单值包含
- 第3组:单field范围查询
- 第4组:单field单值相等
- 第5组:单field 多值相等
- 第6组:filter
- 第7组:sort排序
- 第8组:单个field 多值匹配
- 第9组:单field多值匹配
- 第10组:单field多值匹配,至少匹配几个值
- 第11组:是否存在exists
- 第12组:获取某个字段的去重记录
- 第13组:根据字段长度进行过滤
- 复合语句查询
-
- 第1组:多fields单值包含 + 过滤条件
- 第2组 多fields多值匹配
- 第3组 多fields多值匹配
- 第4组
- 第5组:多个field多个值匹配
- 特殊需求语句查询
-
- 第1组:搜索条件的权重boost
- 第2组:dis_max实现best fields策略
- 第3组:tie_breaker参数优化dis_max搜索效果
- 第4组:boost+dis_max+tie_breaker
- 第5组:most_fields策略
- 第6组:cross-fields技术改善most_fields策略
- 第7组:phrase match 短语匹配
- 第8组:基于slop参数实现proximity match 近似匹配
- 第9组:混合使用match和近似匹配实现召回率与精准度的平衡
- 第10组:使用rescoring机制优化近似匹配搜索的性能
- 第11组:实现前缀搜索
- 第12组:实现通配搜索
- 第13组:实现正则搜索
- 第14组:negative boost
- 第15组:function_score自定义分数
- 第16组:fuzzy 模糊搜索
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html
核心概念
概念1
查询语句其可以分为两种类型:
子查询语句 Leaf query clauses
子查询子句在特定字段中查找特定值,例如match,term或range查询。
复合查询语句 Compound query clauses
复合查询子句包装其他子查询或复合查询,并用于以逻辑方式组合多个查询(例如bool或dis_max查询),或更改其行为(例如constant_score查询)。
概念2
查询语句的使用场景分为两种:query context 以及 filter context
官方文档:Query and filter context
query context
解决问题:该文档与该查询子句的匹配程度如何
其使用相关度评分 relevance score
filter context
解决问题:该文档与该查询子句匹配吗?
其不使用相关度评分 relevance score
概念3
另外的一组关键概念:exact value & full text
在创建索引mapping的时候,不同类型的field,可能有的就是full text,有的就是exact value
对于full text,其会创建倒排索引,并且对每一个词进行分词(类似mapping type=text)
对于exact value,其也会创建倒排索引,但是不会进行分词(类似mapping type=keyword)
对于query context,处理的就是类似sql中like的含义,是否包含,其处理的是full text
对于filter context,其处理的就是类似sql中 = 的含义,是否相等,其处理的是exact value
概念4
召回率recall
比如你搜索一个java spark,总共有100个doc,能返回多少个doc作为结果,就是召回率,recall
精准度precision
比如你搜索一个java spark,能不能尽可能让包含java spark,或者是java和spark离的很近的doc,排在最前面,precision
将查询部分分为子查询语句、复合查询语句以及特殊需求语句
子查询语句
下面以 需求 <-> 对应的Query Dsl为例
第1组:单个field 单值包含
需求:match 单个field 单值包含
语句:
GET /test_index/test_type/_search
{
"query": {
"match": {
"test_field": "test"
}
}
}
match query是会对查询字段进行分词的
第2组:多fields 单值包含
需求:multi_match 多fields 单值包含
语句:
GET /test_index/test_type/_search
{
"query": {
"multi_match": {
"query": "test",
"fields": ["test_field", "test_field1"]
}
}
}
第3组:单field范围查询
需求:range query 单field范围查询
语句:
GET /company/employee/_search
{
"query": {
"range": {
"age": {
"gte": 30
}
}
}
}
第4组:单field单值相等
需求:term query 单field单值相等
语句:
GET /test_index/test_type/_search
{
"query": {
"term": {
"test_field": "test hello"
}
}
}
term query把查询字段当作exact value来查询,这个前提是mapping的时候对应term query的字段,mapping type=keyword 不分词
第5组:单field 多值相等
需求:terms query,单field 多值相等
语句:
GET /_search
{
"query": {
"terms":
{ "tag": [ "search", "full_text", "nosql" ]
}
}
}
第6组:filter
需求:filter
语句:
GET /company/employee/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"age": {
"gte": 30
}
}
}
}
}
}
“query”下直接放filter是不支持的,要加上constant_score
其另外一种写法
GET /_search
{
"query" : {
"bool" : {
"filter" : {
"term" : {
"author_id" : 1
