变分自编码器(Variational AutoEncoder,VAE)
1 从AE谈起
说到编码器这块,不可避免地要讲起AE(AutoEncoder)自编码器。它的结构下图所示:

据图可知,AE通过自监督的训练方式,能够将输入的原始特征通过编码encoder后得到潜在的特征编码,实现了自动化的特征工程,并且达到了降维和泛化的目的。而后通过对进行decoder后,我们可以重构输出。一个良好的AE最好的状态就是解码器的输出能够完美地或者近似恢复出原来的输入, 即。为此,训练AE所需要的损失函数是: ∣ ∣ x − x ^ ∣ ∣ ||x-\hat{x}|| ∣∣x−x^∣∣
AE的重点在于编码,而解码的结果,基于训练目标,如果损失足够小的话,将会与输入相同。从这一点上看解码的值没有任何实际意义,除了通过增加误差来补充平滑一些初始的零值或有些许用处。
易知,从输入到输出的整个过程,AE都是基于已有的训练数据的映射,尽管隐藏层的维度通常比输入层小很多,但隐藏层的概率分布依然只取决于训练数据的分布,这就导致隐藏状态空间的分布并不是连续的,它只是稀疏地记录下来你的输入样本和生成图像的一一对应关系。 因此如果我们随机生成隐藏层的状态,那么它经过解码将很可能不再具备输入特征的特点,因此想通过解码器来生成数据就有点强模型所难了。
如下图所示,仅通过AE,我们在码空间里随机采样的点并不能生成我们所希望的相应图像。这就使得我的不能够达到AIGC的效果。

据此,我们对AE的隐藏层z作出改动(让隐空间连续光滑),得到了VAE。


2 变分自编码器(Variational AutoEncoder,VAE)
关于变分推断,请查看本人的另一篇博文:变分推断(Variational Inference)
这里只做一个总结:
- 变分推断是使用另一个分布 q ( z ) q(z) q(z)近似 p ( z ∣ x ) p(z|x) p(z∣x)
- 用KL距离衡量分布的近似程度: K L ( q ( z ) ∣ ∣ p ( z ∣ x ) ) KL(q(z)||p(z|x)) KL(q(z)∣∣p(z∣x)),所以最优的 q ∗ ( z ) = a r g m i n q ( z ) ∈ Q K L ( q ( z ) ∣ ∣ p ( z ∣ x ) ) q^*(z)=argmin_{q(z) \in Q}KL(q(z)||p(z|x)) q∗(z)=argminq(z)∈QKL(q(z)∣∣p(z∣x))
- 对 K L ( q ( z ) ∣ ∣ p ( z ∣ x ) ) KL(q(z)||p(z|x)) KL(q(z)∣∣p(z∣x))的最小化转化为对ELBO的最大化,也就是 q ∗ ( z ) = a r g m i n q ( z ) ∈ Q K L ( q ( z ) ∣ ∣ p ( z ∣ x ) ) = a r g m a x q ( z ) ∈ Q E L B O = a r g m a x q ( z ) ∈ Q E q ( l o g ( p ( x , z ) − l o g q ( z ) ) ) q^*(z)=argmin_{q(z) \in Q}KL(q(z)||p(z|x))=argmax_{q(z)\in Q}ELBO=argmax_{q(z)\in Q}E_q(log(p(x,z)-logq(z))) q∗(z)=argminq(z)∈QKL(q(z)∣∣p(z∣x))=argmaxq(z)∈QELBO=argmaxq(z)∈QEq(log(p(x,z)−logq(z)))
VAE全称是Variational AutoEncoder,即变分自编码器。
在VAE中 q ( z ) q(z) q(z)用一个编码器神经网络表示,假如其参数是 θ \theta θ,那么我们用 q θ ( z ) q_{\theta}(z) qθ(z)或者 q θ ( z ∣ x ) q_{\theta}(z|x) qθ(z∣x)表示。 p ( z ∣ x ) p(z|x) p(z∣x)可以认为是自然界真实存在的一个概率分布,但是我们不知道,所以需要用一个神经网络把他近似出来。
2.1 VAE的目的

VAE的目的:
(1)用神经网络去逼近和模拟 p ( z ∣ x ) p(z|x) p(z∣x)近似 p ( x ∣ z ) p(x|z) p(x∣z)这两个概率分布
(2)并尽量保证隐空间是连续和平滑的,即 p ( z ) p(z) p(z)和 p ( z ∣ x ) p(z|x) p(z∣x)是平滑的
2.2 VAE方法与损失函数
作者方法“
(1)定义: p ( z ) ∼ N ( 0 , 1 ) p(z) \sim N(0,1) p(z)∼N(0,1)
(2)定义: q θ ( z ∣ x ) ∼ N ( g ( x ) , h ( x ) ) q_{\theta}(z|x) \sim N(g(x),h(x)) qθ(z∣x)∼N(g(x),h(x)),也就是 q θ ( z ∣ x ) q_{\theta}(z|x) qθ(z∣x)的期望和方差是用两个神经网络计算出来的
(3)定义: p θ ′ ( x ∣ z ) ∼ N ( f ( z ) , c I ) p_{\theta'}(x|z) \sim N(f(z),cI) pθ′(x∣z)∼N(f(z),cI),所以解码器的输出的是 p θ ′ ( x ∣ z ) p_{\theta'}(x|z) pθ′(x∣z)的期望
这样直接定义好吗?为这么直接这样定义出来?看下面的一个slide

