LeetCode刷题——剑指offer中链表题目汇总
系列文章目录
每日一题题目汇总
剑指offer中简单遍历查找题目汇总
剑指offer动态规划汇总
剑指offer二叉树题目汇总
剑指offer中链表题目汇总
- 系列文章目录
- 剑指 Offer 06. 从尾到头打印链表(简单)
- 剑指 Offer 18. 删除链表的节点
- 剑指 Offer 22. 链表中倒数第k个节点
- 剑指 Offer 24. 反转链表(简单)
- 剑指 Offer 25. 合并两个排序的链表
- 剑指 Offer 35. 复杂链表的复制(中等)
- 剑指 Offer 52. 两个链表的第一个公共节点
剑指 Offer 06. 从尾到头打印链表(简单)
题目
输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。
示例 1:
输入:head = [1,3,2]
输出:[2,3,1]
限制:
0 <= 链表长度 <= 10000
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/cong-wei-dao-tou-da-yin-lian-biao-lcof
代码
这道题比较简单,直接把链表用数组存一下然后反转数组就好了
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* reversePrint(struct ListNode* head, int* returnSize){
int* ans;
ans = (int *)malloc(10000 * sizeof(int));
int k=0;
*returnSize=0;
while(head!=NULL){
ans[k++] = head->val;
head=head->next;
}
*returnSize=k;
for(int i=0; i < k / 2; i++){
int tmp = ans[i];
ans[i] = ans[k-1-i];
ans[k-1-i] = tmp;
}
return ans;
}
剑指 Offer 18. 删除链表的节点
题目
给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。
返回删除后的链表的头节点。
注意:此题对比原题有改动
示例 1:
输入: head = [4,5,1,9], val = 5
输出: [4,1,9]
解释: 给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9.
示例 2:
输入: head = [4,5,1,9], val = 1
输出: [4,5,9]
解释: 给定你链表中值为 1 的第三个节点,那么在调用了你的函数之后,该链表应变为 4 -> 5 -> 9.
说明:
题目保证链表中节点的值互不相同
若使用 C 或 C++ 语言,你不需要 free 或 delete 被删除的节点
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/shan-chu-lian-biao-de-jie-dian-lcof
代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* deleteNode(ListNode* head, int val) {
if(head->val == val){
return head->next;
}
ListNode* h=head;
while(h->next){
if(h->next->val == val){
ListNode* tmp = h->next;
h->next = h->next->next;
delete tmp;
break;
}
h = h -> next;
}
return head;
}
};
剑指 Offer 22. 链表中倒数第k个节点
题目
输入一个链表,输出该链表中倒数第k个节点。为了符合大多数人的习惯,本题从1开始计数,即链表的尾节点是倒数第1个节点。
例如,一个链表有 6 个节点,从头节点开始,它们的值依次是 1、2、3、4、5、6。这个链表的倒数第 3 个节点是值为 4 的节点。
示例:
给定一个链表: 1->2->3->4->5, 和 k = 2.
返回链表 4->5.
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/lian-biao-zhong-dao-shu-di-kge-jie-dian-lcof
分析
暴力解法:先遍历求链表的长度n,再从头遍历n-k个结点
双指针:使一个指针遍历k个结点,另一个指针从头开始与第一个指针同时遍历,直到第一个指针遍历结束为止。
暴力解法代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* getKthFromEnd(ListNode* head, int k) {
int n=0;
ListNode* h = head;
while(h){
h=h->next;
n++;
}
h = head;
for(int i=0; i < n - k; i++){
h=h->next;
}
return h;
}
};
双指针解法代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* getKthFromEnd(ListNode* head, int k) {
ListNode* h1 = head, * h2;
while(h1 && k--){
h1=h1->next;
}
h2 = head;
while(h1){
h2 = h2->next;
h1 = h1->next;
}
return h2;
}
};
剑指 Offer 24. 反转链表(简单)
题目
定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。
示例:
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
限制:
0 <= 节点个数 <= 5000
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/fan-zhuan-lian-biao-lcof
分析
一个很常规的链表操作题,这里只要理解链表的连接方式,合理的引入指针变量。
这里的操作是遍历原链表,将遍历到的原链表的结点以头连接的方式逐一连入到新的链表当中
代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* reverseList(struct ListNode* head){
struct ListNode* newhead;
newhead = NULL;
while(head!=NULL){
struct ListNode* tmpnode;
tmpnode = head->next;
head->next = newhead;
newhead=head;
head=tmpnode;
}
return newhead;
}
剑指 Offer 25. 合并两个排序的链表
题目
输入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的。
示例1:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
限制:
0 <= 链表长度 <= 1000
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/he-bing-liang-ge-pai-xu-de-lian-biao-lcof