}
}
}
}
}
filter是不计算相关度分数的
第7组:sort排序
需求:sort
语句:
GET /company/employee/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"age": {
"gte": 30
}
}
}
}
},
"sort": [
{
"join_date": {
"order": "asc"
}
}
]
}
默认是根据相关度分数降序排列的,可以通过sort语句修改
sort:最好在“日期型”和“数字型”字段上排序
第8组:单个field 多值匹配
需求:单个field 多值匹配
搜索标题中包含java或elasticsearch的blog
语句:
GET /forum/article/_search
{
"query": {
"match": {
"title": "java elasticsearch"
}
}
}
与之前的term query不同,不是搜索exact value,是进行full text全文检索。
match query,是负责进行全文检索的。当然,如果要检索的field,是not_analyzed 不分词keyword类型,那么match query也相当于term query。
也可以这样实现
{
"bool": {
"should": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }}
]
}
}
实际上es底层最终就是转换为上面的语句进行执行的
第9组:单field多值匹配
需求:搜索标题中包含java和elasticsearch的blog
语句:
GET /forum/article/_search
{
"query": {
"match": {
"title": {
"query": "java elasticsearch",
"operator": "and"
}
}
}
}
灵活使用and关键字,如果你是希望所有的搜索关键字都要匹配的,那么就用and,可以实现单纯match query无法实现的效果
另一种写法must+term
{
"bool": {
"must": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }}
]
}
}
这也是底层实际执行的语句
第10组:单field多值匹配,至少匹配几个值
需求:搜索包含java,elasticsearch,spark,hadoop,4个关键字中,至少3个的blog
语句:
GET /forum/article/_search
{
"query": {
"match": {
"title": {
"query": "java elasticsearch spark hadoop",
"minimum_should_match": "75%"
}
}
}
}
minimum_should_match:指定一些关键字中,必须至少匹配其中的多少个关键字,才能作为结果返回
也可以这样实现
GET /forum/article/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "java" }},
{ "match": { "title": "elasticsearch" }},
{ "match": { "title": "hadoop" }},
{ "match": { "title": "spark" }}
],
"minimum_should_match": 3
}
}
}
如果没有must的话,那么should中必须至少匹配一个才可以
通过minimum_should_match进行精准控制,should的4个条件中,至少匹配几个才能作为结果返回
这是底层实际执行的语句
第11组:是否存在exists
是否存在: exists query
es无法索引或搜索空值null。 当字段设置为null(或空数组或空值数组)时,它被视为该字段没有值。
参考:exists query官方文档
Returns documents that contain an indexed value for a field.
An indexed value may not exist for a document’s field due to a variety of reasons:
- The field in the source JSON is
nullor[] - The field has
"index" : falseset in the mapping - The length of the field value exceeded an
ignore_abovesetting in the mapping - The field value was malformed and
ignore_malformedwas defined in the mapping
GET /_search
{
"query": {
"exists": {
"field": "user"
}
}
}
While a field is deemed non-existent if the JSON value is null or [], these values will indicate the field does exist:
- Empty strings, such as
""or"-" - Arrays containing
nulland another value, such as[null, "foo"] - A custom
null-value, defined in field mapping
第12组:获取某个字段的去重记录
使用Elasticsearch查询字段的所有唯一值,参考:Query all unique values of a field with Elasticsearch
select distinct full_name from authors;
-- is equivanlent to
select full_name from authors group by full_name;
Kibana语句
GET index_name/_search
{
"aggs": {
"userId": {
"terms": {
"field": "userId",