对ELBO做一个推导:

因为 p ( x ∣ z ) = 1 2 π c e ∣ ∣ x − f ( z ) ∣ ∣ 2 2 c p(x|z) = \frac{1}{\sqrt{2\pi c}}e^{\frac{||x-f(z)||^2}{2c}} p(x∣z)=2πc1e2c∣∣x−f(z)∣∣2,所以有:
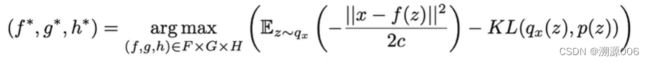
也就是找到这样的三个神经网络使得上面的式子最大。
对于上面的第二项:

所以损失函数可以写成:
l o s s = 1 2 ( − l o g h ( x ) 2 + h ( x ) 2 + g ( x ) 2 − 1 ) + C ∣ ∣ x − f ( z ) ∣ ∣ 2 loss=\frac{1}{2}(-logh(x)^2+h(x)^2+g(x)^2-1)+C||x-f(z)||^2 loss=21(−logh(x)2+h(x)2+g(x)2−1)+C∣∣x−f(z)∣∣2
2.3 重参数技巧
从高斯分布 N ( μ , σ ) N(μ,σ) N(μ,σ)中采样的操作被巧妙转换为了从 N ( 0 , 1 ) N(0,1) N(0,1)中采样得到 ϵ ϵ ϵ后,再通过 z = μ + σ × ϵ z=μ+σ \times ϵ z=μ+σ×ϵ变换得到。

而在重参数后,我们计算反向传播的过程 如下图所示:

2.4 整合起来

(1)从样本库中取图片x
(2)g(x)计算均值,h(x)计算方差,从标准正太分布中采样一个数 ζ \zeta ζ,然后计算 z = ζ h ( x ) + g ( x ) z=\zeta h(x)+g(x) z=ζh(x)+g(x),然后计算 f ( z ) f(z) f(z)
(3)计算损失
(4)反向传播
3 代码实现
3.1 VAE.py
import torch
from torch import nn
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
# [b, 784] =>[b,20]
# u: [b, 10]
# sigma: [b, 10]
self.encoder = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 20),
nn.ReLU()
)
# [b,10] => [b, 784]
# sigmoid函数把结果压缩到0~1
self.decoder = nn.Sequential(
nn.Linear(10, 64),
nn.ReLU(),
nn.Linear(64, 256),
nn.ReLU(),
nn.Linear(256, 784),
nn.Sigmoid()
)
def forward(self, x):
"""
:param x:
:return:
"""
batchsz = x.size(0)
# flatten
x = x.view(batchsz, 784)
# encoder
# [b, 20], including mean and sigma
h_ = self.encoder(x)
# chunk 在第二维上拆分成两部分
# [b, 20] => [b,10] and [b, 10]
mu, sigma = h_.chunk(2, dim=1)
# reparametrize tirchk, epison~N(0, 1)
# torch.randn_like(sigma)表示正态分布
h = mu + sigma * torch.randn_like(sigma)
# decoder
x_hat = self.decoder(h)
# reshape
x_hat = x_hat.view(batchsz, 1, 28, 28)
# KL
# 1e-8是防止σ^2接近于零时该项负无穷大
# (batchsz*28*28)是让kld变小
kld = 0.5 * torch.sum(
torch.pow(mu, 2) +
torch.pow(sigma, 2) -
torch.log(1e-8 + torch.pow(sigma, 2)) - 1
) / (batchsz*28*28)
return x, kld
3.2 main.py
import torch
from torch.utils.data import DataLoader
from torch import nn, optim
from torchvision import transforms, datasets
from ae_1 import AE
from vae import VAE
from vq-vae import VQVAE
import visdom
def main():
mnist_train = datasets.MNIST('mnist', True, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_train = DataLoader(mnist_train, batch_size=32, shuffle=True)
mnist_test = datasets.MNIST('mnist', False, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_test = DataLoader(mnist_test, batch_size=32, shuffle=True)
#无监督学习,不能使用label
x, _ = iter(mnist_train).next()
print('x:', x.shape)
device = torch.device('cuda')
#model = AE().to(device)
model = VAE().to(device)
criteon = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print(model)
viz = visdom.Visdom()
for epoch in range(1000):
for batchidx, (x, _) in enumerate(mnist_train):
# [b, 1, 28, 28]
x = x.to(device)
x_hat, kld = model(x)
loss = criteon(x_hat, x)
if kld is not None:
elbo = - loss - 1.0 * kld
loss = - elbo
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, 'loss', loss.item(), kld.item())
x, _ = iter(mnist_test).next()
x = x.to(device)
with torch.no_grad():
x_hat = model(x)
# nrow表示一行的图片
viz.images(x, nrow=8, win='x', optis=dic(title='x'))
iz.images(x_hat, nrow=8, win='x_hat', optis=dic(title='x_hat'))
if __name__ == '__main__':
main()
参考
讲解变分自编码器-VAE(附代码)
VAE到底在做什么?VAE原理讲解系列#1
VAE的神经网络是如何搭建的?VAE原理讲解系列#3
从零推导:变分自编码器(VAE)