代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
ListNode* h;
if(l1==NULL){
return l2;
}else if(l2==NULL){
return l1;
}
if(l1->val < l2->val){
h=l1;
l1 = l1->next;
}else{
h=l2;
l2 = l2->next;
}
h->next=NULL;
ListNode* t=h;
while(l1!=NULL && l2!=NULL){
if(l1->val < l2->val){
t->next = l1;
l1=l1->next;
t = t->next;
t->next = NULL;
}else{
t->next = l2;
l2=l2->next;
t = t->next;
t->next = NULL;
}
}
while(l1!=NULL){
t->next = l1;
l1=l1->next;
t = t->next;
t->next = NULL;
}
while(l2!=NULL){
t->next = l2;
l2=l2->next;
t = t->next;
t->next = NULL;
}
return h;
}
};
剑指 Offer 35. 复杂链表的复制(中等)
题目
请实现 copyRandomList 函数,复制一个复杂链表。在复杂链表中,每个节点除了有一个 next 指针指向下一个节点,还有一个 random 指针指向链表中的任意节点或者 null。
示例 1:

输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:
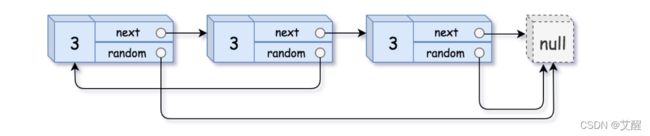
输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
示例 4:
输入:head = []
输出:[]
解释:给定的链表为空(空指针),因此返回 null。
提示:
-10000 <= Node.val <= 10000
Node.random 为空(null)或指向链表中的节点。
节点数目不超过 1000 。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/fu-za-lian-biao-de-fu-zhi-lcof
分析
这个题目相当具有混淆性,其实我们不必要把他看成一个复杂的链表,可以把他看作一个单链表,链表节点存储的信息为val和random,赋值时只要按照单链表复制val和random即可。但是有一个问题是复制时random的值不同,因为在新建结点时地址将会变化,所以我们在新建结点时可以建立一个映射,当除random之外全部复制完成之后再将之前的random值映射成新的random值即可。
代码
/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution {
public:
Node* copyRandomList(Node* head) {
if(head==NULL){
return NULL;
}
Node* newhead=new Node(head->val), *newtail, *h=head;
map<Node*, Node*> m;
m[h]=newhead;
newhead->random = h->random;
newhead->next = NULL;
newtail=newhead;
h = h->next;
while(h!=NULL){
Node* tmpnode = new Node(h->val);
m[h]=tmpnode;
tmpnode->random = h->random;
tmpnode->next = NULL;
newtail->next=tmpnode;
newtail = newtail->next;
h=h->next;
}
newtail=newhead;
while(newtail!=NULL){
newtail->random = m[newtail->random];
newtail = newtail->next;
}
return newhead;
}
};
剑指 Offer 52. 两个链表的第一个公共节点
题目
输入两个链表,找出它们的第一个公共节点。
如下面的两个链表:
在节点 c1 开始相交。
示例 1:
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Reference of the node with value = 8
输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:
输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Reference of the node with value = 2
输入解释:相交节点的值为 2 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
输入解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
解释:这两个链表不相交,因此返回 null。
注意:
如果两个链表没有交点,返回 null.
在返回结果后,两个链表仍须保持原有的结构。
可假定整个链表结构中没有循环。
程序尽量满足 O(n) 时间复杂度,且仅用 O(1) 内存。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/liang-ge-lian-biao-de-di-yi-ge-gong-gong-jie-dian-lcof
分析
以headA比headB长为例:假设headA比headB的长度长n,那么headA和headB同时遍历,当headB遍历结束时headA一定还剩下n个结点未遍历,遍历剩余的结点即可统计出在公共点之前headA比headB多n个结点, 要得到第一个公共结点,那么只需先将headA遍历n个结点,然后headA和headB同时遍历,查找到第一个相同的结点即可(注:要注意区分相同结点是指结点完全相同,不是指结点中存储的值相同)
代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if(headA==NULL || headB==NULL){
return NULL;
}else if(headA==headB){
return headA;
}
ListNode* a, *b;
a = headA;
b = headB;
while(a!=NULL && b!=NULL){
a=a->next;
b=b->next;
}
int cnta=0, cntb=0;
while(a!=NULL){
a=a->next;
cnta++;
}
while(b!=NULL){
b=b->next;
cntb++;
}
if(cnta){
a = headA;
b = headB;
while(cnta--){
a = a->next;
}
while(a!=NULL && b!=NULL){
if(a == b){
return a;
}
a=a->next;
b=b->next;
}
return NULL;
}else{
a = headA;
b = headB;
while(cntb--){
b = b->next;
}
while(a!=NULL && b!=NULL){
if(a == b){
return a;
}
cout<<a->val<<" v "<<b->val<<endl;
a=a->next;
b=b->next;
}
return NULL;
}
return NULL;
}
};