"size":30
}
}
},
"size": 0
}
第13组:根据字段长度进行过滤
需求
过滤出client=android并且client_id的长度不小于40
kibana语句
GET user-tags/_search
{
"query": {
"bool":{
"must": [
{
"match":{
"client":"android"
}
},
{
"constant_score": {
"filter": {
"script": {
"script": "doc['client_id'].getValue().length() >=40"
}
}
}
}
]
}
}
}
复合语句查询
bool查询,是一个或多个查子句的组合,包含四种子句:should, must, must_not, filter,其中2 种会影响算分,2 种不影响算分
相关性并不只是全文本检索的专利。也适用于yes | no 的子句,匹配的子句越多,相关性评分
越高。如果多条查询子句被合并为一条复合查询语句,比如bool 查询,则每个查询子句计算
得出的评分会被合并到总的相关性评分中。
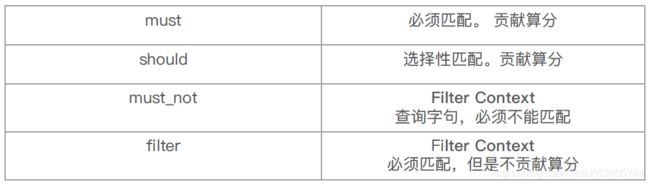
可以通过嵌套bool,实现should not逻辑

第1组:多fields单值包含 + 过滤条件
需求:title必须包含elasticsearch,content可以包含elasticsearch也可以不包含,包含更好,author_id必须不为111
语句:
GET /website/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "elasticsearch"
}
}
],
"should": [
{
"match": {
"content": "elasticsearch"
}
}
],
"must_not": [
{
"match": {
"author_id": 111
}
}
]
}
}
}
说明:should可以影响相关度评分
第2组 多fields多值匹配
需求:
- 条件1: name是tom
- 条件2: hired可以是true,也可以是false
- 条件3: personality要good,不能rude。这个条件满足也行,不满足也行,满足当然好了
- 至少要匹配一个条件
GET /test_index/_search
{
"query": {
"bool": {
"must": { "match": { "name": "tom" }},
"should": [
{ "match": { "hired": true }},
{ "bool": {
"must": { "match": { "personality": "good" }},
"must_not": { "match": { "rude": true }}
}}
],
"minimum_should_match": 1
}
}
}
minimum_should_match:
第3组 多fields多值匹配
需求:年龄必须大于等于30,同时join_date必须是2016-01-01
语句:
GET /company/employee/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"join_date": "2016-01-01"
}
}
],
"filter": {
"range": {
"age": {
"gte": 30
}
}
}
}
}
}
每个子查询都会计算一个document针对它的相关度分数,然后bool综合所有分数,合并为一个分数,当然filter是不会计算分数的
第4组
需求:title中必须包含java,必须不包含spark,hadoop或者elasticsearch可以包含,也可以不包含,包含更好
语句:
GET /forum/article/_search
{
"query": {
"bool": {
"must": { "match": { "title": "java" }},
"must_not": { "match": { "title": "spark" }},
"should": [
{ "match": { "title": "hadoop" }},
{ "match": { "title": "elasticsearch" }}
]
}
}
}
bool组合多个搜索条件,如何计算relevance score
must和should搜索对应的分数,加起来,除以must和should的总数
must是确保说,谁必须有这个关键字,同时会根据这个must的条件去计算出document对这个搜索条件的relevance score
在满足must的基础之上,should中的条件,不匹配也可以,但是如果匹配的更多,那么document的relevance score就会更高
排名第一:java,同时包含should中所有的关键字,hadoop,elasticsearch
排名第二:java,同时包含should中的某个词
排名第三:java,不包含should中的任何关键字
第5组:多个field多个值匹配
需求:多个field多个值匹配
搜索title或content中包含java或solution的帖子
语句:
GET /forum/article/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]
}
}
}
特殊需求语句查询
第1组:搜索条件的权重boost
需求:
- 搜索标题中包含java的帖子
- 如果标题中包含hadoop或elasticsearch就优先搜索出来
- 如果一个帖子包含java hadoop,一个帖子包含java elasticsearch,包含hadoop的帖子要比elasticsearch优先搜索出来
语句:
GET /forum/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "blog"
}
}
],
"should": [
{
"match": {
"title": {
"query": "java"
}
}
},
{
"match": {
"title": {
"query": "hadoop"
}
}
},
{
"match": {
"title": {
"query": "elasticsearch",
"boost": 5
}
}
}
]
}
}
}
默认情况下,搜索条件的boost权重都是一样的,都是1
第2组:dis_max实现best fields策略
需求:搜索title或content中包含java或solution的帖子,并且某一个field中匹配到了尽可能多的关键词,被排在前面
语句:
GET /forum/article/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]
}
}
}
best fields策略,就是说,搜索到的结果,应该是某一个field中匹配到了尽可能多的关键词,被排在前面;而不是尽可能多的field匹配到了少数的关键词,排在了前面
dis_max语法,直接取多个query中,分数最高的那一个query的分数即可
第3组:tie_breaker参数优化dis_max搜索效果
需求:搜索title或content中包含java beginner的帖子
语句:
GET /forum/article/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java beginner" }},
{ "match": { "body": "java beginner" }}
],
"tie_breaker": 0.3
}
}
}
dis_max只取某一个query最大的分数,完全不考虑其他query的分数
tie_breaker参数的意义,在于说,将其他query的分数,乘以tie_breaker,然后综合与最高分数的那个query的分数,综合在一起进行计算
除了取最高分以外,还会考虑其他的query的分数
tie_breaker的值,在0~1之间,是个小数
第4组:boost+dis_max+tie_breaker
需求:
- 搜索title或content中包含java solution的帖子
- title权重为content权重的两倍
GET /forum/article/_search
{
"query": {
"multi_match": {
"query": "java solution",
"type": "best_fields",
"fields": [ "title^2", "content" ],
"tie_breaker": 0.3,
"minimum_should_match": "50%"
}
}
}
长尾,比如你搜索5个关键词,但是很多结果是只匹配1个关键词的,其实跟你想要的结果相差甚远,这些结果就是长尾
minimum_should_match,控制搜索结果的精准度,只有匹配一定数量的关键词的数据,才能返回,去掉长尾
第5组:most_fields策略
语句:
GET /forum/article/_search
{
"query": {
"multi_match": {
"query": "learning courses",
"type": "most_fields",
"fields": [ "sub_title", "sub_title.std" ]
}
}
}
most-fields策略,主要是说尽可能返回更多field匹配到某个关键词的doc,优先返回回来
第6组:cross-fields技术改善most_fields策略
语句
GET /forum/article/_search
{
"query": {
"multi_match": {
"query": "Peter Smith",
"type": "cross_fields",
"operator": "and",
"fields": ["author_first_name", "author_last_name"]
}
}
}
解决most_fields进行cross-fields搜索存在的3个弊端
| 问题 | 解决方案 |
|---|---|
| 问题1:只是找到尽可能多的field匹配的doc,而不是某个field完全匹配的doc | 解决,要求每个term都必须在任何一个field中出现 |
| 问题2: most_fields,没办法用minimum_should_match去掉长尾数据,就是匹配的特别少的结果 | 解决,既然每个term都要求出现,长尾肯定被去除掉了 |
| 问题3:TF/IDF算法,比如Peter Smith和Smith Williams,搜索Peter Smith的时候,由于first_name中很少有Smith的,所以query在所有document中的频率很低,得到的分数很高,可能Smith Williams反而会排在Peter Smith前面 | 计算IDF的时候,将每个query在每个field中的IDF都取出来,取最小值,就不会出现极端情况下的极大值了 |
第7组:phrase match 短语匹配
需求:java spark,就靠在一起,中间不能插入任何其他字符,就要搜索出来这种doc
语句:
GET /forum/article/_search
{
"query": {
"match_phrase": {
"content": "java spark"
}
}
}
phrase match,就是要去将多个term作为一个短语,一起去搜索,只有包含这个短语的doc才会作为结果返回。
match是处理不了短语这种场景的。使用match搜索java spark,java的doc也会返回,spark的doc也会返回。
第8组:基于slop参数实现proximity match 近似匹配
语句:
GET /forum/article/_search
{
"query": {
"match_phrase": {
"title": {
"query": "java spark",
"slop": 1
}
}
}
}
搜索文本中的几个term,要经过几次移动才能与一个document匹配,这个移动的次数,就是slop
match query的性能比phrase match和proximity match(有slop)要高很多。因为后两者都要计算position的距离。
第9组:混合使用match和近似匹配实现召回率与精准度的平衡
需求:我们希望的是匹配到几个term中的部分,就可以作为结果出来,这样可以提高召回率。同时也希望用上match_phrase根据距离提升分数的功能,让几个term距离越近分数就越高,优先返回,提高精准度。
语句:
GET /forum/article/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": {
"query":"java spark" --> java或spark或java spark,java和spark靠前,但是没法区分java和spark的距离,也许java和spark靠的很近,但是没法排在最前面
}
}
},
"should": {
"match_phrase": { --> 在slop以内,如果java spark能匹配上一个doc,那么就会对doc贡献自己的relevance score,如果java和spark靠的越近,那么就分数越高
"title": {
"query": "java spark",
"slop": 50
}
}
}
}
}
}
第10组:使用rescoring机制优化近似匹配搜索的性能
需求:近似匹配情况下,仅对前50个doc进行slop移动去匹配,去贡献自己的分数即可,不需要对全部1000个doc都去进行计算和贡献分数
语句:
GET /forum/article/_search
{
"query": {
"match": {
"content": "java spark"
}
},
"rescore": {
"window_size": 50,
"query": {
"rescore_query": {
"match_phrase": {
"content": {
"query": "java spark",
"slop": 50
}
}
}
}
}
}
第11组:实现前缀搜索
语句:
GET my_index/my_type/_search
{
"query": {
"prefix": {
"title": {
"value": "C3"
}
}
}
}
前缀搜索,要遍历整个倒排索引,存在性能问题
第12组:实现通配搜索
wildcard需要使用其keyword字段
语句:
GET index_name/_search
{
"query":{
"wildcard": {
"H5Title.keyword": {
"value": "学习强国-社保*"
}
}
}
}
原理应该是:通配符搜索要使用正排索引,keyword借助doc values,而对于text,没有fielddata=true,无法执行,即便可以执行,也是分词的结果,估计对于通配符也不合适
第13组:实现正则搜索
语句:
GET /my_index/my_type/_search
{
"query": {
"regexp": {
"title": "C[0-9].+"
}
}
}
C[0-9].+
[0-9]:指定范围内的数字
[a-z]:指定范围内的字母
.:一个字符
+:前面的正则表达式可以出现一次或多次
查询长度超过50位的搜索词内容
GET xxx/_search
{
"query":{
"bool":{
"must":{
"match_all":{
}
},
"filter":[
{
"regexp":{
"word":{
"value":".{50,}"
}
}},
{"range": {
"datetime": {
"gte": "2019-01-01T08:00:00.000Z",
"lte": "2020-01-13T07:59:59.999Z"
}
}}
]
}
},
"size":111
}
wildcard和regexp,与prefix原理一致,都会扫描整个索引,性能很差
第14组:negative boost
需求:搜索包含java,不包含spark的doc,但是这样子很死板
搜索包含java,尽量不包含spark的doc,如果包含了spark,不会说排除掉这个doc,而是说将这个doc的分数降低
语句:
GET /forum/article/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"content": "java"
}
},
"negative": {
"match": {
"content": "spark"
}
},
"negative_boost": 0.2
}
}
}
包含了negative term的doc,分数乘以negative boost,分数降低
第15组:function_score自定义分数
需求:对帖子搜索得到的相关性分数,跟follower_num进行运算,由follower_num在一定程度上增强帖子的分数看帖子的人越多,那么帖子的分数就越高
语句:
GET /forum/article/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "java spark",
"fields": ["tile", "content"]
}
},
"field_value_factor": {
"field": "follower_num",
"modifier": "log1p",
"factor": 0.5
},
"boost_mode": "sum",
"max_boost": 2
}
}
}
如果只有field,那么会将每个doc的分数都乘以follower_num,如果有的doc follower是0,那么分数就会变为0,效果很不好。因此一般会加个log1p函数,公式会变为,new_score = old_score * log(1 + number_of_votes),这样出来的分数会比较合理
再加个factor,可以进一步影响分数,new_score = old_score * log(1 + factor * number_of_votes)
boost_mode,可以决定分数与指定字段的值如何计算,multiply,sum,min,max,replace
max_boost,限制计算出来的分数不要超过max_boost指定的值
第16组:fuzzy 模糊搜索
需求:搜索的时候,可能输入的搜索文本会出现误拼写的情况
语句:
GET /my_index/my_type/_search
{
"query": {
"fuzzy": {
"text": {
"value": "surprize",
"fuzziness": 2
}
}
}
}
fuzzy搜索以后,会自动尝试将你的搜索文本进行纠错,然后去跟文本进行匹配
fuzziness,你的搜索文本最多可以纠正几个字母去跟你的数据进行匹配,默认如果不设置,就是2